一 : 极疯坚信:搜索引擎怎么抓取摘要
今晚在点石上看到乐思蜀说关于页面摘要(Snippet)问题。两大主流中文搜索引擎,页面摘要的有效字符数为:百度:有效字符数为220个(相当于110个汉字)左右,含标点符号; Google:有效字符数为240个(相当于120个汉字)左右,含标点符号。还展视了一些高质量的页面摘要,也就是Description。从展视的摘要上看Google抓取后的摘要比百度的更人性化,用户体验很好,而百度抓取出来的有点不知所云的,Google的技术还是更胜一筹!
对于站长来说,了解搜索引擎怎么抓取摘要是我们想要知道的。下面分别对两大主流搜索引擎谷歌与百度抓取摘要进行介绍,个人经验总结希望大家修证。
对于谷歌来说一般是抓取Description里的内容,而没有写Description的网站抓取的文章第一段的内容,大家在谷歌site:www.shanxiseo.com看看,我的站是用ZBLOG,只在首页加了Keywords和Description,内页都没加。忘记了后来也就懒得加了,呵呵。。。
百度抓取摘要用Description的一般是权重高的网站,例:搜索SEO看到首页的有Description的站都抓取得好好的。而一般来说是直接抓取网页头部的文字内容,而不是文章内容,特别要提一下的是site网址时都是这样,例:site:www.shanxiseo.com。在搜索关键词时是抓取在文章中密度高的段落,例:搜索山西SEO摘要显示出来的都是出来山西与SEO密度高的段落。
二 : 如何让搜索引擎抓取AJAX内容?
越来越多的网站,开始采用"单页面结构"(Single-page application)。
整个网站只有一张网页,采用Ajax技术,根据用户的输入,加载不同的内容。

这种做法的好处是用户体验好、节省流量,缺点是AJAX内容无法被搜索引擎抓取。举例来说,你有一个网站。
http://example.com
用户通过井号结构的URL,看到不同的内容。
http://example.com#1
http://example.com#2
http://example.com#3
但是,搜索引擎只抓取example.com,不会理会井号,因此也就无法索引内容。
为了解决这个问题,Google提出了"井号+感叹号"的结构。
http://example.com#!1
当Google发现上面这样的URL,就自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把AJAX内容放在这个网址,Google就会收录。但是问题是,"井号+感叹号"非常难看且烦琐。Twitter曾经采用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果用户抱怨连连,只用了半年就废除了。
那么,有没有什么方法,可以在保持比较直观的URL的同时,还让搜索引擎能够抓取AJAX内容?
我一直以为没有办法做到,直到前两天看到了Discourse创始人之一的Robin Ward的解决方法,不禁拍案叫绝。
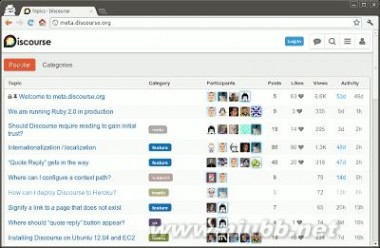
Discourse是一个论坛程序,严重依赖Ajax,但是又必须让Google收录内容。它的解决方法就是放弃井号结构,采用 History API。
所谓 History API,指的是不刷新页面的情况下,改变浏览器地址栏显示的URL(准确说,是改变网页的当前状态)。这里有一个例子,你点击上方的按钮,开始播放音乐。然后,再点击下面的链接,看看发生了什么事?
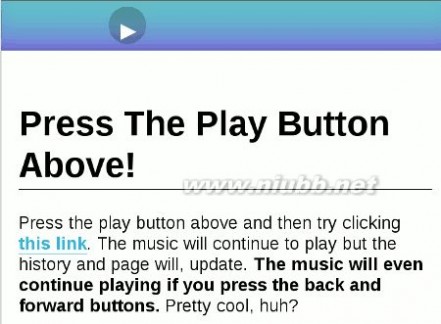
地址栏的URL变了,但是音乐播放没有中断!
History API 的详细介绍,超出这篇文章的范围。这里只简单说,它的作用就是在浏览器的History对象中,添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令,可以让地址栏出现新的URL。History对象的pushState方法接受三个参数,新的URL就是第三个参数,前两个参数都可以是null。
window.history.pushState(null, null, newURL);
目前,各大浏览器都支持这个方法:Chrome(26.0+),Firefox(20.0+),IE(10.0+),Safari(5.1+),Opera(12.1+)。
下面就是Robin Ward的方法。
首先,用History API替代井号结构,让每个井号都变成正常路径的URL,这样搜[www.61k.com)索引擎就会抓取每一个网页。
example.com/1
example.com/2
example.com/3
然后,定义一个JavaScript函数,处理Ajax部分,根据网址抓取内容(假定使用jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
再定义鼠标的click事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑到用户点击浏览器的"前进 / 后退"按钮。这时会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义完上面三段代码,就能在不刷新页面的情况下,显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为不使用井号结构,每个URL都是一个不同的请求。所以,要求服务器端对所有这些请求,都返回如下结构的网页,防止出现404错误。
<html>
<body>
<section id='container'></section>
<noscript>
... ...
