一 : 说说如何用JavaScript实现一个模板引擎
前言
不知不觉就很长时间没造过什么轮子了,以前一直想自己实现一个模板引擎,只是没付诸于行动,最近终于在业余时间里抽了点时间写了一下。因为我们的项目大部分用的是 swig 或者 nunjucks ,于是就想实现一个类似的模板引擎。

至于为什么要做这么一个东西?基本上每一个做前端的人都会有自己的一个框架梦,而一个成熟的前端框架,模板编译能力就是其中很重要的一环,虽然目前市面上的大部分框架 vue、angular 这些都是属于 dom base 的,而 swig nunjucks ejs这些都是属于 string base 的,但是其实实现起来都是差不多的。不外乎都是 Template =parse=> Ast =render=>String。
再者,做一个模板引擎,个人感觉还是对自身的编码能力的提升还是很有帮助的,在性能优化、正则、字符解析上尤为明显。在日后的业务需求中,如果有一些需要解析字符串相关的需求,也会更得心应手。
功能分析
一个模板引擎,在我看来,就是由两块核心功能组成,一个是用来将模板语言解析为 ast(抽象语法树)。还有一个就是将 ast 再编译成 html。
先说明一下 ast 是什么,已知的可以忽略。
抽象语法树(abstract syntax tree或者缩写为AST),或者语法树(syntax tree),是源代码的抽象语法结构的树状表现形式,这里特指编程语言的源代码。树上的每个节点都表示源代码中的一种结构。之所以说语法是“抽象”的,是因为这里的语法并不会表示出真实语法中出现的每个细节。比如,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现;而类似于if-condition-then这样的条件跳转语句,可以使用带有两个分支的节点来表示。
在实现具体逻辑之前,先决定要实现哪几种 tag 的功能,在我看来,for,if else,set,raw还有就是基本的变量输出,有了这几种,模板引擎基本上也就够用了。除了 tag,还有就是 filter 功能也是必须的。
构建 AST
我们需要把模板语言解析成一个又一个的语法节点,比如下面这段模板语言:
{% if test > 1 %} {{ test }} {% endif %}
很明显,div 将会被解析为一个文本节点,然后接着是一个块级节点 if ,然后 if 节点下又有一个变量子节点,再之后有是一个 的文本节点,用 json 来表示这个模板解析成的 ast 就可以表示为:
[ { type: 1, text: ' '
}, { type: 2, tag: 'if', item: 'test > 1', children: [{ type: 3, item: 'test' }] }, { type: 1, text: '' }] 基本上就分成三种类型了,一种是普通文本节点,一种是块级节点,一种是变量节点。那么实现的话,就只需要找到各个节点的文本,并且抽象成对象即可。一般来说找节点都是根据模板语法来找,比如上面的块级节点以及变量节点的开始肯定是{%或者{{,那么就可以从这两个关键字符下手:
...const matches = str.match(/{{|{%/);const isBlock = matches[0] === '{%';const endIndex = matches.index;...
通过上面一段代码,就可以获取到处于文本最前面的{{或者{%位置了。
既然获取到了第一个非文本类节点的位置,那么该节点位置以前的,就都是文本节点了,因此就已经可以得到第一个节点,也就是上面的
了。
获取到 div 文本节点后,我们也可以知道获取到的第一个关键字符是{%,也就是上面的endIndex是我们要的索引,记得要更新剩余的字符,直接通过 slice 更新即可:
// 2 是 {% 的长度str = str.slice(endIndex + 2);
而此时我们就可以知道匹配到的当前关键字符是{%,那么他的闭合处就肯定是%},因此就可以再通过
const expression = str.slice(0, str.indexOf('%}'))
获取到 if test > 1 这个字符串了。然后我们再通过正则/^ifs+([sS]+)$/匹配,就可以知道这个字符串是 if 的标签,同时可以获得test > 1这一个捕获组,然后就可以创建我们的第二个节点,if 的块级节点了。
因为 if 是个块级节点,那么继续往下匹配的时候,在遇到 {% endif %} 之前的所有节点,都是属于 if 节点的子节点,所以我们在创建节点时要给它一个children数组属性,用来保存子节点。
紧接着再重复上面的操作,获取下一个{%以及{{的位置,跟上面的逻辑差不多,获取到{{的位置后再判断}}的位置,就可以创建第三个节点,test 的变量节点,并且 push 到 if 节点的子节点列表中。
创建完变量节点后继续重复上述操作,就能够获取到{% endif %}这个闭合节点,当遇到该节点之后的节点,就不能保存到 if 节点的子节点列表中了。紧接着就又是一个文本节点。
相对比较完整的实现如下:
const root = [];let parent;function parse(str){ const matches = str.match(/{{|{%/); const isBlock = matches[0] === '{%'; const endIndex = matches.index; const chars = str.slice(0, matches ? endIndex : str.length); if(chars.length) { ...创建文本节点 } if(!matches) return; str = str.slice(endIndex + 2); const leftStart = matches[0]; const rightEnd = isBlock ? '%}' : '}}'; const rightEndIndex = str.indexOf(rightEnd); const expression = str.slice(0, rightEndIndex) if(isBlock) { ...创建块级节点 el parent = el; } else { ...创建变量节点 el } (parent ? parent.children : root).push(el); parse(str.slice(rightEndIndex + 2));}
