一 : 肯尼亚山:肯尼亚山-基础数据,肯尼亚山-地理环境
肯尼亚山是东非大裂谷最大的死火山,位于肯中部赤道线上,北距内罗毕约230公里。最高峰海拔5,199米,是仅次于乞力马扎罗山的非洲第二高峰。
肯尼亚时间_肯尼亚山 -基础数据

亦译肯尼山;斯瓦希里语作Kirinyaga。肯尼亚山底高约1,600公尺(5,250呎)。2,440公尺(8,000呎)等高线上的周长约为153公里(95哩)。峰顶地区主要为陡峻、角锥状的尖峰,包括巴蒂安峰(Batian,高5199公尺〔17,058呎〕)、涅里翁峰(Nelion,高5,188公尺〔17,022呎〕)和莱纳纳峰(PointLenana,高4,985公尺〔16,355呎〕)。这座休眠已久的死火山大半已遭侵蚀,最高的几座山峰由堵住前火山口的结晶状霞石正长岩组成。从中央高峰呈放射状延伸的山脉为7条大山谷分隔。山坡上的溪流与沼泽源於几条正在後退的小冰川,其中最大的是路易斯(Lewis)和廷德尔(Tyndall)。所有溪流的特色是呈明显的放射状流向,但最终皆注入塔纳河(TanaRiver)或埃瓦索恩吉里河(EwasoNgiroRiver)。
(www.61k.com]肯尼亚时间_肯尼亚山 -地理环境

肯亚中部火山,位于赤道之南。是非洲第二高峰,仅次於南方320公里(200哩)的吉力马札罗山。肯亚山地区在1997年被联合国教科文组织(UNESCO)列入世界遗产名单内。
东非大裂谷最大的死火山,位于肯尼亚中部。最高峰海拔5,199米,是仅次于吉力马扎罗山的非洲第二高峰。她穿越赤道线,平时烟雾缭绕,峰顶若隐若现,而在晴朗的日子里几英里以外都可以看到屹立在远处的雪峰。巨大冰河形成的山谷紧靠群山,一片瑰丽的景色。山顶终年积雪,并有15条冰川伸延到4,300米处。海拔1,500─3,500米多密林。2,000米以下多种植园,在火山岩发育的肥沃土壤上种植咖啡、剑麻、香蕉等。连同周围地区辟为国家公园。以热带雪峰景色和众多野生动物吸引大量旅游者。山脚和山腰设有旅馆和宿营地。其南面的尼安达鲁瓦山脉的忙忙林海间有野生动物园。
肯尼亚时间_肯尼亚山 -地区特色

