一 : 数据仓库与数据挖掘在天气预报中的作用41
数据仓库系统技术在天气预报技术的融合
[摘要]随着信息时代的不断进步,社会正处于数据技术飞速发展的良好状态。但是在数据信息极度膨胀的同时,并非所有的数据都可被利用,大量的数据浪费造成各种损失,所以有必要将这些数据转化为有用的信息。而传统的数据处理方法越来越不能满足使用要求,迫切需要一种从大量数据中搜索集中并去伪存真的技术。
[关键词]数据仓库与数据挖掘 技术 天气预报
引言
20世纪80年代后期至今高级数据分析——数据挖掘(Data Mining)简称
DM发展起来是开发信息资源的一套科学方法、算法以及软件工具和环境是集统计学、人工智能、模式识别、并行运算、机器学习、数据库等技术为一体的一个交叉性的研究领域。
一、 数据挖掘的基本概念
数据挖掘DM(Data Mining)是指从数据中识别出潜在有用的、先前未知的、
最终可理解的模式的非平凡过程。数据挖掘提取的知识可以表示成概念、规律、模式等形式。其挖掘对象不仅可以是数据库,也可以是文件系统或组织在一起的数据集合,更主要的是数据仓库。简单的说数据挖掘是提取或“挖掘”知识。
在一般基层气象台站天气预报中,传统的手段是预报员根据经验,利用当天
及前几天的少数站点的实况资料及小范围的区域内少数的几个物理量,提取与某一天气现象相关性较高的气象要素作为因子,进行回归、判断分析,即得出预报员个人意见,而手头的“海量”的资料作为历史资料保存,并未在气象预报中发挥作用.另一方面,传统的数据分析手段也根本无法应付这些“海量”的数据,使预报员无法综合理解并有效的使用这些资料用于指导天气预报,从而形成了数据产
生、数据理解与数据应用之间存在着很大的差距.
因此,将数据仓库系统技术应用到气象领域,从一个全新的角度将气象资料
进行分析处理,将各种数据经过清洁、抽取、变换、概括和聚集等操作,按气象预
报的需要进行数据重组和数据存储,提供全局的、统一的、语义一致的、组织良
好的数据视图,在此基础上进行联机分析处理、数据挖掘等技术处理,发现各物理
量和气象要素与某天气现象之间的关系,解决长期以来台站预报员“面对堆积如
山的资料无从下手,只好置之不理”的尴尬局面,使天气预报中的主观因素少些,
客观因素多一些,同时也利于预报模式不断的改进,最终产生较为理想的预报模
式。
二、 数据挖掘技术在天文数据分析中的应用
数据挖掘在天文学上有一个非常著名的应用系统:SKICAT。它是美国加州理
工学院(CIT)与天文科学家合作开发的用于帮助天文学家发现遥远的类星体的一
个工具。SKICAT既是第一个获得相当成功的数据挖掘应用,也是人工智能技术
在天文学和空间科学上第一批成功应用之一。利用SKICAT,天文学家已发现了
16个新的极其遥远的类星体,该项发现能帮助天文工作者更好地研究类星体的
形成以及早期宇宙的结构。
在天文学研究以及航天数据分析中,人们遇到了一个很大的难题,即人工对
大批量数据分析的无能为力。这里所说的数据量一般在数千兆以上,现有的大型
数据库只是把数据以另一种形式给出,而并没有对数据进行更深层次的处理,因
而,在对大量天体数据进行分析的过程中,很难起到根本的促进作用。SKICAT
不仅提供对数据库的管理,并且通过训练可以对天体进行辨识。它采用了模块化
设计,共有三个主要功能模块:分类建立、分类管理及统计分析。其中,分类建
立是通过有示范的训练建立对天体的辨识机制。对天体的辨识是进行其它数据分
析的前提,只有将天体识别出来以后,如是星系还是星球,才能进行相应的研究。
使用SKICAT对天体数据进行分析,一方面是通过机器学习将知识提取过程由学
习算法完成,从而可以实现对大批量数据的分析,另一方面是辨识那些亮度很低、
人工难以判读的天体图像,以进行后续分析。SKICAT通过有效地对天体图像的
特征进行定义,对那些亮度较低的图像可以得到比人工分类更好的结果。将仅由
象素包含的关于天体的多维信息通过变换形成低维空间内的向量空间,并进而利
用示范学习进行分类,以达到人工直接观察无法达到的分类精度。
1、气象数据挖掘技术
1.1时空分析
气象数据具有很强的时序和空间特性,采用时间分析、空间分析以及时空联
合分析气象数据,避开分析气象数据内部隐藏复杂非线性动力学机制。对任何一
个天气特征,一般是通过空间分析得出该特征的现象描述和特征分析,而进行时
间分析,一般是对该天气特征作出预报预测。空间分析对基于空间多站点数据的
聚类分析,形成地理区域划分;对基于空间站点的数据进行主成份分析,得出影响
天气现象较为突出的区域;同时聚类分析中,发现奇异点,指出反常现象。时间分
析指对组成的长时间序列数据进行回归分析、趋势预测与奇异值分析;对时序数
据的分布演变进行跟踪分析,得出比如台风路径等。
1.2降维分析
影响天气的因素众多,且各个因素间的关系十分复杂。现有的气象预报模式
将大量的卫星、雷达和台站观察资料带入复杂的方程计算求解,对计算能力要求
极高。在预报精度不损失的情况下,降低气象预报所需的数据维度,减少对计算机
资源的依赖,实现PC机气象预报。降维分析方法主要有2种:一种是精确降维,
主要是以粗糙集分析方法为为代表;其次是近似降维,以主成分分析为代表。粗糙
理论的基本思想是将数据库中的属性分为条件属性和结论属性,对数据库中的实
例根据各个属性不同的属性值分成相应的子集,然后对条件属性划分的子集与结
论属性划分的子集之间形成的近似空间进行分析,如果条件属性集中去掉某一个
属性a而不影响结论属性的知识表达的精度,那么a就是可约简的,从而实现整个
数据库表的属性维数减少。PetersJF等在风暴预报中,采用粗糙集对气象雷达体
数据进行分类,弥补了气象雷达数据的不精确和不完整性带来常规模式预测效果
差的缺点,取得了较好效果。主成份分析的基本思想是,设法将原来众多具有一定
相关性的指标重新组合成一组新的相互无关的综合指标来代替原来指标。在选取
综合指标时,其个数少于原有指标个数。但是,一般地,选取综合指标并不能完全
代替原有指标,仅仅是根据累计贡献率的大小取前k个综合指标。所以,主成分分
析是不精确的降维方法。黄海洪等先进行主成分分析,然后利用神经网络建模预
报水位,简化了神经网络输入参数,在稍许精度损失下提高了预报效率。 TsegayeTadesse利用双时间序列分析方法在众多的大气因子和海洋因子中找出
影响干旱相对较强的因子。
1.3分类预测
数据挖掘就是要在大量气象资料和数据中,建立描述复杂非线性天气系统的
模型,分析隐藏在数据背后的气象知识和规律,对未来气象因素进行预测,为气象
