一 : 深入分析新老访客数据 为站点创造更多价值
作为站长,我们每天都要分析网站的数据。尤其是在访客数据的分析是十分的重要的。在访客的分析之中我们都会分析道网站的新访客与老访客之间的数据。简单地说,新访客就是第一次访问站点或者第一次使用站点服务的访客;而老访客则是之前已经造访过我们的站点或者使用过站点服务的访客。无论是新老访客都能为网站带来价值,这也是分析的意义所在。
那么分析新老访客对我们的站点有什么具体意义
我们站点的老访客一般都是我们站点的死忠粉丝,对于我们的站点有相对较高的粘度,同时也是为站点带来真正盈利的主要群体。那么新访客对于我们的站点有什么意义呢?对于新访客我们可以说其意味着站点的业务发展,是网站不断发展向上的前提。我们也可以简单的说说,老访客是网站生存的基础,而新访客则是我们站点发展源源不绝的动力,所以我们的站点访客发展路线是在保留老访客的基础上不断地提升新访客数。
对此分析新老访客的意义就昭然若揭了:我们通过分析老访客,可以确定网站近期的运营推广是否稳固,是否在走下坡路。通过分析新访客,我们也可以衡量网站近期的发展是否步伐是否有迈出,是否有更大的发展空间。可以说两个分析一个是着眼于现在,一个放眼未来。
那么我们要如何区分新老访客
对于新老访客的区分我们可以借助不同的工具及模式。最常见的一个区分模式就是分析访客之前是否有访问过我们的站点,是否是第一次访问。谷歌的分析工具GA定义新老访客的方式就是通过用户电脑上的缓存cookie文件,原理就是如果这个访客存有我们网站的缓存的话那他就是老访客,反之则为新访客。这个方法也存在着一定的局限性,那就是访客可能会删除缓存或者更换电脑,这就容易造成数据的偏差。这种方式一般出现在一些流量统计分析工具上。
当然如果你的站点是需要用户登录才能访问的网站,那么你就可以将那些首次注册登录的访客定义为新访客,那些再次登录的则为站点的老访客。这样的数据相对准确,但是使用的范围也相对局限。
如何对于站点的新老访客进行分析
对于我们的站点来说,我们的发展目标当然是在维持老访客的同时不断的拓展新访客,那么我们要如何从网站的数据进行分析呢?对于那些正常正规的站点来说,站点的老访客数应该是保持相对稳定的,并且有不断的微幅的上涨才是正常的。下图就是笔者站点在谷歌分析工具中该比例的微幅变化:

老访客曲线图
我们可以点击谷歌分析工具菜单栏上的Dashboard点击Advanced Segments然后我们选择Returning Visitors,我们可以根据我们想要查看的时间来设置相关年月日,获得更加准确的信息。上图的这条曲线表示笔者的站点老访客处于稳步的增长中,这是一种正常的表现。当然有的站点的曲线并不会这么的平滑,原因除了网站自身的原因外还与一些外在因素有干系,例如旅游站点,而这一类型的站点会受到季节、节日灯严重的影响,对此波动也会较大。对此我们可以通过分析同比(与去年同期的数据进行比较)及环比(今年不同时间段的对比)来获得更加准确的数据。对于我们的站点来说,访问量、销售额、利润等网站关键指标同样可以引用同比和环比进行更加深入的数据分析,这样就可以打消因为季节、节日等外在因素对于我们数据的误差影响。
对于我们的站点来说新老访客的分析有着重要的作用。只有我们真正分析好我们的新老访客才能更加深入的了解到我们的站点所存在的问题并加以更正,希望本文对于那些对于大家在分析访客数据上有所帮助。
本文来源:NC送料机http://www.ncsongliaoji.com 转载请保留出处。
二 : Android深入浅出之Audio 第一部分 AudioTrack分析
Android深入浅出之Audio
第一部分 AudioTrack分析
一 目的
本文的目的是通过从Audio系统来分析Android的代码,包括Android自定义的那套机制和一些常见类的使用,比如Thread,MemoryBase等。(www.61k.com)
分析的流程是:
l 先从API层对应的某个类开始,用户层先要有一个简单的使用流程。
l 根据这个流程,一步步进入到JNI,服务层。在此过程中,碰到不熟悉或者第一次见到的类或者方法,都会解释。也就是深度优先的方法。
1.1 分析工具
分析工具很简单,就是sourceinsight和android的API doc文档。当然还得有android的源代码。我这里是基于froyo的源码。
注意,froyo源码太多了,不要一股脑的加入到sourceinsight中,只要把framwork目录下的源码加进去就可以了,后续如要用的话,再加别的目录。
二 Audio系统
先看看Audio里边有哪些东西?通过Android的SDK文档,发现主要有三个:
l AudioManager:这个主要是用来管理Audio系统的
l AudioTrack:这个主要是用来播放声音的
l AudioRecord:这个主要是用来录音的
其中AudioManager的理解需要考虑整个系统上声音的策略问题,例如来电话铃声,短信铃声等,主要是策略上的问题。一般看来,最简单的就是播放声音了。所以我们打算从AudioTrack开始分析。
三 AudioTrack(JAVA层)
JAVA的AudioTrack类的代码在:
framework\base\media\java\android\media\AudioTrack.java中。
3.1 AudioTrack API的使用例子
先看看使用例子,然后跟进去分析。至于AudioTrack的其他使用方法和说明,需要大家自己去看API文档了。
//根据采样率,采样精度,单双声道来得到frame的大小。
int bufsize = AudioTrack.getMinBufferSize(8000,//每秒8K个点
AudioFormat.CHANNEL_CONFIGURATION_STEREO,//双声道
AudioFormat.ENCODING_PCM_16BIT);//一个采样点16比特-2个字节
//注意,按照数字音频的知识,这个算出来的是一秒钟buffer的大小。
//创建AudioTrack
AudioTrack trackplayer = new AudioTrack(AudioManager.STREAM_MUSIC, 8000,
AudioFormat.CHANNEL_CONFIGURATION_ STEREO,
AudioFormat.ENCODING_PCM_16BIT,
bufsize,
AudioTrack.MODE_STREAM);//
trackplayer.play() ;//开始
trackplayer.write(bytes_pkg, 0, bytes_pkg.length) ;//往track中写数据
….
