一 : Google Adwords匹配模式
今天的Inside Adwords (Google官博)宣布正式推出广泛匹配定制(BMM=Broad Match Modifier)。BMM的BETA版在英国加拿大试运行一阵子了,美国的少数代理/大客户也参与了试验,准备是充分的,但到推出的时候我还是略觉得意外—有点快!
先来解释一下这个广泛匹配定制BMM是个什么东西,最方便的还是直接使用Google自己的图片:

简单说:在使用广泛匹配的关键词(或关键词组成部分)前增添一个+号,就能把这个词(或组成部分)的广泛匹配限制在一定范围中:只有完全含有该词(或组成部分)的搜索词才会激发竞价以及展示。
之前写过一个博文来讨论广泛匹配VS精确匹配,但没有短语匹配的具体案例,同时文中的广泛匹配只基于Adwords广泛匹配的现状,没有涉及多少广泛匹配演变的渊源,及其引发的口水战。2004年以前,Adwords使用相对保守的广泛匹配,匹配到的搜索词相关度非常高,基本是含有原词和微量变形的。从2003年下半年开始,Google开始测试延伸广泛匹配extended broad match,并在2005年用以取代原有的广泛匹配。从RKG这样比较优秀的代理商的博客上,可以看见这在2006年已经成为了一个问题。
延伸广泛匹配的意思就是说:我很广泛!我很延伸!假如我投放的关键词是西太平洋大学,那么太平洋大学,西太平洋,太平,大学这类搜索词都可能激发竞价以及展示。这可能是好事:因为对于一个懒惰/过于忙碌的搜索营销管理员来说,使用广泛匹配就可以用最少的关键词抓获最多的潜在搜索量;而搜索用户也未必能键入最准确的搜索词。但也可能是坏事:广泛匹配会大大降低搜索词的相关性,带来无效展示和点击,对于讲究ROI的客户是很不利的。对于很多严肃的搜索营销管理员来说,向延伸广泛匹配切换是个糟糕的事情,因为延伸广泛匹配可以带来的好处往往可以通过扩充关键词投放来实现,但坏处却是搜索营销管理员所不能控制的。基本上,我觉得这是Google提高流量变现能力的措施,对于广告和搜索用户到底有多少益处就不好说了。
2008年下半年,Google推出Campaign级别的自动匹配测试,再次引起了对于延伸广泛匹配的申讨。自动匹配和延伸广泛匹配是两个概念,但出发点却有相似:只要你还有预算Google就来帮你花掉,你可以得到更多的点击和展示—–注意,这些点击展示的相关性要弱得多。与延伸广泛匹配的强制性不同,自动匹配是可以选择的,但默认值是允许—-相当多的客户可能从头到尾都不知道这个选项,即使知道,对于我们这种管理几百上千个Campaign的搜索营销管理员来说,修改设置也是大麻烦。不知道是否因为客户反弹过大,自动匹配很快变成了需要修改设置来加入的模式。很久没有跟踪这个测试的进展,今天查看帐户,这个功能在我目前管理的帐户中完全看不到了!
近一年来,Google的Adwords开发进度大大加快,连续发布了多个重量级功能,看得我眼花缭乱,到现在还有不少没有消化掉的。可以看得出,在SEM市场增长相对放慢的情况下,Google加强了深耕力度来提高广告商的消费能力。很显然,中长期的SEM市场繁荣需要得到广告商和代理商的支持和认可,不能把ROI带给广告客户的增收措施(比如简单的广泛匹配切换或者百度的MIN CPC提价)在当前的市场条件下代价增加了(高速发展的市场中,搜索引擎有本钱忽略这样的矛盾)。即便如此,如前所述,对于BMM的推出我还是略感意外。
对于广告商和代理商针对延伸广泛匹配的批评,Google的反应是:你不喜欢广泛匹配就用短语匹配嘛!

