一 : 分析搜索引擎是针对网站实际路径来抓取
一个seoer每天都要查看网站的流量,流量来源的域名和页面,用户受访的页面和停留的页面。这是每天必要干的工作,而今天我却意外的发现,统计流量工具把一个受访页面统计成2个受访页面。看到了这个,我有点颤动了,为啥统计成2个呢?我仔细的查看url发现:
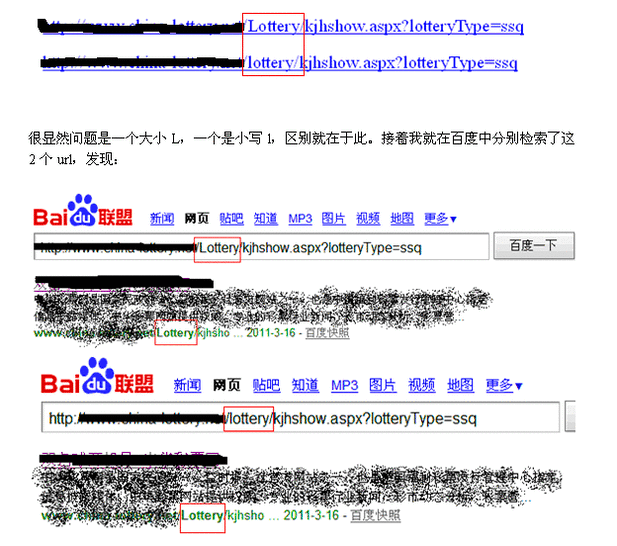
得出结论:无论是小写的l,还是大写的L,收录的全是带有大写L的连接。
也就是说技术是以大写L作为FTP路基的。百度是真对网站的实际路径来抓取的,也验证了这句话了。
解决办法:把带有小l的url换出大写的L的url。虽然这样改了,感觉也是勉强过的去,因为大多数网站的url以小写为主,用户善于用小写搜素。可能其他站长也出现过此问题,如果在网站做之前就布局好,也就不会出现这样一个不该犯的错误了。以下是我总结的url注意事项:
1、 选择静态URL
url静态已经是很多站长认可的,静态对搜素引擎有好处,不过什么事情都不是绝对的。
2、 URL命名规范
url采用统一的大写或者是小写,这个一定要记好。以英文为主。
3、 url链接
url链接以绝对路径为主,首页以www.xxx.com,简单方便。
本文来源:http://www.196tuan.com 沈阳团购导航。
注:相关网站建设技巧阅读请移步到建站教程频道。
二 : 浅析搜索引擎算法的新形势下网站推广该如何进行
那么究竟搜索引擎(百度)新形势下网站该如何推广呢?大家共同来探讨一下吧。
搜索引擎(百度)新规则的出台,非常明确的指出了很多问题,比如百度不喜欢什么样的站点(软文交易平台、软文发布站、软文收益站);不喜欢怎样的优化方式(利用软文来发布大量的外链、堆砌关键词的优化方式);不喜欢低质量的文章(复制、粘贴的文章)等等问题都明确的提出来了,也就说明百度非常的“讨厌”这些问题。同时也告诉大家,这些事情尽量不要去做,没有什么好处的。
而对于一个网站来说,页面含有大量的低质量弹框或者弹窗以及与页面内容相关性非常差的垃圾广告也是百度所“讨厌”的。也就是说如果一个网站存在这些问题,百度是不会给与良好的评价和打分的,也就意味着这个网站不会有很好的排名。因此这对这些搜索引擎新的规则,大家一定要尽量的去避免。
第一,一个新站要上线推广的话,一开始千万不要挂广告。
如果一开始就挂上了大量的广告,会严重的降低搜索引擎对网站的信用度,就像人给人的第一印象一样,第一印象是非常重要的。因此网站上线、刚开始推广的时候千万不要挂广告。因为这是打基础的阶段,如果连基础都打不结实,后期的发展也不会有很大的空间。相信这个道理大家都懂吧。
第二,一个新站上线推广初期,一定要保证文章的质量,也就是说文章最好是原创的。 本来互联网上的文章、资料都是你抄我、我抄你的,产生的垃圾文章已经很多了,如果新站还是抄袭的话,那么内容的质量是相当的低的,这样一点好处都没有,搜索引擎更不会进行收录,相反,也会降低对网站的信用度。
尤其是近期搜索引擎新规则的出台,对原创的文章非常的重视。如果你的网站文章都是原创的,可想而知搜索引擎对你的网站也会更加的青睐。如果实在是写不出原创的文章来,那也可以进行伪原创,不过这个伪原创的要求也是非常的高的,要达到一定的原创度(最起码做到复制文章的大部分语句在搜索框里搜索,不会出现大量飘红的现象),才能够被收录,对网站才会有作用。
第三:一个新站上线推广初期,更要注重网站内链和外链的建设。 内链相对来说比较简单,就不再详细的介绍了。外链,这里所讲的外链主要是针对高质量的外链,哪些低质量的垃圾外链并不在考虑的范围之内。针对外链的建设,提倡质量第一,在保证质量的前提下,达到量的飞跃。那么没有质量的外链再多,也不会对网站有任何的作用,相反,还会对网站有所影响。
第四、用户体验。 一个新站上线,一定要站在访客的角度,以能够给他们提供更好的资源和帮助为关键,才能够留住更多的访客。访客能够在网站上获取想要的知识,得到问题的解决方法,才能够对网站产生好感,不断的关注网站,也有可能介绍给更多的人帮助宣传和推广。