trackplayer.stop();//停止播放
trackplayer.release();//释放底层资源。
这里需要解释下两个东西:
1 AudioTrack.MODE_STREAM的意思:
AudioTrack中有MODE_STATIC和MODE_STREAM两种分类。STREAM的意思是由用户在应用程序通过write方式把数据一次一次得写到audiotrack中。这个和我们在socket中发送数据一样,应用层从某个地方获取数据,例如通过编解码得到PCM数据,然后write到audiotrack。
这种方式的坏处就是总是在JAVA层和Native层交互,效率损失较大。
而STATIC的意思是一开始创建的时候,就把音频数据放到一个固定的buffer,然后直接传给audiotrack,后续就不用一次次得write了。AudioTrack会自己播放这个buffer中的数据。
这种方法对于铃声等内存占用较小,延时要求较高的声音来说很适用。
2 StreamType
这个在构造AudioTrack的第一个参数中使用。这个参数和Android中的AudioManager有关系,涉及到手机上的音频管理策略。
Android将系统的声音分为以下几类常见的(未写全):
l STREAM_ALARM:警告声
l STREAM_MUSCI:音乐声,例如music等
l STREAM_RING:铃声
l STREAM_SYSTEM:系统声音
l STREAM_VOCIE_CALL:电话声音
为什么要分这么多呢?以前在台式机上开发的时候很少知道有这么多的声音类型,不过仔细思考下,发现这样做是有道理的。例如你在听music的时候接到电话,这个时候music播放肯定会停止,此时你只能听到电话,如果你调节音量的话,这个调节肯定只对电话起作用。当电话打完了,再回到music,你肯定不用再调节音量了。
其实系统将这几种声音的数据分开管理,所以,这个参数对AudioTrack来说,它的含义就是告诉系统,我现在想使用的是哪种类型的声音,这样系统就可以对应管理他们了。
3.2 分析之getMinBufferSize
AudioTrack的例子就几个函数。先看看第一个函数:
AudioTrack.getMinBufferSize(8000,//每秒8K个点
AudioFormat.CHANNEL_CONFIGURATION_STEREO,//双声道
AudioFormat.ENCODING_PCM_16BIT);
----->AudioTrack.JAVA
//注意,这是个static函数
static public int getMinBufferSize(int sampleRateInHz, int channelConfig, int audioFormat) {
int channelCount = 0;
switch(channelConfig) {
case AudioFormat.CHANNEL_OUT_MONO:
case AudioFormat.CHANNEL_CONFIGURATION_MONO:
channelCount = 1;
break;
case AudioFormat.CHANNEL_OUT_STEREO:
扩展:android audiotrack / android audio track / audiotrack
case AudioFormat.CHANNEL_CONFIGURATION_STEREO:
channelCount = 2;--->看到了吧,外面名字搞得这么酷,其实就是指声道数
break;
default:
loge("getMinBufferSize(): Invalid channel configuration.");
return AudioTrack.ERROR_BAD_VALUE;
}
//目前只支持PCM8和PCM16精度的音频
if ((audioFormat != AudioFormat.ENCODING_PCM_16BIT)
&& (audioFormat != AudioFormat.ENCODING_PCM_8BIT)) {
loge("getMinBufferSize(): Invalid audio format.");
return AudioTrack.ERROR_BAD_VALUE;
}
//ft,对采样频率也有要求,太低或太高都不行,人耳分辨率在20HZ到40KHZ之间
if ( (sampleRateInHz < 4000) || (sampleRateInHz > 48000) ) {
loge("getMinBufferSize(): " + sampleRateInHz +"Hz is not a supported sample rate.");
return AudioTrack.ERROR_BAD_VALUE;
}
//调用native函数,够烦的,什么事情都搞到JNI层去。
int size = native_get_min_buff_size(sampleRateInHz, channelCount, audioFormat);
if ((size == -1) || (size == 0)) {
loge("getMinBufferSize(): error querying hardware");
return AudioTrack.ERROR;
}
else {
return size;
}
native_get_min_buff_size--->在framework/base/core/jni/android_media_track.cpp中实现。(不了解JNI的一定要学习下,否则只能在JAVA层搞,太狭隘了。)最终对应到函数
static jint android_media_AudioTrack_get_min_buff_size(JNIEnv *env, jobject thiz,
jint sampleRateInHertz, jint nbChannels, jint audioFormat)
{//注意我们传入的参数是:
//sampleRateInHertz = 8000
//nbChannels = 2;
//audioFormat = AudioFormat.ENCODING_PCM_16BIT
int afSamplingRate;
int afFrameCount;
uint32_t afLatency;
//下面涉及到AudioSystem,这里先不解释了,
//反正知道从AudioSystem那查询了一些信息
if (AudioSystem::getOutputSamplingRate(&afSamplingRate) != NO_ERROR) {
return -1;
}
if (AudioSystem::getOutputFrameCount(&afFrameCount) != NO_ERROR) {
return -1;
}
if (AudioSystem::getOutputLatency(&afLatency) != NO_ERROR) {
return -1;
}
//音频中最常见的是frame这个单位,什么意思?经过多方查找,最后还是在ALSA的wiki中
//找到解释了。一个frame就是1个采样点的字节数*声道。为啥搞个frame出来?因为对于多//声道的话,用1个采样点的字节数表示不全,因为播放的时候肯定是多个声道的数据都要播出来//才行。所以为了方便,就说1秒钟有多少个frame,这样就能抛开声道数,把意思表示全了。
// Ensure that buffer depth covers at least audio hardware latency
uint32_t minBufCount = afLatency / ((1000 * afFrameCount)/afSamplingRate);
if (minBufCount < 2) minBufCount = 2;
uint32_t minFrameCount =
(afFrameCount*sampleRateInHertz*minBufCount)/afSamplingRate;
//下面根据最小的framecount计算最小的buffersize
int minBuffSize = minFrameCount
* (audioFormat == javaAudioTrackFields.PCM16 ? 2 : 1)
* nbChannels;
return minBuffSize;
}
getMinBufSize函数完了后,我们得到一个满足最小要求的缓冲区大小。这样用户分配缓冲区就有了依据。下面就需要创建AudioTrack对象了
扩展:android audiotrack / android audio track / audiotrack
3.3 分析之new AudioTrack
先看看调用函数:
AudioTrack trackplayer = new AudioTrack(
AudioManager.STREAM_MUSIC,
8000,
AudioFormat.CHANNEL_CONFIGURATION_ STEREO,
AudioFormat.ENCODING_PCM_16BIT,
bufsize,
AudioTrack.MODE_STREAM);//
其实现代码在AudioTrack.java中。
public AudioTrack(int streamType, int sampleRateInHz, int channelConfig, int audioFormat,
int bufferSizeInBytes, int mode)
throws IllegalArgumentException {
mState = STATE_UNINITIALIZED;
// 获得主线程的Looper,这个在MediaScanner分析中已经讲过了
if ((mInitializationLooper = Looper.myLooper()) == null) {
mInitializationLooper = Looper.getMainLooper();
}
//检查参数是否合法之类的,可以不管它
audioParamCheck(streamType, sampleRateInHz, channelConfig, audioFormat, mode);
//我是用getMinBufsize得到的大小,总不会出错吧?