短语匹配的确是一种取代方式。但实际操作中,短语匹配是Adwords帐户管理中相对较弱的一种匹配方式,平均利用率较低。BMM的图例解释得很清楚,通过+号的运用,搜索营销管理员可以对关键词的广泛匹配范畴进行充分的定制—这比使用短语匹配要灵活得多。而这种可定制的广泛匹配所能激发的竞价和展示也比短语匹配要多得多,对Google的流量变现也是有利的。
我不懂技术,只是YY一下,通过+号方式实现关键词广泛匹配的定制在技术上来说应该不是太大的障碍。如果我们把BMM视作一组独立的匹配规则,那只是在现有的平台上加入了一种参数。当然,由于+号的位置可变,这显然比短语匹配要复杂不少,但规则本身仍然是单纯的。换句话说,+号的应用其实与“”或者【】一样,只是一个参数,对于Adwords的算法不会形成巨大的障碍。
如果技术上的难度没有那么大,那Google为什么要在5年以后才推出这个功能?很简单,BMM的对手不是短语匹配,而是广泛匹配。如果BMM在实践中被证明切实有效,那么它将立刻侵蚀广泛匹配的大量市场空间。RKG的George认为,在更高的相关度下,广告商可能获得更好的ROI,从而提高广告商的支出意愿。这是对的。但另一方面,在这个高相关度的环境中,提高支出意味着竞争实质上增加了,竞价成本也提高了,所以这个支出到底是否能平衡低相关度搜索词带来的收入,我颇存疑。
Google在英国和加拿大这两个二级市场中进行的测试,除了验证这个匹配的可靠性,我猜测很大一部分测试内容是观察BMM对点击量和收入带来的影响。根据前面的讨论,我认为BMM在短期内对Google收入的影响应该是负面的,顶多是这个负面影响不太大,损失可以承受,而推出BMM更多还是着眼在中长期。
最近比较懒,对于Google近期的动作一直想做点讨论,却一直没有动笔。总得来说,BMM和竞争分析或者提供系列试验功能等等一样,都是为了完善Adwords这个市场平台做出的重大努力。Google的这个完善过程将会严重挤压中小代理服务商的生存空间,但会使整个SEM市场水平上一个台阶。而这一切的核心在于:Google将自己定位成平台/市场/环境。正好在SEMWATCH讨论组里与天岸交换了一点关于苹果IAD的想法,下次也许可以拿出来谈谈?苹果,如大家所知,是与Google形成鲜明对照的。
文章来源:搜索营销智库 转载请注明出处链接。
注:相关网站建设技巧阅读请移步到建站教程频道。
二 : XML学习笔记(9)match属性匹配模式
匹配模式
1.匹配根节点
<xsl:template match="/"> <html> <xsl:apply-templates/> </html> </xsl:template>
2.匹配元素名
<xsl:template match="films"> <html> <xsl:apply-templates/> </html> </xsl:template>
3.匹配子节点
<xsl:template match="file/name"> <p> <xsl:value-of select="."/> </p> </xsl:template>
除了使用“/”,还可以使用“*”来匹配任意元素。(www.61k.com]在下面的程序中匹配了“film”元素的所有子节点的“name”元素。
<xsl:template match="film/*/name"> <p> <xsl:value-of select="."/> </p> </xsl:template>
4.匹配元素后代
<xsl:template match="film//name"> <p> <xsl:value-of select="."/> </p> </xsl:template>
在程序中指定的“film//name”, 包括了“film/name”,“film/*/name”,“film/*/*/name”等各种情况。对于选择给定类型的所有元素而不管这些元素是不是直系子孙时,这种方法会特别的有效。
5.匹配属性
<xsl:template match="films/film"> <p> <xsl:value-of select="@country"/> </p> </xsl:template>
匹配属性的机制和匹配元素的机制十分的类似,只是多了一个“@”符号而已。
就像使用“*”来选择一个元素的所有属性,例如,“film/@*”表示选择“film”元素的所有属性。
6.通过ID匹配
<xsl:template match="id('A101')"> <p> <xsl:value-of select="."/> </p> </xsl:template>7.匹配文本节点
<xsl:template match="name"> <xsl:value-of select="text()"/> </xsl:template>
XSL缺省规则规定,如果没有规则用于处理这一个文本节点,这个节点的文本将直接被输出,可以使用text()来推翻这一个缺省规则,让处理器对文本节点什么都不做。如下所示:
<xsl:template match="text()"> </xsl:template>
8.匹配注释
使用comment()来选择注释,例如:
<?xml version="1.0" encoding="gb2312"?> <film> <!--目前只有VCD版, DVD版还未上市--> <name>拯救大兵瑞恩</name> <director>施皮尔伯格</director> </film> <!--xsl--> <?xml version="1.0" encoding="gb2312"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3g.org/1999/XSL/Transform"> <xsl:template match="film"> <xsl:apply-templates select="comment()"/> <xsl:value-of select="name"/> <xsl:value-of select="director"/> </xsl:template> <xsl:template> <xsl:comment> <xsl:value-of select="."/> </xsl:comment> </xsl:template>
9.匹配操作指令
使用processing-instruction()来匹配操作指令,缩写为“pi()”,有时想要将样式单附加到另一个文档上,这是“pi()”就可以派上用场。
<xsl:template match="/pi()"> <xsl:pi name="xml-stylesheet"> <xsl:value-of select="."/> </xsl:pi> </xsl:template>
10.使用“或”操作符
在处理多个节点时,使用“或”操作符可以匹配多种可能的模式。