因此,只有了解搜索引擎新规则的内容,知道哪些方式方法是适合和符合搜索引擎新规则的,再运用到网站的运营和推广当中,才能够获得最好的发展。希望大家能够多多的研究和创新,让自己的网站在搜索引擎那里获得更好的评价和信任。
三 : 搜索引擎的投票选举的模式与网页排序的问题
前些天读了一本《选举的困境》,其中有一章,从美国的选举制度说起,介绍美国选举制度的不足,然后针对其不足,提出种种改善,然而每种改善都有其各自的问题,其中的变化很有趣。
先说美国选举制度,美国的总统选举是一种“赢者通吃”的方式,每个州根据其人口多少,有几十或几百的“州票”,州里的人对总统候选人进行选举,在某个州获得票最多的那个候选人,获得这个州所有的“州票”,然后统计所有候选人的“州票”多少,获得最多“州票”的候选人获胜。
这样制度的问题是显然的,比如如果只有两个州,A州5个人,而B州4个人,州票也分别是5和4,如果某候选人X在A州以3:2获胜,另一个候选人Y在B州以4:0获胜,这样显然候选人Y在全国范围内获得了6张票,而候选人X只有在A州的3张票,但是由于“赢者通吃”,X获得了A周的全部5张“州票”,Y只获得了B周的4张“州票”,在全国只有1/3民众支持的X居然获得了选举的胜利。
这样的情况在2000年美国总统选举中就出现过,小布什的州票领先于戈尔,然而在全国民众中统计支持戈尔的人数却是大于小布什的,当然戈尔输给小布什还有另一个原因,这里按下不表。
如果放在算法领域,可以看出这里的问题在于,为了统计结果R(最适合的总统人选),找到了一个特征A(每个民众的投票),而决定结果R的,却不是特征A,而是由特征A推导出来的特征B(州票),在特征A向特征B的推导过程中,信息丢失了(每个洲的支持百分比不一样)。
“赢者通吃”这种制度的具体历史原因先不说,有兴趣的朋友可以去看原著。解决这种问题的最直接方案就是从“赢者通吃”变成直选,也就是一人一票,直接统计票数,然而这样也会遇到一系列问题。
在谈那一系列问题之前,先把要解决的问题抽象一下:
有n个候选人,每个选民对这n个候选人投票,最终在n个候选人中选出最合适、最符合民意、也符合逻辑的那个人。
方案1:一票制,每人一票,选出自己最喜欢的候选人,对结果进行统计,得票最多的那个人当选。
这样做的问题是会导致作者定义的一种“鹬蚌困局”,举例说,如果有ABC三个候选人,其中BC政见比较类似,支持B的人也比较支持C,反之亦然,在全民中,喜欢BC的人占多数,A的政见和BC相反,支持A的人在全民中占少数。这样导致的后果就是,BC获得的票会比较分散,而A获得的票比较集中从而获得胜利,如果BC中有1人不参加选举,票就会集中到B或者C一个人的手中,从而使多数选民的支持者当选。前面按下不表的戈尔失败的另一个原因,就是有人认为有跟戈尔政见类似的耐德的参与,他分散了部分戈尔的选票。
可以对此问题有所改善的方案叫做“二选制”。
方案2:二选制,每人一票,如果无人获得大于50%的支持,则将得票最高的两个候选人拿出来,再进行一轮选举,得票多的人获胜。
法国总统选举就是这样的二选制,但是这样的方法只能改善“鹬蚌困局”,而不能彻底解决,2002年的法国总统大选就出现了类似的情况,当时支持左派政见的民众较多,然而在二选制下,最终的前两名却是一个右派和一个极右派。出现这种情况的原因是当年有16个总统候选人,且多数是持左派政见者,这样就导致左派的票极端分散。
方案3:n选制,每人一票,如果无人获得大于50%的支持,则去掉支持最少的候选人,再进行一轮投票,若依旧无人获得大于50%的支持,再去掉得票最少的候选人,直到有人大于50%支持为止。
2001年奥委会决定北京为2008年奥运会主办城市的时候,就是用的这样的制度,在第一轮投票里大阪被淘汰,北京在第二轮就获得了半数以上的支持,从而当选。
n选制的问题在于不实用,如果是奥委会这种只有几百个人投票的情况还可以使用,如果类似前面法国总统选举,有16个候选人,举国上下最多可能进行15次投票,成本太高。