audioBuffSizeCheck(bufferSizeInBytes);
// 调用native层的native_setup,把自己的WeakReference传进去了
//不了解JAVA WeakReference的可以上网自己查一下,很简单的
int initResult = native_setup(new WeakReference<AudioTrack>(this),
mStreamType, 这个值是AudioManager.STREAM_MUSIC
mSampleRate, 这个值是8000
mChannels, 这个值是2
mAudioFormat,这个值是AudioFormat.ENCODING_PCM_16BIT
mNativeBufferSizeInBytes, //这个是刚才getMinBufSize得到的
mDataLoadMode);DataLoadMode是MODE_STREAM
....
}
上面函数调用最终进入了JNI层android_media_AudioTrack.cpp下面的函数
static int
android_media_AudioTrack_native_setup(JNIEnv *env, jobject thiz, jobject weak_this,
jint streamType, jint sampleRateInHertz, jint channels,
jint audioFormat, jint buffSizeInBytes, jint memoryMode)
{
int afSampleRate;
int afFrameCount;
下面又要调用一堆东西,烦不烦呐?具体干什么用的,以后分析到AudioSystem再说。
AudioSystem::getOutputFrameCount(&afFrameCount, streamType);
AudioSystem::getOutputSamplingRate(&afSampleRate, streamType);
AudioSystem::isOutputChannel(channels);
popCount是统计一个整数中有多少位为1的算法
int nbChannels = AudioSystem::popCount(channels);
if (streamType == javaAudioTrackFields.STREAM_MUSIC) {
atStreamType = AudioSystem::MUSIC;
}
int bytesPerSample = audioFormat == javaAudioTrackFields.PCM16 ? 2 : 1;
int format = audioFormat == javaAudioTrackFields.PCM16 ?
AudioSystem::PCM_16_BIT : AudioSystem::PCM_8_BIT;
int frameCount = buffSizeInBytes / (nbChannels * bytesPerSample);
//上面是根据Buffer大小和一个Frame大小来计算帧数的。
// AudioTrackJniStorage,就是一个保存一些数据的地方,这
//里边有一些有用的知识,下面再详细解释
AudioTrackJniStorage* lpJniStorage = new AudioTrackJniStorage();
jclass clazz = env->GetObjectClass(thiz);
lpJniStorage->mCallbackData.audioTrack_class = (jclass)env->NewGlobalRef(clazz);
lpJniStorage->mCallbackData.audioTrack_ref = env->NewGlobalRef(weak_this);
lpJniStorage->mStreamType = atStreamType;
//创建真正的AudioTrack对象
AudioTrack* lpTrack = new AudioTrack();
if (memoryMode == javaAudioTrackFields.MODE_STREAM) {
//如果是STREAM流方式的话,把刚才那些参数设进去
lpTrack->set(
atStreamType,// stream type
sampleRateInHertz,
format,// word length, PCM
channels,
扩展:android audiotrack / android audio track / audiotrack
frameCount,
0,// flags
audioCallback,
&(lpJniStorage->mCallbackData),//callback, callback data (user)
0,// notificationFrames == 0 since not using EVENT_MORE_DATA to feed the AudioTrack
0,// 共享内存,STREAM模式需要用户一次次写,所以就不用共享内存了
true);// thread can call Java
} else if (memoryMode == javaAudioTrackFields.MODE_STATIC) {
//如果是static模式,需要用户一次性把数据写进去,然后
//再由audioTrack自己去把数据读出来,所以需要一个共享内存
//这里的共享内存是指C++AudioTrack和AudioFlinger之间共享的内容
//因为真正播放的工作是由AudioFlinger来完成的。
lpJniStorage->allocSharedMem(buffSizeInBytes);
lpTrack->set(
atStreamType,// stream type
sampleRateInHertz,
format,// word length, PCM
channels,
frameCount,
0,// flags
audioCallback,
&(lpJniStorage->mCallbackData),//callback, callback data (user));
0,// notificationFrames == 0 since not using EVENT_MORE_DATA to feed the AudioTrack
lpJniStorage->mMemBase,// shared mem
true);// thread can call Java
}
if (lpTrack->initCheck() != NO_ERROR) {
LOGE("Error initializing AudioTrack");
goto native_init_failure;
}
//又来这一招,把C++AudioTrack对象指针保存到JAVA对象的一个变量中
//这样,Native层的AudioTrack对象就和JAVA层的AudioTrack对象关联起来了。
env->SetIntField(thiz, javaAudioTrackFields.nativeTrackInJavaObj, (int)lpTrack);
env->SetIntField(thiz, javaAudioTrackFields.jniData, (int)lpJniStorage);
}
1 AudioTrackJniStorage详解
这个类其实就是一个辅助类,但是里边有一些知识很重要,尤其是Android封装的一套共享内存的机制。这里一并讲解,把这块搞清楚了,我们就能轻松得在两个进程间进行内存的拷贝。
AudioTrackJniStorage的代码很简单。
struct audiotrack_callback_cookie {