预报员提供决策支持。分类预测有2大类:1)对离散值的预测,如是否降雨、是否
降霜、台风等级、暴雨等级。常用的方法有决策树、分类统计、神经网络、粗糙
集、SVM分类算法。2)对连续值的预测,如降雨量预测、温度预测等。常用的实
现手段是回归分析、神经网络等。向俊莲等利用决策树方法,分别对气温距平值、
雨量距平值及海温距平值进行预报,预报准确率达到59%
TheodoreBTrafalis等通过对比使用ANNS,SVR,LS2SVR,LR以及气象学家应
用的RR来预测降雨量。ChengTao利用动态复神经网络RNN来预测森林火灾的面
积。
1.4关联分析
考虑气象数据的时空特性和数据因素的多维性,对气象数据的关联规则挖掘
要从2个方面进行处理。一是要降低频繁集产生的个数,指定属性进行关联分析;
二是要考虑同一数据属性在不同时间和不同地点的关联关系。气象数据库表中的
属性(字段)数目n较大,考虑所有字段的关联,需要测试的频繁集理论上有2n个,
且产生的频繁集并不一定有意义。指定一个关键属性,考虑其他属性与该属性同
时发生的概率,更具有实际意义。马廷淮采用了指定结论域进行关联规则分析。
特定时刻和地点的气象因素受相邻地域气象因素影响,且具有时间连续性。频繁
候选集的选取要具有跨地域和跨时间性,以便更好表达此时此刻的气象因素与以
往时刻和相邻地域的关系。LingFeng等研究了来自不同的案例的同一个属性,在
不同时段的关联关系。ThomasHHinke等考虑不同地点的数据之间的关联关系。
2、气象数据挖掘的应用
2.1气象预报
气象预报一般指短时、短期和中期的天气预报。根据预报的内容和时限不同,
有不同的预报技术和手段。短时(3h内)天气预报主要采用现代化的探测手段,并用外推法作出预报;短期(72h内)天气预报使用传统的天气学、统计学、动力统计学、数值预报、诊断分析等方法制作;中期(10d内)天气预报应用天气学、统计学、动力学、数值预报等方法,综合分析制作出来。所以在气象预报中,主要还是利用天气学基本原理分析及时得到的探测数据;而基于数据挖掘和统计的气象预报方法未得到充分的应用,具有较大的研究空间。国内外不少学者在这方面进行过有益探讨。从现有研究情况来看,采用SVM分类方法对降雨量的预测估计得到的效果较好。
2.2气候预测
气候预测是指长期天气预报,其主要内容是对预报时效内的旱涝、冷暖、雨量、气温等作趋势性预测。气候预测应用了大量的历史资料数据,采用统计预报等方法综合判断分析制作出来的,这恰是符合数据挖掘从海量数据中进行知识挖掘的特征,由于时效性的相对要求不高,适合进行大规模的数据分析处理。气候预测是数据挖掘的应用重点。例如:焦飞等利用数据挖掘技术中的一些方法,并开发相关的软件来辅助分析,选取广州、香港、澳门、湛江和汕头5个站点的100多年来年平均地面气温资料,建立回归分析模型,研究分析广东及港澳气温的长期变化趋势。向俊莲等基于1961—1997年云南气象有关海温距平值、雨量、气温场等大量数据,利用决策树方法,对云南80个雨量站每个月降雨量预报进行了深入研究和改进,经过实验验证,预报准确率达到59%,满足预报要求,且提高了预报效率。
2.3气象灾害
预测我国是自然灾害多发、频发的国家,几乎每年都发生洪水、台风等自然灾害,造成巨额的经济损失,对人民生活的安定和社会的稳定造成了威胁。防灾减灾在构建和谐社会中有着至关重要的作用。防灾减灾是基于对气象灾害的准确预报的。气象灾害的预报主要是根据灾害天气动力学理论,借助定量遥感技术进行短时临近预报。由于气象灾害事件一般以个案形态呈现,难于有大量的相似案例进行数据挖掘。但是灾害气象的重要性吸引了众多的研究者尝试采用数据挖掘手段试图提高灾害天气预报能力。例如:PetersJF等基于气象雷达体扫数据,采用粗糙集方法对夏季恶劣天气下的风暴类型识别判断进行了研究。利用粗糙集方法,
数据仓库与数据挖掘在天气预报中的作用41_数据仓库与数据挖掘
数据仓库系统技术与天气预报技术的融合
使得气象雷达数据的高维度性、数据的不精确性、数据的不完整性得到克服。并利用加拿大环境署的雷达决策支持数据库,基于分类准确率作为标准,粗糙集方法是众多的分类技术中最适合风暴预测的。
三、总结
通过我对数据仓库与数据挖掘这一门的课程的学习,让我懂得了随着科技的不断进步,数据仓库与数据挖掘的这一技术对我们的影响就越来越广泛,它能够涉及到我们生活的方面面,为我们的现代化生活带来深刻的影响。就比如本论文写的数据仓库与数据挖掘对天气预报的作用一样,在以前,因为科技不发达,天气的各种情况人们未必能够及时了解和及时想出应对特殊天气的措施,导致我们的生活各方面都遭受到一定的影响或损失,但自从了有了数据仓库与数据挖掘这门技术以后,人们能够及时,清晰地了解到不同时刻、不同地方的天气信息,从而方便了人们的生活、生产等方面。
参考文献:
[1]朱明.《数据挖掘》.合肥:中国科技大学出版社,2002年。
[2]苏新宁.《数据仓库与数据挖掘》.北京:北京大学出版社,2006年。
[3]王军.《数据挖掘技术》.北京:科学出版社,1998年。
[4]钱维宏.《中期-延伸期天气预报原理》.科学出版社,2012年。
[5]中国气象局减灾司.《天气预报文集》.气象出版社,2006年。
[6]孔玉寿、钱建明、臧增亮.《统计天气预报原理与方法》.气象出版社,2010年。
5

二 : 数据之舞:大数据与数据挖掘
(文/David J. TenenBaum)泄密者爱德华·斯诺登(Edward Snowden)还在寻求容身之所的时候,美国国家安全局(NSA)全方位收集电话和电子邮件记录之事经过他的披露,已经引发了不安和愤怒。
奥巴马当局声称,监听数据带来了安全,然而左翼和右翼都在谴责这种窥探行为是对隐私的侵犯。
数据不是信息,而是有待理解的原材料。但有一件事是确定无疑的:当NSA为了从其海量数据中“挖掘”出信息,耗资数十亿改善新手段时,它正受益于陡然降落的计算机存储和处理价格。

?麻省理工学院的研究者约翰·古塔格(John Guttag)和柯林·斯塔尔兹(Collin Stultz)创建了一个计算机模型来分析之心脏病病患丢弃的心电图数据。他们利用数据挖掘和机器学习在海量的数据中筛选,发现心电图中出现三类异常者一年内死于第二次心脏病发作的机率比未出现者高一至二倍。这种新方法能够识别出更多的,无法通过现有的风险筛查被探查出的高危病人。 图片来源:Jason Grow 2012/Human Face of Big Data?