当然,具体实现起来还是有其他东西要考虑的,比如一个文本是{% {{ test }},就要考虑到{%的干扰等。还有比如 else 还有 elseif 节点的处理,这两个是需要关联到 if 标签上的,这个也是需要特殊处理的。不过大概逻辑基本上就是以上。
组合 html
创建好 ast 后,要渲染 html 的时候,就只需要遍历语法树,根据节点类型做出不同的处理即可。
比如,如果是文本节点,就直接html += el.text即可。如果是if节点,则判断表达式,比如上面的test > 1,有两种办法可以实现表达式的计算,一种就是eval,还有一种就是new Function了,eval 会有安全性问题,因此就不考虑了,而是使用new Function的方式来实现。变量节点的计算也一样,用new Function来实现。
封装后具体实现如下:
function computedExpression(obj, expression) { const methodBody = `return (${expression})`; const funcString = obj ? `with(__obj__){ ${methodBody} }` : methodBody; const func = new Function('__obj__', funcString); try { let result = func(obj); return (result === undefined || result === null) ? '' : result; } catch (e) { return ''; }}
使用 with ,可以让在 function 中执行的语句关联对象,比如
with({ a: '123' }) { console.log(a); // 123}
虽然 with 不推荐在编写代码的时候使用,因为会让 js 引擎无法对代码进行优化,但是却很适合用来做这种模板编译,会方便很多。包括 vue 中的 render function 也是用 with 包裹起来的。不过 nunjucks 是没有用 with 的,它是自己来解析表达式的,因此在 nunjucks 的模板语法中,需要遵循它的规范,比如最简单的条件表达式,如果用 with 的话,直接写{{ test ? 'good' : 'bad' }},但是在 nunjucks 中却要写成�{{ 'good' if test else 'bad' }}。
anyway,各有各的好吧。
实现多级作用域
在将 ast 转换成 html 的时候,有一个很常见的场景就是多级作用域,比如在一个 for 循环中再嵌套一个 for 循环。而如何在做这个作用域分割,其实也是很简单,就是通过递归。
比如我的对一个 ast 树的处理方法命名为:processAst(ast, scope),再比如最初的 scope 是
{ list: [ { subs: [1, 2, 3] }, { subs: [4, 5, 6] } ] } 那么 processAst 就可以这么实现:
function processAst(ast, scope) { ... if(ast.for) { const list = scope[ast.item]; // ast.item 自然就是列表的 key ,比如上面的 list list.forEach(item => { processAst(ast.children, Object.assign({}, scope, { [ast.key]: item, // ast.key 则是 for key in list 中的 key })) }) } ...}
就简单通过一个递归,就可以把作用域一直传递下去了。
Filter 功能实现
实现上面功能后,组件就已经具备基本的模板渲染能力,不过在用模板引擎的时候,还有一个很常用的功能就是 filter 。一般来说 filter 的使用方式都是这这样 {{ test | filter1 | filter2 }},这个的实现也说一下,这一块的实现我参考了 vue 的解析的方式,还是蛮有意思的。
还是举个例子:
{{ test | filter1 | filter2 }} 在构建 AST 的时候,就可以获取到其中的test | filter1 | filter2,然后我们可以很简单的就获取到 filter1 和 filter2 这两个字符串。起初我的实现方式,是把这些 filter 字符串扔进 ast 节点的 filters 数组中,在渲染的时候再一个一个拿出来处理。
不过后来又觉得为了性能考虑,能够在 AST 阶段就能做完的工作就不要放到渲染阶段了。因此就改成 vue 的方法组合方式。也就是把上面字符串变成:
_$f('filter2', _$f('filter1', test))
预先用个方法包裹起来,在渲染的时候,就不需要再通过循环去获取 filter 并且执行了。具体实现如下:
const filterRE = /(?:|s*w+s*)+$/;const filterSplitRE = /s*|s*/;function processFilter(expr, escape) { let result = expr; const matches = expr.match(filterRE); if (matches) { const arr = matches[0].trim().split(filterSplitRE); result = expr.slice(0, matches.index); // add filter method wrapping utils.forEach(arr, name => { if (!name) { return; } // do not escape if has safe filter if (name === 'safe') { escape = false; return; } result = `_$f('${name}', ${result})`; }); } return escape ? `_$f('escape', ${result})` : result;}
上面还有一个就是对 safe 的处理,如果有 safe 这个 filter ,就不做 escape 了。完成这个之后,有 filter 的 variable 都会变成_$f('filter2', _$f('filter1', test))这种形式了。因此,此前的 computedExpression 方法也要做一些改造了。