依高度不同,肯亚山有一连串独特的植被地区。草原覆盖著西部和北部的高地(有金合欢属〔Acacia〕和菅草属〔Themeda〕种类),南部和东部则以禾草和矮树为主。约从海拔1,800公尺(6,000呎)开始,茂密的环状森林覆盖山坡,向上延伸至海拔3,000公尺(10,000呎)附近。较干燥的西部和北部两侧以雪松和罗汉松最多。森林上缘──海拔约2,400公尺(8,000呎)以上──竹林遍布,但随著海拔愈高,竹林高度明显递减,最後没入继起的高大帚石楠区。在过渡地带(海拔3,400~3,700公尺〔11,000~12,000呎〕)之上即俗称的高沼地,是罕见的非洲高山植被带。再来就是苔藓和地衣,往上生长到海拔4,600公尺(15,000呎)左右。再往上就只有光秃秃的岩石、冰川和其他冰雪覆盖的地区了。肯亚山国家公园(1949年成立)占地718平方公里(277平方哩),涵盖肯亚山大部分海拔较低的边缘地区。公园及其四周有多种大型动物,包括象、水牛、黑犀牛和豹。一些濒危和稀有物种,如桑尼鹿(Sunnibuck)和白化斑马(albino zebra)也分布在那里。基库尤人(Kikuyu)以及和他们有亲缘关系的恩布人(Embu)、梅鲁人(Meru)在低海拔的肥沃山坡上开垦。
基库尤人称这座山为Kirinyaga或Kere-Nyaga(意为「白色山脉」),自古以来一直尊这座山为他们全能之神恩盖(Ngai)的家。克拉普特(Johann Ludwig Krapt)是第1个发现此山的欧洲人(1849),後来,匈牙利探险家泰莱基(Samuel Teleki)伯爵和英国地质学家格列哥里(John Walter Gregory)分别於1887和1893年攀登过肯亚山的一部分。英国地质学家麦金德(Halford John Mackinder)是第一位登上顶峰者(1899),同行的还有瑞士向导欧莱尔(Cesar Ollier)和布洛契尔(Joseph Brocherel)。纳纽基(Nanyuki)镇坐落於肯亚山的西北山麓,位於奈洛比(Nairobi)北方约190公里(120哩)处,有铁路与之相通;纳纽基和位於西部的纳罗莫鲁(Naro Moru)都是登山的主要基地。
肯尼亚时间_肯尼亚山 -自然森林
肯尼亚山国家公园位于内罗毕东北193公里处,横跨赤道,距肯尼亚海岸480公里。海拔1600米到5199米,占地面积为142020公顷,包括:肯尼亚山国家公园71500公顷,肯尼亚山自然森林70520公顷。1949年建立国家公园。1978年4月成为联合国教科文组织人与生物圈规划的1个生态保护区,从此得到国际公认。成立国家公园前已经是森林保护区。1997年列入世界遗产名录。
肯尼亚山由间歇性火山喷发形成。整个山脉被辐射状伸展开去的沟谷深深切开。沟谷大都是冰川侵蚀造成,山脚约96公里宽。有大约二十个冰斗湖,大小不一,带有各种冰渍特征。分布在海拔3750米到4800米之间。最高峰5199米。
肯尼亚山有2个湿润季节。3月-6月的湿润期较长。12月-2月为短暂的干燥季节。降雨量范围从北方到东南斜坡,由900毫米一直增大到2300毫米。海拔2800米到3800米处常年存在一条降雨云带。大约4500米以上的大部分降水为降雪。雨季峰顶经常白雪覆盖,在冰川上形成一米以上的积雪层。年平均气温变化范围2℃,3-4月最低,7-8月最高。白天气温温差很大,1-2月份约为20℃,7-8月为12℃。空气流动剧烈,整个夜晚直到清晨,风不停地从山上吹下来。从早上到下午空气反方向上升。早上峰顶狂风大作,太阳升起后风速逐渐减小。
植被种类随海拔和降雨量变化。高山和次高山花卉丰富。降雨量875-1400毫米之间,较干旱地区和海拔较低处,非洲圆柏和罗汉松生长占优势。西南和东北较湿润地区(年降雨超过2200毫米)内,柱子红树占优势。概括而言,大多数低海拔地区不在保护区内,用来种植麦子。东南斜坡海拔较高地区(2500-3000米,年降雨超过2000毫米)的优势树种是青篱竹。中海拔地区(2600米-2800米)为竹子和罗汉松混生区。海拔稍高(2600-2800米)或稍低(2500-2600米)处为罗汉松。向山的西面和北面伸展开去,竹子逐渐稀少并失去优势。海拔2000-3500米,年降水2400毫米的地区,哈根属乔木占优势。海拔3000米以上,主要因为气温低,树高降低。罗汉松让位于金丝桃属树木。由于下层树木更加发达,因而树冠更加张开。青草茂盛的林间空地在山脊上很常见。较低的高山地区或沼泽(3400-3800米)特点是降水多,腐殖质土层厚,地形变化小,植物种类稍欠丰富。从生禾本植物、羊茅及苔草类占优势。丘陵草丛之中生长着斗篷草,老鹳草。较高高山区(3800-4500米)地形变化较大,花卉种类更多,有巨大的莲叶植物,半边莲,千里光,飞廉属植物。土壤排水良好的地方,溪流旁边和河岸处,生长着各类禾本植物。尽管5000米以上的地区还可以发现维管植物,但从大约4500高度起,连绵的植被消失了。
肯尼亚时间_肯尼亚山 -人类活动
居民居住在肯尼亚山外围地区。当地旅馆和一家私人探险公司组织山地探险活动,当地有肯尼亚山地俱乐部。肯尼亚山国家公园每年接待15-20次学校团体参观。前期研究包括肯尼亚山高山动物种类和植物学研究。目前正在进行气象学和孢粉学研究。大多数研究都在3800米以上完成,需要进行大量相对性研究。肯尼亚山为非洲第二高峰,为700万人赖以生存的重要水源地,森林地区哺育着好几种濒危动物。白雪覆盖的山峰是东非景色最优美的地方之一。其非洲高山生态系统拥有许多特有物种。提供了肯尼亚的主要自然旅游景点,被当地部落公认为圣山。
人类对公园影响不大,但在海拔较低的森林地带影响较大。在干燥低矮林地,生活用火和雷电有一定威胁。火灾后树木只能缓慢自然恢复。森林受到的威胁与邻近地区相同,包括非法伐木、割柴、盗伐、烧炭、破坏性采蜜、定居和农业活动对森林的蚕食。
二 : Oracle数据库基础知识
一、 SQL基础知识(www.61k.com]
数据抽象:物理抽象、概念抽象、视图级抽象,内模式、模式、外模式
SQL语言包括数据定义、数据操纵(data manipulation),数据控制(data control)
数据定义:create table,alter table,drop table, craete/drop index等
数据操纵:select ,insert,update,delete,
数据控制:grant,revoke
创建、删除数据库
创建:create database database-name
删除:drop database dbname
创建、删除修改表
创建表:
综合评价:★★
create table tabname(col1 type1 [not null][primary key],col2 type2 [not null],..)
根据已有的表创建新表:
(1)建一个新表,架构、字段属性、约束条件、数据记录跟旧表完全一样:
create tabletab_new as select col1,col2…from tab_old;
(2)建一个新表,架构跟旧表完全一样,但没有内容:
create tabletab_new as select * from tab_old where 1=2;
删除表:
drop table tabname;--删除表结构
只删除表数据:
delete from tabname;(dml操作需要事务提交)
truncate table tabname;(ddl操作立即生效)
修改表:
修改表名:alter table skate_test rename to table_name
添加表注释:comment on table scott. table_name is '注释内容';
添加列注释:comment column on table_name.column_name is '注释内容';
添加、修改、删除列
添加:alter table tablename add (column datatype [defaultvalue][null/not null],….);
修改:alter table tablename modify(column datatype [default value][null/not null],….);
删除:alter table tablename drop(column);
注:列增加后将不能删除。db2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。
oracle cascade用法
cascade 关键字主要用于级联,级联删除、级联更新等,综合评价:★★
删除用户:drop user user_name; 删除用户,drop user user_name cascade; 删除此用户名下的所有表和视图
alter table table_name add constraint fk_tn_dept foreign key(dept) references dept(deptno) ([on delete set null],[on delete cascade]); |
添加、删除约束(主键、外键)
1、创建表的同时创建主键约束
(1)无命名
create table student (
studentid int primary key not null,
studentname varchar(8),
ageint);
(2)有命名
create table students (
studentid int ,
studentname varchar(8),
age int,
constraint yy primary key(pk_studentid));
2、向表中添加主键约束
alter table student add constraint pk_studentprimary key(pk_studentid);
3、删除表中已有的主键约束
(1)有命名
alter table students drop constraint yy;
(2)无命名
可用SELECT * FROM user_cons_columns WHEREtable_name = ’ student’
查找表中主键名称得student表中的主键名为SYS_C002715
alter table student drop constraintSYS_C002715;
主键与外键
主键是表格里的(一个或多个)字段,只用来定义表格里的行;主键里的值总是唯一的。
外键是一个用来建立两个表格之间关系的约束。这种关系一般都涉及一个表格里的主键字段与另外一个表格(尽管可能是同一个表格)里的一系列相连的字段。那么这些相连的字段就是外键。
创建、删除索引
创建:create [unique] index idx_name on tabname(col_name….)
删除:drop index idxname
注:索引是不可更改的,想更改必须删除重新建。
索引作用:
第一、通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二、可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三、可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四、在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五, 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
索引的作用?和它的优点缺点是什么?
索引就一种特殊的查询表,数据库的搜索引擎可以利用它加速对数据的检索。
优点:它很类似与现实生活中书的目录,不需要查询整本书内容就可以找到想要的数据。索引可以是唯一的,创建索引允许指定单个列或者是多个列。
缺点:是它减慢了数据录入的速度,同时也增加了数据库的尺寸大小。
创建、修改、删除视图
创建、修改:create or replace view view_name as select statement
删除:drop view view_name
二、 SQL查询
基本的SQL语句
选择:select * from table1 where 范围
插入:insert into table1(field1,field2) values(value1,value2)
删除:delete from table1 where 范围
更新:update table1 set field1=value1 where 范围
查找:select * from table1 where field1 like ’%value1%’ ---like语法★★★
排序:select * from table1 order by field1,field2 [desc]
总数:select count(*) as totalcount from table1
求和:select sum(field1) as sumvalue from table1
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
平均:select avg(field1) as avgvalue from table1
最大:select max(field1) as maxvalue from table1
最小:select min(field1) as minvalue from table1
union、minus、intersect
a:union 运算符
union 运算符通过组合其他两个结果表(例如table1 和 table2)并消去表中任何重复行而派生出一个结果表。当 all 随 union 一起使用时(即 union all),不消除重复行。两种情况下,派生表的每一行不是来自 table1 就是来自 table2。
b:minus 运算符
minus 运算符通过包括所有在 table1 中但不在 table2 中的行并消除所有重复行而派生出一个结果表。
c:intersect 运算符
intersect 运算符通过只包括 table1 和 table2 中都有的行并消除所有重复行而派生出一个结果表。
内连接、外连接
内连接,只连接匹配的行
selecta.c1,b.c2 from a join b on a.c3 = b.c3;
左外连接
包含左边表的全部行以及右边表中全部匹配的行
selecta.c1,b.c2 from a left join b on a.c3 = b.c3;
右外连接
包含右边表的全部行以及左边表中全部匹配的行
selecta.c1,b.c2 from a right join b on a.c3 = b.c3;
全外连接
综合评价:★★
包含左、右两个表的全部行
selecta.c1,b.c2 from a full join b on a.c3 = b.c3;
非等连接
使用等值以外的条件来匹配左、右两个表中的行
selecta.c1,b.c2 from a join b on a.c3 != b.c3;
自连接
使用同一张表中的不同字段进行匹配
select *from t1 a,t1 b where a.a1 = b.a3
交叉连接
综合评价:★★
生成笛卡尔积——它不使用任何匹配或者选取条件,而是直接将一个数据源中的每个行与另一个数据源的每个行一一匹
配
select a.c1,b.c2 from a,b;
多表关联
select * from a left inner join b ona.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where .....
内联接,外联接区别:内连接是保证两个表中所有的行都要满足连接条件,而外连接则不然。
在外连接中,某些不满条件的列也会显示出来,也就是说,只限制其中一个表的行,而不限制另一个表的行。分左连接、右连接、全连接三种
oracle8i,9i 表连接方法。
一般的相等连接: select * from a, b where a.id = b.id; 这个就属于内连接。
对于外连接:
oracle中可以使用“(+) ”来表示,9i可以使用left/right/fullouter join
leftouter join:左外关联
selecte.last_name, e.department_id, d.department_name
fromemployees e
leftouter join departments d
on(e.department_id = d.department_id);
等价于
selecte.last_name, e.department_id, d.department_name
fromemployees e, departments d
wheree.department_id=d.department_id(+)
结果为:所有员工及对应部门的记录,包括没有对应部门编号department_id的员工记录。
rightouter join:右外关联
selecte.last_name, e.department_id, d.department_name
fromemployees e
rightouter join departments d
on(e.department_id = d.department_id);
等价于
selecte.last_name, e.department_id, d.department_name
fromemployees e, departments d
wheree.department_id(+)=d.department_id
结果为:所有员工及对应部门的记录,包括没有任何员工的部门记录。
fullouter join:全外关联
selecte.last_name, e.department_id, d.department_name
fromemployees e
fullouter join departments d
on(e.department_id = d.department_id);
结果为:所有员工及对应部门的记录,包括没有对应部门编号department_id的员工记录和没有任何员工的部门记录。
oracle8i是不能在左右两个表上同时加上(+),转换成一个左联接一个右连接
全外连接语法
综合评价: ★★
selectt1.id,t2.id from table1 t1,table t2 where t1.id=t2.id(+)
union
selectt1.id,t2.id from table1 t1,table t2 where t1.id(+)=t2.id
子查询、关联子查询
综合评价:★★★
关联子查询是一种包含子查询的特殊类型的查询。查询里包含的子查询会真正请求外部查询的值,从而形成一个类似于循环的状况。
子查询:
注:表名1:a 表名2:b
select a,b,c from a where a in (select dfrom b) 或者: select a,b,c froma where a in (1,2,3)
关联子查询:
显示文章、提交人和最后回复时间
select a.title,a.username,b.adddate fromtable a, (selectmax(adddate) adddate from table where table.title=a.title) b where b.adddate = a.adddate;——需要显示B表中的字段
scott模式中,找出每个部门中最高工资的人
select a.deptno, a.* from emp a
where a.sal = (select max(b.sal)from emp b where b.deptno = a.deptno) ;——不需要显示B表中的字段
between、in、exists
综合评价:★★
between 使用方法
between的用法,between限制查询数据范围时包括了边界值,not between不包括
select * from table1 where time between time1 and time2
select a,b,c, from table1 where a not between 数值1 and 数值2
in 的使用方法
select * from table1 where a [not] in (‘值1’,’值2’,’值4’,’值6’)
exists 的使用方法
注:存在两张表,table1 table2
select * from table1 t1 where [not] exists(select * from table2 t2 where t1.id = t2.id)
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
in、exists使用区别:如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in
复制表(insert into … select、select … into … from)
综合评价:★★
insert into select语句
语句形式为:insert into table2(field1,field2,...) select value1,value2,... from table1
注意:
(1)要求目标表table2必须存在,并且字段field,field2...也必须存在
(2)注意table2的主键约束,如果table2有主键而且不为空,则 field1, field2...中必须包括主键
select into from语句
语句形式为:select vale1, value2 into table2 from table1;
对比:create table tab_new as select col1,col2…from tab_old;
要求目标表table2不存在,因为在插入时会自动创建表table2,并将table1中指定字段数据复制到table2中
三、 SQL查询优化
SQL 优化的实质:在保证结果正确的前提下,充份利用索引,减少表扫描的 I/O 次数,尽量少访问数据块,尽量避免全表扫描和其他额外开销。
oracle 常用的两种优化器:RBO(rule-based-optimizer)和CBO(cost-based-optimizer)。 目前更多地采用CBO(cost-based-optimizer)基于开销的优化器。在 CBO 方式下,Oracle 会根据表及索引的状态信息来选择计划;在 RBO 方 式下 ,Oracle 会根据自己内部设置的一些 规则来决定选择计划。
1、尽量少用 IN 操作符
基本上所有的 IN 操作符都可以用EXISTS 代替。IN 和EXISTS 操作的选择要根据主子表数据量大小来具体考虑。
2、尽量用 NOT EXISTS 或者外连接替代 NOT IN 操作符
因为 NOT IN 不能应用表的索引
3、尽量不用“<>”或者“!=”操作符
综合评价:★★
不等于操作符是通过全表扫描处理,大于或者小于会使用标的索引。如:a<>0改为 a>0 or a<0
4、在设计表时,把索引列设置为 NOT NULL
判断字段否为空是不会应用索引,因为 B 树索引不会索引空值的。
5、尽量不用通配符“%”或者“_”作为查询字符串的第一个字符
当通配符“%”或者“_”作为查询字符串的第一个字符时,索引不会被使用 。比如用 T 表中 Column1LIKE ‘%5400%’ 这个条件会产生全表扫描,如果改成 Column1 LIKE ’X5400%’ OR Column1 LIKE ’B5400%’ 则会利用 Column1 的索引进行两个范围的查询。
6、Where 子句中避免在索引列上使用计算
如果索引不是基于函数的,那么当在 Where 子句中对索引列使用函数时索引不再起作用。比如:substr(no,1,4)=’5400’,优化处理:no like ‘5400%’
trunc(hiredate)=trunc(sysdate) ,优化处理:hiredate >=trunc(sysdate) and hiredate<trunc(sysdate+1)
7、用“>=”替代“>”
综合评价:★★
大于或小于操作符一般情况下是不用调整的,因为它有索引就会采用索引查找,但有的情况下可以对它进行优化,如一个表有 100 万记录,一个数值型字段 A, 30 万记 录的 A=0,30 万记录的 A=1,39 万记录的 A=2,1 万记录的 A=3。那么执行 A>2 与 A>=3 的效果就有很大的区别了,因为 A>2时 ORACLE 会先找出为 2 的记录索引再进行比较,而 A>=3 时 ORACLE 则直接找到=3 的记录索引
8、利用 SGA 共享池,避开 parse 阶段
同一功能同一性能不同写法 SQL的影响。 如一个 SQL 在
A 程序员写的为:
Select * from zl_yhjbqk;
B 程序员写的为:
Select * from dlyx.zl_yhjbqk(带表所有者的前缀);
C 程序员写的为:
Select * from DLYX.ZLYHJBQK(大写表名);
D 程序员写的为:
Select * from DLYX.ZLYHJBQK(中间多了空格)。
以上四个 SQL 在 ORACLE 分析整理之后产生的结果及执行的时间是一样的,但是从ORACLE 共享内存 SGA 的原理,可以得出 ORACLE 对每个 SQL 都会对其进行一次分析,并且占用共享内存,如果将 SQL 的字符串及格式写得完全相同则 ORACLE 只会分析一次,共享内存也只会留下一次的分析结果,这不仅可以减少分析 SQL 的时间,而且可以减少共享内存重复的信息,ORACLE 也可以准确统计 SQL 的执行频率。
不同区域出现的相同的 SQL 语句要保证查询字符完全相同,建议经常使用变量来代替常量,以尽量使用重复 SQL 代码,以利用 SGA 共享池,避开 parse 阶段,防止相同的 SQL 语句被多次分析,提高执行速度。因此使用存储过程,是一种很有效的提高 share pool 共享率,跳过 parse 阶段,提高效率的办法。
9、WHERE 后面的条件顺序要求
综合评价:★★
WHERE 后面的条件,表连接语句写在最前,可以过滤掉最大数量记录的条件最后。ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。
10、使用表的别名,并将之作为每列的前缀
当在 SQL 语句中连接多个表时,使用表的别名,并将之作为每列的前缀。这样可以减少解析时间
11、进行了显式或隐式的运算的字段不能进行索引
综合评价:★★
比如:
ss_df+20>50,优化处理:ss_df>30
‘X’||hbs_bh>’X5400021452’,优化处理:hbs_bh>’5400021542’
sk_rq+5=sysdate,优化处理:sk_rq=sysdate-5
hbs_bh=5401002554,优化处理:hbs_bh=’ 5401002554’,注:此条件对hbs_bh 进行隐式的 to_number 转换,因为 hbs_bh 字段是字符型。
12、用 UNION ALL 代替 UNION 扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
UNION 是最常用的集操作,使多个记录集联结成为单个集,对返回的数据行有唯一性要求, 所以 oracle 就需要进行 SORTUNIQUE 操作(与使用 distinct 时操作类似),如果结果集又比较大,则操作会比较慢;
UNION ALL 操作不排除重复记录行,所以会快很多,如果数据本身重复行存在可能性较小时,用 union all 会比用 union 效率高很多!
13、其他操作
综合评价:★★
尽量使用 packages: Packages 在第一次调用时能将整个包 load 进内存,对提高性能有帮助。s
尽量使用 cached sequences来生成 primary key :提高主键生成速度和使用性能。很好地利用空间:如用 VARCHAR2 数据类型代替 CHAR 等
使用 SQL 优化工具:SQLexpert;toad;explain-table;PL/SQL;OEM
14、通过改变 oracle 的 SGA 的大小
综合评价:★★★
SGA:数据库的系统全局区。
SGA 主要由三部分构成:共享池、数据缓冲区、日志缓冲区
1、 共享池又由两部分构成:共享 SQL 区和数据字典缓冲区。共享SQL 区专门存放用户 SQL 命令,oracle 使用最近最少使用等优先级算法来更新覆盖;数据字典缓冲区(library cache)存放数据库运行的动态信息。数据库运行一段时间后, DBA 需要查看这些内存区域的命中率以从数据库角度对数据库性能调优。通过执行下述语句查看:
select (sum(pins - reloads)) / sum(pins)"Lib Cache" from v$librarycache;
--查看共享 SQL 区的重用率,最好在 90%以上,否则需要增加共享池的大小。 select (sum(gets - getmisses - usage - fixED)) / sum(gets) "Row Cache" fromv$rowcache;
--查看数据字典缓冲区的命中率,最好在 90%以上,否则需要增加共享池的大小。
2、 数据缓冲区:存放 SQL 运行结果抓取到的 datablock;
SELECT name, value FROM v$sysstat WHERE name IN ('db block gets',
'consistent gets','physical reads');
--查看数据库数据缓冲区的使用情况。查询出来的结果可以计算出来数据缓冲区 的使用命中率=1 - (physical reads / (db block gets + consistent gets) )。命中率应该 在 90%以上,否则需要增加数据缓冲区的大小。
3、 日志缓冲区:存放数据库运行生成的日志。
select name,value from v$sysstat where name in ('redo entries','redo log space requests');
--查看日志缓冲区的使用情况。查询出的结果可以计算出日志缓冲区的申请失败
率:申请失败率=requests/entries,申请失败率应该接近于 0,否则说明日志缓冲区开设太小,需要增加 ORACLE 数据库的日志缓冲区。
SQL调整最关注的是什么
检查系统的i/o问题
sar-d能检查整个系统的iostat(iostatistics)
查看该SQL的response time(db block gets/consistentgets/physical reads/sorts (disk))
四、 ORACLE SQL性能优化
1. 选用适合的ORACLE优化器
ORACLE的优化器共有3种:a. RULE (基于规则) b. COST(基于成本) c. CHOOSE (选择性)
设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS. 你当然也在SQL句级或是会话(session)级对其进行覆盖.
为了使用基于成本的优化器(CBO, Cost-Based Optimizer) , 你必须经常运行analyze 命令,以增加数据库中的对象统计信息(object statistics)的准确性.
如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze命令有关. 如果table已经被analyze过, 优化器模式将自动成为CBO , 反之,数据库将采用RULE形式的优化器.
在缺省情况下,ORACLE采用CHOOSE优化器, 为了避免那些不必要的全表扫描(full table scan) , 你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器.
2. 访问Table的方式
ORACLE 采用两种访问表中记录的方式:
a. 全表扫描
全表扫描就是顺序地访问表中每条记录.ORACLE采用一次读入多个数据块(database block)的方式优化全表扫描.
b. 通过ROWID访问表
你可以采用基于ROWID的访问方式情况,提高访问表的效率, ,ROWID包含了表中记录的物理位置信息..ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系. 通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高.
3. 共享SQL语句
为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在内存中.这块位于系统全局区域SGA(system global area)的共享池(shared bufferpool)中的内存可以被所有的数据库用户共享. 因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同,ORACLE就能很快获得已经被解析的语句以及最好的执行路径. ORACLE的这个功能大大地提高了SQL的执行性能并节省了内存的使用.可惜的是ORACLE只对简单的表提供高速缓冲(cache buffering) ,这个功能并不适用于多表连接查询.数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越大,就可以保留更多的语句,当然被共享的可能性也就越大了.
当你向ORACLE 提交一个SQL语句,ORACLE会首先在这块内存中查找相同的语句.这里需要注明的是,ORACLE对两者采取的是一种严格匹配,要达成共享,SQL语句必须完全相同(包括空格,换行等).
共享的语句必须满足三个条件:
A. 字符级的比较:当前被执行的语句和共享池中的语句必须完全相同.
B. 两个语句所指的对象必须完全相同:
C. 两个SQL语句中必须使用相同的名字的绑定变量(bind variables)
4. 选择最有效率的表名顺序(只在基于规则的优化器中有效)
ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表 driving table)将被最先处理. 在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表.当ORACLE处理多个表时, 会运用排序及合并的方式连接它们.首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行派序,然后扫描第二个表(FROM子句中最后第二个表),最后将所有从第二个表中检索出的记录与第一个表中合适记录进行合并.
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
例如:
表 TAB1 16,384 条记录
表 TAB2 1 条记录
选择TAB2作为基础表 (最好的方法)
select count(*) from tab1,tab2 执行时间0.96秒
选择TAB2作为基础表 (不佳的方法)
select count(*) from tab2,tab1 执行时间26.09秒
如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表.
例如:
EMP表描述了LOCATION表和CATEGORY表的交集.
SELECT *
FROM LOCATION L ,
CATEGORY C,
EMP E
WHERE E.EMP_NO BETWEEN 1000 AND 2000
AND E.CAT_NO = C.CAT_NO
AND E.LOCN = L.LOCN
将比下列SQL更有效率
SELECT *
FROM EMP E ,
LOCATION L ,
CATEGORY C
WHERE E.CAT_NO = C.CAT_NO
AND E.LOCN = L.LOCN
AND E.EMP_NO BETWEEN 1000 AND 2000
5. WHERE子句中的连接顺序.
ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾.
例如:
(低效,执行时间156.3秒)
SELECT …
FROM EMP E
WHERE SAL > 50000
AND JOB = ‘MANAGER’
AND 25 < (SELECT COUNT(*) FROM EMP
WHERE MGR=E.EMPNO);
(高效,执行时间10.6秒)
SELECT …
FROM EMP E
WHERE 25 < (SELECT COUNT(*) FROM EMP
WHERE MGR=E.EMPNO)
AND SAL > 50000
AND JOB = ‘MANAGER’;
6. SELECT子句中避免使用 ‘ * ‘
当你想在SELECT子句中列出所有的COLUMN时,使用动态SQL列引用 ‘*’ 是一个方便的方法.不幸的是,这是一个非常低效的方法. 实际上,ORACLE在解析的过程中, 会将’*’ 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 这意味着将耗费更多的时间.
7. 减少访问数据库的次数
当执行每条SQL语句时, ORACLE在内部执行了许多工作: 解析SQL语句, 估算索引的利用率, 绑定变量 , 读数据块等等. 由此可见, 减少访问数据库的次数 , 就能实际上减少ORACLE的工作量.
例如,
以下有三种方法可以检索出雇员号等于0342或0291的职员.
方法1 (最低效)
SELECT EMP_NAME , SALARY , GRADE
FROM EMP
WHERE EMP_NO = 342;
SELECT EMP_NAME , SALARY , GRADE
FROM EMP
WHERE EMP_NO = 291;
方法2 (次低效)
DECLARE
CURSOR C1 (E_NO NUMBER) IS
SELECT EMP_NAME,SALARY,GRADE
FROM EMP
WHERE EMP_NO = E_NO;
BEGIN
OPEN C1(342);
FETCH C1 INTO …,..,.. ;
…..
OPEN C1(291);
FETCH C1 INTO …,..,.. ;
CLOSE C1;
END;
方法3 (高效)
SELECT A.EMP_NAME , A.SALARY ,A.GRADE,
B.EMP_NAME , B.SALARY , B.GRADE
FROM EMP A,EMP B
WHERE A.EMP_NO = 342
AND B.EMP_NO = 291;
注意:
在SQL*Plus , SQL*Forms和Pro*C中重新设置ARRAYSIZE参数, 可以增加每次数据库访问的检索数据量 ,建议值为200
ORACLE SQL性能优化系列 (三)
8. 使用DECODE函数来减少处理时间
使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表.
例如:
SELECT COUNT(*),SUM(SAL)
FROM EMP
WHERE DEPT_NO = 0020
AND ENAME LIKE ‘SMITH%’;
SELECT COUNT(*),SUM(SAL)
FROM EMP
WHERE DEPT_NO = 0030
AND ENAME LIKE ‘SMITH%’;
你可以用DECODE函数高效地得到相同结果
SELECT COUNT(DECODE(DEPT_NO,0020,’X’,NULL)) D0020_COUNT,
COUNT(DECODE(DEPT_NO,0030,’X’,NULL)) D0030_COUNT,
SUM(DECODE(DEPT_NO,0020,SAL,NULL))D0020_SAL,
SUM(DECODE(DEPT_NO,0030,SAL,NULL))D0030_SAL
FROM EMP WHERE ENAME LIKE ‘SMITH%’;
类似的,DECODE函数也可以运用于GROUP BY 和ORDER BY子句中.
9. 整合简单,无关联的数据库访问
如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系)
例如:
SELECT NAME
FROM EMP
WHERE EMP_NO = 1234;
SELECT NAME
FROM DPT
WHERE DPT_NO = 10 ;
SELECT NAME
FROM CAT
WHERE CAT_TYPE = ‘RD’;
上面的3个查询可以被合并成一个:
SELECT E.NAME , D.NAME , C.NAME
FROM CAT C , DPT D , EMP E,DUAL X
WHERE NVL(‘X’,X.DUMMY) = NVL(‘X’,E.ROWID(+))
AND NVL(‘X’,X.DUMMY) = NVL(‘X’,D.ROWID(+))
AND NVL(‘X’,X.DUMMY) = NVL(‘X’,C.ROWID(+))
AND E.EMP_NO(+) = 1234
AND D.DEPT_NO(+) = 10
AND C.CAT_TYPE(+) = ‘RD’;
(译者按: 虽然采取这种方法,效率得到提高,但是程序的可读性大大降低,所以读者还是要权衡之间的利弊)
10. 删除重复记录
最高效的删除重复记录方法 ( 因为使用了ROWID)
DELETE FROM EMP E
WHERE E.ROWID > (SELECT MIN(X.ROWID)
FROM EMP X
WHERE X.EMP_NO = E.EMP_NO);
12. 尽量多使用COMMIT
只要有可能,在程序中尽量多使用COMMIT, 这样程序的性能得到提高,需求也会因为COMMIT所释放的资源而减少:
COMMIT所释放的资源:
a. 回滚段上用于恢复数据的信息.
b. 被程序语句获得的锁
c. redo log buffer 中的空间
d. ORACLE为管理上述3种资源中的内部花费
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
(译者按: 在使用COMMIT时必须要注意到事务的完整性,现实中效率和事务完整性往往是鱼和熊掌不可得兼)
ORACLE SQL性能优化系列 (四)
13. 计算记录条数
和一般的观点相反, count(*) 比count(1)稍快 , 当然如果可以通过索引检索,对索引列的计数仍旧是最快的. 例如 COUNT(EMPNO)
(译者按: 在CSDN论坛中,曾经对此有过相当热烈的讨论, 作者的观点并不十分准确,通过实际的测试,上述三种方法并没有显著的性能差别)
14. 用Where子句替换HAVING子句
避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤. 这个处理需要排序,总计等操作.如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销.
例如:
低效:
SELECT REGION,AVG(LOG_SIZE)
FROM LOCATION
GROUP BY REGION
HAVING REGION REGION != ‘SYDNEY’
AND REGION != ‘PERTH’
高效
SELECT REGION,AVG(LOG_SIZE)
FROM LOCATION
WHERE REGION REGION != ‘SYDNEY’
AND REGION != ‘PERTH’
GROUP BY REGION
(译者按:HAVING 中的条件一般用于对一些集合函数的比较,如COUNT() 等等. 除此而外,一般的条件应该写在WHERE子句中)
15. 减少对表的查询
在含有子查询的SQL语句中,要特别注意减少对表的查询.
例如:
低效
SELECT TAB_NAME
FROM TABLES
WHERE TAB_NAME = ( SELECT TAB_NAME
FROM TAB_COLUMNS
WHERE VERSION = 604)
AND DB_VER=( SELECT DB_VER
FROM TAB_COLUMNS
WHERE VERSION = 604)
高效
SELECT TAB_NAME
FROM TABLES
WHERE (TAB_NAME,DB_VER)
= ( SELECT TAB_NAME,DB_VER)
FROM TAB_COLUMNS
WHERE VERSION = 604)
Update 多个Column 例子:
低效:
UPDATE EMP
SET EMP_CAT = (SELECT MAX(CATEGORY)FROM EMP_CATEGORIES),
SAL_RANGE = (SELECT MAX(SAL_RANGE) FROMEMP_CATEGORIES)
WHERE EMP_DEPT = 0020;
高效:
UPDATE EMP
SET (EMP_CAT, SAL_RANGE)
= (SELECT MAX(CATEGORY) ,MAX(SAL_RANGE)
FROM EMP_CATEGORIES)
WHERE EMP_DEPT = 0020;
16. 通过内部函数提高SQL效率.
SELECTH.EMPNO,E.ENAME,H.HIST_TYPE,T.TYPE_DESC,COUNT(*)
FROM HISTORY_TYPE T,EMP E,EMP_HISTORY H
WHERE H.EMPNO = E.EMPNO
AND H.HIST_TYPE = T.HIST_TYPE
GROUP BYH.EMPNO,E.ENAME,H.HIST_TYPE,T.TYPE_DESC;
通过调用下面的函数可以提高效率.
FUNCTION LOOKUP_HIST_TYPE(TYP INNUMBER) RETURN VARCHAR2
AS
TDESC VARCHAR2(30);
CURSOR C1 IS
SELECT TYPE_DESC
FROM HISTORY_TYPE
WHERE HIST_TYPE = TYP;
BEGIN
OPEN C1;
FETCH C1 INTO TDESC;
CLOSE C1;
RETURN (NVL(TDESC,’?’));
END;
FUNCTION LOOKUP_EMP(EMP IN NUMBER)RETURN VARCHAR2
AS
ENAME VARCHAR2(30);
CURSOR C1 IS
SELECT ENAME
FROM EMP
WHERE EMPNO=EMP;
BEGIN
OPEN C1;
FETCH C1 INTO ENAME;
CLOSE C1;
RETURN (NVL(ENAME,’?’));
END;
SELECT H.EMPNO,LOOKUP_EMP(H.EMPNO),
H.HIST_TYPE,LOOKUP_HIST_TYPE(H.HIST_TYPE),COUNT(*)
FROM EMP_HISTORY H
GROUP BY H.EMPNO , H.HIST_TYPE;
ORACLE SQL性能优化系列 (六)
20. 用表连接替换EXISTS
通常来说 , 采用表连接的方式比EXISTS更有效率
SELECT ENAME
FROM EMP E
WHERE EXISTS (SELECT ‘X’
FROM DEPT
WHERE DEPT_NO = E.DEPT_NO
AND DEPT_CAT = ‘A’);
(更高效)
SELECT ENAME
FROM DEPT D,EMP E
WHERE E.DEPT_NO = D.DEPT_NO
AND DEPT_CAT = ‘A’ ;
21. 用EXISTS替换DISTINCT
当提交一个包含一对多表信息(比如部门表和雇员表)的查询时,避免在SELECT子句中使用DISTINCT. 一般可以考虑用EXIST替换
例如:
低效:
SELECT DISTINCT DEPT_NO,DEPT_NAME
FROM DEPT D,EMP E
WHERE D.DEPT_NO = E.DEPT_NO
高效:
SELECT DEPT_NO,DEPT_NAME
FROM DEPT D
WHERE EXISTS ( SELECT ‘X’
FROM EMP E
WHERE E.DEPT_NO = D.DEPT_NO);
EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果.
22. 识别’低效执行’的SQL语句
用下列SQL工具找出低效SQL:
SELECT EXECUTIONS , DISK_READS,BUFFER_GETS,
ROUND((BUFFER_GETS-DISK_READS)/BUFFER_GETS,2)Hit_radio,
ROUND(DISK_READS/EXECUTIONS,2)Reads_per_run,
SQL_TEXT
FROM V$SQLAREA
WHERE EXECUTIONS>0
AND BUFFER_GETS > 0
AND(BUFFER_GETS-DISK_READS)/BUFFER_GETS < 0.8
ORDER BY 4 DESC;
(译者按: 虽然目前各种关于SQL优化的图形化工具层出不穷,但是写出自己的SQL工具来解决问题始终是一个最好的方法)
23. 使用TKPROF 工具来查询SQL性能状态
SQL trace 工具收集正在执行的SQL的性能状态数据并记录到一个跟踪文件中. 这个跟踪文件提供了许多有用的信息,例如解析次数.执行次数,CPU使用时间等.这些数据将可以用来优化你的系统.
设置SQL TRACE在会话级别: 有效
ALTER SESSION SET SQL_TRACE TRUE
设置SQL TRACE 在整个数据库有效仿, 你必须将SQL_TRACE参数在init.ora中设为TRUE, USER_DUMP_DEST参数说明了生成跟踪文件的目录
ORACLE SQL性能优化系列 (七 )
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
24. 用EXPLAIN PLAN 分析SQL语句
EXPLAIN PLAN 是一个很好的分析SQL语句的工具,它甚至可以在不执行SQL的情况下分析语句. 通过分析,我们就可以知道ORACLE是怎么样连接表,使用什么方式扫描表(索引扫描或全表扫描)以及使用到的索引名称.
你需要按照从里到外,从上到下的次序解读分析的结果. EXPLAIN PLAN分析的结果是用缩进的格式排列的, 最内部的操作将被最先解读, 如果两个操作处于同一层中,带有最小操作号的将被首先执行.
NESTED LOOP是少数不按照上述规则处理的操作, 正确的执行路径是检查对NESTED LOOP提供数据的操作,其中操作号最小的将被最先处理.
译者按:
通过实践, 感到还是用SQLPLUS中的SET TRACE 功能比较方便.
举例:
SQL> list
1 SELECT *
2 FROM dept, emp
3* WHERE emp.deptno = dept.deptno
SQL> set autotrace on exp;/*traceonly 可以不显示执行结果*/
或者SQL> set autotrace traceonly exp;
SQL> /
14 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 NESTED LOOPS
2 1 TABLE ACCESS (FULL) OF 'EMP'
3 1 TABLE ACCESS (BY INDEX ROWID) OF'DEPT'
4 3 INDEX (UNIQUE SCAN) OF 'PK_DEPT'(UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
2 db block gets
30 consistent gets
0 physical reads
0 redo size
2598 bytes sent via SQL*Net to client
503 bytes received via SQL*Net fromclient
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
14 rows processed
通过以上分析,可以得出实际的执行步骤是:
1. TABLE ACCESS (FULL) OF 'EMP'
2. INDEX (UNIQUE SCAN) OF 'PK_DEPT'(UNIQUE)
3. TABLE ACCESS (BY INDEX ROWID) OF'DEPT'
4. NESTED LOOPS (JOINING 1 AND 3)
ORACLE SQL性能优化系列 (八)
25. 用索引提高效率
索引是表的一个概念部分,用来提高检索数据的效率. 实际上,ORACLE使用了一个复杂的自平衡B-tree结构. 通常,通过索引查询数据比全表扫描要快. 当ORACLE找出执行查询和Update语句的最佳路径时, ORACLE优化器将使用索引. 同样在联结多个表时使用索引也可以提高效率. 另一个使用索引的好处是,它提供了主键(primary key)的唯一性验证.
除了那些LONG或LONG RAW数据类型, 你可以索引几乎所有的列. 通常, 在大型表中使用索引特别有效. 当然,你也会发现, 在扫描小表时,使用索引同样能提高效率.
虽然使用索引能得到查询效率的提高,但是我们也必须注意到它的代价. 索引需要空间来
存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时, 索引本身也会被修改. 这意味着每条记录的INSERT , DELETE , UPDATE将为此多付出4 , 5 次的磁盘I/O . 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢.
译者按:
定期的重构索引是有必要的.
ALTER INDEX <INDEXNAME> REBUILD<TABLESPACENAME>
26. 索引的操作
ORACLE对索引有两种访问模式.
索引唯一扫描 ( INDEX UNIQUE SCAN)
大多数情况下, 优化器通过WHERE子句访问INDEX.
例如:
表LODGING有两个索引 : 建立在LODGING列上的唯一性索引LODGING_PK和建立在MANAGER列上的非唯一性索引LODGING$MANAGER.
SELECT *
FROM LODGING
WHERE LODGING = ‘ROSE HILL’;
在内部 , 上述SQL将被分成两步执行, 首先 , LODGING_PK 索引将通过索引唯一扫描的方式被访问 , 获得相对应的ROWID, 通过ROWID访问表的方式执行下一步检索.
如果被检索返回的列包括在INDEX列中,ORACLE将不执行第二步的处理(通过ROWID访问表). 因为检索数据保存在索引中, 单单访问索引就可以完全满足查询结果.
下面SQL只需要INDEXUNIQUE SCAN 操作.
SELECT LODGING
FROM LODGING
WHERE LODGING = ‘ROSE HILL’;
索引范围查询(INDEX RANGE SCAN)
适用于两种情况:
1. 基于一个范围的检索
2. 基于非唯一性索引的检索
例1:
SELECT LODGING
FROM LODGING
WHERE LODGING LIKE ‘M%’;
WHERE子句条件包括一系列值, ORACLE将通过索引范围查询的方式查询LODGING_PK . 由于索引范围查询将返回一组值, 它的效率就要比索引唯一扫描低一些.
例2:
SELECT LODGING
FROM LODGING
WHERE MANAGER = ‘BILL GATES’;
这个SQL的执行分两步,LODGING$MANAGER的索引范围查询(得到所有符合条件记录的ROWID) 和下一步同过ROWID访问表得到LODGING列的值. 由于LODGING$MANAGER是一个非唯一性的索引,数据库不能对它执行索引唯一扫描.
由于SQL返回LODGING列,而它并不存在于LODGING$MANAGER索引中, 所以在索引范围查询后会执行一个通过ROWID访问表的操作.
WHERE子句中, 如果索引列所对应的值的第一个字符由通配符(WILDCARD)开始, 索引将不被采用.
SELECT LODGING
FROM LODGING
WHERE MANAGER LIKE ‘%HANMAN’;
在这种情况下,ORACLE将使用全表扫描.
ORACLE SQL性能优化系列 (九)
27. 基础表的选择
基础表(Driving Table)是指被最先访问的表(通常以全表扫描的方式被访问). 根据优化器的不同, SQL语句中基础表的选择是不一样的.
如果你使用的是CBO (COST BASED OPTIMIZER),优化器会检查SQL语句中的每个表的物理大小,索引的状态,然后选用花费最低的执行路径.
如果你用RBO (RULE BASED OPTIMIZER) , 并且所有的连接条件都有索引对应, 在这种情况下, 基础表就是FROM 子句中列在最后的那个表.
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
举例:
SELECT A.NAME , B.MANAGER
FROM WORKERA,
LODGING B
WHERE A.LODGING = B.LODING;
由于LODGING表的LODING列上有一个索引, 而且WORKER表中没有相比较的索引, WORKER表将被作为查询中的基础表.
28. 多个平等的索引
当SQL语句的执行路径可以使用分布在多个表上的多个索引时, ORACLE会同时使用多个索引并在运行时对它们的记录进行合并, 检索出仅对全部索引有效的记录.
在ORACLE选择执行路径时,唯一性索引的等级高于非唯一性索引. 然而这个规则只有
当WHERE子句中索引列和常量比较才有效.如果索引列和其他表的索引类相比较. 这种子句在优化器中的等级是非常低的.
如果不同表中两个想同等级的索引将被引用, FROM子句中表的顺序将决定哪个会被率先使用. FROM子句中最后的表的索引将有最高的优先级.
如果相同表中两个想同等级的索引将被引用, WHERE子句中最先被引用的索引将有最高的优先级.
举例:
DEPTNO上有一个非唯一性索引,EMP_CAT也有一个非唯一性索引.
SELECT ENAME,
FROM EMP
WHERE DEPT_NO = 20
AND EMP_CAT = ‘A’;
这里,DEPTNO索引将被最先检索,然后同EMP_CAT索引检索出的记录进行合并. 执行路径如下:
TABLE ACCESS BY ROWID ON EMP
AND-EQUAL
INDEX RANGE SCAN ON DEPT_IDX
INDEX RANGE SCAN ON CAT_IDX
29. 等式比较和范围比较
当WHERE子句中有索引列,ORACLE不能合并它们,ORACLE将用范围比较.
举例:
DEPTNO上有一个非唯一性索引,EMP_CAT也有一个非唯一性索引.
SELECT ENAME
FROM EMP
WHERE DEPTNO > 20
AND EMP_CAT = ‘A’;
这里只有EMP_CAT索引被用到,然后所有的记录将逐条与DEPTNO条件进行比较. 执行路径如下:
TABLE ACCESS BY ROWID ON EMP
INDEX RANGE SCAN ON CAT_IDX
30. 不明确的索引等级
当ORACLE无法判断索引的等级高低差别,优化器将只使用一个索引,它就是在WHERE子句中被列在最前面的.
举例:
DEPTNO上有一个非唯一性索引,EMP_CAT也有一个非唯一性索引.
SELECT ENAME
FROM EMP
WHERE DEPTNO > 20
AND EMP_CAT > ‘A’;
这里, ORACLE只用到了DEPT_NO索引. 执行路径如下:
TABLE ACCESS BY ROWID ON EMP
INDEX RANGE SCAN ON DEPT_IDX
译者按:
我们来试一下以下这种情况:
SQL> select index_name, uniquenessfrom user_indexes where table_name = 'EMP';
INDEX_NAME UNIQUENES
---------------------------------------
EMPNO UNIQUE
EMPTYPE NONUNIQUE
SQL> select * from emp where empno>= 2 and emp_type = 'A' ;
no rows selected
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF'EMP'
2 1 INDEX (RANGE SCAN) OF 'EMPTYPE'(NON-UNIQUE)
虽然EMPNO是唯一性索引,但是由于它所做的是范围比较, 等级要比非唯一性索引的等式比较低!
ORACLE SQL性能优化系列 (十)
31. 强制索引失效
如果两个或以上索引具有相同的等级,你可以强制命令ORACLE优化器使用其中的一个(通过它,检索出的记录数量少) .
举例:
SELECT ENAME
FROM EMP
WHERE EMPNO = 7935
AND DEPTNO + 0 = 10 /*DEPTNO上的索引将失效*/
AND EMP_TYPE || ‘’ = ‘A’ /*EMP_TYPE上的索引将失效*/
这是一种相当直接的提高查询效率的办法. 但是你必须谨慎考虑这种策略,一般来说,只有在你希望单独优化几个SQL时才能采用它.
这里有一个例子关于何时采用这种策略,
假设在EMP表的EMP_TYPE列上有一个非唯一性的索引而EMP_CLASS上没有索引.
SELECT ENAME
FROM EMP
WHERE EMP_TYPE = ‘A’
AND EMP_CLASS = ‘X’;
优化器会注意到EMP_TYPE上的索引并使用它. 这是目前唯一的选择. 如果,一段时间以后, 另一个非唯一性建立在EMP_CLASS上,优化器必须对两个索引进行选择,在通常情况下,优化器将使用两个索引并在他们的结果集合上执行排序及合并. 然而,如果其中一个索引(EMP_TYPE)接近于唯一性而另一个索引(EMP_CLASS)上有几千个重复的值. 排序及合并就会成为一种不必要的负担. 在这种情况下,你希望使优化器屏蔽掉EMP_CLASS索引.
用下面的方案就可以解决问题.
SELECT ENAME
FROM EMP
WHERE EMP_TYPE = ‘A’
AND EMP_CLASS||’’ = ‘X’;
32. 避免在索引列上使用计算.
WHERE子句中,如果索引列是函数的一部分.优化器将不使用索引而使用全表扫描.
举例:
低效:
SELECT …
FROM DEPT
WHERE SAL * 12 > 25000;
高效:
SELECT …
FROM DEPT
WHERE SAL > 25000/12;
译者按:
这是一个非常实用的规则,请务必牢记
33. 自动选择索引
如果表中有两个以上(包括两个)索引,其中有一个唯一性索引,而其他是非唯一性.
在这种情况下,ORACLE将使用唯一性索引而完全忽略非唯一性索引.
举例:
SELECT ENAME
FROM EMP
WHERE EMPNO = 2326
AND DEPTNO = 20 ;
这里,只有EMPNO上的索引是唯一性的,所以EMPNO索引将用来检索记录.
TABLE ACCESS BY ROWID ON EMP
INDEX UNIQUE SCAN ON EMP_NO_IDX
34. 避免在索引列上使用NOT
通常, 我们要避免在索引列上使用NOT, NOT会产生在和在索引列上使用函数相同的
影响. 当ORACLE”遇到”NOT,他就会停止使用索引转而执行全表扫描.
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
举例:
低效: (这里,不使用索引)
SELECT …
FROM DEPT
WHERE DEPT_CODE NOT = 0;
高效: (这里,使用了索引)
SELECT …
FROM DEPT
WHERE DEPT_CODE > 0;
需要注意的是,在某些时候,ORACLE优化器会自动将NOT转化成相对应的关系操作符.
NOT > to <=
NOT >= to <
NOT < to >=
NOT <= to >
译者按:
在这个例子中,作者犯了一些错误. 例子中的低效率SQL是不能被执行的.
我做了一些测试:
SQL> select * from emp where NOTempno > 1;
no rows selected
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF'EMP'
2 1 INDEX (RANGE SCAN) OF 'EMPNO'(UNIQUE)
SQL> select * from emp where empno<= 1;
no rows selected
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF'EMP'
2 1 INDEX (RANGE SCAN) OF 'EMPNO'(UNIQUE)
两者的效率完全一样,也许这符合作者关于” 在某些时候, ORACLE优化器会自动将NOT转化成相对应的关系操作符” 的观点.
35. 用>=替代>
如果DEPTNO上有一个索引,
高效:
SELECT *
FROM EMP
WHERE DEPTNO >=4
低效:
SELECT *
FROM EMP
WHERE DEPTNO >3
两者的区别在于, 前者DBMS将直接跳到第一个DEPT等于4的记录而后者将首先定位到DEPTNO=3的记录并且向前扫描到第一个DEPT大于3的记录.
ORACLE SQL性能优化系列 (十一)
36. 用UNION替换OR (适用于索引列)
通常情况下, 用UNION替换WHERE子句中的OR将会起到较好的效果. 对索引列使用OR将造成全表扫描. 注意, 以上规则只针对多个索引列有效. 如果有column没有被索引, 查询效率可能会因为你没有选择OR而降低.
在下面的例子中, LOC_ID 和REGION上都建有索引.
高效:
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10
UNION
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE REGION = “MELBOURNE”
低效:
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10 OR REGION = “MELBOURNE”
如果你坚持要用OR, 那就需要返回记录最少的索引列写在最前面.
注意:
WHERE KEY1 = 10 (返回最少记录)
OR KEY2 = 20 (返回最多记录)
ORACLE 内部将以上转换为
WHERE KEY1 = 10 AND
((NOT KEY1 = 10) AND KEY2 = 20)
译者按:
下面的测试数据仅供参考: (a = 1003 返回一条记录 , b = 1 返回1003条记录)
SQL> select * from unionvsor /*1sttest*/
2 where a = 1003 or b = 1;
1003 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 CONCATENATION
2 1 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
3 2 INDEX (RANGE SCAN) OF 'UB'(NON-UNIQUE)
4 1 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
5 4 INDEX (RANGE SCAN) OF 'UA'(NON-UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