jclass audioTrack_class;
jobject audioTrack_ref;
}; cookie其实就是把JAVA中的一些东西保存了下,没什么特别的意义
class AudioTrackJniStorage {
public:
sp<MemoryHeapBase> mMemHeap;//这两个Memory很重要
sp<MemoryBase> mMemBase;
audiotrack_callback_cookie mCallbackData;
int mStreamType;
bool allocSharedMem(int sizeInBytes) {
mMemHeap = new MemoryHeapBase(sizeInBytes, 0, "AudioTrack Heap Base");
mMemBase = new MemoryBase(mMemHeap, 0, sizeInBytes);
//注意用法,先弄一个HeapBase,再把HeapBase传入到MemoryBase中去。
return true;
}
};
2 MemoryHeapBase
MemroyHeapBase也是Android搞的一套基于Binder机制的对内存操作的类。既然是Binder机制,那么肯定有一个服务端(Bnxxx),一个代理端Bpxxx。看看MemoryHeapBase定义:
class MemoryHeapBase : public virtual BnMemoryHeap
{
果然,从BnMemoryHeap派生,那就是Bn端。这样就和Binder挂上钩了
扩展:android audiotrack / android audio track / audiotrack
//Bp端调用的函数最终都会调到Bn这来
对Binder机制不了解的,可以参考:
http://blog.csdn.net/Innost/archive/2011/01/08/6124685.aspx
有好几个构造函数,我们看看我们使用的:
MemoryHeapBase::MemoryHeapBase(size_t size, uint32_t flags, char const * name)
: mFD(-1), mSize(0), mBase(MAP_FAILED), mFlags(flags),
mDevice(0), mNeedUnmap(false)
{
const size_t pagesize = getpagesize();
size = ((size + pagesize-1) & ~(pagesize-1));
//创建共享内存,ashmem_create_region这个是系统提供的,可以不管它
//设备上打开的是/dev/ashmem设备,而Host上打开的是一个tmp文件
int fd = ashmem_create_region(name == NULL ? "MemoryHeapBase" : name, size);
mapfd(fd, size);//把刚才那个fd通过mmap方式得到一块内存
//不明白得去man mmap看看
mapfd完了后,mBase变量指向内存的起始位置, mSize是分配的内存大小,mFd是
ashmem_create_region返回的文件描述符
}
MemoryHeapBase提供了一下几个函数,可以获取共享内存的大小和位置。
getBaseID()--->返回mFd,如果为负数,表明刚才创建共享内存失败了
getBase()->返回mBase,内存位置
getSize()->返回mSize,内存大小
有了MemoryHeapBase,又搞了一个MemoryBase,这又是一个和Binder机制挂钩的类。
唉,这个估计是一个在MemoryHeapBase上的方便类吧?因为我看见了offset
那么估计这个类就是一个能返回当前Buffer中写位置(就是offset)的方便类
这样就不用用户到处去计算读写位置了。
class MemoryBase : public BnMemory
{
public:
MemoryBase(const sp<IMemoryHeap>& heap, ssize_t offset, size_t size);
virtual sp<IMemoryHeap> getMemory(ssize_t* offset, size_t* size) const;
protected:
size_t getSize() const { return mSize; }
ssize_t getOffset() const { return mOffset; }
const sp<IMemoryHeap>& getHeap() const { return mHeap; }
};
好了,明白上面两个MemoryXXX,我们可以猜测下大概的使用方法了。
l BnXXX端先分配BnMemoryHeapBase和BnMemoryBase,
l 然后把BnMemoryBase传递到BpXXX
l BpXXX就可以使用BpMemoryBase得到BnXXX端分配的共享内存了。
注意,既然是进程间共享内存,那么Bp端肯定使用memcpy之类的函数来操作内存,这些函数是没有同步保护的,而且Android也不可能在系统内部为这种共享内存去做增加同步保护。所以看来后续在操作这些共享内存的时候,肯定存在一个跨进程的同步保护机制。我们在后面讲实际播放的时候会碰到。
另外,这里的SharedBuffer最终会在Bp端也就是AudioFlinger那用到。
3.4 分析之play和write
JAVA层到这一步后就是调用play和write了。JAVA层这两个函数没什么内容,都是直接转到native层干活了。
先看看play函数对应的JNI函数
static void
android_media_AudioTrack_start(JNIEnv *env, jobject thiz)
{
//看见没,从JAVA那个AudioTrack对象获取保存的C++层的AudioTrack对象指针
//从int类型直接转换成指针。要是以后ARM变成64位平台了,看google怎么改!
AudioTrack *lpTrack = (AudioTrack *)env->GetIntField(
thiz, javaAudioTrackFields.nativeTrackInJavaObj);
lpTrack->start(); //这个以后再说
}
下面是write。我们写的是short数组,
static jint
android_media_AudioTrack_native_write_short(JNIEnv *env, jobject thiz,
jshortArray javaAudioData,
jint offsetInShorts,
jint sizeInShorts,
jint javaAudioFormat) {
return (android_media_AudioTrack_native_write(env, thiz,
(jbyteArray) javaAudioData,
offsetInShorts*2, sizeInShorts*2,
扩展:android audiotrack / android audio track / audiotrack
javaAudioFormat)
/ 2);
}
烦人,又根据Byte还是Short封装了下,最终会调到重要函数writeToTrack去
jint writeToTrack(AudioTrack* pTrack, jint audioFormat, jbyte* data,
jint offsetInBytes, jint sizeInBytes) {
ssize_t written = 0;
// regular write() or copy the data to the AudioTrack's shared memory?