function processFilter(filterName, str) { const filter = filters[filterName] || globalFilters[filterName]; if (!filter) { throw new Error(`unknown filter ${filterName}`); } return filter(str);}function computedExpression(obj, expression) { const methodBody = `return (${expression})`; const funcString = obj ? `with(_$o){ ${methodBody} }` : methodBody; const func = new Function('_$o', '_$f', funcString); try { const result = func(obj, processFilter); return (result === undefined || result === null) ? '' : result; } catch (e) { // only catch the not defined error if (e.message.indexOf('is not defined') >= 0) { return ''; } else { throw e; } }}
其实也是很简单,就是在 new Function 的时候,多传入一个获取 filter 的方法即可,然后有 filter 的 variable 就能被正常识别解析了。
至此,AST 构建、AST 到 html 的转换、多级作用域以及 Filter 的实现,都已经基本讲解完成。
贴一下自己实现的一个模板引擎轮子:https://github.com/whxaxes/mus
算是实现了大部分模板引擎该有的功能,欢迎各路豪杰 star 。
二 : 如何使用谷歌按图片搜索功能
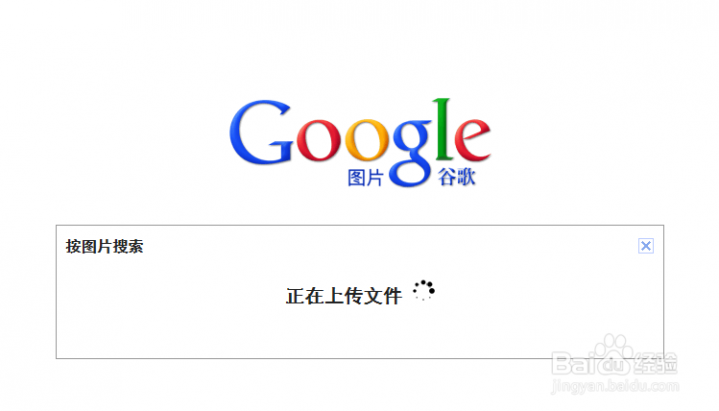
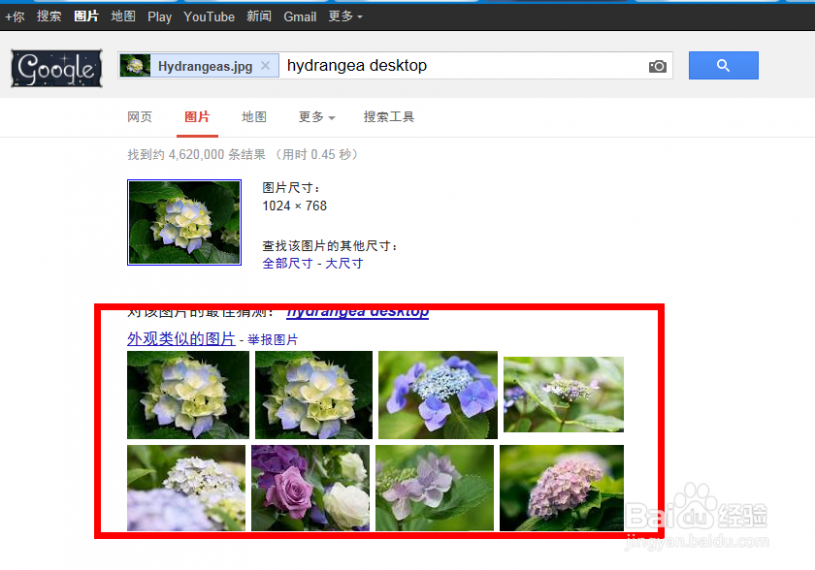
[google图片搜索]如何使用谷歌按图片搜索功能——简介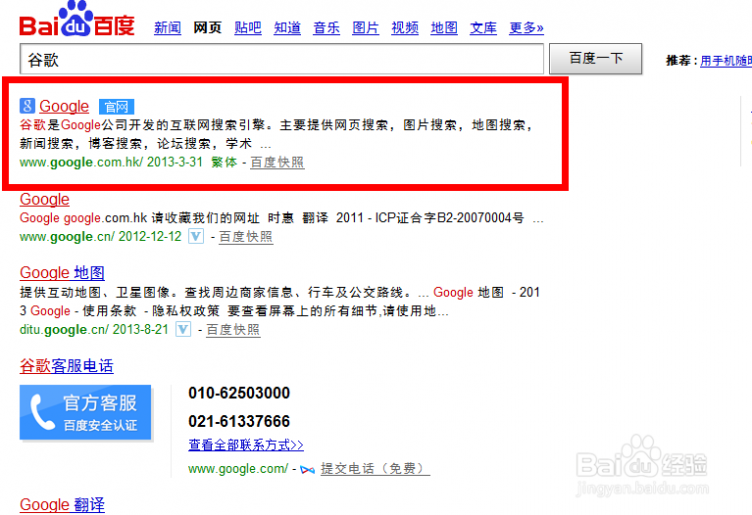
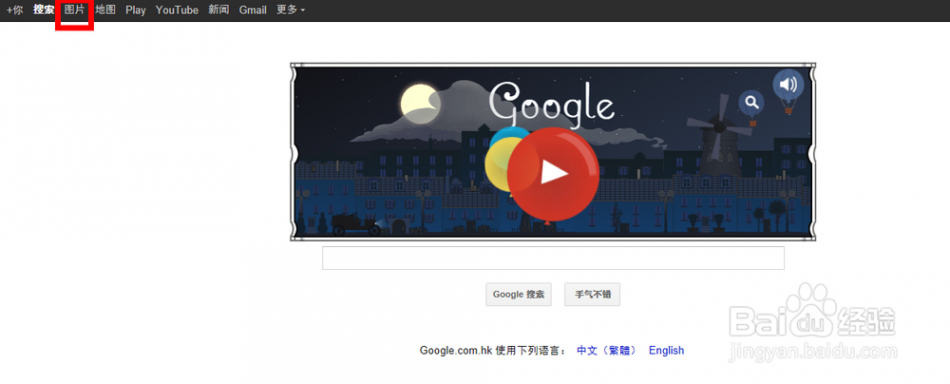
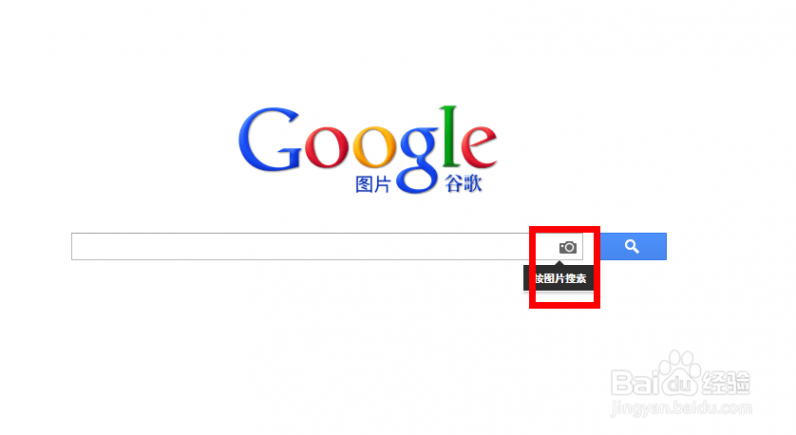
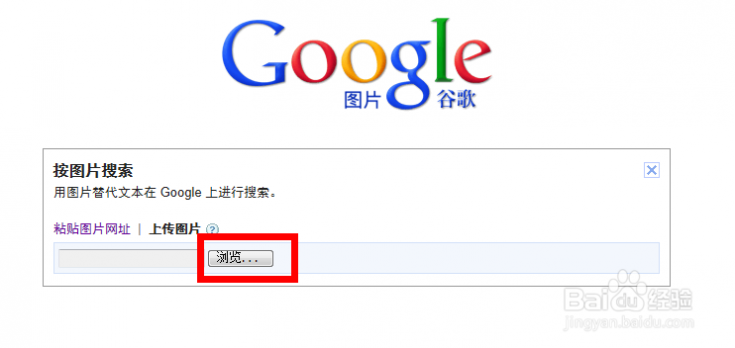

三 : 如何用歌词搜索歌曲
[歌词搜索歌曲]如何用歌词搜索歌曲——简介 [歌词搜索歌曲]如何用歌词搜索歌曲——知识点
[歌词搜索歌曲]如何用歌词搜索歌曲——知识点
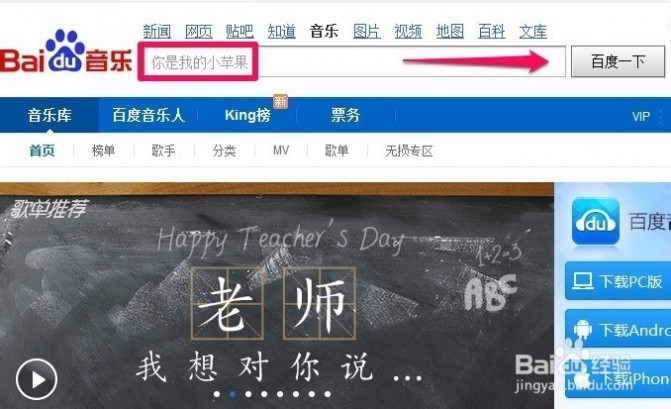
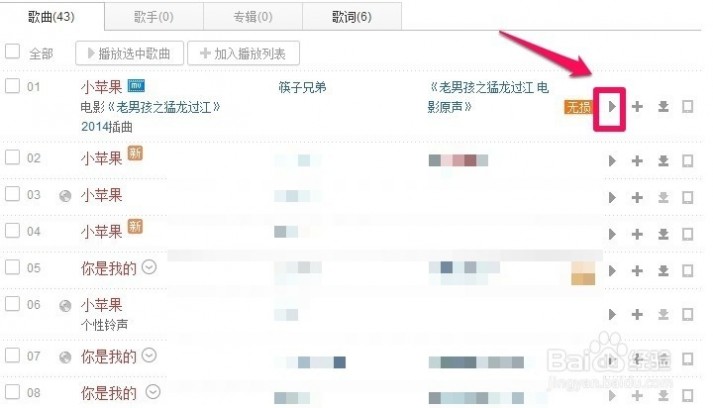
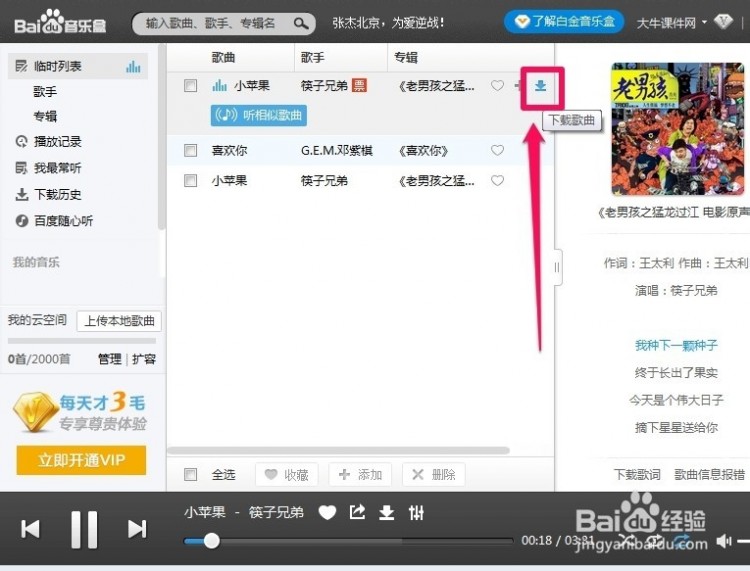
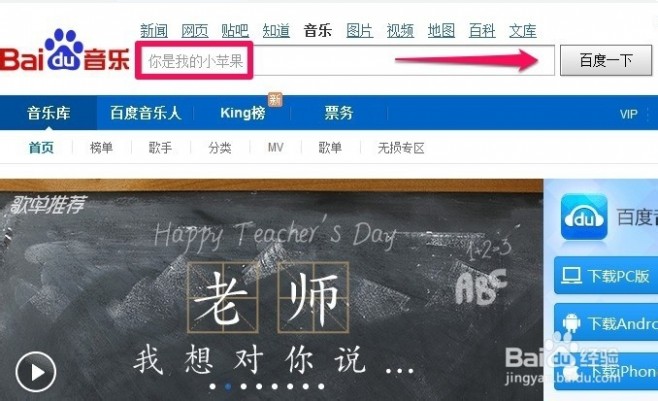 [歌词搜索歌曲]如何用歌词搜索歌曲——注意事项
[歌词搜索歌曲]如何用歌词搜索歌曲——注意事项四 : 如何用好 Google 等搜索引擎?
[谷歌搜索引擎]如何用好 Google 等搜索引擎?网友崔凯对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
搜索引擎命令大全!
1、双引号
把搜索词放在双引号中,代表完全匹配搜索,也就是说搜索结果返回的页面包含双引号中出现的所有的词,连顺序也必须完全匹配。bd和Google 都支持这个指令。例如搜索: “seo方法图片”
2、减号
减号代表搜索不包含减号后面的词的页面。使用这个指令时减号前面必须是空格,减号后面没有空格,紧跟着需要排除的词。Google 和bd都支持这个指令。
例如:搜索 -引擎
返回的则是包含“搜索”这个词,却不包含“引擎”这个词的结果
3、星号
星号*是常用的通配符,也可以用在搜索中。百度不支持*号搜索指令。
比如在Google 中搜索:搜索*擎
其中的*号代表任何文字。返回的结果就不仅包含“搜索引擎”,还包含了“搜索收擎”,“搜索巨擎”等内容。
4、inurl
inurl: 指令用于搜索查询词出现在url 中的页面。bd和Google 都支持inurl 指令。inurl 指令支持中文和英文。
比如搜索:inurl:搜索引擎优化
返回的结果都是网址url 中包含“搜索引擎优化”的页面。由于关键词出现在url 中对排名有一定影响,使用inurl:搜索可以更准确地找到竞争对手。
5、inanchor
inanchor:指令返回的结果是导入链接锚文字中包含搜索词的页面。百度不支持inanchor。
比如在Google 搜索 :inanchor:点击这里
返回的结果页面本身并不一定包含“点击这里”这四个字,而是指向这些页面的链接锚文字中出现了“点击这里”这四个字。
可以用来找到某个关键词的竞争对收,而且这些竞争对手往往是做过SEO 的。研究竞争对手页面有哪些外部链接,就可以找到很多链接资源。
6、intitle
intitle: 指令返回的是页面title 中包含关键词的页面。Google 和bd都支持intitle 指令。
使用intitle 指令找到的文件是更准确的竞争页面。如果关键词只出现在页面可见文字中,而没有出现在title 中,大部分情况是并没有针对关键词进行优化,所以也不是有力的竞争对手。
7、allintitle
allintitle:搜索返回的是页面标题中包含多组关键词的文件。
例如 :allintitle:SEO 搜索引擎优化
就相当于:intitle:SEO intitle:搜索引擎优化
返回的是标题中中既包含“SEO”,也包含“搜索引擎优化”的页面
8、allinurl
与allintitle: 类似。
allinurl:SEO 搜索引擎优化
就相当于 :inurl:SEO inurl:搜索引擎优化
9、filetype
用于搜索特定文件格式。Google 和bd都支持filetype 指令。
比如搜索filetype:pdf SEO