数据挖掘这一术语含义广泛,指代一些通常由软件实现的机制,目的是从巨量数据中提取出信息。数据挖掘往往又被称作算法。
威斯康星探索学院主任大卫·克拉考尔(David Krakauer)说,数据量的增长——以及提取信息的能力的提高——也在影响着科学。“计算机的处理能力和存储空间在呈指数增长,成本却在指数级下降。从这个意义上来讲,很多科学研究如今也遵循摩尔定律。”
在2005年,一块1TB的硬盘价格大约为1,000美元,“但是现在一枚不到100美元的U盘就有那么大的容量。”研究智能演化的克拉考尔说。现下关于大数据和数据挖掘的讨论“之所以发生是因为我们正处于惊天动地的变革当中,而且我们正以前所未有的方式感知它。”克拉劳尔说。
随着我们通过电话、信用卡、电子商务、互联网和电子邮件留下更多的生活痕迹,大数据不断增长的商业影响也在如下时刻表现出来:
你搜索一条飞往塔斯卡鲁萨的航班,然后便看到网站上出现了塔斯卡鲁萨的宾馆打折信息你观赏的电影采用了以几十万G数据为基础的计算机图形图像技术你光顾的商店在对顾客行为进行数据挖掘的基础上获取最大化的利润用算法预测人们购票需求,航空公司以不可预知的方式调整价格智能手机的应用识别到你的位置,因此你收到附近餐厅的服务信息大数据在看着你吗?除了安全和商业,大数据和数据挖掘在科研领域也正在风起云涌。越来越多的设备带着更加精密的传感器,传回愈发难以驾驭的数据流,于是人们需要日益强大的分析能力。在气象学、石油勘探和天文学等领域,数据量的井喷式增长对更高层次的分析和洞察提供了支持,甚至提出了要求。

2005年6月至2007年12月海洋表面洋流示意图。数据源:海面高度数据来自美国航空航天局(NASA)的Topex/Poseidon卫星、Jason-1卫星,以及海形图任务/Jason-2卫星测高仪;重力数据来自NASA/德国航空航天中心的重力恢复及气候实验任务;表面风压数据来自NASA的QuikScat任务;海平面温度数据来自NASA/日本宇宙航空研究开发机构的先进微波扫描辐射计-地球观测系统;海冰浓度和速度数据来自被动微波辐射计;温度和咸度分布来自船载、系泊式测量仪器,以及国际Argo海洋观测系统。
这幅2005年6月至2007年12月海洋表面洋流的示意图集成了带有数值模型的卫星数据。漩涡和窄洋流在海洋中传送热量和碳。海洋环流和气候评估项目提供了所有深度的洋流,但这里仅仅使用了表层洋流。这些示意图用来测量海洋在全球碳循环中的作用,并监测地球系统的不同部分内部及之间的热量、水和化学交换。
在医学领域,2003年算是大数据涌现过程中的一个里程碑。那一年第一例人类基因组完成了测序。那次突破性的进展之后,数以千计人类、灵长类、老鼠和细菌的基因组扩充着人们所掌握的数据。每个基因组上有几十亿个“字母”,计算时出现纰漏的危险,催生了生物信息学。这一学科借助软件、硬件以及复杂算法之力,支撑着新的科学类型。
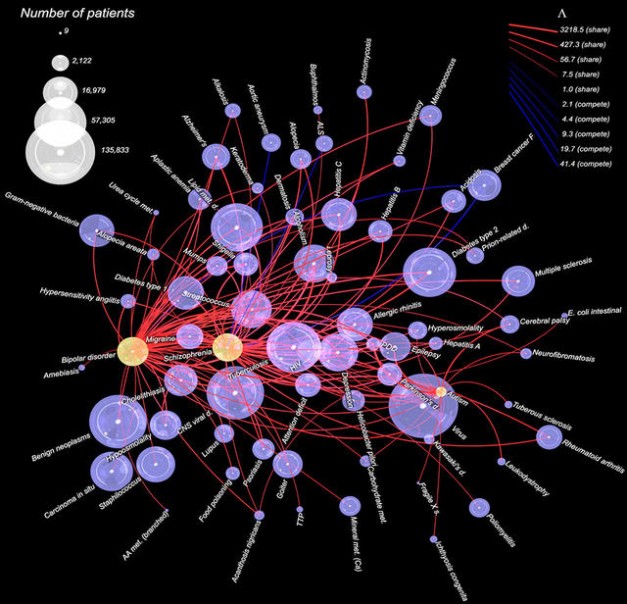 精神障碍通常是具体病例具体分析,但是一项对150万名病人病例的研究表明,相当多的病人患有超过同一种疾病。芝加哥大学的西尔维奥·康特中心利用数据挖掘理解神经精神障碍的成因以及之间的关系。“好几个(研究)团队都在致力于这个问题的解决。”中心主任安德烈·柴斯基(Andrey Rzhetsky)说,“我们正试图把它们全部纳入模型,统一分析那些数据类型……寻找可能的环境因素。”?图片来源:Andrey Rzhetsky,芝加哥大学
精神障碍通常是具体病例具体分析,但是一项对150万名病人病例的研究表明,相当多的病人患有超过同一种疾病。芝加哥大学的西尔维奥·康特中心利用数据挖掘理解神经精神障碍的成因以及之间的关系。“好几个(研究)团队都在致力于这个问题的解决。”中心主任安德烈·柴斯基(Andrey Rzhetsky)说,“我们正试图把它们全部纳入模型,统一分析那些数据类型……寻找可能的环境因素。”?图片来源:Andrey Rzhetsky,芝加哥大学
另一例生物信息学的应用来自美国国家癌症研究所。该所的苏珊·霍尔贝克(Susan Holbeck)在60种细胞系上测试了5000对美国食品和药品管理局批准的抗癌药品。经过30万次试验之后,霍尔贝克说:“我们知道每种细胞系里面每一条基因的RNA表达水平。我们掌握了序列数据、蛋白质数据,以及微观RNA表达的数据。我们可以取用所有这些数据进行数据挖掘,看一看为什么一种细胞系对混合药剂有良好的反应,而另一种没有。我们可以抽取一对观察结果,开发出合适的靶向药品,并在临床测试。”
互联网上的火眼金睛当医学家忙于应对癌症、细菌和病毒之时,互联网上的政治言论已呈燎原之势。整个推特圈上每天要出现超过5亿条推文,其政治影响力与日俱增,使廉洁政府团体面临着数据挖掘技术带来的巨大挑战。