144 consistent gets
0 physical reads
0 redo size
63749 bytes sent via SQL*Net to client
7751 bytes received via SQL*Net fromclient
68 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1003 rows processed
SQL> select * from unionvsor /*2ndtest*/
2 where b = 1 or a = 1003 ;
1003 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 CONCATENATION
2 1 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
3 2 INDEX (RANGE SCAN) OF 'UA'(NON-UNIQUE)
4 1 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
5 4 INDEX (RANGE SCAN) OF 'UB'(NON-UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
143 consistent gets
0 physical reads
0 redo size
63749 bytes sent via SQL*Net to client
7751 bytes received via SQL*Net fromclient
68 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1003 rows processed
SQL> select * from unionvsor /*3rdtest*/
2 where a = 1003
3 union
4 select * from unionvsor
5 where b = 1;
1003 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 SORT (UNIQUE)
2 1 UNION-ALL
3 2 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
4 3 INDEX (RANGE SCAN) OF 'UA'(NON-UNIQUE)
5 2 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
6 5 INDEX (RANGE SCAN) OF 'UB'(NON-UNIQUE)
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
10 consistent gets
0 physical reads
0 redo size
63735 bytes sent via SQL*Net to client
7751 bytes received via SQL*Net fromclient
68 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
1003 rows processed
用UNION的效果可以从consistentgets和 SQL*NET的数据交换量的减少看出
37. 用IN来替换OR
下面的查询可以被更有效率的语句替换:
低效:
SELECT….
FROM LOCATION
WHERE LOC_ID = 10
OR LOC_ID = 20
OR LOC_ID = 30
高效
SELECT…
FROM LOCATION
WHERE LOC_IN IN (10,20,30);
译者按:
这是一条简单易记的规则,但是实际的执行效果还须检验,在ORACLE8i下,两者的执行路径似乎是相同的.
38. 避免在索引列上使用IS NULL和IS NOT NULL
避免在索引中使用任何可以为空的列,ORACLE将无法使用该索引.对于单列索引,如果列包含空值,索引中将不存在此记录. 对于复合索引,如果每个列都为空,索引中同样不存在此记录. 如果至少有一个列不为空,则记录存在于索引中.
举例:
如果唯一性索引建立在表的A列和B列上, 并且表中存在一条记录的A,B值为(123,null) , ORACLE将不接受下一条具有相同A,B值(123,null)的记录(插入). 然而如果
所有的索引列都为空,ORACLE将认为整个键值为空而空不等于空. 因此你可以插入1000
条具有相同键值的记录,当然它们都是空!
因为空值不存在于索引列中,所以WHERE子句中对索引列进行空值比较将使ORACLE停用该索引.
举例:
低效: (索引失效)
SELECT …
FROM DEPARTMENT
WHERE DEPT_CODE IS NOT NULL;
高效: (索引有效)
SELECT …
FROM DEPARTMENT
WHERE DEPT_CODE >=0;
ORACLE SQL性能优化系列 (十二)
39. 总是使用索引的第一个列
如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引.
译者按:
这也是一条简单而重要的规则. 见以下实例.
SQL> create table multiindexusage (inda number , indb number , descr varchar2(10));
Table created.
SQL> create index multindex on multiindexusage(inda,indb);
Index created.
SQL> set autotrace traceonly
SQL> select * from multiindexusagewhere inda = 1;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF'MULTIINDEXUSAGE'
2 1 INDEX (RANGE SCAN) OF 'MULTINDEX'(NON-UNIQUE)
SQL> select * from multiindexusagewhere indb = 1;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (FULL) OF'MULTIINDEXUSAGE'
很明显, 当仅引用索引的第二个列时,优化器使用了全表扫描而忽略了索引
40. ORACLE内部操作
当执行查询时,ORACLE采用了内部的操作. 下表显示了几种重要的内部操作.
ORACLE Clause
内部操作
ORDER BY
SORT ORDER BY
UNION
UNION-ALL
MINUS
MINUS
INTERSECT
INTERSECT
DISTINCT,MINUS,INTERSECT,UNION
SORT UNIQUE
MIN,MAX,COUNT
SORT AGGREGATE
GROUP BY
SORT GROUP BY
ROWNUM
COUNT or COUNT STOPKEY
Queries involving Joins
SORT JOIN,MERGE JOIN,NESTED LOOPS
CONNECT BY
CONNECT BY
41. 用UNION-ALL 替换UNION ( 如果有可能的话)
当SQL语句需要UNION两个查询结果集合时,这两个结果集合会以UNION-ALL的方式被合并, 然后在输出最终结果前进行排序.
如果用UNION ALL替代UNION, 这样排序就不是必要了. 效率就会因此得到提高.
举例:
低效:
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = ’31-DEC-95’
UNION
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = ’31-DEC-95’
高效:
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = ’31-DEC-95’
UNION ALL
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = ’31-DEC-95’
译者按:
需要注意的是,UNION ALL 将重复输出两个结果集合中相同记录. 因此各位还是
要从业务需求分析使用UNION ALL的可行性.
UNION 将对结果集合排序,这个操作会使用到SORT_AREA_SIZE这块内存. 对于这
块内存的优化也是相当重要的. 下面的SQL可以用来查询排序的消耗量
Select substr(name,1,25) "SortArea Name",
substr(value,1,15) "Value"
from v$sysstat
where name like 'sort%'
42. 使用提示(Hints)
对于表的访问,可以使用两种Hints.
FULL 和 ROWID
FULL hint 告诉ORACLE使用全表扫描的方式访问指定表.
例如:
SELECT /*+ FULL(EMP) */ *
FROM EMP
WHERE EMPNO = 7893;
ROWID hint 告诉ORACLE使用TABLE ACCESS BY ROWID的操作访问表.
通常, 你需要采用TABLEACCESS BY ROWID的方式特别是当访问大表的时候, 使用这种方式, 你需要知道ROIWD的值或者使用索引.
如果一个大表没有被设定为缓存(CACHED)表而你希望它的数据在查询结束是仍然停留
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
在SGA中,你就可以使用CACHE hint 来告诉优化器把数据保留在SGA中. 通常CACHE hint 和 FULL hint 一起使用.
例如:
SELECT /*+ FULL(WORKER) CACHE(WORKER)*/*
FROM WORK;
索引hint 告诉ORACLE使用基于索引的扫描方式. 你不必说明具体的索引名称
例如:
SELECT /*+ INDEX(LODGING) */ LODGING
FROM LODGING
WHERE MANAGER = ‘BILL GATES’;
在不使用hint的情况下, 以上的查询应该也会使用索引,然而,如果该索引的重复值过多而你的优化器是CBO, 优化器就可能忽略索引. 在这种情况下, 你可以用INDEX hint强制ORACLE使用该索引.
ORACLE hints 还包括ALL_ROWS, FIRST_ROWS, RULE,USE_NL, USE_MERGE, USE_HASH 等等.
译者按:
使用hint , 表示我们对ORACLE优化器缺省的执行路径不满意,需要手工修改.
这是一个很有技巧性的工作. 我建议只针对特定的,少数的SQL进行hint的优化.
对ORACLE的优化器还是要有信心(特别是CBO)
ORACLE SQL性能优化系列 (十三)
43. 用WHERE替代ORDER BY
ORDER BY 子句只在两种严格的条件下使用索引.
ORDER BY中所有的列必须包含在相同的索引中并保持在索引中的排列顺序.
ORDER BY中所有的列必须定义为非空.
WHERE子句使用的索引和ORDER BY子句中所使用的索引不能并列.
例如:
表DEPT包含以下列:
DEPT_CODE PK NOT NULL
DEPT_DESC NOT NULL
DEPT_TYPE NULL
非唯一性的索引(DEPT_TYPE)
低效: (索引不被使用)
SELECT DEPT_CODE
FROM DEPT
ORDER BY DEPT_TYPE
EXPLAIN PLAN:
SORT ORDER BY
TABLE ACCESS FULL
高效: (使用索引)
SELECT DEPT_CODE
FROM DEPT
WHERE DEPT_TYPE > 0
EXPLAIN PLAN:
TABLE ACCESS BY ROWID ON EMP
INDEX RANGE SCAN ON DEPT_IDX
译者按:
ORDER BY 也能使用索引! 这的确是个容易被忽视的知识点. 我们来验证一下:
SQL> select * from emp order byempno;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF'EMP'
2 1 INDEX (FULL SCAN) OF 'EMPNO'(UNIQUE)
44. 避免改变索引列的类型.
当比较不同数据类型的数据时, ORACLE自动对列进行简单的类型转换.
假设 EMPNO是一个数值类型的索引列.
SELECT …
FROM EMP
WHERE EMPNO = ‘123’
实际上,经过ORACLE类型转换, 语句转化为:
SELECT …
FROM EMP
WHERE EMPNO = TO_NUMBER(‘123’)
幸运的是,类型转换没有发生在索引列上,索引的用途没有被改变.
现在,假设EMP_TYPE是一个字符类型的索引列.
SELECT …
FROM EMP
WHERE EMP_TYPE = 123
这个语句被ORACLE转换为:
SELECT …
FROM EMP
WHERE TO_NUMBER(EMP_TYPE)=123
因为内部发生的类型转换, 这个索引将不会被用到!
译者按:
为了避免ORACLE对你的SQL进行隐式的类型转换, 最好把类型转换用显式表现出来. 注意当字符和数值比较时, ORACLE会优先转换数值类型到字符类型.
45. 需要当心的WHERE子句
某些SELECT 语句中的WHERE子句不使用索引. 这里有一些例子.
在下面的例子里, ‘!=’ 将不使用索引. 记住, 索引只能告诉你什么存在于表中, 而不能告诉你什么不存在于表中.
不使用索引:
SELECT ACCOUNT_NAME
FROM TRANSACTION
WHERE AMOUNT !=0;
使用索引:
SELECT ACCOUNT_NAME
FROM TRANSACTION
WHERE AMOUNT >0;
下面的例子中, ‘||’是字符连接函数. 就象其他函数那样, 停用了索引.
不使用索引:
SELECT ACCOUNT_NAME,AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME||ACCOUNT_TYPE=’AMEXA’;
使用索引:
SELECT ACCOUNT_NAME,AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME = ‘AMEX’
AND ACCOUNT_TYPE=’ A’;
下面的例子中, ‘+’是数学函数. 就象其他数学函数那样, 停用了索引.
不使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE AMOUNT + 3000 >5000;
使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE AMOUNT > 2000 ;
下面的例子中,相同的索引列不能互相比较,这将会启用全表扫描.
不使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME =NVL(:ACC_NAME,ACCOUNT_NAME);
使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME LIKE NVL(:ACC_NAME,’%’);
译者按:
如果一定要对使用函数的列启用索引, ORACLE新的功能: 基于函数的索引(Function-Based Index) 也许是一个较好的方案.
CREATE INDEX EMP_I ON EMP(UPPER(ename)); /*建立基于函数的索引*/
SELECT * FROM emp WHERE UPPER(ename) = ‘BLACKSNAIL’; /*将使用索引*/
ORACLE SQL性能优化系列 (十四) 完结篇
46. 连接多个扫描
如果你对一个列和一组有限的值进行比较, 优化器可能执行多次扫描并对结果进行合并连接.
举例:
SELECT *
FROM LODGING
WHERE MANAGER IN (‘BILL GATES’,’KENMULLER’);
优化器可能将它转换成以下形式
SELECT *
FROM LODGING
WHERE MANAGER = ‘BILL GATES’
OR MANAGER = ’KEN MULLER’;
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
当选择执行路径时, 优化器可能对每个条件采用LODGING$MANAGER上的索引范围扫描. 返回的ROWID用来访问LODGING表的记录 (通过TABLE ACCESS BY ROWID 的方式). 最后两组记录以连接(CONCATENATION)的形式被组合成一个单一的集合.
Explain Plan :
SELECT STATEMENT Optimizer=CHOOSE
CONCATENATION
TABLE ACCESS (BY INDEX ROWID) OFLODGING
INDEX (RANGE SCAN ) OF LODGING$MANAGER(NON-UNIQUE)
TABLE ACCESS (BY INDEX ROWID) OFLODGING
INDEX (RANGE SCAN ) OF LODGING$MANAGER(NON-UNIQUE)
译者按:
本节和第37节似乎有矛盾之处.
47. CBO下使用更具选择性的索引
基于成本的优化器(CBO, Cost-Based Optimizer)对索引的选择性进行判断来决定索引的使用是否能提高效率.
如果索引有很高的选择性, 那就是说对于每个不重复的索引键值,只对应数量很少的记录.
比如, 表中共有100条记录而其中有80个不重复的索引键值. 这个索引的选择性就是80/100 = 0.8 . 选择性越高,通过索引键值检索出的记录就越少.
如果索引的选择性很低, 检索数据就需要大量的索引范围查询操作和ROWID 访问表的
操作. 也许会比全表扫描的效率更低.
译者按:
下列经验请参阅:
a. 如果检索数据量超过30%的表中记录数.使用索引将没有显著的效率提高.
b. 在特定情况下, 使用索引也许会比全表扫描慢, 但这是同一个数量级上的
区别. 而通常情况下,使用索引比全表扫描要块几倍乃至几千倍!
48. 避免使用耗费资源的操作
带有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL语句会启动SQL引擎
执行耗费资源的排序(SORT)功能.DISTINCT需要一次排序操作, 而其他的至少需要执行两次排序.
例如,一个UNION查询,其中每个查询都带有GROUP BY子句,GROUP BY会触发嵌入排序(NESTED SORT) ; 这样, 每个查询需要执行一次排序, 然后在执行UNION时, 又一个唯一排序(SORTUNIQUE)操作被执行而且它只能在前面的嵌入排序结束后才能开始执行. 嵌入的排序的深度会大大影响查询的效率.
通常, 带有UNION,MINUS , INTERSECT的SQL语句都可以用其他方式重写.
译者按:
如果你的数据库的SORT_AREA_SIZE调配得好, 使用UNION , MINUS, INTERSECT也是可以考虑的, 毕竟它们的可读性很强
49. 优化GROUP BY
提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉.下面两个查询返回相同结果但第二个明显就快了许多.
低效:
SELECT JOB , AVG(SAL)
FROM EMP
GROUP JOB
HAVING JOB = ‘PRESIDENT’
OR JOB = ‘MANAGER’
高效:
SELECT JOB , AVG(SAL)
FROM EMP
WHERE JOB = ‘PRESIDENT’
OR JOB = ‘MANAGER’
GROUP JOB
译者按:
本节和14节相同. 可略过.
50. 使用日期
当使用日期是,需要注意如果有超过5位小数加到日期上, 这个日期会进到下一天!
例如:
1.
SELECT TO_DATE(‘01-JAN-93’+.99999)
FROM DUAL;
Returns:
’01-JAN-93 23:59:59’
2.
SELECT TO_DATE(‘01-JAN-93’+.999999)
FROM DUAL;
Returns:
’02-JAN-93 00:00:00’
译者按:
虽然本节和SQL性能优化没有关系, 但是作者的功力可见一斑
51. 使用显式的游标(CURSORs)
使用隐式的游标,将会执行两次操作. 第一次检索记录, 第二次检查TOO MANY ROWS 这个exception . 而显式游标不执行第二次操作.
52. 优化EXPORT和IMPORT
使用较大的BUFFER(比如10MB, 10,240,000)可以提高EXPORT和IMPORT的速度.
ORACLE将尽可能地获取你所指定的内存大小,即使在内存不满足,也不会报错.这个值至少要和表中最大的列相当,否则列值会被截断.
译者按:
可以肯定的是, 增加BUFFER会大大提高EXPORT , IMPORT的效率. (曾经碰到过一个CASE, 增加BUFFER后,IMPORT/EXPORT快了10倍!)
作者可能犯了一个错误: “这个值至少要和表中最大的列相当,否则列值会被截断. “
其中最大的列也许是指最大的记录大小.
关于EXPORT/IMPORT的优化,CSDN论坛中有一些总结性的贴子,比如关于BUFFER参数,COMMIT参数等等, 详情请查.
53. 分离表和索引
总是将你的表和索引建立在不同的表空间内(TABLESPACES). 决不要将不属于ORACLE内部系统的对象存放到SYSTEM表空间里. 同时,确保数据表空间和索引表空间置于不同的硬盘上.
译者按:
“同时,确保数据表空间和索引表空间置与不同的硬盘上.”可能改为如下更为准确 “同时,确保数据表空间和索引表空间置与不同的硬盘控制卡控制的硬盘上.”
五、 SQL编程
数据库表、列
列出数据库里所有的表名
select table_name from user_tables; --当前用户的表
select table_name from all_tables; --所有用户的表
select table_name from dba_tables; --包括系统表
列出表里的所有的列
desc table_name
表备份
综合评价:★★
下面的例子会制作 "persons" 表的备份复件:
select * into persons_backup from persons
in 子句可用于向另一个数据库中拷贝表:
select * into persons in 'backup.mdb' from persons
事务
事务:作为一个逻辑单元执行的一系列操作,一个逻辑工作单元必须有四个属性,称为 acid(原子性、一致性、隔离性和持久性)属性。
原子性:事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。
一致性:事务在完成时,必须使所有的数据都保持一致状态。在相关数据库中,所有规则都必须应用于事务的修改,以保持所有数据的完整性。事务结束时,所有的内部数据结构(如 b 树索引或双向链表)都必须是正确的。
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
隔离性:由并发事务所作的修改必须与任何其它并发事务所作的修改隔离。事务查看数据时所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据。这称为可串行性,因为它能够重新装载起始数据,并且重播一系列事务,以使数据结束时的状态与原始事务执行的状态相同。
持久性:事务完成之后,它对于系统的影响是永久性的。该修改即使出现系统故障也将一直保持。
锁:共享锁、互斥锁
共享锁:如果事务t对数据a加上共享锁后,则其他事务只能对a再加共享锁,不能加排他锁,直到已释放所有共享锁。获准共享锁的事务只能读数据,不能修改数据。
排他锁:如果事务t对数据a加上排他锁后,则其他事务不能再对a加任任何类型的锁,直到在事务的末尾将资源上的锁释放为止。获准排他锁的事务既能读数据,又能修改数据。
两段锁协议:阶段1:加锁阶段阶段2:解锁阶段
触发器
触发器: 当满足触发器条件,则系统自动执行触发器的触发体。
触发时间:有before,after.触发事件:有insert,update,delete三种。触发类型:有行触发、语句触发
触发器的作用:触发器是一中特殊的存储过程,主要是通过事件来触发而被执行的。它可以强化约束,来维护数据的完整性和一致性,可以跟踪数据库内的操作从而不允许未经许可的更新和变化。可以联级运算。如,某表上的触发器上包含对另一个表的数据操作,而该操作又会导致该表触发器被触发。
事前触发器运行于触发事件发生之前,而事后触发器运行于触发事件发生之后。通常事前触发器可以获取事件之前和新的字段值。
语句级触发器可以在语句执行前或后执行,而行级触发在触发器所影响的每一行触发一次。
视图、游标
综合评价:★★★
视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,视图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。
游标:一个游标(cursor)可以被看作指向结果集(a set of rows)中一行的指针(pointer)。游标每个时间点只能指向一行,但是可以根据需要指向结果集中其他的行。
例如:SELECT * FROM employees WHERE sex='M'会返回所有性别为男的雇员,在初始的时候,游标被放置在结果集中第一行的前面。使游标指向第一行,要执行FETCH。当游标指向结果集中一行的时候,可以对这行数据进行加工处理,要想得到下一行数据,要继续执行FETCH。FETCH操作可以重复执行,直到完成结果集中的所有行
在存储过程中使用游标:
声明游标、打开游标、根据需要一次一行,讲游标指向的数据取到本地变量(local variables)中、结束时关闭游标。
显式游标:当查询返回结果超过一行时,就需要一个显式游标,此时用户不能使用select into语句。PL/SQL管理隐式游标,当查询开始时隐式游标打开,查询结束时隐式游标自动关闭。显式游标在PL/SQL块的声明部分声明,在执行部分 或异常处理部分打开,取出数据,关闭。
使用游标:我们所说的游标通常是指 显式游标
CURSOR cursor_name IS select_statement;
在PL/SQL中游标名是一个未声明变量,不能给游标名赋值或用于表达式中。例:
DELCARE CURSOR C_EMP IS SELECT empno,ename,salary FROM emp WHERE salary>2000 ORDER BY ename; ........ BEGIN |
打开关闭游标:使用游标中的值之前应该首先打开游标初始化查询处理。
OPEN cursor_name; CLOSE cursor_name |
从游标提取数据:从游标得到一行数据使用FETCH命令。每一次提取数据后,游标都指向结果集的下一行。语法如下:FETCHcursor_name INTO variable [, variable...]
对于SELECT定义的游标的每一列,FETCH变量列表都应该有一个变量与之相对应,变量的类型也要相同。返回结果集不止一条就要使用循环。例:
SET SERVERIUTPUT ON v_ename EMP.ENAME%TYPE; v_salary EMP.SALARY%TYPE; CURSOR c_emp IS SELECT ename,salary FROM emp; BEGIN OPEN c_emp; LOOP FETCH c_emp INTO v_ename,v_salary; EXIT WHEN c_emp%NOTFOUND; DBMS_OUTPUT.PUT_LINE(/'Salary of Employee/'|| v_ename ||/'is/'|| v_salary);
END; |
记录变量:定义一个记录变量使用TYPE命令和%ROWTYPE。
记录变量用于从游标中提取数据行,当游标选择很多列的时候,那么使用记录比为每列声明一个变量要方便得多。
关 键 词:当在表上使用%ROWTYPE并将从游标中取出的值放入记录中时,如果要选择表中所有列,那么在SELECT子句中使用*比将所有列名列出来要得多。例:
SET SERVERIUTPUT ON DECLARE R_emp EMP%ROWTYPE; CURSOR c_emp IS SELECT * FROM emp; BEGIN OPEN c_emp; LOOP FETCH c_emp INTO r_emp; EXIT WHEN c_emp%NOTFOUND; DBMS_OUT.PUT.PUT_LINE(/'Salary of Employee/'||r_emp.ename||/'is/'|| r_emp.salary); 扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库 END LOOP; CLOSE c_emp; END; |
%ROWTYPE也可以用游标名来定义,这样的话就必须要首先声明游标:
SET SERVERIUTPUT ON DECLARE CURSOR c_emp IS SELECT ename,salary FROM emp; R_emp c_emp%ROWTYPE; BEGIN OPEN c_emp; LOOP FETCH c_emp INTO r_emp; EXIT WHEN c_emp%NOTFOUND; DBMS_OUT.PUT.PUT_LINE(/'Salary of Employee/' ||r_emp.ename||/'is/'|| r_emp.salary); END LOOP; CLOSE c_emp; END; |
带参数的游标:与存储过程和函数相似,可以将参数传递给游标并在查询中使用。语法如下:
CURSOR cursor_name[(parameter[,parameter],...)] IS select_statement; |
定义参数的:
Parameter_name [IN] data_type[{:=|DEFAULT} value] |
游标只能接受传递的值,不能返回值。参数只定义数据类型,没有大小。另外可以给参数设定一个缺省值,当没有参数值传递给游标时,就使用缺省值。
打开游标时给参数赋值:
OPEN cursor_name [value [, value]....]; |
参数值可以是文字或变量。例:
DECALRE CURSOR c_dept IS SELECT * FROM dept ORDER BY deptno; CURSOR c_emp (p_dept VARACHAR2) IS SELECT ename,salary FROM emp WHERE deptno=p_dept ORDER BY ename r_dept DEPT%ROWTYPE; v_ename EMP.ENAME%TYPE; v_salary EMP.SALARY%TYPE; v_tot_salary EMP.SALARY%TYPE; BEGIN OPEN c_dept; LOOP FETCH c_dept INTO r_dept; EXIT WHEN c_dept%NOTFOUND; DBMS_OUTPUT.PUT_LINE (/'Department:/'|| r_dept.deptno||/'-/'||r_dept.dname); v_tot_salary:=0; OPEN c_emp(r_dept.deptno); LOOP FETCH c_emp INTO v_ename,v_salary; EXIT WHEN c_emp%NOTFOUND; DBMS_OUTPUT.PUT_LINE (/'Name:/'|| v_ename||/' salary:/'||v_salary); v_tot_salary:=v_tot_salary+v_salary; END LOOP; CLOSE c_emp; DBMS_OUTPUT.PUT_LINE (/'Toltal Salary for dept:/'|| v_tot_salary); END LOOP; CLOSE c_dept; END; |
游标FOR循环
在大多数时候我们在设计程序的时候都遵循下面的步骤:
1、打开游标。
2、开始循环。
3、从游标中取值。
4、那一行被返回。
5、处理。
6、关闭循环。
7、关闭游标。
可以简单的把这一类代码称为游标用于循环。但还有一种循环与这种类型不相同,这就是FOR循环,用于FOR循环的游标按照正常的声明方式声明,它的优点在于不需要显式的打开、关闭、取数据,测试数据的存在、定义存放数据的变量等等。游标FOR循环的语法如下:
FOR record_name IN (corsor_name[(parameter[,parameter]...)] | (query_difinition) LOOP statements END LOOP; |
用for循环重写上面的例子:
DECALRE CURSOR c_dept IS SELECT deptno,dname FROM dept ORDER BY deptno; CURSOR c_emp (p_dept VARACHAR2) IS SELECT ename,salary FROM emp WHERE deptno=p_dept ORDER BY ename v_tot_salary EMP.SALARY%TYPE; BEGIN FOR r_dept IN c_dept LOOP DBMS_OUTPUT.PUT_LINE (/'Department:/'|| r_dept.deptno||/'-/'||r_dept.dname); v_tot_salary:=0; FOR r_emp IN c_emp(r_dept.deptno) LOOP DBMS_OUTPUT.PUT_LINE (/'Name:/' || v_ename || /'salary:/' || v_salary); v_tot_salary:=v_tot_salary+v_salary; END LOOP; DBMS_OUTPUT.PUT_LINE (/'Toltal Salary for dept:/'|| v_tot_salary); END LOOP; END; |
在游标FOR循环中使用查询
在游标FOR循环中可以定义查询,由于没有显式声明所以游标没有名字,记录名通过游标查询来定义。
DECALRE v_tot_salary EMP.SALARY%TYPE; BEGIN FOR r_dept IN (SELECT deptno,dname FROM dept ORDER BY deptno) LOOP DBMS_OUTPUT.PUT_LINE(/'Department:/'|| r_dept.deptno||/'-/'||r_dept.dname); v_tot_salary:=0; FOR r_emp IN (SELECT ename,salary FROM emp WHERE deptno=p_dept ORDER BY ename) LOOP DBMS_OUTPUT.PUT_LINE(/'Name:/'|| v_ename||/' salary:/'||v_salary); 扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库 v_tot_salary:=v_tot_salary+v_salary; END LOOP; DBMS_OUTPUT.PUT_LINE(/'Toltal Salary for dept:/'|| v_tot_salary); END LOOP; END; |
游标中的子查询
CURSOR C1 IS SELECT * FROM emp WHERE deptno NOT IN (SELECT deptno FROM dept WHERE dname!=/'ACCOUNTING/'); |
游标中的更新和删除(没学)
在PL/SQL中依然可以使用UPDATE和DELETE语句更新或删除数据行。显式游标只有在需要获得多行数据的情况下使用。PL/SQL提供了仅仅使用游标就可以执行删除或更新记录的方法。
UPDATE或DELETE语句中的WHERECURRENT OF子串专门处理要执行UPDATE或DELETE操作的表中取出的最近的数据。要使用这个方法,在声明游标时必须使用FOR UPDATE子串,当对话使用FOR UPDATE子串打开一个游标时,所有返回集中的数据行都将处于行级(ROW-LEVEL)独占式锁定,其他对象只能查询这些数据行,不能进行 UPDATE、DELETE或SELECT...FOR UPDATE操作。
语法:
FOR UPDATE [OF [schema.]table.column[,[schema.]table.column].. [nowait] |
在多表查询中,使用OF子句来锁定特定的表,如果忽略了OF子句,那么所有表中选择的数据行都将被锁定。如果这些数据行已经被其他会话锁定,那么正常情况下ORACLE将等待,直到数据行解锁。
在UPDATE和DELETE中使用WHERECURRENT OF子串的语法如下:
WHERE{CURRENT OF cursor_name|search_condition} DELCARE CURSOR c1 IS SELECT empno,salary FROM emp WHERE comm IS NULL FOR UPDATE OF comm; v_comm NUMBER(10,2); BEGIN FOR r1 IN c1 LOOP IF r1.salary<500 THEN v_comm:=r1.salary*0.25; ELSEIF r1.salary<1000 THEN v_comm:=r1.salary*0.20; ELSEIF r1.salary<3000 THEN v_comm:=r1.salary*0.15; ELSE v_comm:=r1.salary*0.12; END IF; UPDATE emp; SET comm=v_comm WHERE CURRENT OF c1l; END LOOP; END |
存储过程
综合评价:★★★★
存储过程基础知识
存储过程:一组为了完成特定功能的SQL语句集,经编译后存储在数据库中。
存储过程的创建需要CREATE PROCEDURE 系统权限,如果需要被其他用户Schema使用需要CREATE ANY PROCEDURE 权限。存储过程的执行需要 EXECUTE权限或者 EXECUTE ANY PROCEDURE 权限。
单独赋予权限:grant execute on MY_PROCEDURE to Jelly;
调用存储过程:executeMY_PROCEDURE( 'ONE PARAMETER');
存储过程(PROCEDURE)和函数(FUNCTION)的区别:
A: 函数有限制只能返回一个标量,而存储过程可以返回多个;
B: 函数可以嵌入到SQL语句中执行. 而存储过程不行。存储过程执行必须调用EXECUTE
包(PACKAGE)是function,procedure,variables 和SQL 语句的组合。package允许多个procedure使用同一个变量和游标。
存储过程的特点:
1.存储过程运行的速度比较快。
2. 可保证数据的安全性和完整性。
3.可以降低网络的通信量。
4:存储过程可以接受参数、输出参数、返回单个或多个结果集以及返回值。
5:存储过程可以包含程序流、逻辑以及对数据库的查询。
存储过程创建语法
CREATE [ OR REPLACE ] PROCEDURE [ schema.]procedure [(argument [IN | OUT | IN OUT ] [NO COPY] datatype [, argument [IN | OUT | IN OUT ] [NO COPY] datatype]... )] [ authid { current_user | definer }] { is | as } { pl/sql_subprogram_body | language { java name 'String' | c [ name, name] library lib_name }] |
Sql 代码:
CREATE PROCEDURE sam.credit (acc_no IN NUMBER, amount IN NUMBER) AS BEGIN UPDATE accounts SET balance = balance + amount WHERE account_id = acc_no; END; |
IN, OUT, IN OUT用来修饰参数。
IN 表示这个变量必须被调用者赋值然后传入到PROCEDURE进行处理。
OUT 表示PRCEDURE 通过这个变量将值传回给调用者。
IN OUT 则是这两种的组合。
authid代表两种权限:
定义者权限(difiner right 默认),执行者权限(invoker right)。
定义者权限说明这个procedure中涉及的表、视图等对象所需要的权限只要定义者拥有权限的话就可以访问。
执行者权限则需要调用这个 procedure的用户拥有相关表和对象的权限。
Oracle存储过程的语法
1. 基本结构
CREATE OR REPLACE PROCEDURE 存储过程名字 END 存储过程名字 |
2. SELECT INTO STATEMENT 扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
将select查询的结果存入到变量中,可以同时将多个列存储多个变量中,必须有一条记录,否则抛出异常(如果没有记录抛出NO_DATA_FOUND)
例子:
BEGIN WHEN OTHERS THEN xxxx; |
3. IF 判断
IF V_TEST=1 THEN |
4. while 循环
WHILE V_TEST=1 LOOP |
5. 变量赋值
V_TEST := 123; |
6. 用for in 使用cursor
... |
7. 带参数的cursor
CURSOR C_USER(C_ID NUMBER) IS SELECT NAME FROM USER WHERE TYPEID=C_ID; |
8. 用pl/sql developer debug
连接数据库后建立一个Test WINDOW
在窗口输入调用SP的代码,F9开始debug,CTRL+N单步调试
9. Pl/Sql中执行存储过程
在sql*plus中:
declare |
在SQL/PLUS中调用存储过程,显示结果:
SQL>set serveoutput on --打开输出 SQL>var info1 number;--输出1 SQL>var info2 number;--输出2 SQL>declare var1 varchar2(20);--输入1 var2 varchar2(20);--输入2 var3 varchar2(20);--输入2 BEGIN pro(var1,var2,var3,:info1,:info2); END; / SQL>print info1; SQL>print info2; |
注:在EXECUTE IMMEDIATESTR语句是SQLPLUS中动态执行语句,它在执行中会自动提交,类似于DP中FORMS_DDL语句,在此语句中STR是不能换行的,只能通过连接字符"||",或者在换行时加上"-"连接字符。
绑定变量
绑定变量是指在SQL语句中使用变量,改变变量的值来改变SQL语句的执行结果。
优点:使用绑定变量,可以减少SQL语句的解析,能减少数据库引擎消耗在SQL语句解析上的资源。提高了编程效率和可靠性。减少访问数据库的次数, 就能实际上减少oracle的工作量。
缺点:经常需要使用动态SQL的写法,由于参数的不同,可能SQL的执行效率不同;绑定变量是相对文本变量来讲的,所谓文本变量是指在SQL直接书写查询条件,这样的SQL在不同条件下需要反复解析,绑定变量是指使用变量来代替直接书写条件,查询bind value在运行时传递,然后绑定执行。优点是减少硬解析,降低cpu的争用,节省shared_pool缺点是不能使用histogram,SQL优化比较困难
索引
综合评价:★★★
select *from user_indexes 查询现有的索引
select *from user_ind_columns 可获知索引建立在那些字段上
1、什么是索引?、
一种用于提升查询效率的数据库对象;通过快速定位数据的方法,减少磁盘I/O操作;索引信息与表独立存放;Oracle数据库自动使用和维护索引。
2、 索引分类?
唯一索引和非唯一索引
3、 创建索引的两种方式?
自动创建,在定义主键或唯一键约束是系统会自动在相应的字段上创建唯一性索引。
手动创建,用户可以在其他列上创建非唯一索引,加速查询。
4、 索引优缺点
索引的优点
1.大大加快数据的检索速度;
2.创建唯一性索引,保证数据库表中每一行数据的唯一性;
3.加速表和表之间的连接;
4.在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。
有索引且查询条件能使用索引时,数据库会先选取索引,根据索引内容和查询条件,查询出rowid,再根据rowid取出需要的数据。由于索引内容通常比全表内容要少很多,因此通过先读索引,能减少i/o,提高查询性能。
索引的缺点
1.索引需要占物理空间。
2.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
5、 创建索引的原则
创建索引:创建索引一般有以下两个目的:维护被索引列的唯一性和提供快速访问表中数据
的策略。
--在select 操作占大部分的表上创建索引;
--在where 子句中出现最频繁的列上创建索引;
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
--在选择性高的列上创建索引(补充索引选择性,最高是1,eg:primary key)
--复合索引的主列应该是最有选择性的和where 限定条件最常用的列,并以此类推第二列……。
--小于5M 的表,最好不要使用索引来查询,表越小,越适合用全表扫描。
6、 使用索引的原则
--查询结果是所有数据行的5%以下时,使用index 查询效果最好;
--where 条件中经常用到表的多列时,使用复合索引效果会好于几个单列索引。因为当sql
语句所查询的列,全部都出现在复合索引中时,此时由于Oracle 只需要查询索引块即可获
得所有数据,当然比使用多个单列索引要快得多;
--索引利于select,但对经常insert,delte尤其update 的表,会降低效率。
eg:试比较下面两条SQL 语句(emp 表的deptno 列上建有ununique index):
语句A:SELECT dname, deptno FROM dept WHEREdeptno NOT IN
(SELECTdeptno FROM emp);
语句B:SELECT dname, deptno FROM dept WHERE NOTEXISTS
(SELECTdeptno FROM emp WHERE dept.deptno = emp.deptno);
注意:这两条查询语句实现的结果是相同的,但是执行语句A 的时候,ORACLE 会对整个emp 表进行扫描,没有使用建立在emp 表上的deptno 索引,执行语句B 的时候,由于在子查询中使用了联合查询,ORACLE 只是对emp 表进行的部分数据扫描,并利用了deptno 列的索引,
所以语句B 的效率要比语句A 的效率高。
----where子句中的这个字段,必须是复合索引的第一个字段;
eg:一个索引是按f1, f2, f3 的次序建立的,若where 子句是f2 = : var2, 则因为f2 不是索引的第1 个字段,无法使用该索引。
---- where 子句中的这个字段,不应该参与任何形式的计算:任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
---- 应尽量熟悉各种操作符对Oracle 是否使用索引的影响:以下这些操作会显式( explicitly )地阻止Oracle 使用索引: is null ; is not null; not in; !=; like ;
numeric_col+0;date_col+0;char_col||' '; to_char; to_number,to_date 等。
Eg:select jobid from mytabs where isReq='0' and to_date (updatedate)>= to_Date ( '2001-7-18','YYYY-MM-DD');--updatedate 列的索引也不会生效。
7、 创建索引
createindex abc on student(sid,sname);
createindex abc1 on student(sname,sid);
这两种索引方式是不一样的,索引abc 对Select * from student where sid=1; 这样的查询语句更有效索引abc1 对Select * from student where sname=’louis’; 这样的查询语句更有效因此建立索引的时候,字段的组合顺序是非常重要的。一般情况下,需要经常访问的字段放在组合字段的前面
8、 索引的存储
索引和表都是独立存在的。在为索引指定表空间的时候,不要将被索引的表和索引指向同
一个表空间,这样可以避免产生IO 冲突。使Oracle 能够并行访问存放在不同硬盘中的索引数据和表数据,更好的提高查询速度。
9、 删除索引
dropindex PK_DEPT1;
10、 索引类型
索引有b-tree、bit、cluster等类型。oracle使用了一个复杂的自平衡b-tree结构;
B 树索引(B-Tree Index)
创建索引的默认类型,结构是一颗树,采用的是平衡B 树算法:
右子树节点的键值大于等于父节点的键值;左子树节点的键值小于等于父节点的键值
比如有数据:100,101,102,103,104,105,106
位图索引(BitMap Index)
如果表中的某些字段取值范围比较小,比如职员性别、分数列ABC 级等。只有两个值。
这样的字段如果建B 树索引没有意义,不能提高检索速度。这时我们推荐用位图索引
CreateBitMap Index student on(sex);
11、 管理索引
1)先插入数据后创建索引
2)设置合理的索引列顺序
3)限制每个表索引的数量
4)删除不必要的索引
5)为每个索引指定表空间
6)经常做insert,delete 尤其是update的表最好定期exp/imp 表数据,整理数据,降低碎片(缺点:要停应用,以保持数据一致性,不实用);有索引的最好定期rebuild 索引(rebuild期间只允许表的select 操作,可在数据库较空闲时间提交),以降低索引碎片,提高效率
六、 oracle数据库
exp、imp备份数据库
综合评价:★★★
1)命令行备份,如:
a)将数据库test完全导出,用户名system 密码manager 导出到d:\daochu.dmp中,
exp system/manager@test file=d:\daochu.dmp full=y
b)将数据库中system用户与sys用户的表导出 ,
expsystem/manager@test file=d:\daochu.dmp owner=(system,sys)
c)将数据库中的表inner_notify、notify_staff_relat导出
expaichannel/aichannel@testdb2 file= d:\data\newsmgnt.dmp
tables=(inner_notify,notify_staff_relat)
详细内容请查阅oracle相关资料
2)dmp文件导入
将d:\daochu.dmp中的数据导入 test数据库中,
imp system/manager@test file=d:\daochu.dmp,如果已经存在需要导入的表,则使用如下命令imp system/manager@test file=d:\daochu.dmp ignore=y
将d:\daochu.dmp中的表table1 导入
imp system/manager@test file=d:\daochu.dmp tables=(table1)
不借助第三方工具,怎样查看SQL的执行计划
i) 使用explain plan,查询plan_table;
explainplan
setstatement_id='query1'
for
select *
from a
whereaa=1;
selectoperation, options, object_name, object_type, id, parent_id
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
fromplan_table
wherestatement_id = 'query1'
order byid;
ii)SQLplus中的set trace 即可看到execution plan statistics
setautotrace on;
如何使用cbo,cbo与rule的区别
if 初始化参数 optimizer_mode = choose then --(8i default)
if 做过表分析
then 优化器 optimizer=cbo(cost); /*高效*/
else
优化器 optimizer=rbo(rule); /*高效*/
end if;
end if;
区别:
rule根据规则选择最佳执行路径来运行查询。
cbo根据表统计找到最低成本的访问数据的方法确定执行计划。
使用cbo需要注意:
i) 需要经常对表进行analyze命令进行分析统计;
ii) 需要稳定执行计划;
iii)需要使用提示(hint);
使用rule需要注意:
i) 选择最有效率的表名顺序
ii) 优化SQL的写法;
在optimizer_mode=choose时,如果表有统计信息(分区表外),优化器将选择cbo,否则选rbo。
rbo遵循简单的分级方法学,使用15种级别要点,当接收到查询,优化器将评估使用到的要点数目,然后选择最佳级别(最
少的数量)的执行路径来运行查询。
cbo尝试找到最低成本的访问数据的方法,为了最大的吞吐量或最快的初始响应时间,计算使用不同的执行计划的成本,并
选择成本最低的一个,关于表的数据内容的统计被用于确定执行计划。
如何定位重要(消耗资源多)的SQL
使用cpu多的用户session
selecta.sid, spid, status, substr (a.program, 1, 40) prog, a.terminal,a.SQL_text,osuser, value / 60 /
100value
fromv$session a, v$process b, v$sesstat c
wherec.statistic# = 12 and c.sid = a.sid and a.paddr = b.addr
order byvalue desc;
select SQL_textfrom v$SQL
wheredisk_reads > 1000 or (executions > 0 and buffer_gets/executions> 30000);
如何跟踪某个session的SQL
利用trace 跟踪
altersession set SQLtrace on;
column SQLformat a200;
selectmachine, SQL_text SQL
from v$SQLtexta, v$session b
whereaddress = SQL_address
andmachine = '&a'
order byhash_value, piece;
execdbms_system.set_SQL_trace_in_session(sid,serial#,&SQL_trace);
selectsid,serial# from v$session where sid = (select sid from v$mystat where rownum =1);
execdbms_system.set_ev(&sid,&serial#,&event_10046,&level_12,'');
如何稳定(固定)执行计划
可以在SQL语句中指定执行计划。使用hints;
query_rewrite_enabled= true
star_transformation_enabled= true
optimizer_features_enable= 9.2.0
创建并使用stored outline
pctused and pctfree 表示什么含义有什么作用
pctused与pctfree控制数据块是否出现在freelist中, pctfree控制数据块中保留用于update的空间,当数据块中的
freespace小于pctfree设置的空间时,该数据块从freelist中去掉,当块由于dml操作free space大于pct_used设置的空
间时,该数据库块将被添加在freelist链表中。
简单描述tablespace / segment / extent / block之间的关系
tablespace:一个数据库划分为一个或多个逻辑单位,该逻辑单位成为表空间;每一个表空间可能包含一个或多个
segment;
segments:segment指在tablespace中为特定逻辑存储结构分配的空间。每一个段是由一个或多个extent组成。包括数据
段、索引段、回滚段和临时段。
extents:一个 extent 由一系列连续的 oracle blocks组成.oracle为通过extent 来给segment分配空间。
datablocks:oracle 数据库最小的i/o存储单位,一个data block对应一个或多个分配给data file的操作系统块。
table创建时,默认创建了一个data segment,每个data segment含有min extents指定的extents数,每个extent据据表空
间的存储参数分配一定数量的blocks
描述tablespace和datafile之间的关系
一个表空间可包含一个或多个数据文件。表空间利用增加或扩展数据文件扩大表空间,表空间的大小为组成该表空间的
数据文件大小的和。一个datafile只能属于一个表空间;
一个tablespace可以有一个或多个datafile,每个datafile只能在一个tablespace内, table中的数据,通过hash算法分布
在tablespace中的各个datafile中,tablespace是逻辑上的概念,datafile则在物理上储存了数据库的种种对象。
本地管理表空间和字典管理表空间的特点,assm有什么特点
本地管理表空间:(9i默认)空闲块列表存储在表空间的数据文件头。
特点:减少数据字典表的竞争,当分配和收缩空间时会产生回滚,不需要合并。
字典管理表空间:(8i默认)空闲块列表存储在数据库中的字典表里.
特点:片由数据字典管理,可能造成字典表的争用。存储在表空间的每一个段都会有不同的存储字句,需要合并相邻的
块;
本地管理表空间(locally managed tablespace简称lmt)
8i以后出现的一种新的表空间的管理模式,通过位图来管理表空间的空间使用。字典管理表空间(dictionary-managed
tablespace简称dmt)
8i以前包括以后都还可以使用的一种表空间管理模式,通过数据字典管理表空间的空间使用。动段空间管理(assm),
它首次出现在oracle920里有了assm,链接列表freelist被位图所取代,它是一个二进制的数组,
能够迅速有效地管理存储扩展和剩余区块(free block),因此能够改善分段存储本质,assm表空间上创建的段还有另
外一个称呼叫bitmap managed segments(bmb 段)。
回滚段的作用是什么
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
回滚段用于保存数据修改前的映象,这些信息用于生成读一致性数据库信息、在数据库恢复和rollback时使用。一个事
务只能使用一个回滚段。
事务回滚:当事务修改表中数据的时候,该数据修改前的值(即前影像)会存放在回滚段中,当用户回滚事务(
rollback)时,oracle将会利用回滚段中的数据前影像来将修改的数据恢复到原来的值。
事务恢复:当事务正在处理的时候,例程失败,回滚段的信息保存在undo表空间中,oracle将在下次打开数据库时利用
回滚来恢复未提交的数据。
读一致性:当一个会话正在修改数据时,其他的会话将看不到该会话未提交的修改。当一个语句正在执行时,该语句将
看不到从该语句开始执行后的未提交的修改(语句级读一致性)
当oracle执行select语句时,oracle依照当前的系统改变号(system change number-scn) 来保证任何前于当前scn的
未提交的改变不被该语句处理。可以想象:当一个长时间的查询正在执行时,若其他会话改变了该查询要查询的某个数
据块,oracle将利用回滚段的数据前影像来构造一个读一致性视图
日志的作用是什么
日志文件(log file)记录所有对数据库数据的修改,主要是保护数据库以防止故障,以及恢复数据时使用。其特点如
下:
a)每一个数据库至少包含两个日志文件组。每个日志文件组至少包含两个日志文件成员。
b)日志文件组以循环方式进行写操作。
c)每一个日志文件成员对应一个物理文件。
记录数据库事务,最大限度地保证数据的一致性与安全性
重做日志文件:含对数据库所做的更改记录,这样万一出现故障可以启用数据恢复,一个数据库至少需要两个重做日志文
件
归档日志文件:是重做日志文件的脱机副本,这些副本可能对于从介质失败中进行恢复很必要。
sga主要有那些部分,主要作用是什么
系统全局区(sga):是oracle为实例分配的一组共享缓冲存储区,用于存放数据库数据和控制信息,以实现对数据库数
据的管理和操作。
sga主要包括:
a)共享池(shared pool) :用来存储最近执行的SQL语句和最近使用的数据字典的数据。
b)数据缓冲区 (database buffer cache):用来存储最近从数据文件中读写过的数据。
c)重作日志缓冲区(redo log buffer):用来记录服务或后台进程对数据库的操作。
另外在sga中还有两个可选的内存结构:
d)javapool: 用来存储java代码。
e)largepool: 用来存储不与SQL直接相关的大型内存结构。备份、恢复使用。
ga:db_cache/shared_pool/large_pool/java_pool
db_cache:数据库缓存(block buffer)对于oracle数据库的运转和性能起着非常关键的作用,它占据oracle数据库sga
(系统共享内存区)的主要部分。oracle数据库通过使用lru算法,将最近访问的数据块存放到缓存中,从而优化对磁盘
数据的访问.
shared_pool:共享池的大小对于oracle 性能来说都是很重要的。共享池中保存数据字典高速缓冲和完全解析或编译的
的pl/SQL 块和SQL 语句及控制结构
large_pool:使用mts配置时,因为要在sga中分配uga来保持用户的会话,就是用large_pool来保持这个会话内存使用
rman做备份的时候,要使用large_pool这个内存结构来做磁盘i/o缓存器
java_pool:为java procedure预备的内存区域,如果没有使用java proc,java_pool不是必须的
oracle系统进程主要有哪些,作用是什么
数据写进程(dbwr):负责将更改的数据从数据库缓冲区高速缓存写入数据文件
日志写进程(lgwr):将重做日志缓冲区中的更改写入在线重做日志文件
系统监控 (smon): 检查数据库的一致性如有必要还会在数据库打开时启动数据库的恢复
进程监控 (pmon): 负责在一个oracle 进程失败时清理资源
检查点进程(ckpt):负责在每当缓冲区高速缓存中的更改永久地记录在数据库中时,更新控制文件和数据文件中的数据库
状态信息。
归档进程 (arch):在每次日志切换时把已满的日志组进行备份或归档
恢复进程 (reco): 保证分布式事务的一致性,在分布式事务中,要么同时commit,要么同时rollback;
作业调度器(cjq ): 负责将调度与执行系统中已定义好的job,完成一些预定义的工作.
oracle备份分类
逻辑备份:exp/imp 指定表的逻辑备份
物理备份:
热备份:alter tablespace begin/end backup;
冷备份:脱机备份(database shutdown)
rman备份
fullbackup/incremental backup(累积/差异)
物理备份
物理备份是最主要的备份方式。用于保证数据库在最小的数据库丢失或没有数据丢失的情况下得到恢复。
冷物理
冷物理备份提供了最简单和最直接的方法保护数据库因物理损坏丢失。建议在以下几种情况中使用。
对一个已经存在大最数据量的数据库,在晚间数据库可以关闭,此时应用冷物理备份。
对需对数据库服务器进行升级,(如更换硬盘),此时需要备份数据库信息,并在新的硬盘中恢复这些数据信息,建议
采用冷物理备份。
热物理
主要是指备份过程在数据库打开并且用户可以使用的情况下进行。需要执行热物理备份的情况有:
由于数据库性质要求不间断工作,因而此时只能采用热物理备份。
由于备份的要求的时间过长,而数据库只能短时间关闭时。
逻辑备份 (exp/imp)
逻辑备份用于实现数据库对象的恢复。但不是基于时间点可完全恢复的备份策略。只能作为联机备份和脱机备份的一种
补充。
完全逻辑备份
完全逻辑备份是将整个数据库导出到一个数据库的格式文件中,该文件可以在不同的数据库版本、操作系统和硬件平台
之间进行移植。
指定表的逻辑备份
通过备份工具,可以将指定的数据库表备份出来,这可以避免完全逻辑备份所带来的时间和财力上的浪费。
归档是什么含义
关于归档日志:oracle要将填满的在线日志文件组归档时,则要建立归档日志(archived redo log)。其对数据库备份
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
和恢复有下列用处:
数据库后备以及在线和归档日志文件,在操作系统和磁盘故障中可保证全部提交的事物可被恢复。
在数据库打开和正常系统使用下,如果归档日志是永久保存,在线后备可以进行和使用。
数据库可运行在两种不同方式下:noarchivelog方式或archivelog 方式
数据库在noarchivelog方式下使用时,不能进行在线日志的归档,
数据库在archivelog方式下运行,可实施在线日志的归档
归档是归档当前的联机redo日志文件。
svrmgr>alter system archive log current;
数据库只有运行在archivelog模式下,并且能够进行自动归档,才可以进行联机备份。有了联机备份才有可能进行完全
恢复。
如果一个表在2004-08-04 10:30:00 被drop,在有完善的归档和备份的情况下,如何恢复
9i 新增的flash back 应该可以;
logminer应该可以找出dml。
有完善的归档和备份,先归档当前数据,然后可以先恢复到删除的时间点之前,把drop 的表导出来,然后再恢复到最后
归档时间;
手工拷贝回所有备份的数据文件
SQL〉startup mount;