返回的就是包含SEO 这个关键词的所有pdf 文件。
10、site
site:是SEO 最熟悉的高级搜索指令,用来搜索某个域名下的所有文件。
11、linkdomain
linkdomain:指令只适用于雅虎,返回的是某个域名的反向链接。雅虎的反向链接数据还比较准
确,是SEO 人员研究竞争对手外部链接情况的重要工具之一。
比如搜索
linkdomain:http://cnseotool.com-site:http://cnseotool.com
得到的就是点石网站的外部链接,因为-site:http://cnseotool.com已经排除了点石本身的页面,也就是内部
链接,剩下的就都是外部链接了。
12、related
related:指令只适用于Google,返回的结果是与某个网站有关联的页面。比如搜索
related:http://cnseotool.com
我们就可以得到Google 所认为的与点石网站有关联的其他页面。 这种关联到底指的是什么,Google 并没有明确说明,一般认为指的是有共同外部链接的网站。
上面介绍的这几个高级搜索指令,单独使用可以找到不少资源,或者可以更精确地定位竞争对
手。把这些指令混合起来使用则更强大。
inurl:gov 减肥
返回的就是url 中包含gov,页面中有“减肥”这个词的页面。很多SEO 人员认为GVM和学校网
站有比较高的权重,找到相关的GVM和学校网站,就找到了最好的链接资源。
下面这个指令返回的是来自.中国教育和科研计算机网CERNET,也就是学校域名上的包含“交换链接”这个词的页面:
inurl:.中国教育和科研计算机网CERNET交换链接
从中SEO 人员可以找到愿意交换链接的学校网站。
或者使用一个更精确的搜索:
inurl:.中国教育和科研计算机网CERNETintitle:交换链接
返回的则是来自中国教育和科研计算机网CERNET域名,标题中包含“交换链接”这四个字的页面,返回的结果大部分应
该是愿意交换链接的学校网站。
再比如下面这个指令:
inurl:中国教育和科研计算机网CERNET*register
返回的结果是在.中国教育和科研计算机网CERNET域名上,url 中包含“forum”以及“register”这两个单词的页面,也就是
学校论坛的注册页面。找到这些论坛,也就找到了能在高权重域名上留下签名的很多机会。
下面这个指令返回的是页面与减肥有关,url 中包含links 这个单词的页面:
减肥 inurl:links
很多站长把交换链接页面命名为links.html 等,所以这个指令返回的就是与减肥主题相关的交换
链接页面。
下面这个指令返回的是url 中包含http://gov.cn以及links 的页面,也就是GVM域名上的交换链接页面:
allinurl:gov.cn+links
最后一个例子,在雅虎搜索这个指令:
linkdomain:http://cnseotool.com-linkdomain:http://cnseotool.com
返回的是链接到点石网站,却没有链接到我的博客的网站。使用这个指令可以找到很多连向你
的竞争对手或其他同行业网站,却没连向你的网站的页面,这些网站是最好的链接资源。
高级搜索指令组合使用变化多端,功能强大。一个合格的SEO必须熟练掌握这几个常用指令的
意义及组合方法,才能更有效率地找到更多竞争对手和链接资源。
找外链的时候你可以用这几种命令组合,例如site:.com inurl:blog “post a comment” -”comments closed” -”you must be logged in” “输入你的关键词“,
site:.com 是 指, 只显示.com的网站。 如果你想要 org的链接,就换成 site:.org,inurl:blog 是指博客。
“post a comment” -”comments closed” -”you must be logged in” 是指, “能够写评论的” 减去“ 关闭评论的” 再减去“ 必须要登录才能写评论的”。
大家还有什么更高级的命令可以补充!!!!
转载 !!!
网友Raymond Wang对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
我曾给所里的律师助理多次培训如何利用Google进行法律检索、核查事实和证据挖掘,可以分享一点心得。
(1)首先要掌握工具,包括熟悉常见的Google语法(如""、site、filetype)和工具(如图片搜索、Google Alert、Google Trends)。关于基本语法,请见附图。
(2)其次要积累关键字。每个专业领域内都有一些专业术语,而这些术语出现在媒体或口语中都是俗称,要想查到高质量的结果,就要有把术语和俗称进行转换的能力。另外,经过长期检验,有一些专家和记者非常靠谱,在搜索问题时同时加入他们的名字,得到的结果质量会高很多。
(3)掌握了工具和关键字后,要知道二者如何配合使用。比如需要查找一份政府文件,如果知道准确的文件名,就可以加半角引号进行精确检索;但如果不知道准确名称,就可以用site语法只在政府网站内用相关关键字查询,而不是在全网大海捞针。什么时候需要扩大搜索范围,什么时候需要缩小搜索范围,是使用具体语法,还是减少或增加关键字,都需要经验的积累。如果每次搜索时都有意识的、层层推进的而不是盲目的,分析问题的能力也会有提高。
虽然有质量很高的收费法律数据库可以用,我还是很喜欢用Google进行搜索,因为随着搜索次数的增加,搜索效率是能够不断提升的。关键就是要不断总结,查到了以后要“复盘”,看看有没有更快更准确的方法,查不到要思考为什么查不到,隔一段时间换别的语法或关键字再试试。
附:转自http://kaijuan.org/%E6%96%87%E4%BB%B6:%E4%BF%A1%E6%81%AF%E5%9B%BE-%E4%BB%8E%E8%B0%B7%E6%AD%8C%E6%90%9C%E8%8E%B7%E6%9B%B4%E5%A4%9A.png
网友曾少贤对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
超级多图,流量党自求多福。
1、为什么Google已死,你还要写这些东西?
第一:我怀旧,每次用Google都好像让我回到大学的时光;
第二:不爽原本是自己拥有的选择权,却被人毫无道理地剥夺,越得不到的,人们越想得到。
第三:个人比较喜欢简单粗暴,崇尚搜索即答案。没办法,就是这么任性。