印第安纳大学Truthy(意:可信)项目的目标是从这种每日的信息泛滥中发掘出深层意义,博士后研究员埃米利奥·费拉拉(Emilio Ferrara)说。“Truthy是一种能让研究者研究推特上信息扩散的工具。通过识别关键词以及追踪在线用户的活动,我们研究正在进行的讨论。”
Truthy是由印第安纳研究者菲尔·孟泽(Fil Menczer)和亚力桑德罗·弗拉米尼(Alessandro Flammini)开发的。每一天,该项目的计算机过滤多达5千万条推文,试图找出其中蕴含的模式。
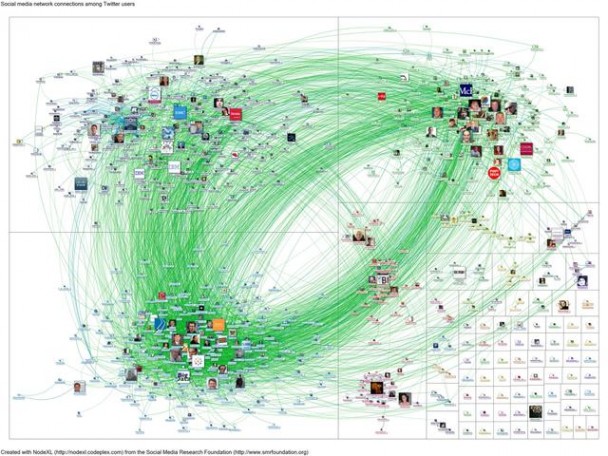
大数据盯着“#bigdata”(意为大数据)。这些是在推特上发布过“bigdata”的用户之间的连接,用户图标的尺寸代表了其粉丝数多寡。蓝线表示一次回复或者提及,绿线表示一个用户是另一个的粉丝。?图片来源:Marc Smith
一个主要的兴趣点是“水军”,费拉拉说:协调一致的造势运动本应来自草根阶层,但实际上是由“热衷传播虚假信息的个人和组织”发起的。
2012年美国大选期间,一系列推文声称共和党总统候选人米特·罗姆尼(Mitt Romney)在脸谱网上获得了可疑的大批粉丝。“调查者发现共和党人和民主党人皆与此事无关。”费拉拉说,“幕后另有主使。这是一次旨在令人们相信罗姆尼在买粉从而抹黑他的造势运动。”
水军的造势运动通常很有特点,费拉拉说。“要想发起一场大规模的抹黑运动,你需要很多推特账号,”包括由程序自动运行、反复发布选定信息的假账号。“我们通过分析推文的特征,能够辨别出这种自动行为。”
推文的数量年复一年地倍增,有什么能够保证线上政治的透明呢?“我们这个项目的目的是让技术掌握一点这样的信息。”费拉拉说,“找到一切是不可能的,但哪怕我们能够发现一点,也比没有强。”
头脑里的大数据人脑是终极的计算机器,也是终极的大数据困境,因为在独立的神经元之间有无数可能的连接。人类连接组项目是一项雄心勃勃地试图绘制出不同脑区之间相互作用的计划。
除了连接组,还有很多充满数据的“组”:
基因组:由DNA编码的,或者由RNA编码的(比如病毒)——全部基因信息转录组:由一个有机体的DNA产生的全套RNA“读数”蛋白质组:所有可以用基因表达的蛋白质代谢组:一个有机体新陈代谢过程中的所有小分子,包括中间产物和最终产物连接组项目的目标是“从1,200位神经健康的人身上收集先进的神经影像数据,以及认知、行为和人口数据”,圣路易斯市华盛顿大学的连接组项目办事处的信息学主任丹尼尔·马库斯(Daniel Marcus)说。
项目使用三种磁共振造影观察脑的结构、功能和连接。根据马库斯的预期,两年之后数据收集工作完成之时,连接组研究人员将埋首于大约100万G数据。
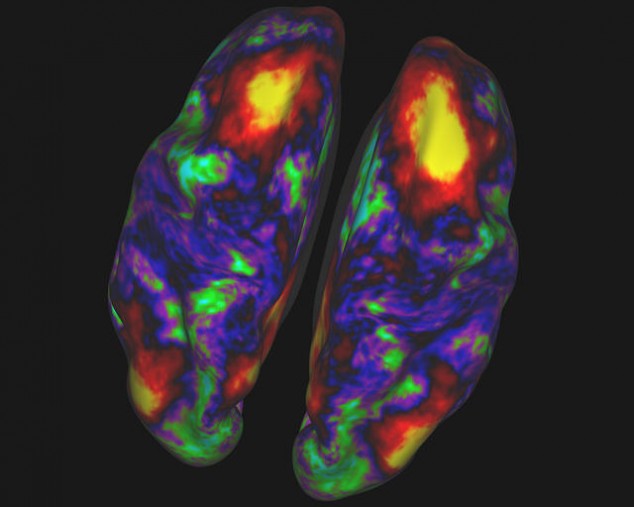 ?20名健康人类受试者处于休息状态下接受核磁共振扫描,得到的大脑皮层不同区域间新陈代谢活动的关联关系,并用不同的颜色表现出来。黄色和红色区域在功能上与右半脑顶叶中的“种子”位置(右上角黄斑)相关。绿色和蓝色区域则与之关联较弱或者根本没有关联。图片来源:M.F.Glasser?and S.M.Smith
?20名健康人类受试者处于休息状态下接受核磁共振扫描,得到的大脑皮层不同区域间新陈代谢活动的关联关系,并用不同的颜色表现出来。黄色和红色区域在功能上与右半脑顶叶中的“种子”位置(右上角黄斑)相关。绿色和蓝色区域则与之关联较弱或者根本没有关联。图片来源:M.F.Glasser?and S.M.Smith
绘制脑区分布图的“分区”是一项关键的任务,这些脑区最早于两到三世纪之前通过对少量大脑染色被识别出来。“我们将拥有1,200个人的数据,”马库斯说,“因此我们可以观察个人之间脑区分布的差别,以及脑区之间是如何关联的。”
为了识别脑区之间的连接,马库斯说,“我们在受试者休息时获取的扫描图中,观察脑中的自发活动在不同区域之间有何关联。”比如,如果区域A和区域B自发地以每秒18个周期的频率产生脑波,“这就说明它们处于同一网络中。”马库斯说。“我们将利用整个大脑中的这些关联数据创建一个表现出脑中的每一个点如何与其他每一个点关联的矩阵。”(这些点将比磁共振成像无法“看到”的细胞大得多。)
星系动物园:把天空转包给大众星系动物园项目打破了大数据的规矩:它没有对数据进行大规模的计算机数据挖掘,而是把图像交给活跃的志愿者,由他们对星系做基础性的分类。该项目2007年启动于英国牛津,当时天文学家凯文·沙文斯基(Kevin Schawinski)刚刚蹬着眼睛瞧完了斯隆数字巡天计划拍摄的5万张图片。
阿拉巴马大学天文学教授、星系动物园科学团队成员威廉·基尔(William Keel)说,沙文斯基的导师建议他完成95万张图像。“他的眼睛累得快要掉出眼窝了,便去了一家酒馆。他在那里遇到了克里斯·林托特(Chris Lintott)。两人以经典的方式,在一张餐巾的背面画出了星系动物园的网络结构。”