</noscript>
</body>
</html>
仔细看上面这段代码,你会发现有一个noscript标签,这就是奥妙所在。
我们把所有要让搜索引擎收录的内容,都放在noscript标签之中。这样的话,用户依然可以执行AJAX操作,不用刷新页面,但是搜索引擎会收录每个网页的主要内容!
(完)
文章来源:阮一峰的网络日志
三 : 了解robots文件,主动告诉搜索引擎该抓取什么内容

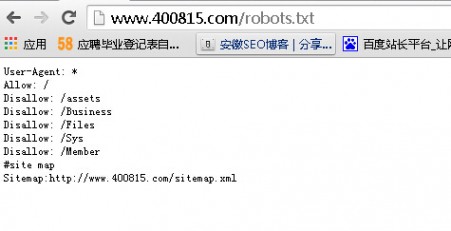
导读:首先我们要了解什么是robots文件,比如,在安徽人才库的首页网址后面加入“/robots.txt”,即可打开该网站的robots文件,如图所示,文件里显示的内容是要告诉搜索引擎哪些网页希望被抓取,哪些不希望被抓取。因为网站中有一些无关紧要的网页,如“给我留言”或“联系方式”等网页,他们并不参与SEO排名,只是为了给用户看,此时可以利用robots文件把他们屏蔽,即告诉搜索引擎不要抓取该页面。
蜘蛛抓取网页的精力是有限的,即它每次来抓取网站,不会把网站所有文章、所有页面一次性全部抓取,尤其是当网站的内容越来越多时,它每次只能抓取一部分。那么怎样让他在有限的时间和精力下每次抓取更多希望被抓去的内容,从而提高效率呢?
这个时候我们就应该利用robots文件。小型网站没有该文件无所谓,但对于中大型网站来说,robots文件尤为重要,因为这些网站数据库非常庞大,蜘蛛来时,要像对待好朋友一样给它看最重要的东西,因为这个朋友精力有限,每次来都不能把所有的东西看一遍,所以就需要robots文件屏蔽一些无关紧要的东西。由于种种原因,某些文件不想被搜索引擎抓取,如处于隐私保护的内容,也可以用robots文件把搜索引擎屏蔽。
当然,有些人会问,如果robots文件没用好或出错了,会影响整个网站的收录,那为什么还有这个文件呢?这句话中的“出错了”是指将不该屏蔽的网址屏蔽了,导致蜘蛛不能抓取这些页面,这样搜索引擎就不会收录他们,那何谈排名呢?所以robots问价的格式一定要正确。下面我们一起来了解robots文件的用法:
1.“user-agent:*disallow:/”表示“禁止所有搜索引擎访问网站的任何部分”,这相当于该网站在搜索引擎里没有记录,也就谈不上排名。
2.“user-agent:*disallow:”表示“允许所有的robots访问”,即允许蜘蛛任意抓取并收录该网站。这里需要注意,前两条语法之间只相差一个“/”。
3.“user-agent:badbot disallow:/”表示“禁止某个搜索引擎的访问”。
4.“user-agent:baiduspider disallow:user-agent:*disallow:/”表示“允许某个搜索引擎的访问”。这里面的“baiduspider”是百度蜘蛛的名称,这条语法即是允许百度抓取该网站,而不允许其他搜索引擎抓取。
说了这么多,我们来举个例子,某个网站以前是做人才招聘的,现在要做汽车行业的,所以网站的内容要全部更换。删除有关职场资讯的文章,这样就会出现大量404页面、很多死链接,而这些链接以前已经被百度收录,但网站更换后蜘蛛再过来发现这些页面都不存在了,这就会留下很不好的印象。此时可以利用robots文件把死链接全部屏蔽,不让百度访问这些已不存在的页面即可。
最后我们来看看使用robots文件应该注意什么?首先,在不确定文件格式怎么写之前,可以先新建一个文本文档,注意robots文件名必须是robots.txt,其后缀是txt并且是小写的,不可以随便更改,否则搜索引擎识别不了。然后打开该文件,可以直接复制粘贴别人的格式,
Robots文件格式是一条命令一行,下一条命令必须换行。还有,“disallow: ”后面必须有一个空格,这是规范写法。
文章有万马奔腾原创http://www.400815.com,转载请注明。
四 : 搜索引擎抓取系统概述(二)
编者按:之前与大家分享了关于搜索引擎抓取系统中有关抓取系统基本框架、抓取中涉及的网络协议、抓取的基本过程的内容(),今天将于大家分享搜索引擎抓取系统第二部分内容—spider抓取过程中的策略。
spider在抓取过程中面对着复杂的网络环境,为了使系统可以抓取到尽可能多的有价值资源并保持系统及实际环境中页面的一致性同时不给网站体验造成压力,会设计多种复杂的抓取策略。以下简单介绍一下抓取过程中涉及到的主要策略类型:
1、抓取友好性:抓取压力调配降低对网站的访问压力
2、常用抓取返回码示意
3、多种url重定向的识别
4、抓取优先级调配