2、看完之后我能学到什么?
第一:让你明白什么是简单粗暴;
第二:明白Google不单单是一个搜索引擎而已,还有很多东西你或许不知道;
第三:让你装地一手好B。
3、需要准备什么?
第一:你要能用Google Search,具体怎么做,请出门左转去果壳。
第二:很多情况下如果搜索不出来的话,请将系统语言更换成英语。
下面的正文分为四大类:
第一:日常生活类
第二:一个学霸的Google素养
第三:万万没想到的搜索结果
第四:彩蛋
一、日常生活类。
1、搜索语法:weather/time/sunrise/sundown+城市名(英语)。
即时结果:返回各个城市的天气/所在时区的时间/日出时间/日落时间。
例如:weather/time/sunrise/sundown guangzhou(广州),就可以即时看到广州的天气、时间、日出日落时间。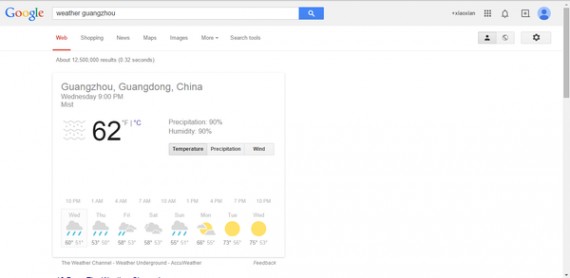 广州的天气,一夜入冬冷趴了~~~~~~~~~~~~广州的天气,一夜入冬冷趴了~~~~~~~~~~~~
广州的天气,一夜入冬冷趴了~~~~~~~~~~~~广州的天气,一夜入冬冷趴了~~~~~~~~~~~~ 广州现在的时间。广州现在的时间。
广州现在的时间。广州现在的时间。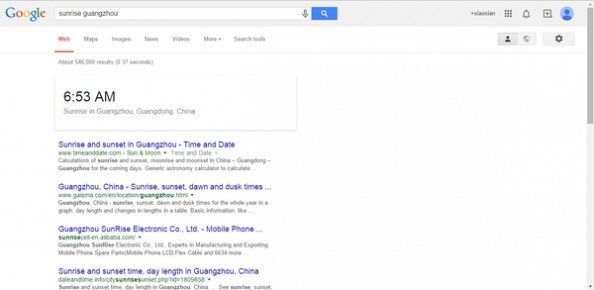 广州日出的时间。广州日出的时间。
广州日出的时间。广州日出的时间。 广州日落的时间。广州日落的时间。
广州日落的时间。广州日落的时间。
2、搜索语法:歌手名字(英语)+music/songs
即时结果:返回歌手的各首歌曲。
例如:Jay Chow music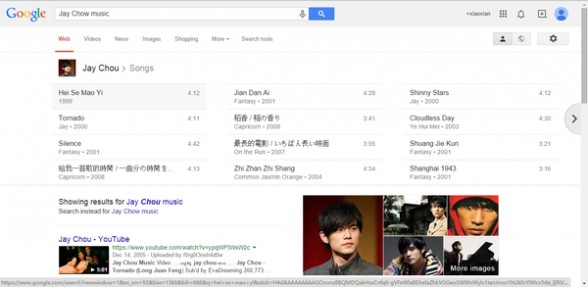 周杰伦的歌单。周杰伦的歌单。
周杰伦的歌单。周杰伦的歌单。
3、搜索语法:国家(英语)/省+capital
即时结果:返回这个国家的首都或者省会
例如:Guangdong capital,广东的省会即为广州。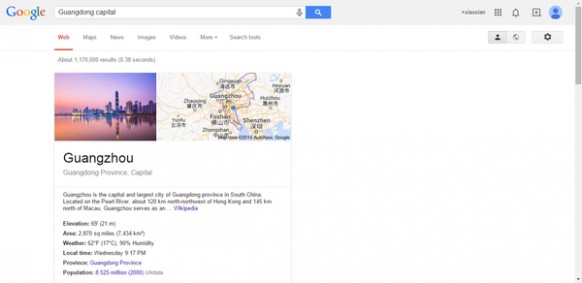
4、搜索语法:[货币一]+in+[货币二]
即时结果:返回货币一可以兑换多少货币二,还能给出汇率的走势。
你也可以在搜索栏中直接将各种货币相加,e.g:100usd+50eur+250inr=rmb,就可以直接得出多少人民币。
例如:1 usd in rmb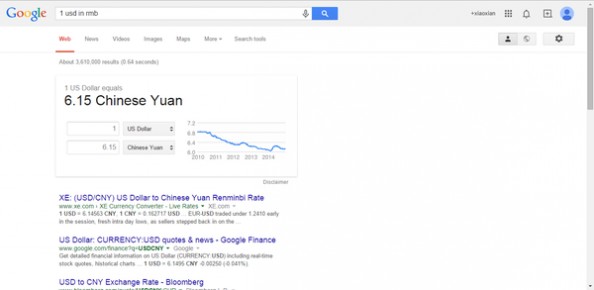 1美元可以兑换6.15元人民币。1美元可以兑换6.15元人民币。
1美元可以兑换6.15元人民币。1美元可以兑换6.15元人民币。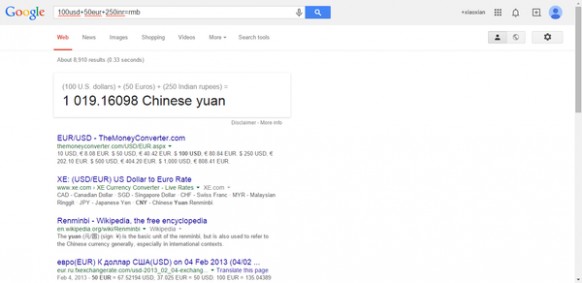 100美元加50欧元加250元印度货币等于1019.16元人民币。100美元加50欧元加250元印度货币等于1019.16元人民币。
100美元加50欧元加250元印度货币等于1019.16元人民币。100美元加50欧元加250元印度货币等于1019.16元人民币。
5、搜索语法:Set timer XX seconds/minutes/hours,XX表示具体的数字。
即时结果:设置XX秒/分/小时的计时器。
例如:set timer 30 minutes,设置倒数时间为30分钟的计时器。
6、搜索语法:城市名+to+城市名+distance
即时结果:返回两个城市相距的距离。
例如:Paris to Rome distance,即时看到巴黎到罗马的距离。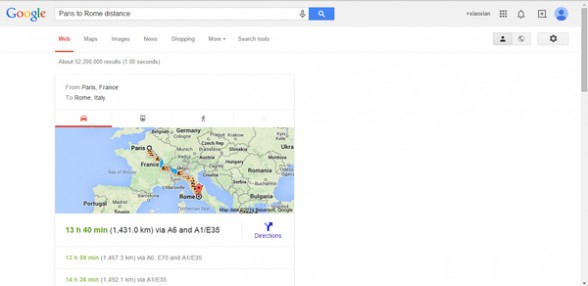
7、搜索语法:what's my location/IP
即时结果:返回你所在的地址以及电脑的IP地址。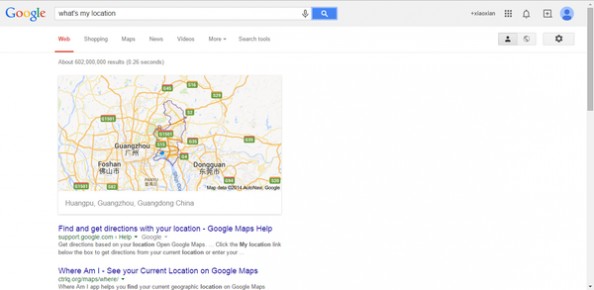 我的地址,这个范围有点大,所以看看就好,因为你找不到我哈哈哈。我的地址,这个范围有点大,所以看看就好,因为你找不到我哈哈哈。
我的地址,这个范围有点大,所以看看就好,因为你找不到我哈哈哈。我的地址,这个范围有点大,所以看看就好,因为你找不到我哈哈哈。 我的IP地址,就是简单粗暴啊。我的IP地址,就是简单粗暴啊。
我的IP地址,就是简单粗暴啊。我的IP地址,就是简单粗暴啊。
二、一个学霸的Google素养
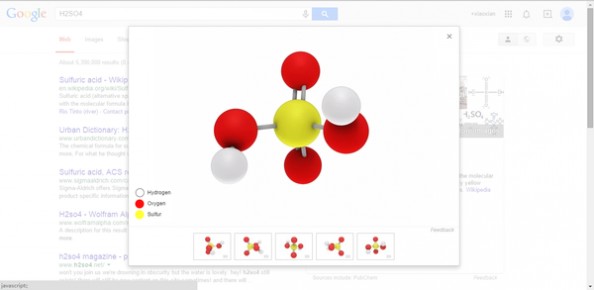
1、化学成分3D显示。
在搜索栏搜索你想要的化学名称,例如硫酸(H2SO4),点击下面第一张图中红色方框中的3D选项,就可以查看该化学成分的3D动态立体效果。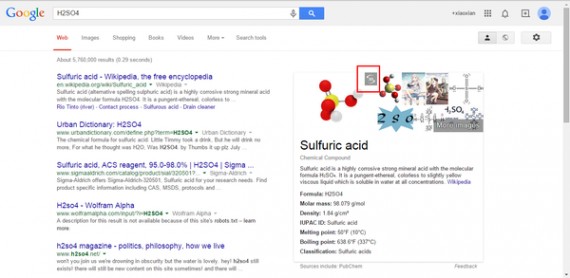
2、各国的GDP增长率
搜索语法:country GDP growth。例如搜索“Japan GDP growth”和“China GDP growth”。嗯,不错,一对比就知道我天朝一派欣欣向荣。(数据来源于世界银行,怒赞!)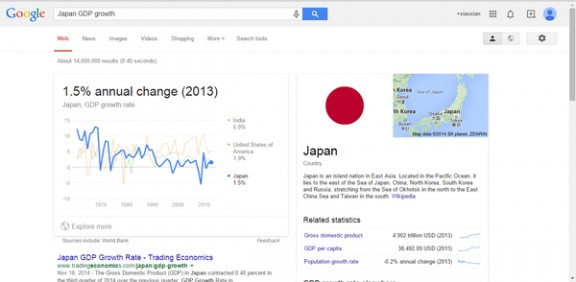 日本的GDP增长率。日本的GDP增长率。
日本的GDP增长率。日本的GDP增长率。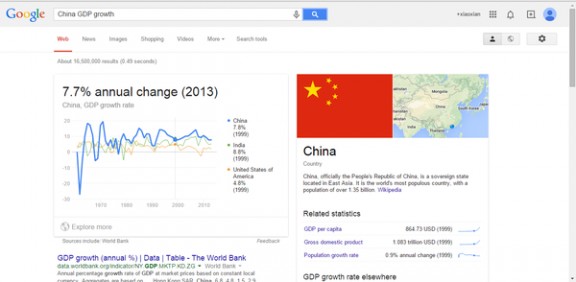 中国的GDP增长率。中国的GDP增长率。
中国的GDP增长率。中国的GDP增长率。
3、绘制多元方程以及复杂的方程式
搜索语法:graph for+方程式子
例如:graph for x^8,graph for sin(x)+tan(x),graph for x^8+y^8。请你多多探索。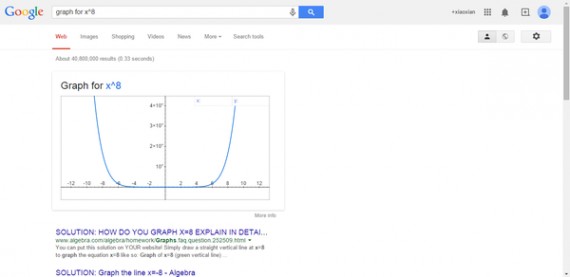 graph for x^8的图形。graph for x^8的图形。
graph for x^8的图形。graph for x^8的图形。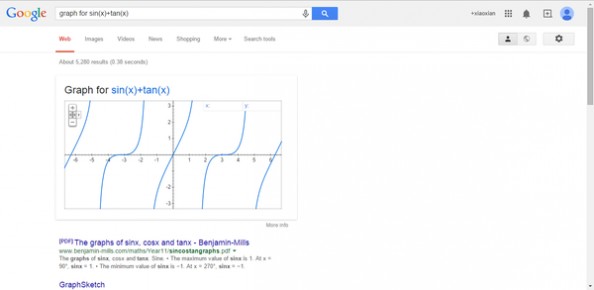 graph for sin(x)+tan(x)的图形。graph for sin(x)+tan(x)的图形。
graph for sin(x)+tan(x)的图形。graph for sin(x)+tan(x)的图形。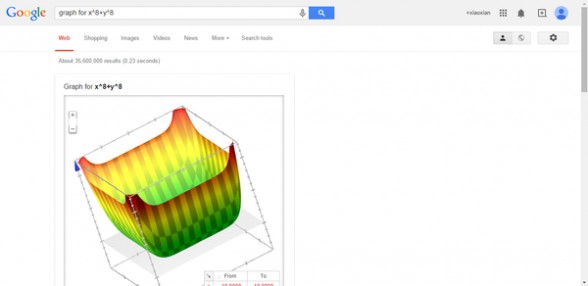
graph for x^8+y^8的3D动态立体图形,这个必须给赞。
4、食物对比
搜索语法:水果名称(英文)VS水果名称(英文)。