SQL〉alter database recover automatic until time '2004-08-04:10:30:00';
SQL〉alter database open resetlogs;
rman是什么,有何特点
rman(recoverymanager)是dba的一个重要工具,用于备份、还原和恢复oracle数据库, rman 可以用来备份和恢复数据
库文件、归档日志、控制文件、系统参数文件,也可以用来执行完全或不完全的数据库恢复。
rman有三种不同的用户接口:command line方式、gui 方式(集成在oem 中的备份管理器)、api 方式(用于集成到第
三方的备份软件中)。
具有如下特点:
1)功能类似物理备份,但比物理备份强大n倍;
2)可以压缩空块;
3)可以在块水平上实现增量;
4)可以把备份的输出打包成备份集,也可以按固定大小分割备份集;
5)备份与恢复的过程可以自动管理;
6)可以使用脚本(存在recovery catalog 中)
7)可以做坏块监测
七、 专题研究
重复数据处理
查看重复记录
select * from table_name where id in (select id from table_name groupby id having count(*)>1)
过滤掉所有多余的重复记录
select distinct * from table_name
或 select t.col1,t.col2 from table_name t group by t.col1,t.col2
删除重复记录
单表记录重复
1)delete from table_namewhere id not in (select max(id)from table_name group by col1,col2,...);
2)delete from table_namet where exists(select 1 from table_name where col1=t.col1 and col2=t. col2 and col3=t. col3 and id>t.id);
多表无效记录
一、两张关联表,删除主表中已经在副表中没有的信息
delete from table1 where not exists ( select 1 from table2 wheretable1.field1=table2.field1)
二、包括所有在 tablea 中但不在 tableb和tablec 中的行并消除所有重复行而派生出一个结果表(minus、intersect)
select a from tablea minus(select afrom tableb union select a from tablec)
查询表中列的值重复出现多次
注:查询表a中存在id重复3次以上的记录
select *from a t where exists (select 1 from a t1 where t.id = t1.idgroup by id having count(id) > 3);
重复数据处理实践
create table emp(
idint not null primary key,
name varchar (25),
age int
);
insert into empvalues(test_sequence.nextval,'zhang1',26);
insert into empvalues(test_sequence.nextval,'zhang2',27);
insert into empvalues(test_sequence.nextval,'zhang3',28);
insert into emp values(test_sequence.nextval,'zhang1',26);
insert into empvalues(test_sequence.nextval,'zhang2',27);
insert into empvalues(test_sequence.nextval,'zhang3',29);
insert into empvalues(test_sequence.nextval,'wang2',26);
insert into emp values(test_sequence.nextval,'wang1',22);
使用不同的方法查询出重复的数据
--解法一:查询重复记录的一个方法就是分组统计:
select * from emp where name in (select name from emp group by name having count(*)>1);使用in 或者exists
--查询出重复的名称及重复次数
方法一、select sum(1)as sig, name from emp group by name having sum(1) > 1;
方法二、select name, count(*) from empgroup by name having count(*)>1;
count(*)的效率比sum(1)要高
--解法二:如果对每个名字都和原表进行比较,大于2个人名字与这条记录相同的就是合格的,就有:
select * from emp where ( select count(*)from emp e where e.name = emp.name )>1;
--解法三:如果有另外一个名字相同的人工号不与他相同那么这条记录符合要求:
select * from emp where exists (select *from emp e where e.name = emp.name and
e.id<>emp.id);
解法四:思路同解法三
select distinct emp.* from emp inner join emp e onemp.name=e.name and emp.id<>e.id;
查询过滤掉所有多余的重复记录
--解法一:通过distinct、group by过滤重复 扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
select distinct name,age from emp;
或
select name,age from emp group by name,age;
--解法二:使用临时表
--不推荐
select distinct * into #tmp from emp;
delete from emp;
insert into emp select * from #tmp;
--解法三:使用rowid
--高效,name列使用了索引。
select * from emp a where a.rowid = (selectmin(b.rowid) from emp b where a.name = b.name);
--普通
select a.* from emp a,(select min(b.rowid)row_id from emp b group by b.name) b where a.rowid = b.row_id;
删除SQL表中重复的记录
注:除id值不一样外其它字段都一样,每两行记录重复
delete from emp t where exists(select 1from emp where name = t.name and age = t.age and t.id < id)
基于oracle数据背景的重复记录删除
综合评价:★★★
(1).在oracle中,每一条记录都有一个rowid,rowid在整个数据库中是唯一的,rowid确定了每条记录是在oracle中的哪一个数据文件、块、行上。
(2).在重复的记录中,可能所有列的内容都相同,但rowid不会相同,所以只要确定出重复记录中那些具有最大rowid的就可以了,其余全部删除。
重复记录判断的标准是:
c1,c10和c20这三列的值都相同才算是重复记录,并且保存最新的记录。
(1).适用于有大量重复记录的情况(在c1,c10和c20列上建有索引的时候,用以下语句效率会很高):
方法一、delete from cz where(c1,c10,c20) in (select c1,c10,c20 from cz group by c1,c10,c20 havingcount(*)>1) and rowid not in selectmin(rowid) from cz group by c1,c10,c20 having count(*)>1);
方法二、delete from cz where rowid not in(select min(rowid) fromcz group by c1,c10,c20);
(2).适用于有少量重复记录的情况(注意,对于有大量重复记录的情况,用以下语句效率会很低):
方法一、delete from cz a where a.rowid!=(select max(rowid) from cz b wherea.c1=b.c1 and a.c10=b.c10 and a.c20=b.c20);
方法二、delete from cz a where a.rowid<(select max(rowid) from cz b wherea.c1=b.c1 and a.c10=b.c10 and a.c20=b.c20);
方法三、delete from cz a where rowid <(select max(rowid) from cz wherec1=a.c1 and c10=a.c10 and c20=a.c20);
详细教程:http://www.csdn.net/article/2010-08-17/278287
oracle取随机数据
注:随机取出n条数据
1)select * from (select * from tablename order bysys_guid()) where rownum < n;
2)select * from (select * from tablename order by dbms_random.value)where rownum< n
3)select * from (select *from tablename sample(n) order by trunc(dbms_random.value(0,1000))) where rownum < n;
说明: sample(n)含义为检索表中的n%数据,sample值应该在[0.000001,99.999999]之间。
其中 sys_guid() 和 dbms_random.value都是内部函数。
oracle中一般获取随机数的方法是
select trunc(dbms_random.value(0,1000)) from dual; (0-1000的整数)
select dbms_random.value(0, 1000) fromdual; (0-1000的浮点数)
oracle 关键字case的用法
case匹配语句
case expression
when value then statement
[when value then statement ]...
[else statement [, statement ]... ]
end case;
case搜索语句
case
when (boolean_condition1) then action1;
when (boolean_condition2) then action2;
when (boolean_condition3) then action3;
……
else action;
end case;
select case 语句
有一张表,里面有3个字段:语文,数学,英语。其中有3条记录分别表示语文70分,数学80分,英语58分,请用一条SQL语句查询出这三条记录并按以下条件显示出来。大于或等于80表示优秀,大于或等于60表示及格,小于60分表示不及格。
显示格式:
语文 数学 英语
及格 优秀 不及格
------------------------------------------
select
(case when 语文>=80 then '优秀'
when 语文>=60 then '及格'
else '不及格') as 语文,
(case when 数学>=80 then'优秀'
when 数学>=60 then '及格'
else '不及格') as 数学,
(case when 英语>=80 then'优秀'
when 英语>=60 then '及格'
else '不及格') as 英语
from table
oracle日期函数
一、日程安排提前五分钟提醒(oracle 日期函数)
select * from 日程安排 where datediff(‘minute’,开始时间,getdate())>5
二、请取出tb_send表中日期(sendtime字段)为当天的所有记录?(sendtime字段为date型,包含日期与时间)
select * from tb_send t where to_char(t.sendtime,’yyyy-mm-dd’) = to_char(sysdate,’yyyy-mm-dd’) |
oracle trunc()函数的用法
综合评价:★★
trunc() 操作日期
1.select trunc(sysdate) from dual --2011-3-18 今天的日期为2011-3-18 2.select trunc(sysdate, 'mm') from dual --2011-3-1 返回当月第一天. 扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库 3.select trunc(sysdate,'yy') from dual --2011-1-1 返回当年第一天 4.select trunc(sysdate,'dd') from dual --2011-3-18 返回当前年月日 5.select trunc(sysdate,'yyyy') from dual --2011-1-1 返回当年第一天 6.select trunc(sysdate,'d') from dual --2011-3-13 (星期天)返回当前星期的第一天 7.select trunc(sysdate, 'hh') from dual --2011-3-18 14:00:00 当前时间为14:41 8.select trunc(sysdate, 'mi') from dual --2011-3-18 14:41:00 trunc()函数没有秒的精确 |
trunc() 操作数字
注:trunc(number,num_digits) number 需要截尾取整的数字。 num_digits 用于指定取整精度的数字。num_digits 的默认值为 0。trunc()函数截取时不进行四舍五入
9.select trunc(123.458) from dual --123 10.select trunc(123.458,0) from dual --123 11.select trunc(123.458,1) from dual --123.4 12.select trunc(123.458,-1) from dual --120 13.select trunc(123.458,-4) from dual --0 | 14.select trunc(123.458,4) from dual --123.458 15.select trunc(123) from dual --123 16.select trunc(123,1) from dual --123 17.select trunc(123,-1) from dual –120 |
计算当月的天数
综合评价:★★
select datepart(dd,dateadd(dd,-1,dateadd(mm,1,cast(cast(year(getdate()) as varchar)+'-'+cast(month(getdate()) as varchar)+'-01' as datetime)))) |
1.求当年天数
selectadd_months(trunc(sysdate, 'yyyy'), 12) - trunc(sysdate, 'yyyy') days from dual
2.求当月天数
selectto_number(to_char(last_day(trunc(sysdate)),'dd')) from dual
3.求指定月天数
select to_number(add_months(trunc(to_date('2013-06-1710:09:02',
'yyyy-fmmm-ddhh24:mi:ss'), 'mm'), 1) - trunc(to_date('2013-06-17 10:09:02',
'yyyy-fmmm-ddhh24:mi:ss'), 'mm')) from dual;
oracle临时表
oracle多行数据分组拼接
只用一条SQL语句,要求从左表查询出右表
lefttable: righttable:
id name id name
---------- ------------------
1 a5 1 a5,a8,af....
2 a8 2 b5,b3,bd....
3 af 3 c3,ck,ci....
4 b5
5 b3
6 bd
7 c3
8 ck
9 ci
解答:
select replace(wmsys.wm_concat(t.name),',',',')from lefttable t group by substr(t.name,0,1);
oracle分析函数
oracle 常用函数,nvl、递归、字符串操作、日期操作、数字操作
case when、正则表达式操作
oracle分页与rownum
参照表:test_tb_grade
题目:查询6到10条数据。
解法一、注:采用rownum关键字(三层嵌套)
select * from ( select t.*,rownum rn from (select * from test_tb_grade order by user_id) t where rownum <= 10) where rn >=6; |
解法二、注:采用row_number解析函数进行分页(效率更高)
select * from ( select t.*, row_number() over(order by t.user_id) rn from test_tb_grade t) where rn between 6 and 10; |
行转列,列转行
行转列
create table test_tb_grade -- 学生语文、数学、英语成绩统计
(
user_id number(10) not nullprimary key,
user_name varchar2(20),
course varchar2(20),
score float
);
create sequence test_sequence;
insert into test_tb_gradevalues(test_sequence.nextval,'m','c',78);
insert into test_tb_gradevalues(test_sequence.nextval,'m','m',95);
insert into test_tb_gradevalues(test_sequence.nextval,'m','e',81);
insert into test_tb_gradevalues(test_sequence.nextval,'z','c',97);
insert into test_tb_gradevalues(test_sequence.nextval,'z','m',78);
insert into test_tb_gradevalues(test_sequence.nextval,'z','e',91);
insert into test_tb_gradevalues(test_sequence.nextval,'l','c',80);
insert into test_tb_grade values(test_sequence.nextval,'l','m',55);
insert into test_tb_gradevalues(test_sequence.nextval,'l','e',75);
insert into test_tb_gradevalues(test_sequence.nextval,'v','c',49);
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
insert into test_tb_gradevalues(test_sequence.nextval,'v','m',63);
insert into test_tb_grade values(test_sequence.nextval,'v','e',70);
insert into test_tb_gradevalues(test_sequence.nextval,'k','e',53);
insert into test_tb_gradevalues(test_sequence.nextval,'k','m',58);
insert into test_tb_gradevalues(test_sequence.nextval,'k','c',59);
insert into test_tb_gradevalues(test_sequence.nextval,'k','c',59);
commit;
列出不同科目下学生对应的成绩,如图
注:sum聚集函数也可以用max、min、avg等其他聚集函数替代。不同聚合函数得到结果根据数据会有稍微的差异
select user_name,
sum(decode(course,'c',score,null)) aschinese,
sum(decode(course,'m',score,null)) as math,
sum(decode(course,'e',score,null)) as english
from test_tb_grade
group by user_name
order by 1;
列转行
create table test_tb_grade2 (
gidnumber(10) primary key,
sname varchar2(20),
cn_score float,
math_score float,
en_score float
);
insert into test_tb_grade2 values(test_sequence.nextval,'m',70,65,60);
insert into test_tb_grade2 values(test_sequence.nextval,'l',74,83,76);
insert into test_tb_grade2 values(test_sequence.nextval,'v',80,68,89);
insert into test_tb_grade2 values (test_sequence.nextval,'k',80,83,82);
insert into test_tb_grade2 values(test_sequence.nextval,'z',58,86,80);
commit;
查询结果如图:
需要实现到如下效果:
方法一、union all
select t2.sname,'chinese' as course,t2.cn_score as score from test_tb_grade2 t2 -- 语文
union all
select t2.sname,'math' as course,t2.math_score as score from test_tb_grade2 t2 -- 数学
union all
select t2.sname,'english' as course,t2.en_score as score from test_tb_grade2 t2 -- 英语
方法二、model (复杂)
方法三、collection(涉及到数组、集合、对象)
分组统计与取值
分组统计
实现对各门功课的不同分数段的学生进行统计(0-60,60-70,70-80..)
方法一、select t2.course,count(t2.course),'0-60'as ts from (
select t.course,t.score from test_tb_gradet group by t.course,t.score having t.score<60 ) t2 group by t2.course
union all
select t2.course,count(t2.course),'60-70'asts from (
select t.course,t.score from test_tb_gradet group by t.course,t.score having t.score>60 and t.score<=70 ) t2 groupby t2.course….
方法二、select t.course,
case
when t.score<= 60 then '0-60'
when 60< t.score and t.score <=70 then '60-70'
when 70< t.score and t.score <=80 then '70-80'
when 80< t.score then '80-100'
else 'error' end as score_cp,
count(t.course)
fromtest_tb_grade t group by t.course
得到如下视图
取前n条记录
参照表:test_tb_grade
题目:查询出每个学生分数最高的两门课(允许并列第二)
解法一、注:使用左联接和分组函数
select t1.user_id,t1.user_name,t1.course,t1.score from test_tb_grade t1 left
join test_tb_grade t2 on t1.user_name =t2.user_name and t1.score < t2.score
group by t1.user_id,t1.user_name,t1.course,t1.score
having count(t2.user_id) < 2;
解法二、注:oracle分析函数(不出现并列)
select * from (
select user_id, user_name, course, score, row_number()over(partition byuser_nameorder by score desc) rn from test_tb_grade) where rn <= 2;
解法三、注:使用关联子查询
select * from test_tb_grade t where 2 > (
select count(*) from test_tb_grade where user_name= t.user_name and t.score < score);
取最大记录
参照表:test_tb_grade
题目:查询每个单科分数最高的信息
解法一、注:分组函数不能放到where后面
select * from test_tb_grade t where t.score=
( select max(score) from test_tb_gradewhere course = t.course) order by t.user_name;
解法二、注:使用notexists 关键字
select * from test_tb_grade t where not exists
(select 1 from test_tb_grade where course = t. course andt.score < score);
解法三、注:使用内连接查询
select t.* from test_tb_grade t,
(select course,max(score) score fromtest_tb_grade group by course) t1
where t. course = t1. course and t.score =t1.score;
解法四、注:使用关联子查询
select t.* from test_tb_grade t where 1> (select count(*) from test_tb_grade where user_name = t.user_name andt.score < score);
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
八、 练习题
一、s(s#,sn,sd,sa) s#,sn,sd,sa分别代表学号,学员姓名,所属单位,学员年龄
c(c#,cn) c#,cn分别代表课程编号,课程名称
sc(s#,c#,g) s#,c#,g分别代表学号,所选的课程编号,学习成绩
(1)使用标准SQL嵌套语句查询选修课程名称为’税收基础’的学员学号和姓名?
答案:select s# ,sn from s where s# in(select s# from c,sc wherec.c#=sc.c# and cn=’税收基础’)
selects.s#, s.sn from sc,s,c where c.c# = sc.c# and sc.s# = s.s# and c.cn = ‘税收基础’;
selects#, sn from s where exists (select 1 from c,sc where c.c# = sc.c# and c.cn = ‘税收基础’ andsc.s# = s.s#);
(2) 使用标准SQL嵌套语句查询选修课程编号为’c2’的学员姓名和所属单位?
答:select sn,sd from s,sc where s.s#=sc.s# and sc.c#=’c2’;
(3) 使用标准SQL嵌套语句查询不选修课程编号为’c5’的学员姓名和所属单位?
答:select sn,sd from s where s# not in(select s# from sc where c#=’c5’)
(4)查询选修了课程的学员人数
selectcount(distinct s#) 学员人数 from sc;
(5) 查询选修课程超过5门的学员学号和所属单位
selectsn,sd from s where s# in(select s# from sc group by s# having count(distinctc#)>5)
selects#, sd from s t where exists (select 1 from sc where t.s# = s# group by #having count(distinct c#)>5);
(6)查询a(id,name)表中第31至40条记录,id作为主键可能是不是连续增长的列
SQLserver:
select top 10 * from (select top 40 * from a order by id)order by id desc;
mySQL:
select * from a limit 31,40;
oracle:rownum 始终从下一个整数开始,第一值是1,如果前9个值可以确定,那下一个值就10(rownum 是伪列)
select * from (select t.*, rownum rn from at where rownum <= 40 order by id) t1 where t1.rn => 31;
(7)查询表a中存在id重复三次以上的记录
select *from a t where exists (select 1 from a t1 where t1.id = t.id group by id havingcount(id) > 3);
(8)游标使用
-- 声明游标;CURSOR cursor_name IS select_statement
--For 循环游标
--(1)定义游标
--(2)定义游标变量
--(3)使用for循环来使用这个游标
declare
--类型定义
cursor c_job
is
select empno,ename,job,sal
from emp
where job='MANAGER';
--定义一个游标变量v_cinfoc_emp%ROWTYPE ,该类型为游标c_emp中的一行数据类型
c_row c_job%rowtype;
begin
for c_row in c_job loop
dbms_output.put_line(c_row.empno||'-'||c_row.ename||'-'||c_row.job||'-'||c_row.sal);
end loop;
end;
--Fetch游标
--使用的时候必须要明确的打开和关闭
declare
--类型定义
cursor c_job
is
select empno,ename,job,sal
from emp
where job='MANAGER';
--定义一个游标变量
c_row c_job%rowtype;
begin
open c_job;
loop
--提取一行数据到c_row
fetch c_job into c_row;
--判读是否提取到值,没取到值就退出
--取到值c_job%notfound 是false
--取不到值c_job%notfound 是true
exit when c_job%notfound;
dbms_output.put_line(c_row.empno||'-'||c_row.ename||'-'||c_row.job||'-'||c_row.sal);
end loop;
--关闭游标
close c_job;
end;
--1:任意执行一个update操作,用隐式游标sql的属性%found,%notfound,%rowcount,%isopen观察update语句的执行情况。
begin
update emp set ENAME='ALEARK' WHEREEMPNO=7469;
if sql%isopen then
dbms_output.put_line('Openging');
else
dbms_output.put_line('closing');
end if;
if sql%found then
dbms_output.put_line('游标指向了有效行');--判断游标是否指向有效行
else
dbms_output.put_line('Sorry');
end if;
if sql%notfound then
dbms_output.put_line('Also Sorry');
else
dbms_output.put_line('Haha');
end if;
dbms_output.put_line(sql%rowcount);
exception
when no_data_found then
dbms_output.put_line('Sorry No data');
when too_many_rows then
dbms_output.put_line('Too Many rows');
end;
declare
empNumber emp.EMPNO%TYPE;
empName emp.ENAME%TYPE;
begin
if sql%isopen then
dbms_output.put_line('Cursor is opinging');
else
dbms_output.put_line('Cursor is Close');
end if;
if sql%notfound then
dbms_output.put_line('No Value');
else
dbms_output.put_line(empNumber);
end if;
dbms_output.put_line(sql%rowcount);
dbms_output.put_line('-------------');
select EMPNO,ENAME into empNumber,empName fromemp where EMPNO=7499;
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
dbms_output.put_line(sql%rowcount);
if sql%isopen then
dbms_output.put_line('Cursor is opinging');
else
dbms_output.put_line('Cursor is Closing');
end if;
if sql%notfound then
dbms_output.put_line('No Value');
else
dbms_output.put_line(empNumber);
end if;
exception
when no_data_found then
dbms_output.put_line('No Value');
when too_many_rows then
dbms_output.put_line('too many rows');
end;
--2,使用游标和loop循环来显示所有部门的名称
--游标声明
declare
cursor csr_dept
is
--select语句
select DNAME
from Depth;
--指定行指针,这句话应该是指定和csr_dept行类型相同的变量
row_dept csr_dept%rowtype;
begin
--for循环
for row_dept in csr_dept loop
dbms_output.put_line('部门名称:'||row_dept.DNAME);
end loop;
end;
--3,使用游标和while循环来显示所有部门的的地理位置(用%found属性)
declare
--游标声明
cursor csr_TestWhile
is
--select语句
select LOC
from Depth;
--指定行指针
row_loc csr_TestWhile%rowtype;
begin
--打开游标
open csr_TestWhile;
--给第一行喂数据
fetch csr_TestWhile into row_loc;
--测试是否有数据,并执行循环
while csr_TestWhile%found loop
dbms_output.put_line('部门地点:'||row_loc.LOC);
--给下一行喂数据
fetch csr_TestWhile into row_loc;
end loop;
close csr_TestWhile;
end;
select *from emp
--4,接收用户输入的部门编号,用for循环和游标,打印出此部门的所有雇员的所有信息(使用循环游标)
--CURSORcursor_name[(parameter[,parameter],...)] IS select_statement;
--定义参数的语法如下:Parameter_name [IN] data_type[{:=|DEFAULT} value]
declare
CURSOR
c_dept(p_deptNo number)
is
select * from emp where emp.depno=p_deptNo;
r_emp emp%rowtype;
begin
for r_emp in c_dept(20) loop
dbms_output.put_line('员工号:'||r_emp.EMPNO||'员工名:'||r_emp.ENAME||'工资:'||r_emp.SAL);
end loop;
end;
select *from emp
--5:向游标传递一个工种,显示此工种的所有雇员的所有信息(使用参数游标)
declare
cursor
c_job(p_job nvarchar2)
is
select * from emp where JOB=p_job;
r_job emp%rowtype;
begin
for r_job in c_job('CLERK') loop
dbms_output.put_line('员工号'||r_job.EMPNO||' '||'员工姓名'||r_job.ENAME);
end loop;
end;
SELECT *FROM EMP
--6:用更新游标来为雇员加佣金:(用if实现,创建一个与emp表一摸一样的emp1表,对emp1表进行修改操作),并将更新前后的数据输出出来
create table emp1 as select * from emp;
declare
cursor
csr_Update
is
select * from emp1 for update OF SAL;
empInfo csr_Update%rowtype;
saleInfo emp1.SAL%TYPE;
begin
FOR empInfo IN csr_Update LOOP
IF empInfo.SAL<1500 THEN
saleInfo:=empInfo.SAL*1.2;
elsif empInfo.SAL<2000 THEN
saleInfo:=empInfo.SAL*1.5;
elsif empInfo.SAL<3000 THEN
saleInfo:=empInfo.SAL*2;
END IF;
UPDATE emp1 SET SAL=saleInfo WHERE CURRENT OFcsr_Update;
END LOOP;
END;
--7:编写一个PL/SQL程序块,对名字以‘A’或‘S’开始的所有雇员按他们的基本薪水(sal)的10%给他们加薪(对emp1表进行修改操作)
declare
cursor
csr_AddSal
is
select * from emp1 where ENAME LIKE 'A%' ORENAME LIKE 'S%' for update OF SAL;
r_AddSal csr_AddSal%rowtype;
saleInfo emp1.SAL%TYPE;
begin
for r_AddSal in csr_AddSal loop
dbms_output.put_line(r_AddSal.ENAME||'原来的工资:'||r_AddSal.SAL);
saleInfo:=r_AddSal.SAL*1.1;
UPDATE emp1 SET SAL=saleInfo WHERE CURRENT OFcsr_AddSal;
end loop;
end;
--8:编写一个PL/SQL程序块,对所有的salesman增加佣金(comm)500
declare
cursor
csr_AddComm(p_job nvarchar2)
is
select * from emp1 where JOB=p_job FOR UPDATEOF COMM;
r_AddComm emp1%rowtype;
commInfo emp1.comm%type;
begin
for r_AddComm in csr_AddComm('SALESMAN') LOOP
commInfo:=r_AddComm.COMM+500;
UPDATE EMP1 SET COMM=commInfo where CURRENT OFcsr_AddComm;
END LOOP;
END;
--9:编写一个PL/SQL程序块,以提升2个资格最老的职员为MANAGER(工作时间越长,资格越老)
--(提示:可以定义一个变量作为计数器控制游标只提取两条数据;也可以在声明游标的时候把雇员中资格最老的两个人查出来放到游标中。)
declare
cursor crs_testComput
is
select * from emp1 order by HIREDATE asc;
--计数器
top_two number:=2;
r_testComput crs_testComput%rowtype;
begin
open crs_testComput;
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
FETCH crs_testComput INTO r_testComput;
while top_two>0 loop
dbms_output.put_line('员工姓名:'||r_testComput.ENAME||' 工作时间:'||r_testComput.HIREDATE);
--计速器减一
top_two:=top_two-1;
FETCH crs_testComput INTO r_testComput;
end loop;
close crs_testComput;
end;
--10:编写一个PL/SQL程序块,对所有雇员按他们的基本薪水(sal)的20%为他们加薪,
--如果增加的薪水大于300就取消加薪(对emp1表进行修改操作,并将更新前后的数据输出出来)
declare
cursor
crs_UpadateSal
is
select * from emp1 for update of SAL;
r_UpdateSal crs_UpadateSal%rowtype;
salAdd emp1.sal%type;
salInfo emp1.sal%type;
begin
for r_UpdateSal in crs_UpadateSal loop
salAdd:= r_UpdateSal.SAL*0.2;
if salAdd>300 then
salInfo:=r_UpdateSal.SAL;
dbms_output.put_line(r_UpdateSal.ENAME||': 加薪失败。'||'薪水维持在:'||r_UpdateSal.SAL);
else
salInfo:=r_UpdateSal.SAL+salAdd;
dbms_output.put_line(r_UpdateSal.ENAME||': 加薪成功.'||'薪水变为:'||salInfo);
end if;
update emp1 set SAL=salInfo where current ofcrs_UpadateSal;
end loop;
end;
--11:将每位员工工作了多少年零多少月零多少天输出出来
--近似
--CEIL(n)函数:取大于等于数值n的最小整数
--FLOOR(n)函数:取小于等于数值n的最大整数
--truc的用法
declare
cursor
crs_WorkDay
is
select ENAME,HIREDATE,trunc(months_between(sysdate, hiredate) / 12) AS SPANDYEARS,
trunc(mod(months_between(sysdate, hiredate),12)) AS months,
trunc(mod(mod(sysdate - hiredate, 365), 12))as days
from emp1;
r_WorkDay crs_WorkDay%rowtype;
begin
for r_WorkDay in crs_WorkDay loop
dbms_output.put_line(r_WorkDay.ENAME||'已经工作了'||r_WorkDay.SPANDYEARS||'年,零'||r_WorkDay.months||'月,零'||r_WorkDay.days||'天');
end loop;
end;
--12:输入部门编号,按照下列加薪比例执行(用CASE实现,创建一个emp1表,修改emp1表的数据),并将更新前后的数据输出出来
--deptno raise(%)
-- 10 5%
-- 2010%
-- 3015%
-- 4020%
-- 加薪比例以现有的sal为标准
--CASEexpr WHEN comparison_expr THEN return_expr
--[,WHEN comparison_expr THEN return_expr]... [ELSE else_expr] END
declare
cursor
crs_caseTest
is
select * from emp1 for update of SAL;
r_caseTest crs_caseTest%rowtype;
salInfo emp1.sal%type;
begin
for r_caseTest in crs_caseTest loop
case
when r_caseTest.DEPNO=10
THEN salInfo:=r_caseTest.SAL*1.05;
when r_caseTest.DEPNO=20
THEN salInfo:=r_caseTest.SAL*1.1;
when r_caseTest.DEPNO=30
THEN salInfo:=r_caseTest.SAL*1.15;
when r_caseTest.DEPNO=40
THEN salInfo:=r_caseTest.SAL*1.2;
end case;
update emp1 set SAL=salInfo where current ofcrs_caseTest;
end loop;
end;
--13:对每位员工的薪水进行判断,如果该员工薪水高于其所在部门的平均薪水,则将其薪水减50元,输出更新前后的薪水,员工姓名,所在部门编号。
--AVG([distinct|all]expr) over (analytic_clause)
---作用:
--按照analytic_clause中的规则求分组平均值。
--分析函数语法:
--FUNCTION_NAME(,...)
--OVER
--()
--PARTITION子句
--按照表达式分区(就是分组),如果省略了分区子句,则全部的结果集被看作是一个单一的组
select * from emp1
DECLARE
CURSOR
crs_testAvg
IS
select EMPNO,ENAME,JOB,SAL,DEPNO,AVG(SAL) OVER(PARTITION BY DEPNO ) AS DEP_AVG
FROM EMP1 for update of SAL;
r_testAvg crs_testAvg%rowtype;
salInfo emp1.sal%type;
begin
for r_testAvg in crs_testAvg loop
if r_testAvg.SAL>r_testAvg.DEP_AVG then
salInfo:=r_testAvg.SAL-50;
end if;
update emp1 set SAL=salInfo where current ofcrs_testAvg;
end loop;
end;
九、 存在的问题
1) 存储过程、游标使用
2) Oracle常用函数、分析函数、oracle 递归查询
3) 基于oracle的SQL优化
4)数据库设计原则、设计规范学习
5) 教材:数据库设计与开发、数据库设计入门。。。。
扩展:oracle数据库教程 / oracle数据库基础教程 / oracle数据库
三 : 中文版Access2007实用教程_第一章--数据库基础知
中文版Access 2007实用教程 中文版Access 2007实用教程
第01章 数据库基础知识 01章
数据库技术和系统已经成为信息基础设施的核心技术和重要基础。数据库 技术作为数据管理的最有效的手段,极大的促进了计算机应用的发展。本章将 介绍数据库、数据库系统、数据管理系统、数据模型等基础理论知识,为后面 各章的学习打下基础。
中文版Access 2007实用教程 中文版Access 2007实用教程 教学重点与难点
数据库基本知识 数据库系统的组成与分类 数据库管理系统的概念和类型 常用的数据模型
中文版Access 2007实用教程 中文版Access 2007实用教程
1.1 数据库简介
数据库(Data Base)是计算机应用系统中的一种专门管理数据资源的系统。 数据库(Data Base)是计算机应用系统中的一种专门管理数据资源的系统。 数据有多种形式,如文字、数码、符号、图形、图像以及声音等。 数据库的概念 数据处理
中文版Access 2007实用教程 中文版Access 2007实用教程
1.1.1 数据库的概念 1.1.1
数据库就是数据的集合,例如,日常生活中,公司记录了每个员工的姓 名、地址、电话、学号等信息,这个员工记录就是一个简单的“数据库”( 名、地址、电话、学号等信息,这个员工记录就是一个简单的“数据库”(如 下图所示) 下图所示)。每个员工的姓名、员工编号、性别等信息就是这个数据库中的 “数据”,我们可以在这个“数据库”中添加新员工的信息,也可以由于某个 员工的离职或联系方式变动而删除或修改该数据。
中文版Access 2007实用教程 中文版Access 2007实用教程
1.1.2 数据处理 1.1.2
数据处理就是将数据转换为信息的过程,它包括对数据库中的数据进行 收集、存储、传播、检索、分类、加工或计算、打印和输出等操作,如向“员 工信息表”数据表中增加一条记录,或者从中查找某学生的出生日期等都是数 据处理。
中文版Access 2007实用教程 中文版Access 2007实用教程
1.2 数据库系统简介
数据库系统,从根本上说是计算机化的记录保持系统,它的目的是存储 和产生所需要的有用信息。这些有用的信息可以是使用该系统的个人或组织的 有意义的任何事情,是对某个人或组织辅助决策过程中不可少的事情。 数据库系统的概念 数据库系统的特点 数据库系统的分类
中文版Access 2007实用教程 中文版Access 2007实用教程
1.2.1 数据库系统的概念 1.2.1
狭义地讲,数据库系统是由数据库、数据库管理系统和用户构成。广义地 讲,数据库系统是指采用了数据库技术的计算机系统,它包括数据库、数据库 管理系统、操作系统、硬件、应用程序、数据库管理员及终端用户,如下图所 示。
用户
应用程序 数据库、数据库管理系统 操作系统 硬件
中文版Access 2007实用教程 中文版Access 2007实用教程
1.2.2 数据库系统的特点 1.2.2
面向文件的系统存在着严重的局限性,随着信息需求的不断扩大,克服 这些局限性就显得愈加迫切。下图是传统的文件管理系统的示意图。
学生数据 学籍数据 学籍管理应用程序 文 件 文 件 文 件
学生数据 学籍数据
文 成绩管理应用程序 件 文 财务管理应用程序 件
文 件 文 件
文 件 文 件
学生数据 学籍数据
中文版Access 2007实用教程 中文版Access 2007实用教程
与传统的文件管理系统相比,数据库系统具有以下优点: 数据结构化 数据存储灵活 数据共享性强 数据冗余度低 数据独立性高
中文版Access 2007实用教程 中文版Access 2007实用教程
1.2.3 数据库系统的分类 1.2.3
在信息高速发展的时代,数据信息同样是宝贵的资产,应该妥善地使用、 管理并加以保护。根据数据库存放位置的不同,数据库系统可以分为集中式数 据库和分布式数据库。 集中式数据库 分布式数据库
中文版Access 2007实用教程 中文版Access 2007实用教程
1.3 数据库系统管理
数据库管理系统(Database 数据库管理系统(Database Management System)是从图书馆的管理方法 System)是从图书馆的管理方法 改进而来的。人们将越来越多的资料存入计算机中,并通过一些编制好的计算 机程序对这些资料进行管理,这些程序后来就被称为“数据库管理系统”,它 们可以帮我们管理输入到计算机中的大量数据,就像图书馆的管理员。 数据库管理系统的概念 数据库管理系统的组成
中文版Access 2007实用教程 中文版Access 2007实用教程
1.3.1 数据库管理系统的概念 1.3.1
数据库管理系统由一个互相关联的数据的集合和一组访问这些数据的程序 组成,它负责对数据库的存储数据进行管理、维护和使用,因此,DBMS是一 组成,它负责对数据库的存储数据进行管理、维护和使用,因此,DBMS是一 种非常复杂的、综合性的、在数据库系统中对数据进行管理的大型系统软件, 它是数据库系统的核心组成部分。
中文版Access 2007实用教程 中文版Access 2007实用教程
1.3.2 数据库管理系统的组成 1.3.2
DBMS大多是由许多系统程序所组成的一个集合。每个程序都有各自的功 DBMS大多是由许多系统程序所组成的一个集合。每个程序都有各自的功 能,一个或几个程序一起协调完成DBMS的一件或几件工作任务。各种DBMS 能,一个或几个程序一起协调完成DBMS的一件或几件工作任务。各种DBMS 的组成因系统而异,一般来说,它由以下几个部分组成。 语言编译处理程序 系统运行控制程序 系统建立、维护程序 数据字
典
中文版Access 2007实用教程 中文版Access 2007实用教程
1.4 数据库设计的一般步骤
数据库设计是指对于一个给定的应用环境,构造最优的数据库模式,建立 数据库及其应用系统,使之能够有效地存储数据,满足各种用户的应用需求。 需求分析 逻辑设计结构 物理设计结构 数据库的实施 数据库的运行与维护
中文版Access 2007实用教程 中文版Access 2007实用教程
1.4.1 需求分析 1.4.1
整个数据库开发活动从对系统的需求分析开始。系统需求包括对数据的 需求和对应用功能的需求两方面内容。该阶段应与系统用户相互交流,了解他 们对数据的要求及已有的业务流程,并把这些信息用数据流图或文字等形式记 录下来,最终获得处理需求。
中文版Access 2007实用教程 中文版Access 2007实用教程
1.4.2 逻辑设计结构 1.4.2
由于逻辑设计与具体的数据库管理系统有关。以Microsoft 由于逻辑设计与具体的数据库管理系统有关。以Microsoft Office Access为 Access为 例,逻辑结构设计主要完成两个任务: 按照一定的原则将数据组织成一个或多个数据库,指明每个数据库中包 含哪几个表,并指出每个表包含的字段。 确定表间关系。通俗地说,就是设计一种逻辑结构,通过该逻辑结构能 够导出与用户需求一致的结果。如果不能达到用户的需求,就要反复修正或重 新设计。
中文版Access 2007实用教程 中文版Access 2007实用教程
1.4.3 物理设计结构 1.4.3
物理结构设计同样依赖于具体的数据库管理系统。对Access来说,物理 物理结构设计同样依赖于具体的数据库管理系统。对Access来说,物理 结构的设计过程通常包括以下步骤: 创建数据库 创建表 创建表之间的关系
中文版Access 2007实用教程 中文版Access 2007实用教程
1.4.4 数据库的实施 1.4.4
该阶段是建立数据库的实质性阶段,需要完成装入数据、完成编码、进行 测试等工作。完成以上工作后,即可投入试运行,即把数据库连同有关的应用 程序一起装入计算机,从而考察他们在各种应用中能否达到预定的功能和性能 要求。
中文版Access 2007实用教程 中文版Access 2007实用教程
1.4.5 数据库的运行与维护 1.4.5
完成了部署数据库系统,用户也开始使用系统,但这并不标志着数据库开 发周期的结束。要保持数据库持续稳定地运行,需要数据库管理员具备特殊的 技能,同时要付出更多的劳动。而且,由于数据库环境是动态的,随着时间的 推移,用户数量和数据库事务不断扩大,数据库系统必然增加。因此,数据库 管理员必须持续关注数据库管理,并在必要的时候对数据库进行升级。
中文版Access 2007实用教程 中文版Access 2007实用教程
1.5 关系
数据库
关系模型是用二维表格结构来表示实体与实体之间联系的数据模型。关系 模型的数据结构是一个二维表框架组成的集合,而每个二维表又可称为关系, 每个二维表都有一个名字。目前大多数数据库管理系统都是关系型的,如 Access就是一种关系型的数据库管理系统。在这一小节中,将为读者介绍关 Access就是一种关系型的数据库管理系统。在这一小节中,将为读者介绍关 系数据模型最基本的术语概念和常见的关系运算。 非规范化的关系 第一范式1NF 第一范式1NF 第二范式2NF 第二范式2NF 第三范式3NF 第三范式3NF
中文版Access 2007实用教程 中文版Access 2007实用教程
1.5.1 非规范化的关系 1.5.1
一般而言,关系数据库设计的目标是生成一组关系模式,使我们既不必 存储不必要的重复信息,又可以方便地获取信息。方法之一就是设计满足适当 范式的模式。在学习范式前,首先来了解非规范化的表格。 当一个关系中的所有字段都是不可分割的数据项时,称该关系是规范化 的。 当表格中含有多值数据项时,该表格同样为不规范化的表格 。
中文版Access 2007实用教程 中文版Access 2007实用教程
1.5.2 第一范式1NF 1.5.2 第一范式1NF
如果关系模式R的所有属性的值域中每个值都是不可再分解的值,则称R 如果关系模式R的所有属性的值域中每个值都是不可再分解的值,则称R 是属于第一范式(1NF)。第一范式的模式要求属性值不可再分成更小的部分, 是属于第一范式(1NF)。第一范式的模式要求属性值不可再分成更小的部分, 即属性项不能是属性组合或组属性组成。
中文版Access 2007实用教程 中文版Access 2007实用教程
1.5.3 第二范式2NF 1.5.3 第二范式2NF
满足第一范式并且关系模式R 满足第一范式并且关系模式R中的所有非主属性都完全依赖于任意一个候 选关键字,则称关系R 选关键字,则称关系R是属于第二范式。
中文版Access 2007实用教程 中文版Access 2007实用教程
1.5.4 第三范式3NF 1.5.4 第三范式3NF
如果关系模式R满足第一、第二范式,且R 如果关系模式R满足第一、第二范式,且R中的所有非主属性对任何候选 关键字都不存在传递信赖,则称关系R是属于第三范式的。3NF是一个可用的 关键字都不存在传递信赖,则称关系R是属于第三范式的。3NF是一个可用的 关系模式应满足的最低范式,也就是说,如果一个关系不服从3NF,这个关系 关系模式应满足的最低范式,也就是说,如果一个关系不服从3NF,这个关系 其实是不能使用的。
四 : SQL数据库基础知识集合
1、 技术标签:(数据库 使用实例)
2、 技术细节:(数据库 的具体使用环境 MSSQL、mySQL、Oracle)
1、数据库简介:
数据库是专门开发数据管理的软件,或者说专门管理数据的软件就是数据库。
数据库存在的意义就是:减轻开发人员的负担。数据库是一个综合的软件,那么我们不需要队要进行2进制保存数据进行处理了,但是却是要与数据库产生交互,那么命令式SQL,有技巧的 ,数据库就是万物皆关系(面向对象,万物皆是对象)有所区别。
2、数据库的发展:
一开始的是层次化的数据与网状数据库 ,后来也发现使用确实很麻烦。
于是到了1970年EF.Cold博士(IBM公司的研究员)开创了关系性的数据库的先驱,发表了关系性数据库的论文 ,但是由于当时电脑硬件的局限性,大家觉得跑如此大的程序不值得。后来,Oracle(甲骨文)公司的创始人,拉里带领Oracle投入到关系型数据库的研发,并且得到了一个大客户 —美国国防部。随即开始世界刮起了关系数据库的旋风,随后各个公司都纷纷推出自己的数据库系统。比如:IBM的DB2 ,还有风靡一时的DBS3。
但是随即出现不兼容的问题,由于最早的时候都没有进行没规范。所以到最后各个数据库巨头统一了操纵数据库的SQL(结构化Struct数据查询语言) 变成了标准语言,而关系型数据库也俨然变成大家的宠儿,Oracle也从一个小公司,变成现在的数据库巨头,而我们的微软也推出了SQLServer。当然还有PHPer的最爱mySQL。但是mySQL被SUN,SUN被Oracle收购,现在有免费版与收费专业版了。所以我们学习SQL语言的时候,先学共同点,再学特异性。各种数据库软件在使用上有一点区别。
3、数据库系统详解:
为适应数据处理的需要而发展起来的一种较为理想的数据处理的核心机构。计算机的高速处理能力和大容量存储器提供了实现数据管理自动化的条件。
数据库系统一般由4个部分组成:
数据库,即存储在磁带、磁盘、光盘或其他外存介质上、按一定结构组织在一起的相关数据的集合。(个体)
数据库管理系统(DBMS)。一组能完成描述、管理、维护子数据库的程序系统。它按照一种公用的和可控制的方法完成插入新数据、修改和检索原有数据的操作。
数据库管理员(DBA)。
用户和应用程序。(微软的称作SSMS)
4、数据库系统的基本要求是:
1、能够保证数据的独立性。数据和程序相互独立有利于加快软件开发速度,节省开发费用。
2、冗余数据少,数据共享程度高。
3、系统的用户接口简单,用户容易掌握,使用方便。
4、能够确保系统运行可靠,出现故障时能迅速排除,能够保护数据不受非受权者访问或破坏,能够防止错误数据的产生,一旦产生也能及时发现。
5、有重新组织数据的能力,能改变数据的存储结构或数据存储位置,以适应用户操作特性的变化,改善由于频繁插入、删除操作造成的数据组织零乱和时空性能变坏的状况。
6、具有可修改性和可扩充性、可维护性。
7、能够充分描述数据间的内在联系。
5、数据库(Database):
由众多的数据、数据表、约束、存储过程、函数、视图、索引构成的一个数据存储与交互单元,是按照数据结构来组织、存储和管理数据的仓库。
6、数据表(table):
数据表,实际上是一个二维表。一般是围绕一个事务、动作记录,或者是一个信息主题作为一个数据表。数据表由行与列构成。
7、列(column、field):
列,其实就是字段。也是决定了信息的基本单元。列,包含有数据类型的设定。
8、行(row、record):
行,实际上就是一条基本信息。一行包含了多列数据的存储的信息。所以一行也有一条记录之称。
9、行业(trade)
一个行业一种需求,没一个需求每一种数据库的设计模式与思想。每个行业的数据设计的重点都是不同的。侧重查询(要求低范式)还是操作(要求搞范式)就是自己选择的问题了。
10、索引(index)
索引是一个单独的、物理的数据库结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引其实就是一个B+树,但是这个索引是N^n层数次方的。目的就是在数据库中划分出一定的区域优化查询。可以提升大量数据的查询速度。索引一般可以分为:基于字段优化查询速度的普通索引、唯一性索引、主键索引、全文索引、单列与多列索引。现在由于数据库系统的不断升级,我们只要设定索引就可以了,不需要特殊的维护。而且数据在查询的时候也会根据查询适当地选择是利用索引查询,还是仅仅是表查询。由于数据库系统的发展,系统内部已经自动帮我们完成对索引的维护。但是在设计的时候要考虑到索引的损耗问题。数据库DB就像是一个字典,索引就是根据指定字段制成的快速指向。由于只是指向数据对象标识,真正的数据是存储在DB中,所以查询速度极快。但是额外的内存与硬盘花销也是一个需要考虑的问题。比如:增加、删除、修改时数据库都要对索引进行维护,但是这样也是为了最后查询的效率的提升,特别适合W行级别的数据查询。而索引可以分为:隐式索引(针对单个字段)、唯一索引(唯一约束)、函数索引(函数(字段))、聚簇索引(主键)、组合索引(最多16个field)与全文索引(text)。一般索引会占用原数据库大小的20%。
11、视图(view)
固化的子查询,将一个子查询起了一个固化的名字,保存在数据库中,方便以后的使用。其实调用大量的Join来进行一个查询一般也是用视图。视图与索引都是为了优化查询的速度与语句。视图是优化语句,索引是优化单查速度。一般是DBA来设定数据库的视图, 封装内部数据库的数据关系,范式修改数据容易了,视图让我们查询复杂关系的数据变得容易。
12、触发器(trigger)
触发器(trigger)是个特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由个事件来触发,比如当对一个表进行操作( insert,delete, update)时就会激活它
执行。触发器经常用于加强数据的完整性约束和业务规则等。 触发器可以从 DBA_TRIGGERS ,USER_TRIGGERS 数据字典中查到。
13、SQLServer数据类型详解