方案4:即刻复选制,每个民众对候选人进行排序,如果某个候选人获得了50%以上的首选,则直接获得胜利,否则淘汰票数最低的候选人,并且把票数最低候选人的得票中的第二候选人拿出来,分给对应的候选人,如果有人获得50%以上,则当选,否则再淘汰一位最低的,并且把他票分给里面排序最高的且未被淘汰的候选人,如此往复。
爱尔兰总统选举和伦敦市长选举采用的是类似的方案,此方案也有问题,试想如此场景:选民共10人,中间派候选人是3人的首选,左派和右派的候选人分别是4人的首选,当然左派选民最讨厌右派候选人,而右派选民也最讨厌左派候选人,而左派右派的民众对中间派候选人倒是都可以接受,不管是即可复选制还是n选制,中间派候选人都会在第一轮被淘汰。而中间派候选人则是全体民众都可以接受的人,也最能调和各派之间矛盾,最和谐。
这个方案的本质问题是,虽然每个选民可以对候选人排序,但是在第一轮的时候却只考虑了第一选,没有考虑选民的二、三选。
方案5:上行复选制,跟方案4类似,只不过第一轮淘汰的不是支持最少,而是反对最多的候选人(获得最多末选票的候选人)
再看上面提到的情况,中间派候选人由于不是任何人的末选,所以第一轮淘汰的是左派或者右派,再第二轮选举中,中间派的候选人就可以获胜了。
方案5也有方案5的问题,考虑这样一种情况,只有两个候选人AB参选,选民9人,其中6人喜欢A而讨厌B,3人喜欢B而讨厌A,无论按照之前的哪种方式,都会是A获胜。但是现在又多了两个候选人C和D,喜欢B的3人中,都是把A列在最后一个候选的,而喜欢A的6人的末选,却是BCD各2票,这样,在第一轮选举中,A就由于获得了最多的末选票被淘汰了,而通过精心的构造例子,完全可以使B最终当选。仅仅由于CD参选或者不参选,A和B之间的胜负关系就发生了大逆转。
实际使用此方案的例子不多,只有在公元前507年的雅典有类似的方案,不是让民众投支持票,而是投反对票,把反对最多的人投出局。
方案6:多赛制,民众对候选人排序,然后候选人之间两两pk,统计每一张选票上看候选人A在候选人B前面还是B在A前面,如此找到获胜场次最多的候选人来赢得选举。
这样的问题是可能导致循环胜负,如ABC三个候选人,有3个民众,投票分别是ABC,BCA,CAB,可以看出AB之间A获胜两次,A>B;BC之间B获胜两次,B>C,AC之间C获胜两次,C>A,这样就构成了一个A>B>C的循环。这个是不是有点像足球联赛的记分制啊,如果积分相同,足球比赛中可以再看净胜球、进球、胜负关系等,但是作者并没有在这个方面进行展开,而是介绍了另一种方式:博达制。
方案7:博达制,民众对候选人排序,假如有n个候选人,第一位的候选人得n分,第二位得n-1分,以此类推,然后统计每个候选人的总分,获得最多分的获胜。
有人对博达制的批评是:可能有选民会利用这种方式进行作弊(投“策略票”),最支持B的候选人本来心目中的排序是B>A>C,但是由于相对A,他们还是更喜欢B,因此,为了把B拉上来,就得把A拉下去,他们的投票就变成了B>C>A。博达对此批评的回应是:我的制度只适用于诚实的投票者。
而这本书的作者却认为博达制的“策略票”问题没那么严重,如果无法准确预测民意和精确控制策略票的投法,有可能因为用力过猛,不但把A拉下来了,反而让C获得的支持票增加,这样就使得最支持B的那些人的“策略票”反而使得他们最讨厌的C当选了,当年在IMDB上就发生过类似一幕:
电影《蝙蝠侠6》上映后,蝙蝠侠的粉丝们觉得这部片太酷了,于是就想把蝙蝠侠6投成IMDB第一位,于是他们疯狂的给蝙蝠侠6打高分,而同时,也纷纷的给当时的IMDB第一《教父》投低分,导致的结果就是用力过猛,教父变成了第三名,原来的第二肖申克的救赎(TSR)变成了第二(原来的第二是排在教父后面,新的第二是排在蝙蝠侠6后面),而后来,随着疯狂粉丝的热情消退,理性的意见占据了上风,蝙蝠侠6的得分逐渐下降,跌到了第10。而教父还是在肖申克的救赎后面,很久没有回去了。
博达制是否有其他问题呢?