if (pTrack->sharedBuffer() == 0) {
//创建的是流的方式,所以没有共享内存在track中
//还记得我们在native_setup中调用的set吗?流模式下AudioTrackJniStorage可没创建
//共享内存
written = pTrack->write(data + offsetInBytes, sizeInBytes);
} else {
if (audioFormat == javaAudioTrackFields.PCM16) {
// writing to shared memory, check for capacity
if ((size_t)sizeInBytes > pTrack->sharedBuffer()->size()) {
sizeInBytes = pTrack->sharedBuffer()->size();
}
//看见没?STATIC模式的,就直接把数据拷贝到共享内存里
//当然,这个共享内存是pTrack的,是我们在set时候把AudioTrackJniStorage的
//共享设进去的
memcpy(pTrack->sharedBuffer()->pointer(),
data + offsetInBytes, sizeInBytes);
written = sizeInBytes;
} else if (audioFormat == javaAudioTrackFields.PCM8) {
PCM8格式的要先转换成PCM16
}
return written;
}
到这里,似乎很简单啊,JAVA层的AudioTrack,无非就是调用write函数,而实际由JNI层的C++ AudioTrack write数据。反正JNI这层是再看不出什么有意思的东西了。
四 AudioTrack(C++层)
接上面的内容,我们知道在JNI层,有以下几个步骤:
l new了一个AudioTrack
l 调用set函数,把AudioTrackJniStorage等信息传进去
l 调用了AudioTrack的start函数
l 调用AudioTrack的write函数
那么,我们就看看真正干活的的C++AudioTrack吧。
AudioTrack.cpp位于framework\base\libmedia\AudioTrack.cpp
4.1 new AudioTrack()和set调用
JNI层调用的是最简单的构造函数:
AudioTrack::AudioTrack()
: mStatus(NO_INIT) //把状态初始化成NO_INIT。Android大量使用了设计模式中的state。
{
}
接下来调用set。我们看看JNI那set了什么
lpTrack->set(
atStreamType, //应该是Music吧
sampleRateInHertz,//8000
format,// 应该是PCM_16吧
channels,//立体声=2
frameCount,//
0,// flags
audioCallback, //JNI中的一个回调函数
&(lpJniStorage->mCallbackData),//回调函数的参数
0,// 通知回调函数,表示AudioTrack需要数据,不过暂时没用上
0,//共享buffer地址,stream模式没有
true);//回调线程可以调JAVA的东西
那我们看看set函数把。
status_t AudioTrack::set(
int streamType,
uint32_t sampleRate,
int format,
int channels,
int frameCount,
扩展:android audiotrack / android audio track / audiotrack
uint32_t flags,
callback_t cbf,
void* user,
int notificationFrames,
const sp<IMemory>& sharedBuffer,
bool threadCanCallJava)
{
...前面一堆的判断,等以后讲AudioSystem再说
audio_io_handle_t output =
AudioSystem::getOutput((AudioSystem::stream_type)streamType,
sampleRate, format, channels, (AudioSystem::output_flags)flags);
//createTrack?看来这是真正干活的
status_t status = createTrack(streamType, sampleRate, format, channelCount,
frameCount, flags, sharedBuffer, output);
//cbf是JNI传入的回调函数audioCallback
if (cbf != 0) { //看来,怎么着也要创建这个线程了!
mAudioTrackThread = new AudioTrackThread(*this, threadCanCallJava);
}
return NO_ERROR;
}
看看真正干活的createTrack
status_t AudioTrack::createTrack(
int streamType,
uint32_t sampleRate,
int format,
int channelCount,
int frameCount,
uint32_t flags,
const sp<IMemory>& sharedBuffer,
audio_io_handle_t output)
{
status_t status;
//啊,看来和audioFlinger挂上关系了呀。
const sp<IAudioFlinger>& audioFlinger = AudioSystem::get_audio_flinger();
//下面这个调用最终会在AudioFlinger中出现。暂时不管它。
sp<IAudioTrack> track = audioFlinger->createTrack(getpid(),
streamType,
sampleRate,
format,
channelCount,
frameCount,
((uint16_t)flags) << 16,
sharedBuffer,
output,
扩展:android audiotrack / android audio track / audiotrack
&status);
//看见没,从track也就是AudioFlinger那边得到一个IMemory接口
//这个看来就是最终write写入的地方
sp<IMemory> cblk = track->getCblk();
mAudioTrack.clear();
mAudioTrack = track;
mCblkMemory.clear();//sp<XXX>的clear,就看着做是delete XXX吧
mCblkMemory = cblk;
mCblk = static_cast<audio_track_cblk_t*>(cblk->pointer());
mCblk->out = 1;
mFrameCount = mCblk->frameCount;
if (sharedBuffer == 0) {
//终于看到buffer相关的了。注意我们这里的情况
//STREAM模式没有传入共享buffer,但是数据确实又需要buffer承载。
//反正AudioTrack是没有创建buffer,那只能是刚才从AudioFlinger中得到
//的buffer了。
mCblk->buffers = (char*)mCblk + sizeof(audio_track_cblk_t);
}
return NO_ERROR;
}
还记得我们说MemoryXXX没有同步机制,所以这里应该有一个东西能体现同步的,
那么我告诉大家,就在audio_track_cblk_t结构中。它的头文件在
framework/base/include/private/media/AudioTrackShared.h
实现文件就在AudioTrack.cpp中
audio_track_cblk_t::audio_track_cblk_t()
//看见下面的SHARED没?都是表示跨进程共享的意思。这个我就不跟进去说了
//等以后介绍同步方面的知识时,再细说
: lock(Mutex::SHARED), cv(Condition::SHARED), user(0), server(0),
userBase(0), serverBase(0), buffers(0), frameCount(0),
loopStart(UINT_MAX), loopEnd(UINT_MAX), loopCount(0), volumeLR(0),
flowControlFlag(1), forceReady(0)
{
}
到这里,大家应该都有个大概的全景了。
l AudioTrack得到AudioFlinger中的一个IAudioTrack对象,这里边有一个很重要的数据结构audio_track_cblk_t,它包括一块缓冲区地址,包括一些进程间同步的内容,可能还有数据位置等内容