14、命名规范:


15null也是一个集合,但是仅仅表示的是一个空集,但是实际上是null=Unknow。 1、 数值运算null为null; 2、 逻辑判定null为null; 3、 主外键联接null为忽略;
4、 语句连结null为or或真、and和假。 具体可查三值逻辑的真值表。
5、特殊情况:
<1>where null = null,where column = value:表中column为NULL的行永远不会返回,即使value是NULL,直接断言; <2>case null when null then XXX:XXX永远不会执行,即使value是NULL,直接断言;
<3>unknow判断,if <unknow> {XXX} else {YYY} end或case when <Unknown> then XXX else YYY end:这两种情况下,<unknow>,即是null会执行。 <4>唯一约束(unique index)的字段只允许一个null的行,再插入或更新该字段为NULL的行会报字段重复的错误。 <5>group by时,所有null被视为一组。
<6>order by时,所有null排在一起,但null排在最前面.(如SQL Server),或者是最后面(如Oracle),SQL标准未规定。 <7>聚集函数(sum/avg/max/min/count)忽略null的行,即是不返回此行数据,直接断言 <8> declare时,在未赋值之前为null。 <9>与NULL处理相关的运算符和函数:
- is null/is not null:用这两个运算符来判断一个值是否为NULL,而不是=或<>; - is null/ coalesce:取第一个非空值(注意两个函数的数据类型转换规则不同); - nullif(a,b):等价于如果a等于b返回null,如果不等于返回b - isnull(a,b):取两者中不为null的值,都为null返回null。
16、Not Null的建表
由于三值关系的存在,很多开发人员在建表的时候,除非是非null不可,基本都是允许为null的,其结果往往是一张表除了主键以外所有的字段都可以为Null。之所以会有这样的思路,是因为Null好啊,程序不容易出错啊,你插入记录的时候如果不小心忘输了一个字段,程序依然可以R运行un,而不会出现 “XX字段不能为Null”的错误消息。
但是,这样做的结果却是很严重的,也会使你的程序变得更加繁琐,你不得不进行一些无谓的空值处理,以避免程序出错。更糟的是,如果一些重要数据,比如说订单的某一项值为Null了,那么大家知道,任何值与Null相操作(比如加减乘除),结果都是Null,导致的结果就是订单的总金额也为Null。 你可以运行下面的代码尝试一下:
Select Null + 5 As Result
但是我们如何解决输入为空的问题呢?我们为什么不使用我们强悍的工具—check约束与默认值呢?
Field Varchar(500) default ‘nothing’ Not Null Constraint ck_ColumnName Check(Len(ColumnName)>0), [Type] TinyInt Not Null Default 0 Constraint ck_ArticleType Check([Type] in (0,1,2)),
所以,合理的思维方式应该是这样的:默认这个字段是 Not Null的,然后判断这个字段是不是非Null不可,如果不是这样,OK,这个字段是Not Null的,进行下一个字段。
17、数据库的原子性
1、你的表是描述什么事物,明确表的信息对象主体 2、你的表是为了适合什么操作语句的设计的,面向操作设计
3、列的内容要不要原子性的切块,让查询直逼要害,列的设计的小块的程度要拿捏好
4、表必须是二维表,而且要根据不同的需求进行设计,表的设计与列的设计一样都要依赖与操作与需求
原子性的存在是为了切分适合的信息块 ,从而达到信息的最大化、最优化的使用,并不是无限切分就好,要看实际的应用。但是由于原子性数据的表容易设计,而且运行的所需时间较短(查询信息的指向性比较强,同时也便于维护喝更新操作,但是却是在海量数据搜索面前有点乏力),所以对大量的数据处理的时候要加分效果。 1、 同一列中不能存在多个类型相同的值,一列不能多值(除非是) 2、 同一个表中也不能存在有多个存储相同类型数据的列
3、 无重复的行,每列只存储一份同类型下的一份数据(列是单值的),无重复列名 4、
18、结合信息对象与业务设计数据库设计
1、数据库的设计师根据信息要素、关系来设计的; 2、数据库的信息查找依赖于信息的使用方式的; 3、对于可有可无的东西,我们需要花点时间去好好斟酌; 4、简短的查询,比囧长的业务查询更加需要思考;
5、使用数据的方式将会与我们占用系统内存与硬盘息息相关,影响着服务器的整体表现,所以我们的设计会有所倚重与侧重; 现在基本是双数据库,外层是方便查询,内层是方便修改。
SQL换一句话其实就是关系数据库管理系统 Realtional Database Management System ,RDBMS 表的设计的方法:
1、挑出事物对象(对象信息浓缩法)
2、围绕事物对象的信息收集(信息扩散聚拢法)
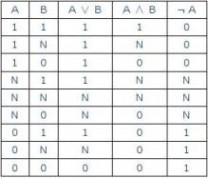
3、信息拆分成块(字段原子性)
4、事务需求拆分法(关系设计)
5、数据的发散与聚合程度的分析(表设计的检验)
19、范式 1NF 2NF 3NF 4NF
1NF,主要是解决表中字段设计、信息与业务之间的关系的问题
1、 数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。在第一范式(1NF)中表的每一行只包含一个
实例的信息。简而言之,第一范式就是无重复的列,而且单列无重复的值。
2、 所有属性都必须是原子的——每个属性一个值。一个实体的所有实例都必须包含同等数量的值。一个实体的所有实例必须两两不相同。
2NF,主要是设定主键,解决数据库的数据冗余、更新、插入、更新的指向性的问题
1、 要求数据库表中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。这个唯一属性列被称为主关键字或主键、主码、唯一
关联。引入主键约束primary key,Constraint pk_Article Primary Key(Id)。主键的设定也是有要求的。主键默认不能为空,保持唯一性。插入、更新删、除记录的时候必须指定主键的值。要求主键必须简洁,主键值不能被修改。
2、 实体必须满足第一范式。所有属性描述的事实都必须与整个键相关,而不能只描述键的一个子集。
3NF,主要是解决排除部分列之间的依赖关系,利用了表与表的主外键关系解决。
1、 要求实体数据记录(record)相对于外部完全依赖于主关键ID。所谓完全依赖,是指在除主键外其他的属性列之间不存在对应依赖。如果存在,那么这一依赖部分应该分离出来形
成一个表(关联),一般抽离出这一部分的主依赖项的ID,把这一部分作为一个新的表记录,同时原表也存储此次依赖项ID,然后利用建立主外键关系,将一表分成两表,解决原表因为主次依赖项存在而造成的数据冗余等一系列问题(但是对于以查询操作为主、记录大量数据的表此范式就需要斟酌了)。第二范式就是建立主键,与排除其他列对其属性列的依赖(消除部分列的依赖)。
2、 实体必须满足第二范式。如果每个非键属性描述的事实都与一个键属性相关,则实体满足第三范式所有属性描述的都必须是关于键的事实,除此之外别无其他。
4NF,主要是解决根据属性列的相似(不同的从属对象)与共同(相同的从属对象)信息的建表问题,即是表中所有列对外的一对多关系不受限制
1、 因为比较抽象,即是A表中含有a1,a2两个属性列,B表中记录a1的信息(包含b1),C表中包含a2的信息(包含c1),但是b1,c1实际上是相同类型的信息,但是从对象
不同。此处就是要我们明确建表的时候,要仔细区分共有与相似(决定建表)的关系,从属对象与属性列之间关系与一对多关系的搭设与否的问题。
2、 在实体中,不会出现多于一个的多值依赖。
5NF,主要是解决将信息切割得更细,清除所有冗余,但是在4NF设计会出现联接不当而产生的错误record
1、在4NF下,一般我们仅仅是区分了属性列的相似与共有信息,但是这个时候就会因为新建的b、c而产生误解数据或者是错误记录。因此可以从第五范式(实际上是所有范式)中得到的启示是,当你觉得可以将表分解为带着不同自然键的更多、更小的表时,这么干很可能就是最好的方式。如果你想要把各个部分联结到一起,表示最初的、分解得更少的数据形式,数据库干这事比你干得强多了。很明显,如果你不能通过联结来重新构建分解前的表,那就最好不要进行分解。即是有一个道理,更少得冗余,更多的错误。唯有靠联接来解决了。或者采用树状分层设计法,同层合并,也可以单独建立一个事务记录表。
2、当分解是信息无损的时候,所有关系都被分解成了二元关系。
但是面对日益变态的信息几何级的增长,为了令到数据库从焦油坑变成金矿我们会加入数据挖掘的思想,但是这个时候就需要无损的信息与高度分块的。所以在物理建表之前,我们还是需要遵循规范化建表的原则。
20、规范化建表
让数据具有原子性是设计出规范化数据表的第一步(同时也是为了提高数据库的可读性),但是到后期你可能会因为数据量以及性能的问题打破这种规范化。因为你的数据库投入使用后数据库的大小日益增大,设计规范化的表可以时刻保持你应对以后各种复杂的组合查询 (主要是应对数据库过分膨胀后的,查询缓慢的问题)
规范化建表的优点:
1、可以减少表中重复数据的存储,减少数据库的大小;
2、因为数据库的切割使得你的查询的指向性更强,查找的数据少,查找得更加快速;
3、但是最后归根到底还是 避免存储重复的数据节省我们的硬盘空间。
21、不规范化建表
规范化主要用来改善性能,过度规范化的结构会造成查询处理器和SQL Server中其他进程的开销过大(不适用在查询表的设计),或者,有时需要降低复杂性来使得实现更容易些,非规范化在这些时候就会发挥作用。正如我在这章中一直试图阐明的那样,虽然人们大都认为非规范化到第三范式就可以了(靠着减少所需联结的数量,查询过程已经被简化了)然而,这样做冒着引入数据异常的风险。每个使用数据库的应用程序都要复制任何额外写的,用来处理这些异常代码,因此就增加了人为错误的可能性。在这种情况下必须作出的判断是:是一个稍微慢点(但是100%正确)的应用更好呢,还是一个更快但正确性稍差的应用更好些。
在逻辑建模阶段,绝不应该从我们规范化的结构倒退,对应用程序过早过激地进行性能调优工作。OLTP数据库结构上,所以设计中最重要的部分就是:保证我们的逻辑模型体现了最终的数据库含有的所有实体和属性。一旦开始物理建模过程(这与性能调优应该是同义语),那就有足够充足的理由来对结构进行非规范化操作,要么是出于性能的考虑,要么是出于减少复杂性的考虑,但是,这两种考虑都不适合用在逻辑模型上。当我们物理上的实现在逻辑上也正确的时候,碰到的问题几乎总是会更少些。对几乎所有情况来说,我都建议等到物理建模阶段才对解决方案进行实现,或者,至少等到有某种非做不可的原因时(比如,系统中某些部分失败了)才进行非规范化工作。
总结:一般,我们是采用两层数据库的,一层是外层,用于直接的查询。一层是内层数据库,用于记录与维护更新的。维护更新资料的时候,对内层数据库进行操作,当操作完成的时候就会马上更新外层数据库。所以外层数据库(以查询为主)设计的范式要求比较低,但是内层数据库(维护更新为主)的要求就比较高了。
22、数据库设计建议:
数据库不仅是用来保存数据,还应负责维护数据的完整性和一致性
我看过很多的开发人员设计出来的数据库,给我的感觉就是:在他们眼里,数据库的作用就如同它的名称一样――不仅仅是用来存放数据的,除了不得不建的主键以外,什么都没有...没有 Check约束,没有索引,没有外键约束,没有视图,甚至没有存储过程。 一个很好的数据库该有的还是有的。什么都没有的数据库插入操作是很好,但是多了这点东西的数据库还是很快的。
如果要写代码来确保表中的行都是唯一的,就为表添加一个主键,即是distinct的使用频率应该是比价少的。
如果要写代码来确保表中的一个单独的列是唯一的,就为表添加一个约束,一般是事务状态记录表。
如果要写代码确定表中的列的取值只能属于某个范围,就添加一个Check约束。
如果要写代码来连接 父-子 表,就创建一个关系,上下其实都是依据主外键的。
如果要写代码来维护“一旦父表中的一行发生变化,连带变更子表中的相关行”,就启用级联删除和更新。
如果要调用大量的Join来进行一个查询,就创建一个视图。
如果要逐条的写数据库操作的语句来完成一个业务规则,就使用存储过程。
没有提到触发器,实践证明触发器会使数据库迅速变得过于复杂,更重要的是触发器难以调试,如果不小心建了个连环触发器,就更让人头疼了,所以我更倾向于根本就不使用触发器trigger。
3、技术实例:(数据库)
1、 加载数据库脚本
source C:\Users\Administrator\Desktop\script-1.sql ;——mySQL
source (\.) Execute an SQL script file. Takes a file name as an argument.
2、 保存为数据库脚本
Tee C:\Users\Administrator\Desktop\script-1.sql ;
tee (\T) Set outfile [to_outfile]. Append everything into given outfile.
notee 输入的时候就会把tee与notee进行保存为sql脚本。
3、 查询当前实例的数据库集合
Show databases ; ——mySQL
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| drinks |
| mysql |
| performance_schema |
| test |
+--------------------+
4、使用某个数据库
mysql> use drinks;
Database changed
5、查询当前数据库的表集
mysql> show tables;
+------------------+
| Tables_in_drinks |
+------------------+
| easy_drinks |
| my_contacts |
+------------------+
6、查询表的结构
mysql> desc my_contacts;
+------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+--------------+------+-----+---------+-------+
7、判断存在
方法1:精确方法
Sysobjects是Master系统视图
object_id是抓取对象在视图中的ID
OBJECTPROPERTY是根据对象判断类型函数,返回的是bool
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[tb]') and OBJECTPROPERTY(id, N'IsUserTable') = 1) drop table [dbo].[tb];
方法2:模糊方法
declare @a varchar(2000) ——MSSQL 删除约束
set @a=(select name from sysobjects where name like 'Name')
set @a= 'ALTER TABLE [dbo].[TableName] DROP CONSTRAINT '+@a
exec (@a)
8、数据库的新建、删、改
<1>新建数据库
mysql> create database myDB; ——mySQL
Query OK, 1 row affected (0.00 sec)
create database mmc; ——MSSQL
<2>数据库修改
exec sp_rename 'a1.name ', 'Name ', 'database' ——MSSQL
<3>删除数据库
mysql> drop database drinks;——mySQL
Query OK, 2 rows affected (0.34 sec)
drop database mySQL;——MSSQL
9、数据表的新建、删、改
<1>新建数据表
mysql> show create table servers;——mySQL显示表的创建方式
| servers | CREATE TABLE `servers` (
`Server_name` char(64) NOT NULL DEFAULT '',
`Host` char(64) NOT NULL DEFAULT '', `Db` char(64) NOT NULL DEFAULT '',
`Username` char(64) NOT NULL DEFAULT '',
`Password` char(64) NOT NULL DEFAULT '',
`Port` int(4) NOT NULL DEFAULT '0',
`Socket` char(64) NOT NULL DEFAULT '',
`Wrapper` char(64) NOT NULL DEFAULT '',
`Owner` char(64) NOT NULL DEFAULT '',
PRIMARY KEY (`Server_name`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='MySQL Foreign Servers table' |
mysql> create table my_contacts( ——mySQL
-> ID int not null Auto_increment,
-> last_name varchar(20) not null,
-> first_name varchar(20) not null,
-> email varchar(50) not null,
-> birthday date,
-> profession varchar(50),
-> location varchar(50),
-> status varchar(20),
-> interests varchar(20),
-> seeking varchar(100) ,
Parmary key (名 ) );
Create Table Article ——MSSQL
(
Id Int Identity(1,1) Not Null,——自增
Varchar(50)
Varchar(50) Not Null Constraint uq_ArticleTitle Unique,——1、唯一约束 Not Null Constraint ck_KeywordsLength Check (len(Keywords)<10),——2、检查约束
Not Null, ——3、非空约束
Not Null,
Not Null Default 0 Constraint ck_ArticleType Check([Type] in (0,1,2)),
Not Null Default 1, ——默认值
Not Null,
Null,
Not Null Default 'TraceFact',
Null,
Not Null Default GetDate(),
Not Null Default 0,
Not Null , Title Keywords Abstract Author [Type] Varchar(500) Varchar(50) TinyInt IsOnIndex Bit Content Text [Source] SrcUrl PostDate ClassId SourceCode Varchar(100) Varchar(50) DateTime Int Varchar(150) ViewCount Int
Constraint pk_Article Primary Key(Id), —— 4、主键约束
Constraint fk_Article foreign key(scoreId) references student(id)——5、外键约束,为主表student建立外键关系 )
<2>修改数据表
mysql> alter table 旧表名 rename to 新表名; ——mySQL
use databasename;
EXEC sp_rename '旧表名', '新表名';——MSSQL
<3>删除数据表
mysql> drop table mytables;——mySQL
drop table a1;——MSSQL
10、字段、约束(数据表成员)的增加、删、改
<1>增加字段
mysql> alter table mytable——mySQL 添加字段
-> add column mycolumn2 int first , 其中还有 after column 排在指定的列之后
-> add primary key (mycolumn2); ——mySQL 添加主键
alter table test1 add nob int identity(1,1) not null ——MSSQL 添加字段
alter table test1 add primary key (nob); ——MSSQL 添加主键
alter table [dbo].[Article2] add default ((1)) for [IsOnIndex] ——MSSQL添加默认约束
alter table [dbo].[Article2] with check add constraint [ck_KeywordsLength2] check ((len([Keywords])<(10))) ——新建check
alter table [dbo].[Article2] check constraint [ck_KeywordsLength2] ——MSSQL把ck_KeywordsLength2添加check约束集合
alter table [dbo].[Article2] with check add constraint [ck_ArticleType2] check (([Type]=(2) OR [Type]=(1) OR [Type]=(0)))
<2>修改字段
mysql> alter table mytables
-> add primary key ( lastname );
mysql> alter table mytable——mySQL 不改变名字,改类型
-> modify mycolumn2 varchar(20); -> change column firstname firstName varchar(30) ,——mySQL 改变名字、类型
exec sp_rename 'a1.name ', 'Name ', 'column ' ——MSSQL 只改变名字
alter table test1 alter column ID varchar(200) null ——MSSQL 不改变名字,改类型
alter table test1 drop Constraint constraintname; ——MSSQL 删除约束
alter table test1 add primary key (nob); ——MSSQL 添加主键约束
alter table Articles2 add constraint fk_job_id foreign key (Id) references Article3(Id); ——MSSQL添加外键约束
alter table dbo.Article2 add constraint uk_Id unique nonclustered (Id); ——MSSQL添加唯一约束
alter table [dbo].[Article2] add constraint uk_Id default ((1)) for [IsOnIndex] ——MSSQL添加默认约束
alter table [dbo].[Article2] with check add constraint [ck_KeywordsLength2] CHECK ((len([Keywords])<(10))) ——新建check
alter table [dbo].[Article2] chenk constraint [ck_KeywordsLength2] ——MSSQL把ck_KeywordsLength2添加check约束集合
alter table [dbo].[Article2] with check add constraint [ck_ArticleType2] check (([Type]=(2) OR [Type]=(1) OR [Type]=(0))) alter table [dbo].[Article2] with check add constraint [ck_KeywordsLength2] check ((len([Keywords])<(10))) ——新建check
alter table [dbo].[Article2] check constraint [ck_KeywordsLength2] ——MSSQL把ck_KeywordsLength2添加check约束集合
备注:最后一栏column/database/index/object等等,还有约束的修改只能是先删除再新建。
还能够建立联合主键,就使用利用两个字段来确定一条数据,一般这样的数据不会进行修改。