以上只是对这本书第14章的一个笔记,也仅仅针对“多候选人单职位”问题进行了讨论,书的后面还会对“多候选人多职位”的情况继续探讨,也就是根据每个人对候选人的排序,来决定最终的候选人排序。
回到搜索引擎领域来,如上策略的变迁会给我们一些启示,先看看之前抽象出来的问题:
有n个候选人,每个选民对这n个候选人投票,最终在n个候选人中选出最合适、最符合民意、也符合逻辑的那个人。
这很像搜索引擎在解决的问题: 系统里有n个网页,有m个特征(页面质量、页面内容丰富度、页面超链、文本相关性等)对n个网页有不同的打分,如何根据这些特征的“投票”,选出最适合放在第一位的网页呢?
从选举的例子中,我们可以得到的几个启示:
1. 设计算法时,要避免出现“赢者通吃”带来的信息丢失问题。
2. 不要因为某几个特征特别好,就把某个网页排到最前,或者因为某几个特征特别差,就把某个网页抛弃。
3. 最合适放在首位的网页不一定是在每个特征上都最好,而应该是能够兼顾所有特征,综合表现最好的那个。
4. 搜索引擎使用者对搜索结果的点击行为,可以看成是对搜索结果进行的“投票”,这样的“投票”信息的使用方式,也要注意考虑是否会带来选举过程中出现的种种不合理。
以上提到的种种选举方案,仅仅是对“多候选人单职位的”的情况进行讨论,而搜索引擎面对的问题,则更类似于“多候选人排序”的情况,也即:
系统里有n个网页,有m个特征(页面质量、页面内容丰富度、页面超链、文本相关性等)对n个网页有不同的打分,如何根据这些特征的“投票”,决定n个网页的顺序?
而这个“多候选人排序”问题,是有一个“不可能的民主”的理论的,该理论的大意是,“合理”的民主应该满足3个条件:
1. 如果选民都认为A比B好,那么最终结果应该也是A比B好
2. 没有“独裁者”,也即,不存在这样一个人,无论别人怎么排序,最终结果的排序都和这个人的排序一致
3. 无关因素独立性,也即,在第一次投票完成后,A排在B前面,现在进行第二次投票,如果所有人都没有改变自己投票中A和B的相对顺序,那最终结果应该也是A在B前面
而通过数学的证明,可以得出结论:如果某种选举方式满足条件1和3,则必然不满足2,也即必然存在“独裁者.