5、重复url的过滤
6、暗网数据的获取
7、抓取反作弊
8、提高抓取效率,高效利用带宽
1、抓取友好性
互联网资源庞大的数量级,这就要求抓取系统尽可能的高效利用带宽,在有限的硬件和带宽资源下尽可能多的抓取到有价值资源。这就造成了另一个问题,耗费被抓网站的带宽造成访问压力,如果程度过大将直接影响被抓网站的正常用户访问行为。因此,在抓取过程中就要进行一定的抓取压力控制,达到既不影响网站的正常用户访问又能尽量多的抓取到有价值资源的目的。
通常情况下,最基本的是基于ip的压力控制。这是因为如果基于域名,可能存在一 个域名对多个ip(很多大网站)或多个域名对应同一个ip(小网站共享ip)的问题。实际中,往往根据ip及域名的多种条件进行压力调配控制。同时,站长平台也推出了压力反馈工具,站长可以人工调配对自己网站的抓取压力,这时百度spider将优先按照站长的要求进行抓取压力控制。
对同一个站点的抓取速度控制一般分为两类:其一,一段时间内的抓取频率;其二,一段时间内的抓取流量。同一站点不同的时间抓取速度也会不同,例如夜深人静月黑风高时候抓取的可能就会快一些,也视具体站点类型而定,主要思想是错开正常用户访问高峰,不断的调整。对于不同站点,也需要不同的抓取速度。
2、常用抓取返回码示意
简单介绍几种百度支持的返回码:
1) 最常见的404代表“NOT FOUND”,认为网页已经失效,通常将在库中删除,同时短期内如果spider再次发现这条url也不会抓取;
2) 503代表“Service Unavailable”,认为网页临时不可访问,通常网站临时关闭,带宽有限等会产生这种情况。对于网页返回503状态码,百度spider不会把这条url直接删除,同时短期内将会反复访问几次,如果网页已恢复,则正常抓取;如果继续返回503,那么这条url仍会被认为是失效链接,从库中删除。
3) 403代表“Forbidden”,认为网页目前禁止访问。如果是新url,spider暂时不抓取,短期内同样会反复访问几次;如果是已收录url,不会直接删除,短期内同样反复访问几次。如果网页正常访问,则正常抓取;如果仍然禁止访问,那么这条url也会被认为是失效链接,从库中删除。
4)301 代表是“Moved Permanently”,认为网页重定向至新url。当遇到站点迁移、域名更换、站点改版的情况时,我们推荐使用301返回码,同时使用站长平台网站改版工具,以减少改版对网站流量造成的损失。
3、多种url重定向的识别
互联网中一部分网页因为各种各样的原因存在url重定向状态,为了对这部分资源正常抓取,就要求spider对url重定向进行识别判断,同时防止作弊行为。重定向可分为三类:http 30x重定向、meta refresh重定向和js重定向。另外,百度也支持Canonical标签,在效果上可以认为也是一种间接的重定向。
4、抓取优先级调配
由于互联网资源规模的巨大以及迅速的变化,对于搜索引擎来说全部抓取到并合理的更新保持一致性几乎是不可能的事情,因此这就要求抓取系统设计一套合理的抓取优先级调配策略。主要包括:深度优先遍历策略、宽度优先遍历策略、pr优先策略、反链策略、社会化分享指导策略等等。每个策略各有优劣,在实际情况中往往是多种策略结合使用以达到最优的抓取效果。
5、重复url的过滤
spider在抓取过程中需要判断一个页面是否已经抓取过了,如果还没有抓取再进行抓取网页的行为并放在已抓取网址集合中。判断是否已经抓取其中涉及到最核心的是快速查找并对比,同时涉及到url归一化识别,例如一个url中包含大量无效参数而实际是同一个页面,这将视为同一个url来对待。
6、暗网数据的获取
互联网中存在着大量的搜索引擎暂时无法抓取到的数据,被称为暗网数据。一方面,很多网站的大量数据是存在于网络数据库中,spider难以采用抓取网页的方式获得完整内容;另一方面,由于网络环境、网站本身不符合规范、孤岛等等问题,也会造成搜索引擎无法抓取。目前来说,对于暗网数据的获取主要思路仍然是通过开放平台采用数据提交的方式来解决,例如“百度站长平台”“百度开放平台”等等。
7、抓取反作弊
spider在抓取过程中往往会遇到所谓抓取黑洞或者面临大量低质量页面的困扰,这就要求抓取系统中同样需要设计一套完善的抓取反作弊系统。例如分析url特征、分析页面大小及内容、分析站点规模对应抓取规模等等。
本文标题:搜索引擎抓取ajax-极疯坚信:搜索引擎怎么抓取摘要61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1