l AudioTrack启动了一个线程,叫AudioTrackThread,这个线程干嘛的呢?还不知道
l AudioTrack调用write函数,肯定是把数据写到那块共享缓冲了,然后IAudioTrack在另外一个进程AudioFlinger中(其实AudioFlinger是一个服务,在mediaservice中运行)接收数据,并最终写到音频设备中。
那我们先看看AudioTrackThread干什么了。
调用的语句是:
mAudioTrackThread = new AudioTrackThread(*this, threadCanCallJava);
AudioTrackThread从Thread中派生,这个内容在深入浅出Binder机制讲过了。
反正最终会调用AudioTrackAThread的threadLoop函数。
先看看构造函数
AudioTrack::AudioTrackThread::AudioTrackThread(AudioTrack& receiver, bool bCanCallJava)
: Thread(bCanCallJava), mReceiver(receiver)
{ //mReceiver就是AudioTrack对象
// bCanCallJava为TRUE
}
这个线程的启动由AudioTrack的start函数触发。
void AudioTrack::start()
{
//start函数调用AudioTrackThread函数触发产生一个新的线程,执行mAudioTrackThread的
threadLoop
sp<AudioTrackThread> t = mAudioTrackThread;
t->run("AudioTrackThread", THREAD_PRIORITY_AUDIO_CLIENT);
//让AudioFlinger中的track也start
status_t status = mAudioTrack->start();
}
bool AudioTrack::AudioTrackThread::threadLoop()
{
//太恶心了,又调用AudioTrack的processAudioBuffer函数
return mReceiver.processAudioBuffer(this);
}
bool AudioTrack::processAudioBuffer(const sp<AudioTrackThread>& thread)
{
Buffer audioBuffer;
uint32_t frames;
size_t writtenSize;
...回调1
mCbf(EVENT_UNDERRUN, mUserData, 0);
...回调2 都是传递一些信息到JNI里边
mCbf(EVENT_BUFFER_END, mUserData, 0);
// Manage loop end callback
while (mLoopCount > mCblk->loopCount) {
mCbf(EVENT_LOOP_END, mUserData, (void *)&loopCount);
}
//下面好像有写数据的东西
do {
audioBuffer.frameCount = frames;
//获得buffer,
status_t err = obtainBuffer(&audioBuffer, 1);
size_t reqSize = audioBuffer.size;
扩展:android audiotrack / android audio track / audiotrack
//把buffer回调到JNI那去,这是单独一个线程,而我们还有上层用户在那不停
//地write呢,怎么会这样?
mCbf(EVENT_MORE_DATA, mUserData, &audioBuffer);
audioBuffer.size = writtenSize;
frames -= audioBuffer.frameCount;
releaseBuffer(&audioBuffer); //释放buffer,和obtain相对应,看来是LOCK和UNLOCK
操作了
}
while (frames);
return true;
}
难道真的有两处在write数据?看来必须得到mCbf去看看了,传的是EVENT_MORE_DATA标志。
mCbf由set的时候传入C++的AudioTrack,实际函数是:
static void audioCallback(int event, void* user, void *info) {
if (event == AudioTrack::EVENT_MORE_DATA) {
//哈哈,太好了,这个函数没往里边写数据
AudioTrack::Buffer* pBuff = (AudioTrack::Buffer*)info;
pBuff->size = 0;
}
从代码上看,本来google考虑是异步的回调方式来写数据,可惜发现这种方式会比较复杂,尤其是对用户开放的JAVA AudioTrack会很不好处理,所以嘛,偷偷摸摸得给绕过去了。
太好了,看来就只有用户的write会真正的写数据了,这个AudioTrackThread除了通知一下,也没什么实际有意义的操作了。
让我们看看write吧。
4.2 write
ssize_t AudioTrack::write(const void* buffer, size_t userSize)
{
够简单,就是obtainBuffer,memcpy数据,然后releasBuffer
眯着眼睛都能想到,obtainBuffer一定是Lock住内存了,releaseBuffer一定是unlock内存了
do {
audioBuffer.frameCount = userSize/frameSize();
status_t err = obtainBuffer(&audioBuffer, -1);
size_t toWrite;
toWrite = audioBuffer.size;
memcpy(audioBuffer.i8, src, toWrite);
src += toWrite;
}
userSize -= toWrite;
written += toWrite;
releaseBuffer(&audioBuffer);
} while (userSize);
return written;
}
obtainBuffer太复杂了,不过大家知道其大概工作方式就可以了
status_t AudioTrack::obtainBuffer(Buffer* audioBuffer, int32_t waitCount)
{
//恕我中间省略太多,大部分都是和当前数据位置相关,
uint32_t framesAvail = cblk->framesAvailable();
cblk->lock.lock();//看见没,lock了
result = cblk->cv.waitRelative(cblk->lock, milliseconds(waitTimeMs));
//我发现很多地方都要判断远端的AudioFlinger的状态,比如是否退出了之类的,难道
//没有一个好的方法来集中处理这种事情吗?
if (result == DEAD_OBJECT) {
result = createTrack(mStreamType, cblk->sampleRate, mFormat, mChannelCount,
mFrameCount, mFlags, mSharedBuffer,getOutput());
}
//得到buffer
audioBuffer->raw = (int8_t *)cblk->buffer(u);
return active ? status_t(NO_ERROR) : status_t(STOPPED);
}
在看看releaseBuffer
void AudioTrack::releaseBuffer(Buffer* audioBuffer)
{
audio_track_cblk_t* cblk = mCblk;
cblk->stepUser(audioBuffer->frameCount);
}
uint32_t audio_track_cblk_t::stepUser(uint32_t frameCount)
{
uint32_t u = this->user;
u += frameCount;
if (out) {
if (bufferTimeoutMs == MAX_STARTUP_TIMEOUT_MS-1) {
bufferTimeoutMs = MAX_RUN_TIMEOUT_MS;
}
} else if (u > this->server) {
u = this->server;
}
if (u >= userBase + this->frameCount) {
userBase += this->frameCount;
}
this->user = u;
flowControlFlag = 0;
return u;
}
奇怪了,releaseBuffer没有unlock操作啊?难道我失误了?