星系是一个经典的大数据问题:一台最先进的望远镜扫描整个天空,可能会看到2000亿个这样的恒星世界。然而,“一系列与宇宙学和星系统计学相关的问题可以通过让许多人做相当简单的分类工作得以解决。”基尔说,“五分钟的辅导过后,分类便是一项琐碎的工作,直到今日也并不适合以算法实现。”
星系动物园的启动相当成功,用户流量让一台服务器瘫痪了,基尔说。
斯隆巡天的全部95万张图片平均每张被看过60次之后,动物园的管理者们转向了更大规模的巡天数据。科学受益匪浅,基尔说。“我的很多重要成果都来自人们发现的奇怪物体,”包括背光星系。
 这是星系动物园志愿者们发现的差不多2000个背光星系之一。它被其后方的另一个星系照亮。来自背后的光令前景星系中的尘埃清晰可辨。星际尘埃在恒星的形成中扮演了关键的角色,但它本身也是由恒星制造的,因此检测其数量和位置对于了解星系的历史至关重要。 图片来源:WIYN 望远镜, Anna Manning, Chris Lintott, William Keel
这是星系动物园志愿者们发现的差不多2000个背光星系之一。它被其后方的另一个星系照亮。来自背后的光令前景星系中的尘埃清晰可辨。星际尘埃在恒星的形成中扮演了关键的角色,但它本身也是由恒星制造的,因此检测其数量和位置对于了解星系的历史至关重要。 图片来源:WIYN 望远镜, Anna Manning, Chris Lintott, William Keel
星系动物园依赖统计学、众多观察者以及处理、检查数据的逻辑。假如观察某个特定星系的人增加时,而认为它是椭圆星系的人数比例保持不变,这个星系就不必再被观察了。
然而,对一些稀有的物体,基尔说,“你可能需要40至50名观察者。”
大众科学正在发展自己的法则,基尔补充道。志愿者们的工作“已经对一个真实存在的重大问题做出了贡献,是现存的任何软件都无法实现的。鼠标的点击不该被浪费。”
这种动物园方法在zooniverse.org 网站上得到了复制和优化。这是一个运行着大约20项目的机构,这些项目的处理对象包括热带气旋、火星表面和船只航行日志上的气象数据。
最终,软件可能会取代志愿者,基尔说。但是计算机和人类之间的界线是可互换的。比如说超新星动物园项目在软件学会了任务之后就关闭了。
我们惊讶地得知志愿者们积累的庞大数据是计算机学习分类的理想材料。“一些星系动物园用户真的很反感这一点。”基尔说,“他们对于自己的点击被用来训练软件表达出明显的怨恨。但是我们说,不要浪费点击。如果某人带来了同样有效的新算法,人们就不必做那些事情了。”
学习的渴望人们长久以来改进对图像和语音的模式识别的努力已经受益于更多的训练,威斯康星大学麦迪逊分校的克拉考尔说。“它不仅仅是有所改善,更是有了实际的效果。5到10年之前,iPhone上的Siri是个想都不敢想的点子,语音识别一塌糊涂。现在我们拥有了这样一批庞大的数据来训练算法,忽然之间它们就管用了。”
 随着数据及通讯价格持续下跌,新的思路和方法应运而生。如果你想了解你家中每一件设备消耗了多少水和能量,麦克阿瑟奖获得者西瓦塔克·帕特尔(Shwetak Patel)有个解决方案:用无线传感器识别每一台设备的唯一数字签名。帕特尔的智能算法配合外挂传感器,以低廉的成本找到耗电多的电器。位于加利福尼亚州海沃德市的这个家庭惊讶地得知,录像机消耗了他们家11%的电力。 图片来源:Peter Menzel/?The Human Face of Big Data
随着数据及通讯价格持续下跌,新的思路和方法应运而生。如果你想了解你家中每一件设备消耗了多少水和能量,麦克阿瑟奖获得者西瓦塔克·帕特尔(Shwetak Patel)有个解决方案:用无线传感器识别每一台设备的唯一数字签名。帕特尔的智能算法配合外挂传感器,以低廉的成本找到耗电多的电器。位于加利福尼亚州海沃德市的这个家庭惊讶地得知,录像机消耗了他们家11%的电力。 图片来源:Peter Menzel/?The Human Face of Big Data
等到处理能力一次相对较小的改变令结果出现突破性的进展,克拉考尔补充道,大数据的应用可能会经历一次“相变”。
“大数据”是一个相对的说法,不是绝对的,克拉考尔指出。“大数据可以被视作一种比率—我们能计算的数据比上我们必须计算的数据。大数据一直存在。如果你想一下收集行星位置数据的丹麦天文学家第谷·布拉赫(Tycho Brahe,1546 - 1601),当时还没有解释行星运动的开普勒理论,因此这个比率是歪曲的。这是那个年代的大数据。”
大数据成为问题“是在技术允许我们收集和存储的数据超过了我们对系统精推细研的能力之后。”克拉考尔说。