根据“不可能的民主”理论,和搜索引擎结合起来看,似乎搜索引擎很难给出一个合理的网页排序,但是搜索引擎和投票又似乎有所不同,有两个角度可以破解
1. 认为条件3过于强,需要弱化。
2. 也许在网页排序问题上,真的存在这样一个“独裁特征”,这个“独裁特征”从目前看来,最适合的应该就是“用户满意度”了,按照用户的满意程度来排序网页,就是最合理的网页排序。如何衡量“用户满意度”呢?这就是我们一直在努力的。
by liangaili
四 : 如何让搜索引擎蜘蛛喜欢上你的网站
第一个问题:了解搜索引擎蜘蛛 当引擎蜘蛛爬行一个网站的时候,它需要爬行的信息首先就是站内的结构,检查站内结构是否通畅,当蜘蛛爬行网站看完结构辨认是通畅的,那么它下面要做的就是判断站内信息的新鲜度,根据信息的新鲜程度进行采集,当蜘蛛把采集到的网站信息带到服务器的时候,服务器会根据文章的价值,做排名处理。根据这些特性,我们可这样做:
1、尽量使用静态网站,动态网站中蜘蛛不能识别的东西应做好文字注释;
2、站内资源尽量原创,重复内容蜘蛛不会收录的;
3、做好适当的关键词、权重网页等信息,不误导蜘蛛;
4、蜘蛛会定时爬行网站,网站更新时尽量把握在每天的同一个时间。
第二个问题:吸引蜘蛛爬行自己网站 吸引蜘蛛最好的办法是写软文,软文不仅是高质量的外链,也是吸引蜘蛛爬行本站的一种方法,当我们吧写好的原创文章发布到一些权重比较高的网站时(一般权重高的网站蜘蛛会爬行的比较频繁),蜘蛛爬行时就会发现你的文章,然后循着软文中的连接地址进入你的网站,这时蜘蛛开始判断你的网站资源,然后根据你的文章的锚链接,关键词抓取你的网站,说到这里,我提醒大家几句,尽量不要使用伪原创工具,虽然这些工具会很节省时间,但是网上大多数软件蜘蛛们都免疫了,它们有它们自己的算法,然后按照算法识别你的文章是否用机器伪原创了,如果有的话,蜘蛛是照样不会收录你的文章。当蜘蛛爬行完你网站后就会把采集到内容带到服务器然后进行收录,然后就会因为站内文章出现的关键词和链接地址进行提高你网站排名的工作。蜘蛛爬行的过程如下:
1、在一些权重比较高的原创网站上发布原创文章,然后在文章的最后加入关键词和链接地址,吸引蜘蛛爬行自己网站;
2、蜘蛛进入我们的网站,检查网站相关信息;
3、蜘蛛确认爬行,查看网站的整体结构是否符合标准,具体标准如下:
(1)、title中嵌入关键词,关键词排序从短到长排序,做百度SEO的话就用“_”分隔符,如果做谷歌SEO就用“,”分隔符。
(2)、meta中的keyword和desc ription,keyword和desc ription的信息,keyword写关键词,而desc ription写描述。
(3)、网站页面中出现的图片加alt,在每一个图片中嵌入一个关键词,尽量简单描述清楚。
(4)、次导航,在首页只出现次导航的话不会有提高首页权重的效果,次导航要用关键词命名,每一个关键词要嵌入一个超链接。葵力果
(5)、友情链接,链接一些和本站相关,权重较高的网站。
4、看完代码下面蜘蛛产看网站内容,文章尽量是原创,如果不是原创可以手动伪原创,不要用机器进行伪原创就可以了,每天更新文章的时间要固定,慢慢的就可以培养蜘蛛对网站爬行了。
五 : 新网站如何让自己的网站在搜索引擎上被搜到的方法
方法非常简单,就是找到各搜索引擎提交网站的入口,根据其格式来填写自己的网站信息.下面分享了一些主要搜索引擎的提交网址.
Google搜索
百度搜索
hao123 http://tieba.baidu.com/f?kw=hao123
爱问搜索 http://iask.com/guest/add_url.php
雅虎搜索
中国搜索 http://service.chinasearch.com.cn/NetSearch/pageurlrecord/frontpageurl.jsp
TOM搜索 http://search.tom.com/tools/weblog/log.php
天网搜索
MSN搜索 http://beta.search.msn.com/docs/submit.aspx
Bing提交 http://cn.bing.com/docs/submit.aspx
有道提交 http://tellbot.youdao.com/report
DMOZ提交 http://www.dmoz.org/World/Chinese_Simplified
千度提交 http://www.qiandu.com/protocol.asp
好站导航 http://www.beijixing.com.cn/cgi-bin/add.cgi
凯希提交
协通提交
法律网 http://www.law-lib.com/lawseek/wzdl.asp
网站搜索 http://bbs.wangyeba.com
极限搜索
精彩实用网 http://www.ok881.com/add.asp
114啦提交 http://url.114la.com/
中文分类目录
第一摘网站 http://www.dzhai.com/User/UserLogin.asp
站长区分类 http://www.admin7.cn/MuLu/UserPublish.asp
35分类目录 http://www.35dir.com/Submit.asp
酷帝分类 http://www.coodir.com/accounts/addsite.asp
网站目录 http://www.friendpage.cn/submit.php
160网站分类 http://www.dir160.com/user/login.aspx
258商业搜索 http://dir.258.com/
网络营销 http://www.ubestweb.com/plus/heightsearch.php
奇虎提交
本文标题:
搜索引擎如何抓取网页-分析搜索引擎是针对网站实际路径来抓取 本文地址:
http://www.61k.com/1120884.html