再去看看obtainBuffer?为何写得这么晦涩难懂?
扩展:android audiotrack / android audio track / audiotrack
原来在obtainBuffer中会某一次进去lock,再某一次进去可能就是unlock了。没看到obtainBuffer中到处有lock,unlock,wait等同步操作吗。一定是这个道理。难怪写这么复杂。还使用了少用的goto语句。
唉,有必要这样吗!
五 AudioTrack总结
通过这一次的分析,我自己觉得有以下几个点:
l AudioTrack的工作原理,尤其是数据的传递这一块,做了比较细致的分析,包括共享内存,跨进程的同步等,也能解释不少疑惑了。
l 看起来,最重要的工作是在AudioFlinger中做的。通过AudioTrack的介绍,我们给后续深入分析AudioFlinger提供了一个切入点
工作原理和流程嘛,再说一次好了,JAVA层就看最前面那个例子吧,实在没什么说的。
l AudioTrack被new出来,然后set了一堆信息,同时会通过Binder机制调用另外一端的AudioFlinger,得到IAudioTrack对象,通过它和AudioFlinger交互。
l 调用start函数后,会启动一个线程专门做回调处理,代码里边也会有那种数据拷贝的回调,但是JNI层的回调函数实际并没有往里边写数据,大家只要看write就可以了
l 用户一次次得write,那AudioTrack无非就是把数据memcpy到共享buffer中咯
l 可想而知,AudioFlinger那一定有一个线程在memcpy数据到音频设备中去。我们拭目以待。
扩展:android audiotrack / android audio track / audiotrack
三 : 《深入浅出数据分析》读书笔记
拖了很久了,一个不折不扣的拖延症患者。如果不是现实再一次把我打倒谷底,我要闭着眼睛走到哪里。 从产品到数据再到分析,我似乎爱上了这种从数据中刨根问底,追踪溯源,从假设到验证到证实自己的想法,逻辑和数据的碰撞,理性和感性的碰撞。这渐渐的让我在遇到生活中的事情的时候,也容易抽取其中的问题,更清楚的去思考。 读完这本书最大的感觉是深入浅出,任何一个实际的事情都可以抽象成一个数学模型,这样更有利于看清这个问题的本质,找到解决或者提升问题的思路。一个问题摆在这里,那么与这个问题有关的数据表,文字报道,熟悉的相关人员的描述或者回答,在这个问题的分析中,都是一个不可或缺的变量,由变量到散点图,你看出了他们的分布规律,有散点图再到函数的拟合,加上控制变量在不同图形中的对比,你发现了影响问题的本质,甚至预知了将要呈现的未来(这个和黑天鹅里面的观点正好相反,他们的理论是任何可以预知的东西都是没有价值的,这个世界更多的是由小概率事件组成,从以往的数据中寻找规律毫无意义,就像金融危机,就像黑天鹅,无法预知的事物确是颠覆性的影响)。当然,我们不能因为未知而什么也不去做。数据无处不在。 书的第一章告诉我们数据无处不在,从确定,到数据分解,到评估,最后指导我们做决策,这个是一个数据分析师要做的事情。现实或者(www.61k.com]老板抛给我们一个问题,开始要做的是分解思考询问在重组,最全面客观的完善我们要分析的这份数据。还有数据是因为对比才显得有意义。 接下来我们从主观上对这件事情有个一个整体的认知,加上工作和生活的经验,我们大概觉得产生这件事情的原因。这是假设,有了这个假设,我们拿到的这批数据便是可能会支持自己假设的数据,如何证明我们的想法呢。那么从这些客观的数据中抽取可能影响这个结论的变量吧。比如我觉得是因为高低影响了我在这次选美大赛中的成绩,那么看看个子高的人呢,她们的成绩和身高的两个变量呈现怎么样的关系。身高越高,成绩越高,那么我的猜想是对的。当然某个问题可能会牵扯到不止一个的混杂因素影响,一个个抽取控制变量相互比较吧。更快更好的数据分析,需要思想和工具,不同的变量影响一个问题,那么这些变量直接存在的相互制约的关系是找到目标函数最优解的关键,像是寻找最大值一样,橡胶数量一定的情况下,生产多少只鸭子多少只鱼能让我们拿到最多的利润呢,似乎想到了高中数学里面的可行区域和渐近线。当然在考虑一个实际问题的时候还有人们不同时间的需求量也是其中的一个约束条件。 在工作中,往往最后呈现给别人看的是你的分析结论以及支持这些结论的一些图形变化,直观有效的可以展示出问题的变化和分布,书中提到了一个r软件,摆弄了一下,发现需要一些特定的指令和编程语言,遂还不是会用的。 在对于一个实际问题中,数据分析的精髓大体是这样的,数据描述信息然后抽取变量明确目标函数,提出假设,然后假设验证,尤其是对于一个没有123实际数据的抽象概念或者事件,只有描述,如何拿到可靠地结论,最近对于搜索引擎索引量的问题组长想要阻止讨论,只有描述,我们想知道对于自己来书索引多少数据最合适,按照数据分析师的思路,在自己没有想法和方向的时候不要召集讨论,我们各自说各自的开多长时间会也拿不出结论,不是徒劳吗,想想在这个问题中,影响索引量的变量都有哪些,机器资源?搜索量?需求范围等等,这些约束条件有什么关系,提出个假设说是60亿呢,开始假设验证,证明不对那么剩下的那个就是对的了。用已经掌握的要素和关系使用逻辑推理,这其中貌似缺乏了些数据的东西,但是也是一种思维。在不要求一些精确数值的时候,可以这样子去检验。 书中提到了贝叶斯统计,这是一种更贴近于实际的概率模型,事实上,任何实际问题多数都已在某个条件下成立的,这也使得贝叶斯非常的实用,想到当初的概率论亦或是高中的线性规划,只见其标,不见其本,更谈不上联系实际,多少有些感慨,背公式也可以背到90多分,可是我们学习不是为考试的啊。刚实习的时候,导师跟我说任何的一个结论都要量化,只是后来见他总是可能也许大概的说,有些迷糊。优秀的数据分析师告诉我们,人的主观概念也是可以量化的,比如我认为这件事情成功的概率是80%,其他人认为90%,或者我的80%的概率是哪些因素引起的,他们的概率又都是多少,把这些主观的概率都拿出来记录一下,我们是可以分析出结论的。四 : 破乳剂原理深入分析