我们好奇,当软件继续在大到无法想象的数据库上执行复杂计算,以此为基础在科学、商业和安全领域制定决策,我们是不是把过多的权力交给了机器。在我们无法觑探之处,决策在没人理解输入与输出、数据与决策之间的关系的情况下被自动做出。“这正是我所从事的领域,”克拉考尔回应道,“我的研究对象是宇宙中的智能演化,从大爆炸到大脑。我毫不怀疑你说的。”
本文编译自:The Why Files,Data Dance, Big Data and Data Mining
原创人员:编辑/Terry Devitt;?设计制图/S.V. Medaris; 项目助理/Yilang Peng; 专题作者/David J. TenenBaum; 内容制作总监/Amy Toburen
本文由?Whyfiles.org?授权果壳网(guokr.com)编译发表,未经书面许可严禁转载。
THE WYE FILES?? 2013 UNIVERSITY OF WISCONSIN BOARD OF REGENTS
相关的果壳网小组
数据江湖分布式计算怎样学编程三 : 数据仓库与数据挖掘论文
《数据仓库与数据挖掘》论文
题目:浅析基于数据仓库与数据挖掘技术的决策支持系统
指导老师:
班级:
学号:
姓名:
专业:
2012年11月2日
数据仓库与数据挖掘 数据仓库与数据挖掘论文
摘要
通过对数据仓库与数据挖掘的学习和大致的了解,主要提出了一种基于数据仓库的数据挖掘系统的决策支持系统的框架。(www.61k.com]该文章把数据仓库、数据挖掘工具和知识库结合在一起,提高了数据挖掘的效率。增加了挖掘数据的效率和价值实用性!
一、概述
今天, 越来越多的企业认识到要从以往的事务处理和决策中总结经验,利用现有的数据进行分析和推理,建立企业的决策支持系统(DSS)以提高决策的质量。企业如果不能快速精确的收集和分析信息,将无法进行科学而有效的决策。建立数据仓库(Data warehouse)将能很的解决这一问题,使企业从大量的业务信息中筛选出所需的信息,并做出正确的决策。数据仓库不是单一的产品, 而是综合了多种信息技术的计算环境。它将全企业的运行数据汇集到一个精心设计的关系数据库中,并将它们转换成面向主题(Subject-oriented)的形式,使最终用户很容易的从历史的角度对这些数据进行访问和分析。以银行为例,通常,银行的应用系统是按业务分类的,如储蓄、信贷、信用卡等,一个客户的信息分布在不同的业务系统中,要想得到一个客户的全面信息非常困难。银行通过建立数据仓库, 可以将分离在各个业务系统中的数据合并成一个统一的图表,这样就可以看到客户在各个系统中的全貌,而且可以从历史的角度对客户档案进行分析,
数据仓库与数据挖掘 数据仓库与数据挖掘论文
以便做出为每一个客户进一步服务的决策。[www.61k.com]
二、数据仓库和数据挖掘的基本概念
数据仓库是支持管理决策过程的、面向主题的、集成的、随时间而变的、持久的数据集合。数据仓库系统负责从操作型数据库中抽取数据,实现对集成和综合后的数据的管理,并把数据呈现给一组数据仓库前端工具, 以满足用户的各种分析和决策的需求。数据仓库系统的前端工具以OLAP 工具和数据挖掘工具为代表,是用户赖以从数据仓库中提取、分析数据,以及实施决策的必经途径。数据挖掘DM(Data Mining),是指从数据中识别出潜在有用的、先前未知的、最终可理解的模式的非平凡过程。研究基于数据仓库的数据挖掘系统结构框架是很有意义的。
三、数据仓库的结构、功能
1、数据仓库的基本结构
数据仓库中的信息存储, 根据对数据的不同深度的分析处理而区分为不同的层次,其基本结构分为以下几个部分:
(1)历史性详细数据层:它存储历史数据,用于数据对比、回归、汇总等供分析、建模预测之用。历史数据一般为5 至10 年或更久的数据,它纵向只对数据/信息进行分类存储。
(2)当前详细数据层:存储当前最新详细数据,重点用于了解当前情况,是进一步分析数据的基础。在一定时刻,这些数据会转移到历
数据仓库与数据挖掘 数据仓库与数据挖掘论文
史数据层去。(www.61k.com]
(3)不同程序的归纳总结信息层:可包含多个层次,根据所需分类和归纳的不同深度而定。如按周、月、年统计的数据。这些信息只是一些简单的汇总,尚不能形成高级的决策信息。
(4)专业信息分析层:进一步专业分析的结果,如统计分析、运筹分析、时间序列分析以及表面数据的内在规律分析等。
(5)仓库结构信息:数据仓库的内部结构信息,反映各种信息在数据仓库中的位置分布和处理方式等,以便检索查询之用。组织数据仓库的数据时, 应根据数据访问概率把数据分为经常被访问但较少被修改的数据和经常被修改但较少被访问的数据。对于前者可以做较多的索引(一般可做8 至12 个)来提高访问的效率;对于后者就必须少建索引,否则,由于它经常被修改,重索引的概率就很大,反而会降低系统的效率。
2、数据仓库的功能特点