<3>删除字段
mysql> alter table mytable ——mySQL
-> drop column mycolumn2;
alter table test1 drop column nob; ——MSSQL 删除字段
alter table test1 drop Constraint constraintname; ——MSSQL 删除约束
11、连接词 and、or 、not
<1>and:A and B,即是A与B 要同时成立。 <2>or:A或者B,只要其中一个成立就成立 <3>not:not A and B,当A不成立而且B成立;A and not B,当A成立而且B不成立; not (A and B),当A与B都不成立 1、<:小于 2、>:大于 3、<=:小于或者等于
4、>=:大于或者等于
5、<>:不等于;=等于
6、is null 或者是 not null
7、<?D?: field的第一个字母早于D;>?A?:field的第一个字母要晚于A
13、匹配关键字LIKE、通配符“%”与占位符 “_”与区间关键字“between”与集合关键字“in“
①:where field Like ‘%CA%’,filed字段里面包含CA字符的所有结果;
②:where field Like ‘CA%’,field字段前面是CA字符的结果;
③:where field Like ‘%CA’,field字段后面是CA字符的结果;
③:where field Like ‘_CA%’,field字段前面第二第三个是CA的结果;
④:where field between 20 and 30 在20与30之间 或者 between ?A? and ?Z? 在A与Z之间。
⑤:where field in (1,2,3) filed(类型相同)是1,2,3中的其中一个 或者 where field in (‘1’,‘2’,‘3’)field在‘1’、‘2’、‘3’中的其中之一,即是filed的类型要
与in里面的类型相同。
14、SQL语句select、insert、delete、update
①:select field from table
②:insert into table (fields) values (values)
③:delete from table where field 条件
④:update table set field = value where field 条件,例子:update table set table.column2= Right(table,2)
⑤:SQL语句是可以结合运算的。Update set const=const=1; 12、符号 <、>、=、<=、=>、<>、null
15、SQL字符串处理函数
①:Right (column,2) 从右边开始截取2位的字符
②:Substring _index( column,“,”,2) 截取第二个逗号(字符)前的字符串
③:Substring (column,numberA,numberB) 截取列中,从A位开始读取后面B位的字符串
④:Upper(column) 转换大写、
⑤:Lower (column) 转换小写
⑥:Reverse(column) 反转字符串的顺序
⑦:Ltim( colum ) 左去除空
⑧:Rtrim( column) 右去除空
⑨:Length (column) 获取字符长度,返回一个int,但是在MSSQL len(Keywords)<10
16、数据表约束Constraint(唯一、非空、检查、主键、外键)
<1>唯一约束:Constraint uq_ArticleTitle Unique,——唯一约束
alter table dbo.Article2 add constraint uk_Id unique nonclustered (Id); ——MSSQL添加唯一约束 唯一约束即是指定的列的值在此列中只出现一次,null也是不能出现第二次的。 <2>非空约束:Content Text Not Null, alter table student add constraint codenn check(code is not null);
非空约束指定列不能为空。
<3>检查约束:Constraint ck_ArticleType Check([Type] in (0,1,2)), alter table [dbo].[Article2] with check add constraint [ck_KeywordsLength2] check ((len([Keywords])<(10))) check约束是功能最强大的约束,其中可以写很多逻辑条件进去。 <4>主键约束:Constraint pk_Article Primary Key(Id), —— 4、主键约束 alter table test1 add primary key (nob); ——MSSQL 添加主键约束 主键约束是指此列为唯一标识,一般配合identity(1,1)使用。 <5>外键约束:Constraint fk_Article foreign key(scoreId) references student(id)——5、外键约束,为主表student建立外键关系 alter table Articles2 add constraint fk_job_id foreign key (Id) references Article3(Id); ——MSSQL添加外键约束 B表中使用外键约束字段ID,那么确保B表中的输入的ID的值与A表中ID的值匹配。A表ID为主键,B表ID为外键,B的ID依赖与A的ID的存在。
17、case when then语句
<1>一般使用:
select case column when value1 then operate1 end when value2 then operate2 end else operate3 end from table 返回的operate的值
<2>结合连接词 :
select ('Disk'+Ltrim(Rtrim(Convert(char,a.Disk_ID)))+'Movie'+Rtrim(Ltrim(Convert(char,b.Movie_ID)))) as 编号, b.Movie_Name as 影片名称,a.RentCount as 租借次数, (case a.States when 0 then '没租' when 1 then '已租出'
when 2 then '已预定' when 3 then '损毁' end ) as 状态 from (tbl_MovieDisk a inner join tbl_Movies b
on a.Movie_ID=b.Movie_ID) left join tbl_MovieTypes e on b.Type_ID=e.Type_ID;
<3>结合组函数转置:
select [sid],
sum ([mark]) as 总分,
avg ([mark]) as 平均分,
avg ( case when [cid]=1 then [mark] end) as [database],
avg (case when [cid]=2 then [mark] end) as [C#],
avg (case when [cid]= 3 then [mark] end) as [xml]
from tbl_marks
group by [sid] –-对查询结果字段中没有聚合函数的字段进行分组修饰
18、排序关键字 order by column(顺序) 与 order by column desc(倒序)MSSQL的功能都不是单一、独立的,所以必须对结果集合进行收缩
create table #tmp1
(
name nvarchar(20),
name2 nvarchar(20)
)
select * from #tmp1;
insert into #tmp1 (name) values ('A');
insert into #tmp1 (name,name2) values (1,1);
insert into #tmp1 (name,name2) values ('a',1);
insert into #tmp1 (name,name2) values (1,'b');
insert into #tmp1 (name,name2) values (1,'?');
insert into #tmp1 (name,name2) values (1,'B');
insert into #tmp1 (name,name2) values (1,'A');
select name2 from #tmp1 order by name2;
①:对于数字1到9,顺序是1-9,由小到大;而倒序是9-1;
②:对于数字1到9,而且夹杂a-z与A-Z,顺序是aABbcCDd 小大大小模式;
③:对于字母a到z,顺序是a-z;而倒序是z-a;
④:对于字母a到z,即是夹杂a-z与A-Z,没有排序的时候:aABbcCDd 小大大小模式;
⑤:其实是MSSQL对大小写都是同等对待。select tmpChar from #tmp1 group by tmpChar,只出现一组的a-g,而且是不区分大小写的,导致了。
⑥:order by的多组合,先执行列1再在列1的区域里面再进行列2的排序select tmpChar from #tmp1 order by tmpChar desc倒序,tmpNum asc顺序; ⑦:对于符号的排序的问题,我们有时候要对nvarchar类型的字段进行排序,里面有很多特殊的字符,那么顺序是:!“&‘(*+=@
⑧:一般规律是:顺序上到下 ,null 非字母字符 数字 大写字母 小写字母 非字母字符
19、分组关键字 group by
create table #tmp2
(
[Count] int,
name2 nvarchar(20)
)
select * from #tmp2;
insert into #tmp2 ([Count],name2) values (1,1)
insert into #tmp2 ([Count],name2) values (2,1)
insert into #tmp2 ([Count],name2) values (3,2)
insert into #tmp2 ([Count],name2) values (4,2)
insert into #tmp2 ([Count],name2) values (5,3)
select name2 from #tmp2 group by name2;OK
select [Count],name2 from #tmp2 group by name2;wrong
select [Count],name2 from #tmp2 group by name2,[Count]; OK
select SUM([Count]) as 汇总 ,name2 from #tmp2 group by name2; OK
①:指定的列进行分组,返回的结果集合要是包含其他的列(没有组函数运算),那么需要把其他的列依次加入到分组集合中。
20、聚合SUM()、AVG()、COUNT()、MAX()、MIN()
①:SUM(),汇总聚合函数
②:AVG(),平均聚合函数; ③:COUNT(),计数聚合函数; ④:MAX(),求最大值聚合函数; ⑤:MIN(),求最小值聚合函数。
备注:使用聚合函数在查询范围后一定要使用group by 对聚合函数以外的列进行分组。而且所有的对象是除字符类型的所有数值类型。 ②:在结果集合里面,除分组集合中的列外,其他列必须有组函数修饰。
21、子查询、范围匹配关键字in与聚合函数后的查询子句Having
①:子查询是指当一个查询是令一个查询的条件的时候。即是:查询出来的结果是另外一个查询的搜索域或者条件。
①-1:
搜索域(双重嵌套)
select ss.studentid, ts.[name], ss.totalmark from
(
条件(返回的集合区间) select Name
from AdventureWorks.Production.Product
where ListPrice =
( select ListPrice
from AdventureWorks.Production.Product
where Name = 'Chainring Bolts' )
①-2:集合in、having、exists
②:in是确定指定的值是否与子查询或列表区域中的值相匹配。返回一个bool
区间条件:· select s.studentid, sum( mark ) as TotalMark from ( tbl_students s inner join tbl_marks m on s.studentId = m.sid ) inner join tbl_courses c on m.cid = c.courseId inner join tbl_students ts on ss.studentid = ts.studentid group by s.studentId ) ss
select FirstName, LastName, e.Title
from HumanResources.Employee as e
JOIN Person.Contact as c on e.ContactID = c.ContactID
where e.Title in ('Design Engineer', 'Tool Designer', 'Marketing Assistant');
GO
Check约束:Constraint ck_ArticleType Check([Type] in (0,1,2)), –-check约束中的使用
③:Having是指定组或聚合的搜索条件,相当于group by后的where。
Having 只能与 select 语句一起使用。Having 通常在 group by 子句中使用。如果不使用 group by 子句,则 Having 的行为与 where 子句一样。在 Having 子句中不能使用 text、image 和 ntext 数据类型
select SalesOrderID, sum(LineTotal) as SubTotal –-此处有聚合函数
from Sales.SalesOrderDetail
group by SalesOrderID
Having sum(LineTotal) > 100000.00 –Having不能使用text、image、ntext,Having使用的时候必须跟在分组之后。 order by SalesOrderID ;
22、内连接inner join table on ,外连接 right join table on 、 Left join table on与全连接 full join table on
现在有table A 与 table B。A、B表有主外键关于 ID主外键关系。A表是主表,B表是子表。A是影片表,B是影碟表,ID是MovieID。 Create table #tmpMovie
(
MovieID int ,
MovieName nvarchar(30)
)
select * from #tmpMovie; --6条数据,2条没用
insert into #tmpMovie (MovieID,MovieName)values (1,'影片');
insert into #tmpMovie (MovieID,MovieName)values (2,'影片');
insert into #tmpMovie (MovieID,MovieName)values (3,'影片');
insert into #tmpMovie (MovieID,MovieName)values (4,'影片');
insert into #tmpMovie (MovieID,MovieName)values (5,'影片');--多余的
insert into #tmpMovie (MovieID,MovieName)values (6,'影片');--多余的
create table #tmpDisk
(
DiscID int,
DiscName nvarchar(30),
MovieID int
)
select * from #tmpDisk; --10条数据,4条没用
insert into #tmpDisk (DiscID,DiscName,MovieID) values (1,'影碟',1);
insert into #tmpDisk (DiscID,DiscName,MovieID) values (2,'影碟',1);
insert into #tmpDisk (DiscID,DiscName,MovieID) values (3,'影碟',2);
insert into #tmpDisk (DiscID,DiscName,MovieID) values (4,'影碟',2);
insert into #tmpDisk (DiscID,DiscName,MovieID) values (5,'影碟',3);
insert into #tmpDisk (DiscID,DiscName) values (6,'影碟');--为空
insert into #tmpDisk (DiscID,DiscName,MovieID) values (7,'影碟',4);
insert into #tmpDisk (DiscID,DiscName) values (8,'影碟');--为空
insert into #tmpDisk (DiscID,DiscName,MovieID) values (9,'影碟',7); --影片不存在
insert into #tmpDisk (DiscID,DiscName,MovieID) values (10,'影碟',8); --影片不存在
--内连A,6条
select a.MovieID from #tmpMovie a inner join #tmpDisk b on a.MovieID=b.MovieID;
--内连B,6条
select b.MovieID from #tmpDisk b inner join #tmpMovie a on a.MovieID=b.MovieID;--效果一致
--左连接A,6条+A2条
select * from #tmpMovie a left join #tmpDisk b on a.MovieID=b.MovieID;
--左连接B,6条+B4条
select * from #tmpDisk b left join #tmpMovie a on a.MovieID=b.MovieID;
--右连接A,6条+B4条
select * from #tmpMovie a right join #tmpDisk b on a.MovieID=b.MovieID;
--右连接B,6条+A2条
select * from #tmpDisk b right join #tmpMovie a on a.MovieID=b.MovieID;
--外连接A,6条+A2条+B4条
select * from #tmpMovie a full join #tmpDisk b on a.MovieID=b.MovieID;
--外连接B,6条+A2条+B4条
select * from #tmpDisk b full join #tmpMovie a on a.MovieID=b.MovieID;
①:内连接,select ID from A inner join B on A.ID = B.ID,查询出A中依赖于B中有的,即是A与B共有的。
select ID from B inner join A on A.ID = B.ID,查询出B中依赖于A中有的。与上面一样。
内连,只查询出A与B中共有的数据,不会出现对应ID为null的情况。不完全的查询,没有null的存在。
②:左连接:select * from A Left join B on A.ID=B.ID,先查询出A的,再根据A的结果查询B,B中没A的会以A列为null的形式出现。5 左连接,只根据左表的ID对应查询出右表的数据,右表不存在时将出现null的情况。左全右不全 Select * from B Right join A on A.ID=B.ID,先查询A的,再根据A的结果查询B,A中没B的会以B列为null的形式出现。 右连接,只根据右表的ID对应查询出左表的数据,左表不存在时将出现null的情况。右全左不全 全连接,把A、B表的数据全部显示,实际上是内、左、右连接的并集。共有的,两边独自的。笛卡尔积, ④:全连接:select * from A full join B on A.ID=B.ID,即是在查询出A与B共有的数据的同时,一并把A有B没有,B有A没有的数据全部显示。
备注:凡是出现连接字段(主键没外键、外键没主键)的数据一律称为数据冗余。 影片 NULL NULL NULL select * from B Left join A on A.ID=B.ID,先查询出B的,再根据B的结果查询A,A中没B的会以B列为null的形式出现。10影碟8 NULL NULL ③:右连接:select * from A Right join B on A.ID=B.ID,先查询B的,再根据B的结果查询A,B中没A的会以A列为null的形式出现。