例如:durian vs banana,榴莲对比香蕉。你就可以看到两种水果组成成分的对比。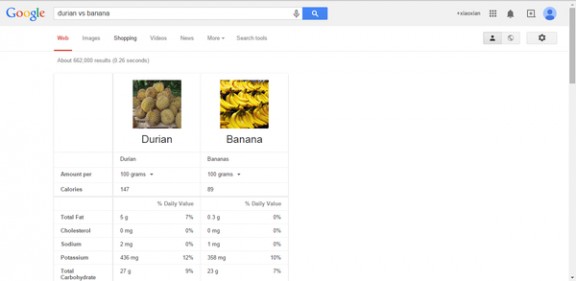
5、追踪词汇的来源以及演变
搜索语法:Word etymology,word代表你想要搜索的单词。
例如:coffee etymology。你就可以看到咖啡这个单词是怎么演变的了。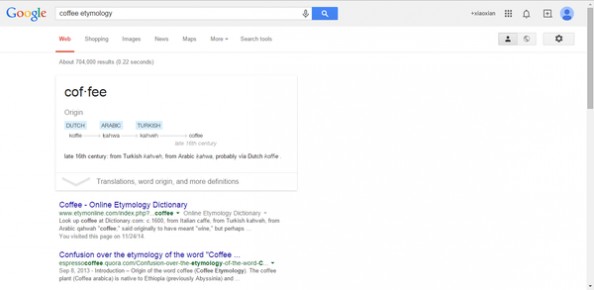
三、万万没想到的搜索结果
1、搜索“399999999999999-399999999999998”。你将会得到0。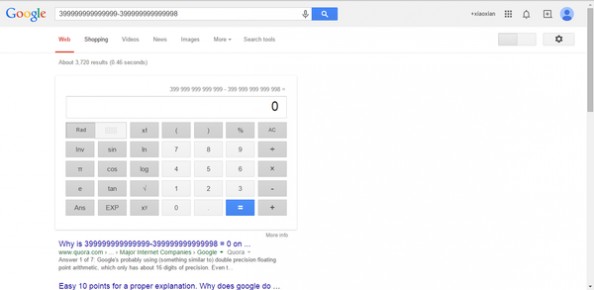
2、搜索“do a barrel roll”或者“Z or R twice”,让你的页面旋转360°
3、搜索”the Answer to Life, the Universe and Everything”。生命,宇宙以及一切的答案是什么?是42!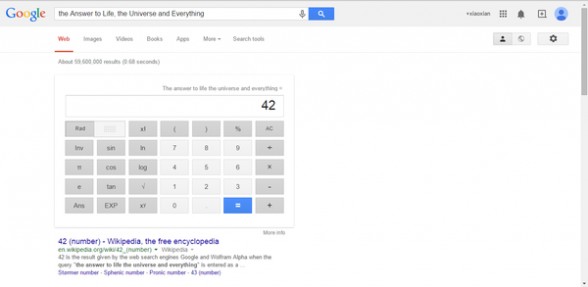
4、搜索”zerg rush”。会从页面上方降下很多圆圈,每个圆圈你都要三击它们才会将它们消灭,不然随着圆圈的降落,它们会把搜索出来的结果一个个融化掉,最后剩下空白的页面。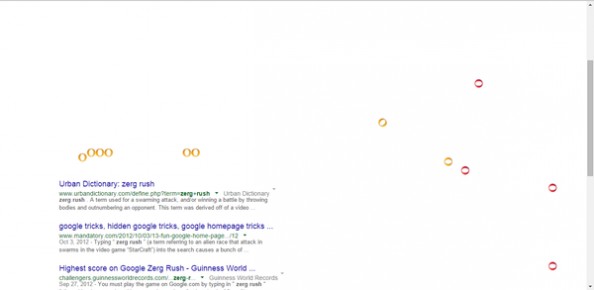 圆圈正在融化搜索结果中。圆圈正在融化搜索结果中。
圆圈正在融化搜索结果中。圆圈正在融化搜索结果中。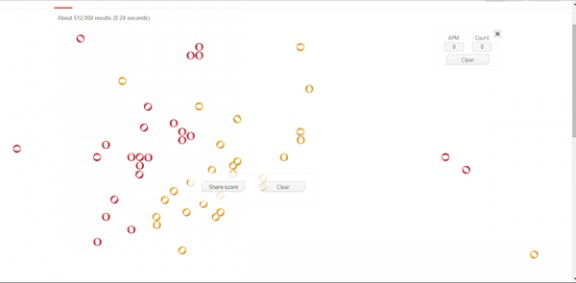 全部融化完毕,剩下空白的页面。全部融化完毕,剩下空白的页面。
全部融化完毕,剩下空白的页面。全部融化完毕,剩下空白的页面。
5、搜索“Google in 1998”,你就可以看到1998年的谷歌究竟是长什么样子的。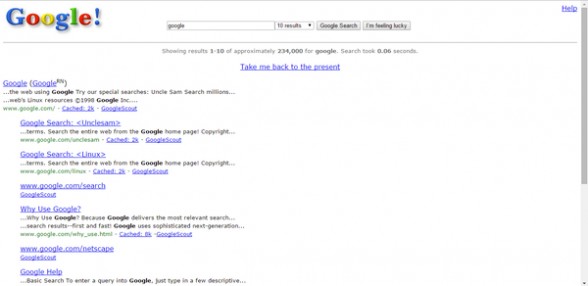
6、搜索“Google Gravity”,让你无视61阅读页
搜寻:“ 易筋经- 吸星大法”
结果:已搜寻有关易筋经- 吸星大法的中文( 简体) 网页。共约有5,440 项查询结果,这是第1-10 项。搜寻用时0.13 秒。
注意:这里的“+” 和“-” 号,是英文字符,而不是中文字符的“ +” 和“ -” 。此外,”+” 或”-“ 两侧的关键字之间不能有空格。比如“ 易筋经- 吸星大法” ,搜寻引擎将视为逻辑“ 与” ,中间的“-” 被忽略。
3. 用大写的“OR” 表示逻辑“ 或” 。但是,关键字为中文的” 或” 查询似乎还有BUG ,无法得到正确的查询结果。
范例:搜寻包含布兰妮“Britney” 或者披头士“Beatles” 、或者两者均有的中文网页。
搜寻:“ britney OR beatles ”
结果:已搜寻有关britney OR beatles的中文( 简体) 网页。共约有14,600 项查询结果,这是第1-10 项。搜寻用时0.08 秒。
搜寻:“ 布兰妮OR 披头士”
结果:找不到和您的查询- 布兰妮OR 披头士- 相符的网页。
注意:小写的“or” ,在查询的时候将被忽略;这样上述的**** 作实际上变成了一次“ 与” 查询。
4. “+” 和“-” 的作用有的时候是相同的,都是为了缩小搜寻结果的范围,提高查询结果命中率。
例:查阅天龙八部具体是哪八部。
分析:如果光用“ 天龙八部” 做关键字,搜寻结果有26,500 项,而且排前列的主要与金庸的小说《天龙八部》相关,很难找到所需要的资讯。可以用两个方法减少无关结果。
如果你知道八部中的某一部,比如阿修罗,增加“ 阿修罗” 关键字,搜寻结果就只有995 项,可以直接找到全部八部,“ 天龙八部 阿修罗” 。如果你不知道八部中的任何一部,但知道这与佛教相关,可以排除与金庸小说相关的记录,查询结果为1,010 项,可以迅速找到需要的资料,“ 天龙八部 佛教- 金庸” 。
1. 不支援万用符号,如“*” 、“?” 等,只能做精确查询,关键字后面的“*” 或者“?” 会被忽略掉。
2. 忽略英文字符大小写,“GOD” 和“god” 搜寻的结果是一样的。
3. 关键字可以是词组(中间没有空格),也可以是句子(中间有空格),但是,用句子做关键字,必须加英文引号。
范例:搜寻包含“long, long ago” 字串的网页。
搜寻:“"long, long ago"”
结果:搜寻"long, long ago". 共约有28,300 项查询结果,这是第1-10 项。搜寻用时0.28 秒。
注意:和搜寻英文关键字串不同的是,GOOGLE 对中文字串的处理并不十分完善。比如,搜寻“" 啊,我的太阳"” ,我们希望结果中含有这个句子,事实并非如此。查询的很多结果,“啊” 、“ 我的” 、“ 太阳” 等词语是完全分开的,但又不是“ 啊 我的 太阳” 这样的与查询。显然,GOOGLE 对中文的支援尚有欠缺之处。
4. 对一些网路上出现频率极高的词(主要是英文单词),如“ i ” 、“com” ,以及一些符号如“*” 、“.” 等,作忽略处理,如果用户必须要求关键字中包含这些常用词,就要用强制语法“+” 。
范例:搜寻包含“Who am I ?” 的网页。如果用“"who am i ?"” ,“Who” 、“I” 、“?” 会被省略掉 ??,搜寻将只用“am” 作关键字,所以应该用强制搜寻。
搜寻:“"+who +am + i "”
结果:搜寻"+who +am + i ". 共约有362,000 项查询结果,这是第1-10 项。搜寻用时0.30 秒。
注意:英文符号(如问号,句号,逗号等)无法成为搜寻关键字,加强制也不行。
关键词的选择在搜寻中起到决定性的作用,所有搜寻技巧中,关键词选择是最基本也是最有效的。
“ 特定词法” 的关键字选择技巧
范例:查找《镜花缘》一书中淑士国酒保的酸话原文。
分析:如果按照一般的思路,找某部小说中的具体段落,就需要用搜寻引擎先找到这本书,然后再翻到该段落。这样做当然可以,但是效率很低。如果了解目标资讯的构成,用一些目标资讯所特有的字词,可以非常迅速的查到所需要的资料。也就是说,高效率的搜寻关键字不一定就是目标资讯的主题。在上面的例子中,酒保谈到酒的浓淡与贵贱的关系时,之乎者也横飞。因此,可以用特定的词语一下子找到目标资料。
搜寻:“ 酒 贵 贱 之” ,OK ,找到的第一条资讯就是镜花缘的这一段落:“ 先生听着:今以酒醋论之,酒价贱之,醋价贵之。因何贱之?为什贵之?真所分之,在其味之。酒昧淡之,故而贱之;醋味厚之,所以贵之。..”