数据仓库的主要功能是提供企业决策支持系统或执行信息系统(EIS)所需要的信息,它把企业日常运行中分散不一致的数据经归纳整理后转换为集中统一的、可随时取用的深层信息,这种信息虽然也是按关系数据库的存储结构存储的, 单与面向逐条记录的联机时务处理(OLTP)不同,在数据仓库中的一条记录,有可能是基础数据中若干个表、若干条记录的归纳和汇总。
数据仓库的基本特点是:
(1)面向对象性。数据仓库中存储的信息是面向主题来组织的。它
数据仓库与数据挖掘 数据仓库与数据挖掘论文
根据所需要的信息,分不同类、不同角度等主题把数据加工、整理之后存储起来(按横向对数据进行分类存储)。(www.61k.com)
(2)数据历史性。数据仓库中可以专门存储5 至10 年或更久的历史数据,数据具有时间标示,以满足信息比较、分析预测等的数据需求(按纵向对数据进行分类存储)。
(3)数据集成性。无论数据来源于何处,进入数据仓库后都具有统一的数据结构和编码规则, 数据仓库中的数据具有一致性的特点。
(4)数据只读性。数据仓库是一个信息源,它只是为在其上开发的DSS 或EIS 等提供信息服务,因此它应是只读数据库,一般不能轻易改动,只能定期刷新。
(5)操作集合性。数据仓库可通过快照机制,成批的更新来自不同资源的数据, 将其载入数据仓库; 也可以成批的访问数据。
(6)应用C/S(客户机/服务器)性。数据仓库通过定义信息(元信息)把整个数据组织起来。在元信息中有一类记录系统信息,定义了数据存储、修改权限等,记录系统将原始数据转换成适合于数据仓库应用的数据,所以这实际上是C/S 应用模式。
四、数据挖掘技术
数据挖掘是一种大型数据库(如数据仓库)中提取隐藏的预测性信息的新技术。数据挖掘是一种展望和预测性的信息分析工具,它能挖掘数据间潜在的关系模式,发现用户可能忽略的信息,为企业管理者提供前摄的(Proactive)、基于知识的决策。数据挖掘技术使DSS
数据仓库与数据挖掘 数据仓库与数据挖掘论文
的应用向效益型卖出了重要的一步。[www.61k.com]传统的DSS 通常是在某个假设的前提下通过数据查询和分析来验证或否定这个假设,而数据挖掘技术则能够自动分析数据,进行归纳性推理,从中发掘出潜在模式或产生联想,建立新的业务模型,帮助决策者调整市场策略,做出正确的决策。
五、一种基于DW 的DMS 结构框架
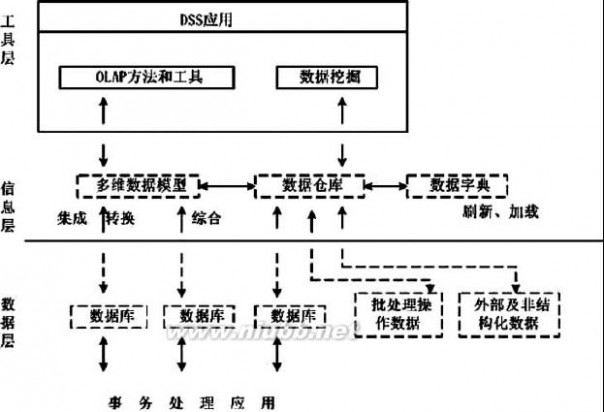
根据数据仓库系统的特点, 提出一种基于数据仓库的通用数据挖掘系统的结构框架,如图1。该结构框架的概念模型包括如下组成部分:
(1)用户查询接口它可分为查询分类、查询解释及规格化两部分。其作用是将数据挖掘请求解释成规格化的查询语言,并交由查询协同机处理。
(2)查询协同机它的工作是协同数据仓库管理系统、数据挖掘工具管理系统和知识库管理系统, 共同对查询接口提交的查询请求进行处理。
数据仓库与数据挖掘 数据仓库与数据挖掘论文
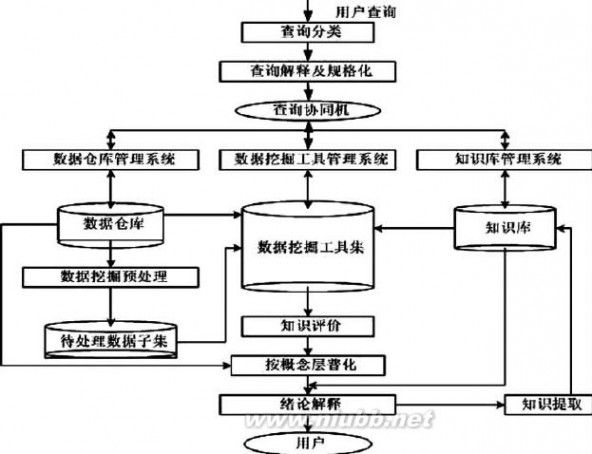
图1 一种基于数据仓库的数据挖掘系统的结构框架
(3)数据仓库管理系统它直接负责对数据仓库进行管理,并完成对各种异构分布数据源中数据的提取工作, 以最大限度屏蔽各异构数据源对系统的影响。(www.61k.com)
(4)知识库管理系统它对知识库进行管理和控制,包括知识的增加、删除、更新和查询等。一方面,处理由查询协同机处理后产生的知识库查询请求,并将结果提交给数据挖掘模块;另一方面,接受通过知识评价的知识模式,并存入知识库。
(5) 数据挖掘工具的管理系统它的作用是对数据挖掘工具进行管理。
(6) 数据挖掘预处理模块它的任务是在数据仓库管理系统的协同下,根据元数据和维表,对整个数据仓库中储存的数据进行处理,生
数据仓库与数据挖掘 数据仓库与数据挖掘论文
成符合用户查询需要的,并能满足数据挖掘工具集要求的待处理数据子集。(www.61k.com]
(7) 知识评价模块数据挖掘阶段发现出来的模式需要经过知识评价模块的评估。如果存在冗余或无关的模式,则将其剔除了;如果模式不能满足用户要求,则需要重新选取数据,设定新的数据挖掘参数值, 甚至更换数据挖掘算法重新进行数据挖掘。
(8) 结论表达模块它将得到的结论按语义层次结构进行普化,得出各语义层上的结论,并对其进行解释,将发现的模式以可视化或自然语言的形式呈现给用户。
六、基于数据仓库与数据挖掘技术的DSS 创建数据仓库的目的是为企业的DSS 和EIS 提供科学的决策依据。数据仓库用于大量数据存储和组织;数据挖掘用于从大量的数据中发现知识,为用户进行预测决策。数据挖掘以数据仓库和多维数据库为基础, 通过OLAP 和多维分析工具自动发现数据中的潜在模式,并以这些模式为基础自动做出预测。数据仓库与数据挖掘技术的结合为企业DSS 和EIS 的建立提供了新的、更有效的解决方案。图2 表明了这种方案的一种结构。