23、SQL语句执行顺序

24、使用临时表标记# #temp,模拟转置效果
create table #tmp(rq varchar(10),shengfu nchar(1))
insert into #tmp values('2005-05-09','胜')
insert into #tmp values('2005-05-09','胜')
insert into #tmp values('2005-05-09','负')
insert into #tmp values('2005-05-09','负')
insert into #tmp values('2005-05-10','胜')
insert into #tmp values('2005-05-10','负')
insert into #tmp values('2005-05-10','负')
insert into #tmp values('2005-05-11','负')
select * from #tmp;
类型转换函数
Cast ,Convert;
insert into #tmp values (cast ?string? as datetime);
insert into #tmp values ( Convert (datetime,?strings?) );
where DateDiff ( dd , 开始时间,结束时间) =0 返回的是一个整数
笛卡尔积1(T1、T2都有共有K)
select *
from
( select rq, count(rq) a1 from #tmp where shengfu='胜' group by rq) a, ( select rq, count(rq) b1 from #tmp where shengfu='负' group by rq) b 笛卡尔积2 (T1与T2)
select * from tbl_Type,tbl_Movie

isnull与full outer join
select a.rq, b.rq, isnull( a.rq, b.rq ) AS 空 , a.胜, b.负
from
( select rq, count(*) as 胜 from #tmp where shengfu='胜' group by rq ) a full outer join ( select rq, count(*) as 负 from #tmp where shengfu='负'group by rq ) b on a.rq=b.rq
cast
select
rq, count( case when shengfu = '胜' then 1 end ) as '胜',
sum( case when shengfu = '负' then 1 end ) as '负'
from #tmp
group by rq
pivot
select rq, [胜], [负], [胜] + [负] as 总场数
from #tmp pivot
(
count( shengfu )
for shengfu in ( [胜], [负] )
) as pvt
25、转置 转置一般有两种办法,一种是case+聚合函数、分组,一种是 pivat
①:case when then 结合聚合函数与分组,值得注意的是结果字段要是没聚合函数修饰,那么就要在查询域后对field进行分组 select [sid],
sum ([mark]) as 总分,
avg ([mark]) as 平均分,
avg ( case when [cid]=1 then [mark] end) as [database],
avg (case when [cid]=2 then [mark] end) as [C#],
avg (case when [cid]= 3 then [mark] end) as [xml]
from tbl_marks
group by [sid] –-对查询结果字段中没有聚合函数的字段进行分组修饰
②:pivot语句, select 'AverageCost' as Cost_Sorted_By_Proction_Days,–-排除子查询只能够piovt中的字段就是剩下的唯一字段进行默认分组
[0], [1], [2], [3], [4] --对应的列
From -- 记得在查询域中不能包含non-pivoted column,即是除了最后单一分组字段,其余字段必须是pivoted column
(
select DaysToManufacture, StandardCost
from Production.Product) as SourceTable
PIVOT for DaysToManufacture IN ([0], [1], [2], [3], [4] –for old field in 集合
)
) as PivotTable

; ( avg(StandardCost) -–对原来行的数据的目标列进行聚合函数的修饰
Select *
From –- 筛选子查询字段信息,排除no pivoted 集合的 column
(
select [sid], [cid], [mark]
from tbl_marks) p
pivot
(
sum (mark)
for [cid] in
( [1], [2], [3] )
) as pvt
26、创建视图
在不影响任何关联应用程序的情况下对表进行更改,这种抽象化使安全性得以提高。而且可以封装一些复杂的查询,可以快速地获取所需要的数据。一般是DBA来设定数据库的视图, 封装内部数据库的数据关系,范式修改数据容易了,视图让我们查询复杂关系的数据变得容易。
create view vMoneyUsing as
select * from MoneyUsing;
if exists (select * from dbo.sysobjects where id=OBJECT_ID(N'[dbo].[vMovieDiskTypeAll]') and OBJECTPROPERTY(id,N'IsView')=1)
drop view [dbo].[vMovieDiskTypeAll];
create view vMovieDiskTypeAll as
SELECT tbl_Type.TypeID, tbl_Type.TypeCode, tbl_Type.TypeName, tbl_Type.TypeDate, tbl_Movie.MovieID, tbl_Movie.MovieCode, tbl_Movie.MovieName, tbl_Movie.MovieContent, tbl_Movie.MovieDate, tbl_Disk.DiskID, tbl_Disk.DiskCode, tbl_Disk.DiskCharge, tbl_Disk.DiskState, tbl_Disk.RentRecordID, tbl_Disk.DiskCount, tbl_Disk.DiskDate, tbl_RentRecord.RenRecordCode,
tbl_RentRecord.AsscciatorID,tbl_Associator.AsscciatorCode,tbl_Associator.AsscciatorName,tbl_Associator.AsscciatorBalance,tbl_Associator.AsscciatorPhone, tbl_RentRecord.EmployeeID, tbl_Employee.EmployeeName, tbl_Employee.EmployeeTel,
tbl_RentRecord.RentRecordState, tbl_RentRecord.RentRecordDateStart, tbl_RentRecord.RentRecordDateEnd
FROM tbl_Associator INNER JOIN tbl_RentRecord ON tbl_Associator.AsscciatorID = tbl_RentRecord.AsscciatorID INNER JOIN tbl_Employee ON tbl_RentRecord.EmployeeID = tbl_Employee.EmployeeID RIGHT OUTER JOIN tbl_Disk ON tbl_RentRecord.DiskID = tbl_Disk.DiskID RIGHT OUTER JOIN tbl_Movie ON tbl_Disk.MovieID = tbl_Movie.MovieID RIGHT OUTER JOIN
tbl_Type ON tbl_Movie.TypeID = tbl_Type.TypeID
select * from vMovieDiskTypeAll;
27、创建函数function

create function MathMax
(
)
RETURNS int –2、声明返回的数据类型
AS
BEGIN
declare @max int
if(@a > @b) begin set @max= @a; end else begin set @max=@b; end --1、定义参数 @a int , @b int
return @max –3、返回值
END
GO
Select dbo.MathMax(dbo.MathMax(3,4),5)
28、创建索引
数据库DB就像是一个字典,索引就是根据指定字段制成的快速指向。由于只是指向数据对象标识,真正的数据是存储在DB中,所以查询速度极快。但是额外的内存与硬盘花销也是一个需要考虑的问题。比如:增加、删除、修改时数据库都要对索引进行维护,但是这样也是为了最后查询的效率的提升,特别适合W行级别的数据查询。而索引可以分为:隐式索引(针对单个字段)、唯一索引(唯一约束)、函数索引(函数(字段))与聚簇索引clusrered(主键)。
<1>视图创建索引

<2>代码创建索引
①:隐式索引:
create index ixTableColumn on table(column)
②:唯一索引
不允许具有索引值相同的行,从而禁止重复的索引或键值。系统在创建该索引时检查是否有重复的键值,并在每次使用 INSERT 或 UPDATE 语句添加数据时进行检查建立唯一约束的时候自动生成(而且unique关键字是可以用在聚簇与非聚簇索引中的)
create unique index ixTableColumn on table(column)
③:函数索引(函数(field)):
create index ixTableColumn on table( upper(column)) ;
④:聚簇索引
使用聚簇索引查找数据几乎总是比使用非聚簇索引快。每张表只能建一个聚簇索引,并且建聚簇索引需要至少相当该表120%的附加空间,以存放该表的副本和索引中间页。
一般使用对象:主键列,该列在where子句中使用并且插入是随机的;按范围存取的列,如pri_order > 100 and pri_order < 200;在group by或order by中使用的列;不经常修改的列;在连接操作中使用的列。
create clustered index ixTableColumn table(column)
但是此时如果表中有重复的记录,当你试图用这个语句建立索引时,会出现错误。
有重复记录的表也可以建立索引;你只要使用关键字allow_dup_row
create clustered index ixTableColumn table(column) with allow_dup_row
⑤:组合索引
对N个字段建立了一个索引。在一个复合索引中,你最多可以对16个字段进行索引。
create index ixTableColum1Column2 ON table(column1,column2)
⑥:全文索引(针对超长文本,一般是博文 text):

全文索引条件:表中的含有唯一约束(唯一索引)的列可以升级为全文索引,但是每个表只可以有一个全文索引,存放在指定的索引目录里,可以通过向导创建,也可以通过SQL创建。
1、 启动全文索引
use MoviesDB;
exec sp_fulltext_database 'enable'
2、创建全文目录(fulltext catalog 存放全文索引的文件)
create fulltext catalog ixCatalog
3、创建唯一索引 (unique)
create unique index ixTableColumn1 on table(column)
4、创建全文索引 (fulltext index)
create fulltext index on table(column1,column2)key index ixTableColumn1 on ixCatalog
注:ixTableColumn1是指已存在的基于指定表的唯一索引名.而不是唯一索引列名.如果索引不存在,需要先创建唯一索引.
代码创建索引成功后回出现:This command did not return data,and it did not return any rows (此命令不会返回行数据)
5、使用全文索引 (select contain freetext)
主要使用contains,freetext进行查询假设已有一个表table,已为字段field 创建全文索引,那么要查询含有周杰伦或者jay的所有记录的语句为:
select * from table where contains(fieldname,'"周杰伦" or "jay"')
也可以使用匹配模式进行包含条件组合,还可以使用and连接条件.
<3>使用索引
索引一旦创建成功,需要修改时必须先删除再创建:
一般执行查询的时候数据库系统会自动调用索引。
Drop index table.ixTableColumn

<4>全文索引扩展(使用系统存储过程)
1、 库
exec sp_fulltext_database 'enable'—启用全文索引功能
2、 目录
exec sp_fulltext_catalog 'ixTableColum','drop'--删除
exec sp_fulltext_catalog 'ixTableColum','create'--创建
3、表
exec sp_fulltext_table 'table','create','catalog','column'--创建
exec sp_fulltext_table 'table','active','catalog','column'—启动
exec sp_fulltext_table 'table','start_full','catalog','column'—同上
exec sp_fulltext_table 'table','deactive','catalog','clumn'—冻结
exec sp_fulltext_table 'table','drop','catalog','clumn'—删除
4、列
exec sp_fulltext_column 'table','column','add'--添加
exec sp_fulltext_column 'table','column','drop'—删除
5、检查填充情况
While fulltextcatalogproperty('catalog','populateStatus')<>0--检查全文目录填充情况
begin
waitfor delay '0:0:5'--如果全文目录正处于填充状态,则等待秒后再检测一次
END
6、使用全文索引(调用关键字contain、freetext)
select * from table where contains(columnname,'美赞臣'or ‘宝洁’) –显式使用全文索引查询
29、创建事务
很多时候我们的操作都不是一步完成的,而是由多次的修改插入删除所完成的
在银行数据库里面 ,张三存了1W ,那么转账呢? 那么得至少写两条SQL语句 防止程序出现灾难与数据错误,所以在高度自动化的时代,我们就必须搞好。五角大楼的事务例子,
利用计算机技术去处理,
一般是从4个方面去理解。ACID
A、 原子性 就是执行的时候要么整个完成,要么整个失败,就是两条语句构成一个整体,C#是不支持的,而且不论什么状态下都高度保持这样的原子性
B、一致性 指的是数据库是一条条的执行,但是在外部观察不会出现瞬时的不同步,也就是说我们在任何时候查询数据库,就是转得时候也是已经完成业务的(不论什么时候查询,都是保持一致的,就是业务都是执行完毕的,保证瞬时执行的完整性)
I、隔离性 就是虽然是一条条地改,但是对于事务外的对象是完全隔离的,但是外部查询是依赖于一致性的,在事务之外是查询不到的。但是Oracle是可以做到的,还是可以直接查询
D、持久性 一旦事务提交成功那么堆事务的修改是持久更新的,不会因为断电而悲剧。将被持久地存下来。需要DBA提供后备的支持的。支持多种方式的,分布式的话,就是同时在4个地方存储,银行不是那么低级地存得,要求全部都是实时的备份
create database myBankDB;
use myBankDB;
create table bank
(
账户 int identity(1,1),
存款 int
)
begin transaction
insert into bank values(10000);
insert into bank values(10000);
insert into bank values(10000);
select * from myBankDB.dbo.bank;
update myBankDB.dbo.bank set 存款=20000 where 账户>10 and 账户<55;
delete from myBankDB.dbo.bank;
commit;
rollback;
开始执行了begin transaction
再执行一半的语句这个时候
停止服务rollback,就会返回原来执行那一条的状态
直到运行至commit才完成事务,要不系统自动回滚
ALTER procedure [dbo].[prReturnDisk]
(
@EmployeeID int,
@RentRecordID int,
@Account int
)
as
declare @AccountRecordCode nvarchar(50)
declare @RentRecordState int
declare @DiskID int
declare @DateStrat datetime
declare @DateEnd datetime
declare @Cost float
begin try
begin transaction
select @AccountRecordCode=MAX(AccountRecordID)+1 from tbl_Account;--获取编号
select @RentRecordState=tbl_RentRecord.RentRecordState from tbl_RentRecord;--判断租借记录
if @RentRecordState = 1
begin
insert into tbl_Account (AccountRecordCode,EmployeeID,RentRecordID,Account)
values('Account'+@AccountRecordCode,@EmployeeID,@RentRecordID,@Account);--还碟子
update tbl_RentRecord set RentRecordState=0,RentRecordDateEnd=GETDATE() where RentRecordID=@RentRecordID;
select @DiskID=DiskID,@DateStrat =RentRecordDateStart,@DateEnd=RentRecordDateEnd from tbl_RentRecord where
RentRecordID=@RentRecordID;
select @Cost=((dbo.fnGetDate(@DateStrat,@DateEnd))*(select tbl_Disk.DiskCharge from tbl_Disk where DiskID=@DiskID)); update tbl_Disk set DiskState=0,RentRecordID=0 where DiskID=@DiskID;
if @Account>@Cost
begin
update tbl_Associator set AsscciatorBalance=AsscciatorBalance+(@Account-@Cost) where AsscciatorID=(select AsscciatorID from tbl_RentRecord where RentRecordID=@RentRecordID);
end
end
commit;
end try
begin catch
rollback
end catch