<xsl:template match="name|director"> <xsl:value-of select="."> </xsl:template>
程序中同时选择了“name”和“director”2个元素,并对他们使用同样的规则。
实例:
xml
<?xml version="1.0" encoding="utf-8"?> <?xml-stylesheet type="text/xsl" href="MyFirstXsl.xslt"?> <root> <music date="2010"> <title>传奇</title> <signer>王菲</signer> <舞台> <演员>路人甲</演员> <代表作>路人甲的代表作</代表作> </舞台> <舞台> <演员>路人乙</演员> <代表作>路人乙的代表作</代表作> </舞台> <lyric>我一直在你身旁,从未走远...</lyric> <!--在2010年春节联欢晚会上演唱--> </music> <music date="2009"> <title>梁祝</title> <signer>sweety</signer> <lyric>沉默了七世纪,没放弃逆转这宿命...</lyric> </music> <music date="2009"> <title>幸福毛毛虫</title> <signer>sweety</signer> <lyric>你的出现改变我原来的想象...</lyric> <!--很受欢迎--> </music> </root>
xslt
<?xml version="1.0" encoding="utf-8"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:msxsl="urn:schemas-microsoft-com:xslt" exclude-result-prefixes="msxsl" > <xsl:output method="xml" indent="yes"/> <xsl:template match="/"> <p align="center"> <font size="7">流行歌曲</font> </p> <table width="95%" border="1"> <tr> <td width="15%"> <div align="center">歌曲</div> </td> <td width="10%"> <div align="center">演唱者</div> </td> <td width="30%"> <div align="center">伴唱</div> </td> <td width="20%"> <div align="center">歌词概览</div> </td> <td width="10%"> <div align="center">时间</div> </td> <td width="10%"> <div align="center">备注</div> </td> </tr> <xsl:apply-templates/> </table> </xsl:template> <!--注释的匹配规则--> <xsl:template match="root/music/comment()"> <xsl:value-of select="."/> </xsl:template> <!--演唱者的详细介绍--> <xsl:template match="舞台"> <xsl:value-of select="演员"/>( <xsl:value-of select="代表作"/>) <br/> </xsl:template> <xsl:template match="root/music"> <tr> <td> <div align="center"> <strong> <font size="5"> <xsl:value-of select="title"/> </font> </strong> </div> </td> <td> <div align="center"> <strong> <font size="5"> <xsl:value-of select="signer"/> </font> </strong> </div> </td> <td> <div align="center"> <strong> <font size="5"> <xsl:apply-templates select="舞台"/> </font> </strong> </div> </td> <td> <div align="center"> <strong> <font size="5"> <xsl:value-of select="lyric"/> </font> </strong> </div> </td> <td> <div align="center"> <strong> <font size="5"> <xsl:value-of select="@date"/> </font> </strong> </div> </td> <!--匹配注释--> <td> <div align="center"> <strong> <font size="5"> <xsl:apply-templates select="comment()"/> </font> </strong> </div> </td> </tr> </xsl:template> </xsl:stylesheet>扩展:preg match 匹配数字 / js 正则匹配 match / preg match 匹配中文
显示效果:
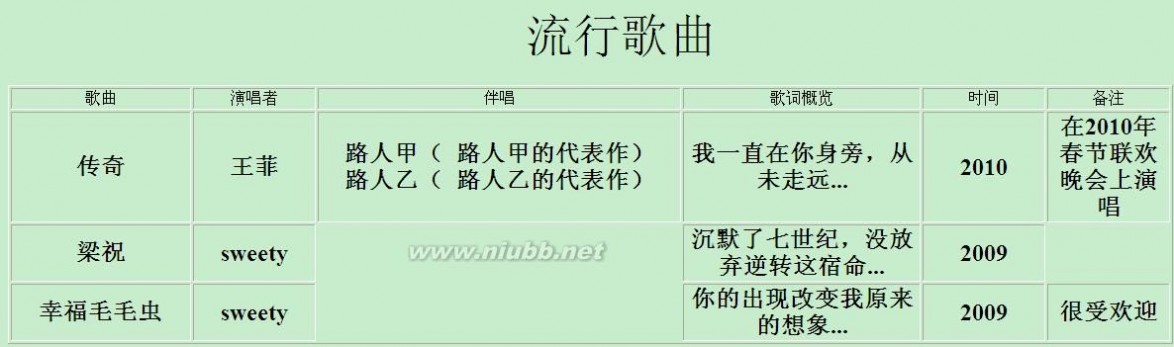
扩展:preg match 匹配数字 / js 正则匹配 match / preg match 匹配中文
三 : 模式匹配
我们知道比较有战斗力的直线提前量和圆周运动瞄准算法,都是针对固定模式的瞄准算法,比如直线提前量算法,如果对手不是走直线,就打不准;而圆周运动算法是针对做圆周运动的机器人的,如果对手走S型路线呢?我们是不是还要设计一套S行路线的瞄准算法呢?好,就算我们设计出来了,遇到走三角形路线的呢?是不是又要设计一套新的算法呢?就算你都设计出来了,如果对手的运动模式不断变化,一会儿做圆周,一会儿做S型,你该怎么办,使用圆周算法瞄准还是S型算法瞄准?显然,我们原来的思路出现了局限性。这里我将要介绍一种技术,能让我们的机器人自己识别对手的运动模式,然后从对手的模式推导出瞄准点,不管对手怎样变,只要有规律,我们都能打得很准。这可以说是一种具有学习能力的算法了,学习完本文后,实际上你已踏入了人工智能的领域。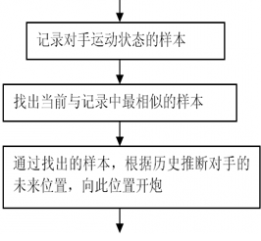
61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1