数据仓库与数据挖掘 数据仓库与数据挖掘论文
七、结束语
通过对数据仓库与数据挖掘教程的学习,我了解了数据仓库对相关数据进行分析的方法,以及用相关软件预测的步骤。[www.61k.com)并且懂得了企业未来的成功,很大程度上取决于准确的数据挖掘能力,许多领域都需要对潜在的数据进行深层次的分析,困难主要有对数据的一些概念和方法方法不太熟悉,导致思想比较懵懂,会时不时出现差错,导致出现的结果与预期的不一致。但总体来说还是有很多收获的,通过这次学习,我巩固了所学的理论知识,进一步理解了相关的概念和方法。也明白了一些深刻的道理,即在遇到困难时不要放弃,要有持之以恒的精神,遇到不懂的问题时要及时请教老师和同学,要在实际动手操
数据仓库与数据挖掘 数据仓库与数据挖掘论文
作时进一步完善自己的所学的知识,要善于思考,善于总结,这样才能有所学有所想,学有所得。[www.61k.com)
八、参考文献:
1、赖福军,周婷, 数据仓库及其本关技术, 软件世界, 1997.2
2、王珊,数据仓库联机分析处理数据挖掘.计算机世界报1997.01.06. P123-125
3 、骆斌, 面向对象的数据仓库技术的研究, 南京大学博士学位论文,1999.12 .
4、陈兆乾,周志华、骆斌、陈世福,"增量式IHMCAP 算法的研究及其应用",计算机学报,1998,8.
5、陈坚志 ,广东外语外贸大学,"数据仓库与数据挖掘在决策系统中的应用"
四 : Facebook在巴黎开设人工智能实验室 挖掘欧洲人才库

Facebook人工智能研究主管雅恩·乐库
凤凰科技讯 北京时间6月3日消息,据《华尔街日报》网络版报道,Facebook在巴黎开设了一个人工智能研究实验室,希望能够挖掘欧洲的大型人才库。
Facebook人工智能研究主管雅恩·乐库(Yann LeCun)表示:“它将为法国研究人员创造机会,并会建立一种围绕着Facebook的生态系统,供创业公司从事类似研究项目。”
乐库出生于法国,是一位知名人工智能研究员。他表示,长期以来,人工智能相关领域研究一直是法国的传统优势,比如深度学习、计算机视觉,它们能够教会软件以大致和人脑相同的方式识别语言和图像。
Facebook已经为巴黎人工智能实验室招募了6名研究员,从事理解婴儿如何学习言语和语言等项目。Facebook还招募了图像处理、文本分析、语音识别以及实时战略游戏领域的专家。Facebook首席技术官马克·斯科洛普夫(Mike Schroepfer)表示,公司计划在今年年底前再招募6名研究员,明年再招募20名至25名。
自2013年招募乐库后,Facebook在一直在大力投资人工智能这个曾经的小众领域。Facebook在纽约和加州门洛帕克的人工智能研究团队目前有大约50名研究员。Facebook发言人迈克·科克兰德(Mike Kirkland)表示,随着巴黎人工智能实验室的开设,每一家实验室最终将拥有40名至50名研究员。
Facebook的人工智能研究目前正被用于图像标记、预测话题趋势以及面部识别。所有这些服务都需要使用算法筛选海量数据,比如图片、书面信息以及视频,以就内容和上下文作出正确判断。
乐库称,图像和视频识别将是Facebook的“下一条战线”。(编译/箫雨)
五 : Twitter正与微软谷歌进行数据挖掘合作谈判
北京时间10月8日晚间消息,据国外科技博客报道,消息人士周四称,Twitter正在与微软和谷歌就数据挖掘合作分别进行谈判,该交易将允许两家搜索引擎在搜索结果中整合Twitter的消息。
消息人士透露,谈判双方正在讨论各种可能的方案,包括如何向Twitter支付报酬。目前Twitter每月有5400万用户,可发布数亿条实时的Twitter消息。消息人士称,支付方式可能包括搜索引擎向Twitter支付数百万美元,并根据搜索所带来的广告收入进行分成。
消息人士强调称,与微软和谷歌的协议并非独家,这意味着雅虎也可以获得Twitter的内容授权,但并不清楚雅虎是否也在与Twitter进行类似谈判。7月底,雅虎和微软达成了搜索技术与网络广告合作协议。消息人士指出,谈判各方最后也有可能无法达成协议。
由于Twitter很难在搜索引擎方面与微软和谷歌竞争,因此与后两家的合作将很有意义。Twitter的目标是打造大型开放式平台,允许搜索引擎、营销商、发行商以及开发人员与其平台进行整合。Twitter也曾考虑向上述各方提供付费服务,同时也在考虑采用广告模式。
Twitter上月刚刚融资1亿美元,此前该公司已融资5500万美元。尽管Twitter的收入规模仍微不足道,但此次融资对该网站的估值达到了10亿美元。(肖恩)
本文标题:数据仓库与数据挖掘-数据仓库与数据挖掘在天气预报中的作用4161阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1