“ 近义词法” 的关键字选择技巧
范例:“ 黄花闺女” 一词中“ 黄花” 是什么意思。
分析:“ 黄花闺女” 是一个约定的俗语,如果只用“ 黄花闺女 黄花” 做关键词,搜寻结果将浩如烟海,没什么价值,因此必须要加更多的关键词,约束搜寻结果。选择什么关键词好呢?备选的有“ 意思” 、“ 含义” 、“ 来历” 、“ 由来” 、“ 典故” 、“ 出典” 、“ 渊源” 等,可以猜到的是,类似的资料,应该包含在一些民俗介绍性的文字里,所以用诸如“ 来历” 、“ 由来” 、“出典” 等词汇的概率更高一些。
搜寻:“ 黄花闺女 黄花 由来” ,查到“ 黄花” 原来出典于《太平御览》,与南朝的寿阳公主相关。如果想获得第一手资料,那就可以用“ 太平御览 寿阳公主” 做搜寻了。
“ 相关词法” 的关键字选择技巧
范例:刘德华的胸围是多少。
分析:首先声明,这是某个MM 要我做的搜寻,我把它作为搜寻案例而已,没其他的意思。非常直接的搜寻是,“ 刘德华 胸围” ,但事实上,这么搜寻出来的结果,尽是一些诸如“ 刘德华取笑莫文蔚胸围太小” 之类的八卦新闻,无法快速得到所需要的资料。可以想到的是,需要的资料应该包含在刘德华的全面介绍性文字中,除了胸围,应该还包括他的身高,体重,生日等一系列相关资讯。这样就可以进一步的增加其他约束性关键词以缩小搜寻范围。
搜寻:“ 刘德华 胸围 身高” ,没有料到的情况发生了,网上炙手可热的痞子蔡《第一次亲密接触》里居然含有这样关键字,阿泰“ 改编自刘德华《忘情水》的变态歪歌” 、“ 用身高体重三围和生日来加以编号” 。好办,把这部小说去掉,“ 刘德华 胸围 身高- 阿泰” ,OK ,结果出来了,华仔胸围84cm 。说明一下,为什么用“ 阿泰” 而不用“ 第一次亲密接触” 呢?这是因为小说的名字被转载的时候可能有变动,但里 ??面角色的名字是不会变的。
1. “site” 表示搜寻结果局限在某个具体网站或者网站频道,如“ sina.com.cn ” 、“ edu.sina.com.cn ” ,或者是某个域名,如“ com.cn ” 、“com” 等等。如果是要排除某网站或者域名范围内的页面,只需用“- 网站/ 域名” 。
范例:搜寻中文教育科研网站(edu.cn)上所有包含“ 金庸” 的页面。
搜寻:“ 金庸 site:edu.cn ”
结果:已搜寻有关金庸 site:edu.cn的中文( 简体) 网页。共约有2,680 项查询结果,这是第1-10 项 。搜寻用时0.31 秒。
范例:搜寻包含“ 金庸” 和“ 古龙” 的中文新浪网站网页,
搜寻:“ 金庸 古龙 site:sina.com.cn ”
结果:已在sina.com.cn搜寻有关金庸 古龙的中文( 简体) 网页。共约有869 项查询结果,这是第1-10 项。搜寻用时0.34 秒。
注意:site 后的冒号为英文字符,而且,冒号后不能有空格,否则,“site:” 将被作为一个搜寻的关键字。此外,网站域名不能有“http” 以及“www” 等,也不能有任何“/” 的目录后显示;网站频道则只局限在“ 频道名. 域名” 方式,而不能是“ 域名/ 频道名” 方式。诸如“ 金庸site:edu.sina.com.cn/1/” 的语法是错误的。
2. “link” 语法返回所有链接到某个URL 地址的网页。
范例:搜寻所有含指向华军软体园www.61k.com 链接的网页。
搜寻:“link:61阅读站相关页面“About Google” 。
Q :如何切换google.com 的初始语言界面?
A :点击搜寻栏右边的“ 使用偏好” ??(Preferences ),选择“ 界面语言” (Interface Language )中你期望的语言,点击最下面的“ 设定使用偏好” ??(Save Preferences )按钮。需要提醒的是,GOOGLE 用cookie 记录这个偏好,所以如果你把浏览器的cookie 功能关掉,就无法进行设定。
Q :如何设定每页搜寻结果显示数量?
A :同上,进入使用偏好,在该页的“ 查看结果” (Number of Results )选择显示结果数,数目越大,显示结果需要的时间越长,预设是10 项。
Q :搜寻到的链接无法打开怎么办?
A :链接无法打开的原因很多,比如网站当机,或者ISP 过滤等,可以点击GOOGLE 的“ 网页快取” 查看在GOOGLE 服务器上的网页缓存。
Q :打开搜寻结果的链接,可是该页面太大,很难找到一下子找到目的资料怎么办?
A :直接打开“ 网页快取” ,GOOGLE 会把关键词用不同颜色标记出来,很容易找到。
网友蒙面大侠对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
其实正常用户一般不会去记这么多的搜索技巧,比如s.f2do.com就很巧妙的把这些技巧直接整合进了自己的产品里,一切的技巧大部分都是因为本身做的不够傻瓜化。让用户直接搜到想搜的内容,搜资源比原来快了好几倍!!多维搜索 - 同时搜索多个维度的数据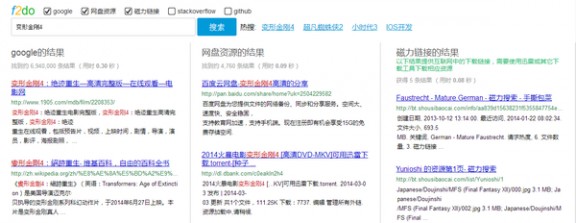
网友卖瓜瓜瓜对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
谷歌搜索中输入
cache:网站名 直接进入快照
譬如:cache:http://baidu.com搜索之
ps:百度好像不行。。。
网友郑维对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
没人提用https访问谷歌的么?