1、破乳过程。(www.61k.com)
破乳剂的破乳过程一般分为 3个阶段: ①破乳剂加入原油乳状液后, 让它分散在整个油相中, 并能进入被乳化的水珠上; ②破乳剂渗入到乳化水珠的保护层, 并使保护层脆弱变皱破坏, 保护层破坏后, 被乳化的水珠互相接近并接触; ③水珠聚结, 被乳化的水珠从连续相分离出来。
2、 破乳机理。
尽管存在许多稳定原油乳状液的因素, 但是从热力学观点看, 乳状液是不稳定体系, 即使最稳定的乳状液其最终的平衡都应是两相分离, 破乳是必然结果, 只是方式和时间的差别而已。根据 Stokes定律, 对于W /O型原油乳状液,增大油水密度差或减小分散介质的粘度均有利于水滴沉降, 而沉降速度与水滴半径的平方成正比。所以在原油脱水过程中要尽量控制各种因素, 创造条件使微小的水滴聚结变大, 加速水滴沉降的油水分离过程。例如, 增大水滴尺寸和油水密度差、减小原油密度等。其主要方法有: 加热乳状液 (热处理)、加入破乳剂 (化学处理 )、施加电场 (电处理) 等, 还有混合、振动、微波、超声、离心、过滤以及加入微生物等。原油破乳过程一般要同时采用上述两种或数种方法。
近些年来, 原油乳状液的破乳机理的研究多集中在液滴聚结过程的精细考察和破乳剂对界面流变性质的影响等方面, 但由于破乳剂对乳状液的作用非常复杂, 尽管在这个领域进行了大量的研究工作, 目前对破乳机理尚无统一论断。一般认为, 乳状液的坏需经历分油、絮凝、膜排水、聚结等过程。破乳剂加入后朝油水界面扩散, 由于破乳剂的界面活性高于原油中成膜物质的界面活性, 能在油水界面上吸附或部分置换界面上吸附的天然乳化剂, 并且与原油中的成膜物质形成具有比原来界面膜强度更低的混合膜, 导致界面膜破坏, 将膜内包复的水释放出来, 水滴互相聚结形成大水滴沉降到
底部, 油水两相发生分离, 达到破乳的目的。Kotsari dou等认为, 水溶性破乳剂是通过取代界面粗乳化剂, 破坏乳液界面膜, 或改变界面层的润湿性, 产生界面非活性配合物而引起破乳; 而油溶性破乳剂除取代天然粗胶体外, 其机理是基于通过加入破乳剂的中和作用, 造成界面膜破坏, 从而使乳液破坏。H artland等人采用对称平面平行膜模型描述了破乳剂的作用。在无破乳剂的体系内液滴界面膜吸附沥青质等天然乳化剂, 两个液滴的聚结膜发生薄化使天然乳化剂分子在界面上的浓度分布不均形成负的界面张力梯度, 这种状况使膜排水作用降低; 加入破乳剂后, 破乳剂扩散到界面上空缺的地
方, 由于相同界面浓度下, 破乳剂降低界面张力的能力高于天然乳化剂, 使膜中的界面张力降低, 阻止沥青质的转移, 形成正的界面张力梯度, 加速膜排水过程。
根据研究结果, 目前公认的破乳机理有以下几点: ①相转移 反向变形机理; ②碰撞击破界面膜机理; ③增溶机理; ④褶皱变形机理。
化学破乳的机理比较复杂, 总结起来有如下几点: ①化学破乳剂较乳化剂具有更高活性, 分散到油-水界面上, 可将乳化剂排掉, 自已构成一个新的易破裂的界面膜。这种膜在重力沉降和电场作用下, 更易破裂, 便于油、水分离成层; ②化学破乳剂具有反相作用, 可使W /O型乳状液反相成 O /W型。在反相过程中, 乳化膜破裂; ③化学破乳剂对
乳化膜有很强的溶解作用, 通过溶解使乳化膜破裂; ④化学破乳剂可以中和油 - 水界面膜上的电荷, 破坏受电荷保护的界面膜。
在 80年代中期, 我国油田上常用的破乳剂品牌有 AE型、AR型、SP型、TA型、DP A 型和 PE型等。从 80年代中期到现在, 我国油田工作者在破乳剂的研制、合成方面做了大量的工作, 针对油田的各自特点, 研制出了一系列破乳剂, 包括: ①聚氨酯原油破乳剂; ②磷酸酯型原油破乳剂; ③烷基酚醛树脂型原油低温破乳剂; ④反相破乳剂; ⑤超高分子量聚醚原油破乳剂。 www.61k.com ?12_923.html
五 : Arnold_Vray_Mentalray全局照明测试与深入分析
本文对于渲染师或者渲染爱好者来说是一道技术大餐,但你要有耐心,跟着笔者的思路从头到尾看完,除了看图之外更要看字,这道大餐才算是能真正吃上。
在进行渲染测试以及撰写本文的时候,我尽量站在严谨、客观的角度去看待Arnold、Vray和Mentalray这三款常用渲染器。


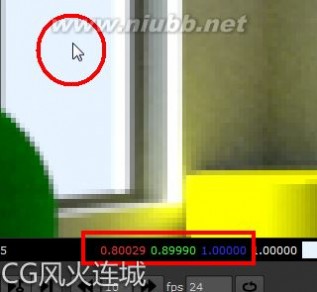





1、arnold的aiSky的颜色bug,在使用hdr与jpg贴图的时候,不存在,只有在直接赋予rgb颜色的时候,才有bug。
本文标题:深入浅出数据分析-深入分析新老访客数据 为站点创造更多价值61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1