https走的是443端口,且网路上没法监听传送内容。能有效避免搜索结果重置。
网友fiat lux要有光对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
https://support.google.com/websearch/answer/134479?hl=zh-Hans
我觉得最好的搜索指南
网友freestyle对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
贴个搜索语法就成了最高票的答案??!!各大搜索的帮助中心都有的内容啊... 【未经允许不得转载】【未经允许不得转载】
【未经允许不得转载】【未经允许不得转载】
附上线性版的吧
一、强化搜索意识1. 互联网信息时代信息资源非常非常丰富 2.善用搜索可以搜索出很多有价值的东西来,往往可以得到多方面多角度的结果信息 有助于多维度全面思考 3.通过搜索,减弱信息不对称,解决问题 4.在不要求你独立思考的时候运用搜索解决问题是最快速有效的办法!!而且经常有意想不到的收获 5.经常尝试变换关键词搜索些词,往往可以得到意外的不错的收获二、学习常用搜索语法(通用搜索引擎)
, 学习搜索基本常用语法是件低投入高回报的事情
* 通配符 - 排除字词 .. 搜索数字范围 "关键词"或者 《关键词》 精确匹配不拆分关键词 (注:双引号是通用,书名号只用于百度 OR 如果想搜索可能只包含多个搜索字词中某一个的页面,可以在这些字词之间加上OR(大写)。 site:域名 或者 site:.edu 在特定网站或网域中搜索 inurl: 把搜索范围限定在url链接中 新闻url中的某些信息,常常有某种有价值的含义。于是,如果对搜索结果的url做某种限定,就可以获得良好的效果。 intitle:关键词 在特定的网页标题中搜索 info:域名 搜索某网站的相关信息(仅google) info:zhihu.com filetype:文件格式 特定文件搜索 link:域名 搜索链接到某网址的页面 cache:网址 查看网站的缓存版本(仅google) 若用百度直接搜索框键入地址搜索点击百度快照 related: 搜索与某网址相似的页面,查找与您已浏览过的网址类似的网站。当您搜索与Time.com相关的网站时,会找到您可能感兴趣的其他新闻出版物网站。 实在认为搜索语法太高大上反人类 懒得学习应用搜索语法的话 用各大通用搜索引擎的高级搜索吧 基本都包含了以上的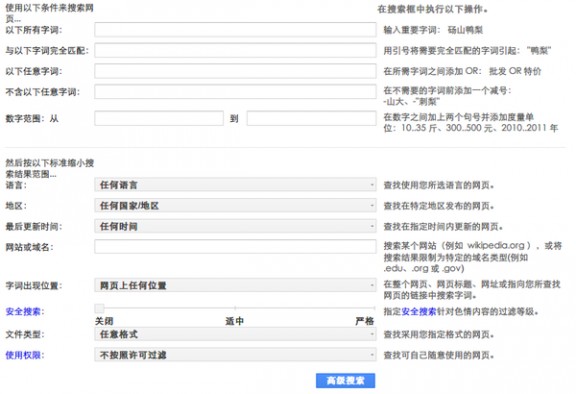 三、优化关键字 1.搜前思考关键词 2.应用搜索语法 3.当给关键词加太多条件时可能出现搜索结果不理想,尝试删减限定词 放宽搜索条件三、优化关键字 1.搜前思考关键词 2.应用搜索语法 3.当给关键词加太多条件时可能出现搜索结果不理想,尝试删减限定词 放宽搜索条件
三、优化关键字 1.搜前思考关键词 2.应用搜索语法 3.当给关键词加太多条件时可能出现搜索结果不理想,尝试删减限定词 放宽搜索条件三、优化关键字 1.搜前思考关键词 2.应用搜索语法 3.当给关键词加太多条件时可能出现搜索结果不理想,尝试删减限定词 放宽搜索条件, 列举一部分,远不止这些...
1.网盘搜索 1).site:pan.baidu.com 资源关键词 2).网盘搜索网站 2.论坛搜索 基本上的领域都有相应论坛,大家交流分享形成了资源信息库 比如手机论坛、电脑相关论坛、跑步论坛、摄影论坛、 各种设计软件论坛、手工论坛、厨艺论坛、地方论坛、金融论坛 、股票论坛等等太丰富了 3.问答搜索:知乎社区已经聚集了大量很有价值的问答 2.论坛搜索 基本上的领域都有相应论坛,大家交流分享形成了资源信息库 比如手机论坛、电脑相关论坛、跑步论坛、摄影论坛、 各种设计软件论坛、手工论坛、厨艺论坛、地方论坛、金融论坛 、股票论坛等等太丰富了 3.问答搜索:知乎社区已经聚集了大量很有价值的问答
2.论坛搜索 基本上的领域都有相应论坛,大家交流分享形成了资源信息库 比如手机论坛、电脑相关论坛、跑步论坛、摄影论坛、 各种设计软件论坛、手工论坛、厨艺论坛、地方论坛、金融论坛 、股票论坛等等太丰富了 3.问答搜索:知乎社区已经聚集了大量很有价值的问答 2.论坛搜索 基本上的领域都有相应论坛,大家交流分享形成了资源信息库 比如手机论坛、电脑相关论坛、跑步论坛、摄影论坛、 各种设计软件论坛、手工论坛、厨艺论坛、地方论坛、金融论坛 、股票论坛等等太丰富了 3.问答搜索:知乎社区已经聚集了大量很有价值的问答 4.电影 书籍介绍评价搜索 豆瓣 亚马逊 5.微博搜索 4.电影 书籍介绍评价搜索 豆瓣 亚马逊 5.微博搜索
4.电影 书籍介绍评价搜索 豆瓣 亚马逊 5.微博搜索 4.电影 书籍介绍评价搜索 豆瓣 亚马逊 5.微博搜索 6.qq空间搜索 6.qq空间搜索
6.qq空间搜索 6.qq空间搜索 7.微信文章搜索 7.微信文章搜索
7.微信文章搜索 7.微信文章搜索 8.识图搜索 8.识图搜索
8.识图搜索 8.识图搜索 9.学习资料搜索 新东方资料中心 9.学习资料搜索 新东方资料中心
9.学习资料搜索 新东方资料中心 9.学习资料搜索 新东方资料中心 10.百度文库 docin等 实践证明在文库中搜索比通用搜索效果要好 11.论文等文献搜索 cnki google scholar 12.偏自然科学的搜索 果壳 13.购物经验/价格等搜索 smzdm等 14.百科搜索 weiki 百度百科等 15.数码产品测评搜索 16.种子搜索五、其它辅助工具 chrome插件Alexa Taffic Rank 搜索结果可靠性辅助工具 10.百度文库 docin等 实践证明在文库中搜索比通用搜索效果要好 11.论文等文献搜索 cnki google scholar 12.偏自然科学的搜索 果壳 13.购物经验/价格等搜索 smzdm等 14.百科搜索 weiki 百度百科等 15.数码产品测评搜索 16.种子搜索五、其它辅助工具 chrome插件Alexa Taffic Rank 搜索结果可靠性辅助工具
10.百度文库 docin等 实践证明在文库中搜索比通用搜索效果要好 11.论文等文献搜索 cnki google scholar 12.偏自然科学的搜索 果壳 13.购物经验/价格等搜索 smzdm等 14.百科搜索 weiki 百度百科等 15.数码产品测评搜索 16.种子搜索五、其它辅助工具 chrome插件Alexa Taffic Rank 搜索结果可靠性辅助工具 10.百度文库 docin等 实践证明在文库中搜索比通用搜索效果要好 11.论文等文献搜索 cnki google scholar 12.偏自然科学的搜索 果壳 13.购物经验/价格等搜索 smzdm等 14.百科搜索 weiki 百度百科等 15.数码产品测评搜索 16.种子搜索五、其它辅助工具 chrome插件Alexa Taffic Rank 搜索结果可靠性辅助工具在插件图标上显示当前页面的Alexa区域及全球排名 以及在google搜索结果页中显示每个链接的alexa排名
六、扩展内容:本地搜索 1.everything 2.listary3. total commander为代表的第三方文件管理器 4.特殊 压缩包内搜索工具 Archive Searcher 包含文档内容的强大搜索 百度/google硬盘搜索等网友lvlvbuaa对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
我所知道和使用的就两点:
1、关键词 不要使用完整的话,尽量使用几个关键词空格隔开
2、得翻墙。我曾经在google搜索一个android开发的问题,然后打开了有八个网站链接,结果都显示 无法链接,但其实那几个网站是没有问题的,都是国内中规中矩的技术网站,当时是凌晨四点,直接崩 溃的想砸了电脑。
顺便吐槽一下百度搜索,同样一个android技术问题,百度居然会给出我得了性病去哪里以及如何有效的治疗的一整套的解决方案。
网友胡江对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
先学会翻-墙再说别的。无它。
网友蒙面大侠对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
首先,
网友陈开城对[谷歌搜索引擎]如何用好 Google 等搜索引擎?给出的答复:
使用非中文语言进行检索,世界很大,中文是个信息孤岛
61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1