30、创建存储过程
不同的数据库的语言也是不同的,MSSQL的是TSQL ,存储过程一般是解决复杂的业务逻辑操作(一般是多表的操作)的问题。Oracle的PLSQL。在oracle就没有返回值,但是MSSQL有。返回值不是普通的返回值,这个一般不返回计算的结果,一般仅仅是返回整数的类型,若果没有显示返回结果,默认为返回0,一般是判断存储过程的执行状态。
<1>单纯的传参
create procedure proc_test
(
@NewName nvarchar(20),
@OldName nvarchar(20)
)
as
begin transaction
begin try
if exists (select Movie_Name from tbl_Movies)
return 0;
commit;
else
begin
rollback;
end
end try
<2>传参与返回值output
create procedure proc_test
(
)
as
begin transaction
begin try
--scope_identity()--标识当前作用域中新创造的主键
--insert之后马上获取当前状态的唯一标识的问题
declare @key int;
set @key =scope_identity();--赋值
select @key=scope_identity();--赋值
--但是临时变量@key仅仅在与自己的作用域中,要赋值给传出参数
set @number = @key;
commit;
end try
begin catch
rollback;
end catch
--执行
declare @Pan int;
execute @Pan = proc_test 'a','B','C',@number output;
print @Pan;--打印,return的
print @number;--返回的
执行存储过程的名字
Execute proc_name parmmarys ; @NewName nvarchar(20), @OldName nvarchar(20), @Name nvarchar(30), @number int output
Execute proc_UpdateName '精武门','新版精武门' ;
31、创建触发器
触发器(trigger)是个特殊的存储过程, 它的执行不是由程序调用,也不是手工启动,而是由事件来触发,比如当对一个表进行操作( insert,delete, update)时就会激活它执行。触发器经常用于加强数据的完整性约束和业务规则等。 触发器可以从 DBA_TRIGGERS ,USER_TRIGGERS 数据字典中查到。
触发器可以查询其他表,而且可以包含复杂的 SQL 语句。它们主要用于强制服从复杂的业务规则或要求。例如:您可以根据客户当前的帐户状态,控制是否允许插入新订单。 触发器也可用于强制引用完整性,以便在多个表中添加、更新或删除行时,保留在这些表之间所定义的关系。然而,强制引用完整性的最好方法是在相关表中定义主键和外键约束。如果使用数据库关系图,则可以在表之间创建关系以自动创建外键约束。
触发器,可以自己定义,一类是系统级触发器(数据库系统级别),一类是表触发器。
alter trigger [dbo].[tbl_Employee_AspNet_SqlCacheNotification_Trigger]
on [dbo].[tbl_Employee]
for insert, update, delete
as
begin
set nocount on
exec dbo.AspNet_SqlCacheUpdateChangeIdStoredProcedure N'tbl_Employee'
end
微软在framework4.0中asp.net_regsql.exe用命令行执行 C:\Windows\Microsoft.NET\Framework\v4.0.30319\aspnet_regsql.exe aspnet_regsql –S WIN-0E92J4Q2A85 –E –d MoviesDB –ed ——启动依赖项
aspnet_regsql –S WIN-0E92J4Q2A85 –E –d MoviesDB –lt ——显示监听表
aspnet_regsql –S WIN-0E92J4Q2A85 –E –d MoviesDB –t tablename –et ——为表建立监听触发器
32、时间函数
参考网址:
<1>datepart部分时间提取函数,返回表示指定 date 的指定 datepart 的整数。
datepart (datepart,”datetime”)
SELECT DATEPART(YY,'2007-10-30 12:15:32.1234567 +05:10')
datediff(datepart,stratdate,enddate)
<2>datediff时间间隔函数,返回指定的 startdate 和 enddate 之间所跨的指定 datepart 边界的计数(带符号的整数)。
五 : SQL数据库基础知识集合
1、 技术标签:(数据库 使用实例)
2、 技术细节:(数据库 的具体使用环境 MSSQL、mySQL、Oracle)
1、数据库简介:
数据库是专门开发数据管理的软件,或者说专门管理数据的软件就是数据库。(www.61k.com]
数据库存在的意义就是:减轻开发人员的负担。数据库是一个综合的软件,那么我们不需要队要进行2进制保存数据进行处理了,但是却是要与数据库产生交互,那么命令式SQL,有技巧的 ,数据库就是万物皆关系(面向对象,万物皆是对象)有所区别。
2、数据库的发展:
一开始的是层次化的数据与网状数据库 ,后来也发现使用确实很麻烦。
于是到了1970年EF.Cold博士(IBM公司的研究员)开创了关系性的数据库的先驱,发表了关系性数据库的论文 ,但是由于当时电脑硬件的局限性,大家觉得跑如此大的程序不值得。后来,Oracle(甲骨文)公司的创始人,拉里带领Oracle投入到关系型数据库的研发,并且得到了一个大客户 —美国国防部。随即开始世界刮起了关系数据库的旋风,随后各个公司都纷纷推出自己的数据库系统。比如:IBM的DB2 ,还有风靡一时的DBS3。
但是随即出现不兼容的问题,由于最早的时候都没有进行没规范。所以到最后各个数据库巨头统一了操纵数据库的SQL(结构化Struct数据查询语言) 变成了标准语言,而关系型数据库也俨然变成大家的宠儿,Oracle也从一个小公司,变成现在的数据库巨头,而我们的微软也推出了SQLServer。当然还有PHPer的最爱mySQL。但是mySQL被SUN,SUN被Oracle收购,现在有免费版与收费专业版了。所以我们学习SQL语言的时候,先学共同点,再学特异性。各种数据库软件在使用上有一点区别。
3、数据库系统详解:
为适应数据处理的需要而发展起来的一种较为理想的数据处理的核心机构。计算机的高速处理能力和大容量存储器提供了实现数据管理自动化的条件。
数据库系统一般由4个部分组成:
数据库,即存储在磁带、磁盘、光盘或其他外存介质上、按一定结构组织在一起的相关数据的集合。(个体)
数据库管理系统(DBMS)。一组能完成描述、管理、维护子数据库的程序系统。它按照一种公用的和可控制的方法完成插入新数据、修改和检索原有数据的操作。
数据库管理员(DBA)。
用户和应用程序。(微软的称作SSMS)
4、数据库系统的基本要求是:
1、能够保证数据的独立性。数据和程序相互独立有利于加快软件开发速度,节省开发费用。
2、冗余数据少,数据共享程度高。
3、系统的用户接口简单,用户容易掌握,使用方便。
4、能够确保系统运行可靠,出现故障时能迅速排除,能够保护数据不受非受权者访问或破坏,能够防止错误数据的产生,一旦产生也能及时发现。
5、有重新组织数据的能力,能改变数据的存储结构或数据存储位置,以适应用户操作特性的变化,改善由于频繁插入、删除操作造成的数据组织零乱和时空性能变坏的状况。
6、具有可修改性和可扩充性、可维护性。
7、能够充分描述数据间的内在联系。
5、数据库(Database):
由众多的数据、数据表、约束、存储过程、函数、视图、索引构成的一个数据存储与交互单元,是按照数据结构来组织、存储和管理数据的仓库。
6、数据表(table):
数据表,实际上是一个二维表。一般是围绕一个事务、动作记录,或者是一个信息主题作为一个数据表。数据表由行与列构成。
7、列(column、field):
列,其实就是字段。也是决定了信息的基本单元。列,包含有数据类型的设定。
8、行(row、record):
行,实际上就是一条基本信息。一行包含了多列数据的存储的信息。所以一行也有一条记录之称。
9、行业(trade)
一个行业一种需求,没一个需求每一种数据库的设计模式与思想。每个行业的数据设计的重点都是不同的。侧重查询(要求低范式)还是操作(要求搞范式)就是自己选择的问题了。
10、索引(index)
索引是一个单独的、物理的数据库结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引其实就是一个B+树,但是这个索引是N^n层数次方的。目的就是在数据库中划分出一定的区域优化查询。可以提升大量数据的查询速度。索引一般可以分为:基于字段优化查询速度的普通索引、唯一性索引、主键索引、全文索引、单列与多列索引。现在由于数据库系统的不断升级,我们只要设定索引就可以了,不需要特殊的维护。而且数据在查询的时候也会根据查询适当地选择是利用索引查询,还是仅仅是表查询。由于数据库系统的发展,系统内部已经自动帮我们完成对索引的维护。但是在设计的时候要考虑到索引的损耗问题。数据库DB就像是一个字典,索引就是根据指定字段制成的快速指向。由于只是指向数据对象标识,真正的数据是存储在DB中,所以查询速度极快。但是额外的内存与硬盘花销也是一个需要考虑的问题。比如:增加、删除、修改时数据库都要对索引进行维护,但是这样也是为了最后查询的效率的提升,特别适合W行级别的数据查询。而索引可以分为:隐式索引(针对单个字段)、唯一索引(唯一约束)、函数索引(函数(字段))、聚簇索引(主键)、组合索引(最多16个field)与全文索引(text)。一般索引会占用原数据库大小的20%。
11、视图(view)
固化的子查询,将一个子查询起了一个固化的名字,保存在数据库中,方便以后的使用。其实调用大量的Join来进行一个查询一般也是用视图。视图与索引都是为了优化查询的速度与语句。视图是优化语句,索引是优化单查速度。一般是DBA来设定数据库的视图, 封装内部数据库的数据关系,范式修改数据容易了,视图让我们查询复杂关系的数据变得容易。
12、触发器(trigger)
触发器(trigger)是个特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由个事件来触发,比如当对一个表进行操作( insert,delete, update)时就会激活它
sql数据库入门 SQL数据库基础知识集合
执行。[www.61k.com)触发器经常用于加强数据的完整性约束和业务规则等。 触发器可以从 DBA_TRIGGERS ,USER_TRIGGERS 数据字典中查到。
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
13、SQLServer数据类型详解

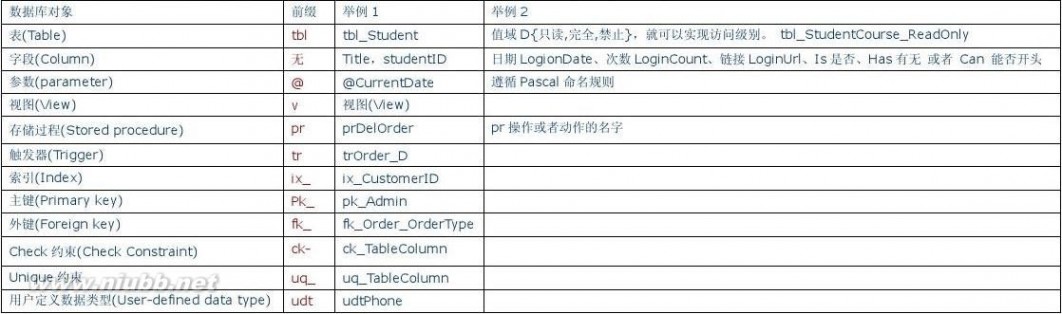
14、命名规范:
sql数据库入门 SQL数据库基础知识集合

15null也是一个集合,但是仅仅表示的是一个空集,但是实际上是null=Unknow。[www.61k.com) 1、 数值运算null为null; 2、 逻辑判定null为null; 3、 主外键联接null为忽略;
4、 语句连结null为or或真、and和假。 具体可查三值逻辑的真值表。
5、特殊情况:
<1>where null = null,where column = value:表中column为NULL的行永远不会返回,即使value是NULL,直接断言; <2>case null when null then XXX:XXX永远不会执行,即使value是NULL,直接断言;
<3>unknow判断,if <unknow> {XXX} else {YYY} end或case when <Unknown> then XXX else YYY end:这两种情况下,<unknow>,即是null会执行。 <4>唯一约束(unique index)的字段只允许一个null的行,再插入或更新该字段为NULL的行会报字段重复的错误。 <5>group by时,所有null被视为一组。
<6>order by时,所有null排在一起,但null排在最前面.(如SQL Server),或者是最后面(如Oracle),SQL标准未规定。 <7>聚集函数(sum/avg/max/min/count)忽略null的行,即是不返回此行数据,直接断言 <8> declare时,在未赋值之前为null。 <9>与NULL处理相关的运算符和函数:
- is null/is not null:用这两个运算符来判断一个值是否为NULL,而不是=或<>; - is null/ coalesce:取第一个非空值(注意两个函数的数据类型转换规则不同); - nullif(a,b):等价于如果a等于b返回null,如果不等于返回b - isnull(a,b):取两者中不为null的值,都为null返回null。
16、Not Null的建表
由于三值关系的存在,很多开发人员在建表的时候,除非是非null不可,基本都是允许为null的,其结果往往是一张表除了主键以外所有的字段都可以为Null。之所以会有这样的思路,是因为Null好啊,程序不容易出错啊,你插入记录的时候如果不小心忘输了一个字段,程序依然可以R运行un,而不会出现 “XX字段不能为Null”的错误消息。
但是,这样做的结果却是很严重的,也会使你的程序变得更加繁琐,你不得不进行一些无谓的空值处理,以避免程序出错。更糟的是,如果一些重要数据,比如说订单的某一项值为Null了,那么大家知道,任何值与Null相操作(比如加减乘除),结果都是Null,导致的结果就是订单的总金额也为Null。 你可以运行下面的代码尝试一下:
Select Null + 5 As Result
但是我们如何解决输入为空的问题呢?我们为什么不使用我们强悍的工具—check约束与默认值呢?
Field Varchar(500) default ‘nothing’ Not Null Constraint ck_ColumnName Check(Len(ColumnName)>0), [Type] TinyInt Not Null Default 0 Constraint ck_ArticleType Check([Type] in (0,1,2)),
所以,合理的思维方式应该是这样的:默认这个字段是 Not Null的,然后判断这个字段是不是非Null不可,如果不是这样,OK,这个字段是Not Null的,进行下一个字段。
17、数据库的原子性
1、你的表是描述什么事物,明确表的信息对象主体 2、你的表是为了适合什么操作语句的设计的,面向操作设计
3、列的内容要不要原子性的切块,让查询直逼要害,列的设计的小块的程度要拿捏好
4、表必须是二维表,而且要根据不同的需求进行设计,表的设计与列的设计一样都要依赖与操作与需求
原子性的存在是为了切分适合的信息块 ,从而达到信息的最大化、最优化的使用,并不是无限切分就好,要看实际的应用。但是由于原子性数据的表容易设计,而且运行的所需时间较短(查询信息的指向性比较强,同时也便于维护喝更新操作,但是却是在海量数据搜索面前有点乏力),所以对大量的数据处理的时候要加分效果。 1、 同一列中不能存在多个类型相同的值,一列不能多值(除非是) 2、 同一个表中也不能存在有多个存储相同类型数据的列
3、 无重复的行,每列只存储一份同类型下的一份数据(列是单值的),无重复列名 4、
18、结合信息对象与业务设计数据库设计
1、数据库的设计师根据信息要素、关系来设计的; 2、数据库的信息查找依赖于信息的使用方式的; 3、对于可有可无的东西,我们需要花点时间去好好斟酌; 4、简短的查询,比囧长的业务查询更加需要思考;
5、使用数据的方式将会与我们占用系统内存与硬盘息息相关,影响着服务器的整体表现,所以我们的设计会有所倚重与侧重; 现在基本是双数据库,外层是方便查询,内层是方便修改。
SQL换一句话其实就是关系数据库管理系统 Realtional Database Management System ,RDBMS 表的设计的方法:
1、挑出事物对象(对象信息浓缩法)
2、围绕事物对象的信息收集(信息扩散聚拢法)
sql数据库入门 SQL数据库基础知识集合
3、信息拆分成块(字段原子性)
4、事务需求拆分法(关系设计)
5、数据的发散与聚合程度的分析(表设计的检验)
19、范式 1NF 2NF 3NF 4NF
1NF,主要是解决表中字段设计、信息与业务之间的关系的问题
1、 数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。(www.61k.com)在第一范式(1NF)中表的每一行只包含一个
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
实例的信息。简而言之,第一范式就是无重复的列,而且单列无重复的值。
2、 所有属性都必须是原子的——每个属性一个值。一个实体的所有实例都必须包含同等数量的值。一个实体的所有实例必须两两不相同。
2NF,主要是设定主键,解决数据库的数据冗余、更新、插入、更新的指向性的问题
1、 要求数据库表中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。这个唯一属性列被称为主关键字或主键、主码、唯一
关联。引入主键约束primary key,Constraint pk_Article Primary Key(Id)。主键的设定也是有要求的。主键默认不能为空,保持唯一性。插入、更新删、除记录的时候必须指定主键的值。要求主键必须简洁,主键值不能被修改。
2、 实体必须满足第一范式。所有属性描述的事实都必须与整个键相关,而不能只描述键的一个子集。
3NF,主要是解决排除部分列之间的依赖关系,利用了表与表的主外键关系解决。
1、 要求实体数据记录(record)相对于外部完全依赖于主关键ID。所谓完全依赖,是指在除主键外其他的属性列之间不存在对应依赖。如果存在,那么这一依赖部分应该分离出来形
成一个表(关联),一般抽离出这一部分的主依赖项的ID,把这一部分作为一个新的表记录,同时原表也存储此次依赖项ID,然后利用建立主外键关系,将一表分成两表,解决原表因为主次依赖项存在而造成的数据冗余等一系列问题(但是对于以查询操作为主、记录大量数据的表此范式就需要斟酌了)。第二范式就是建立主键,与排除其他列对其属性列的依赖(消除部分列的依赖)。
2、 实体必须满足第二范式。如果每个非键属性描述的事实都与一个键属性相关,则实体满足第三范式所有属性描述的都必须是关于键的事实,除此之外别无其他。
4NF,主要是解决根据属性列的相似(不同的从属对象)与共同(相同的从属对象)信息的建表问题,即是表中所有列对外的一对多关系不受限制
1、 因为比较抽象,即是A表中含有a1,a2两个属性列,B表中记录a1的信息(包含b1),C表中包含a2的信息(包含c1),但是b1,c1实际上是相同类型的信息,但是从对象
不同。此处就是要我们明确建表的时候,要仔细区分共有与相似(决定建表)的关系,从属对象与属性列之间关系与一对多关系的搭设与否的问题。
2、 在实体中,不会出现多于一个的多值依赖。
5NF,主要是解决将信息切割得更细,清除所有冗余,但是在4NF设计会出现联接不当而产生的错误record
1、在4NF下,一般我们仅仅是区分了属性列的相似与共有信息,但是这个时候就会因为新建的b、c而产生误解数据或者是错误记录。因此可以从第五范式(实际上是所有范式)中得到的启示是,当你觉得可以将表分解为带着不同自然键的更多、更小的表时,这么干很可能就是最好的方式。如果你想要把各个部分联结到一起,表示最初的、分解得更少的数据形式,数据库干这事比你干得强多了。很明显,如果你不能通过联结来重新构建分解前的表,那就最好不要进行分解。即是有一个道理,更少得冗余,更多的错误。唯有靠联接来解决了。或者采用树状分层设计法,同层合并,也可以单独建立一个事务记录表。
2、当分解是信息无损的时候,所有关系都被分解成了二元关系。
但是面对日益变态的信息几何级的增长,为了令到数据库从焦油坑变成金矿我们会加入数据挖掘的思想,但是这个时候就需要无损的信息与高度分块的。所以在物理建表之前,我们还是需要遵循规范化建表的原则。
20、规范化建表
让数据具有原子性是设计出规范化数据表的第一步(同时也是为了提高数据库的可读性),但是到后期你可能会因为数据量以及性能的问题打破这种规范化。因为你的数据库投入使用后数据库的大小日益增大,设计规范化的表可以时刻保持你应对以后各种复杂的组合查询 (主要是应对数据库过分膨胀后的,查询缓慢的问题)
规范化建表的优点:
1、可以减少表中重复数据的存储,减少数据库的大小;
2、因为数据库的切割使得你的查询的指向性更强,查找的数据少,查找得更加快速;
3、但是最后归根到底还是 避免存储重复的数据节省我们的硬盘空间。
21、不规范化建表
规范化主要用来改善性能,过度规范化的结构会造成查询处理器和SQL Server中其他进程的开销过大(不适用在查询表的设计),或者,有时需要降低复杂性来使得实现更容易些,非规范化在这些时候就会发挥作用。正如我在这章中一直试图阐明的那样,虽然人们大都认为非规范化到第三范式就可以了(靠着减少所需联结的数量,查询过程已经被简化了)然而,这样做冒着引入数据异常的风险。每个使用数据库的应用程序都要复制任何额外写的,用来处理这些异常代码,因此就增加了人为错误的可能性。在这种情况下必须作出的判断是:是一个稍微慢点(但是100%正确)的应用更好呢,还是一个更快但正确性稍差的应用更好些。
在逻辑建模阶段,绝不应该从我们规范化的结构倒退,对应用程序过早过激地进行性能调优工作。OLTP数据库结构上,所以设计中最重要的部分就是:保证我们的逻辑模型体现了最终的数据库含有的所有实体和属性。一旦开始物理建模过程(这与性能调优应该是同义语),那就有足够充足的理由来对结构进行非规范化操作,要么是出于性能的考虑,要么是出于减少复杂性的考虑,但是,这两种考虑都不适合用在逻辑模型上。当我们物理上的实现在逻辑上也正确的时候,碰到的问题几乎总是会更少些。对几乎所有情况来说,我都建议等到物理建模阶段才对解决方案进行实现,或者,至少等到有某种非做不可的原因时(比如,系统中某些部分失败了)才进行非规范化工作。
总结:一般,我们是采用两层数据库的,一层是外层,用于直接的查询。一层是内层数据库,用于记录与维护更新的。维护更新资料的时候,对内层数据库进行操作,当操作完成的时候就会马上更新外层数据库。所以外层数据库(以查询为主)设计的范式要求比较低,但是内层数据库(维护更新为主)的要求就比较高了。
22、数据库设计建议:
数据库不仅是用来保存数据,还应负责维护数据的完整性和一致性
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
我看过很多的开发人员设计出来的数据库,给我的感觉就是:在他们眼里,数据库的作用就如同它的名称一样――不仅仅是用来存放数据的,除了不得不建的主键以外,什么都没有...没有 Check约束,没有索引,没有外键约束,没有视图,甚至没有存储过程。 一个很好的数据库该有的还是有的。什么都没有的数据库插入操作是很好,但是多了这点东西的数据库还是很快的。
如果要写代码来确保表中的行都是唯一的,就为表添加一个主键,即是distinct的使用频率应该是比价少的。
如果要写代码来确保表中的一个单独的列是唯一的,就为表添加一个约束,一般是事务状态记录表。
如果要写代码确定表中的列的取值只能属于某个范围,就添加一个Check约束。
如果要写代码来连接 父-子 表,就创建一个关系,上下其实都是依据主外键的。
如果要写代码来维护“一旦父表中的一行发生变化,连带变更子表中的相关行”,就启用级联删除和更新。
如果要调用大量的Join来进行一个查询,就创建一个视图。
如果要逐条的写数据库操作的语句来完成一个业务规则,就使用存储过程。
没有提到触发器,实践证明触发器会使数据库迅速变得过于复杂,更重要的是触发器难以调试,如果不小心建了个连环触发器,就更让人头疼了,所以我更倾向于根本就不使用触发器trigger。
sql数据库入门 SQL数据库基础知识集合
3、技术实例:(数据库)
1、 加载数据库脚本
source C:UsersAdministratorDesktopscript-1.sql ;——mySQL
source (.) Execute an SQL script file. Takes a file name as an argument.
2、 保存为数据库脚本
Tee C:UsersAdministratorDesktopscript-1.sql ;
tee (T) Set outfile [to_outfile]. Append everything into given outfile.
notee 输入的时候就会把tee与notee进行保存为sql脚本。(www.61k.com]
3、 查询当前实例的数据库集合
Show databases ; ——mySQL
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| drinks |
| mysql |
| performance_schema |
| test |
+--------------------+
4、使用某个数据库
mysql> use drinks;
Database changed
5、查询当前数据库的表集
mysql> show tables;
+------------------+
| Tables_in_drinks |
+------------------+
| easy_drinks |
| my_contacts |
+------------------+
6、查询表的结构
mysql> desc my_contacts;
+------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+--------------+------+-----+---------+-------+
7、判断存在
方法1:精确方法
Sysobjects是Master系统视图
object_id是抓取对象在视图中的ID
OBJECTPROPERTY是根据对象判断类型函数,返回的是bool
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[tb]') and OBJECTPROPERTY(id, N'IsUserTable') = 1) drop table [dbo].[tb];
方法2:模糊方法
declare @a varchar(2000) ——MSSQL 删除约束
set @a=(select name from sysobjects where name like 'Name')
set @a= 'ALTER TABLE [dbo].[TableName] DROP CONSTRAINT '+@a
exec (@a)
8、数据库的新建、删、改
<1>新建数据库
mysql> create database myDB; ——mySQL
Query OK, 1 row affected (0.00 sec)
create database mmc; ——MSSQL
<2>数据库修改
exec sp_rename 'a1.name ', 'Name ', 'database' ——MSSQL
<3>删除数据库
sql数据库入门 SQL数据库基础知识集合
mysql> drop database drinks;——mySQL
Query OK, 2 rows affected (0.34 sec)
drop database mySQL;——MSSQL
9、数据表的新建、删、改
<1>新建数据表
mysql> show create table servers;——mySQL显示表的创建方式
| servers | CREATE TABLE `servers` (
`Server_name` char(64) NOT NULL DEFAULT '',
`Host` char(64) NOT NULL DEFAULT '', `Db` char(64) NOT NULL DEFAULT '',
`Username` char(64) NOT NULL DEFAULT '',
`Password` char(64) NOT NULL DEFAULT '',
`Port` int(4) NOT NULL DEFAULT '0',
`Socket` char(64) NOT NULL DEFAULT '',
`Wrapper` char(64) NOT NULL DEFAULT '',
`Owner` char(64) NOT NULL DEFAULT '',
PRIMARY KEY (`Server_name`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='MySQL Foreign Servers table' |
mysql> create table my_contacts( ——mySQL
-> ID int not null Auto_increment,
-> last_name varchar(20) not null,
-> first_name varchar(20) not null,
-> email varchar(50) not null,
-> birthday date,
-> profession varchar(50),
-> location varchar(50),
-> status varchar(20),
-> interests varchar(20),
-> seeking varchar(100) ,
Parmary key (名 ) );
Create Table Article ——MSSQL
(
Id Int Identity(1,1) Not Null,——自增
Varchar(50)
Varchar(50) Not Null Constraint uq_ArticleTitle Unique,——1、唯一约束 Not Null Constraint ck_KeywordsLength Check (len(Keywords)<10),——2、检查约束
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
Not Null, ——3、非空约束
Not Null,
Not Null Default 0 Constraint ck_ArticleType Check([Type] in (0,1,2)),
Not Null Default 1, ——默认值
Not Null,
Null,
Not Null Default 'TraceFact',
Null,
Not Null Default GetDate(),
Not Null Default 0,
Not Null , Title Keywords Abstract Author [Type] Varchar(500) Varchar(50) TinyInt IsOnIndex Bit Content Text [Source] SrcUrl PostDate ClassId SourceCode Varchar(100) Varchar(50) DateTime Int Varchar(150) ViewCount Int
Constraint pk_Article Primary Key(Id), —— 4、主键约束
Constraint fk_Article foreign key(scoreId) references student(id)——5、外键约束,为主表student建立外键关系 )
<2>修改数据表
mysql> alter table 旧表名 rename to 新表名; ——mySQL
use databasename;
EXEC sp_rename '旧表名', '新表名';——MSSQL
<3>删除数据表
mysql> drop table mytables;——mySQL
drop table a1;——MSSQL
10、字段、约束(数据表成员)的增加、删、改
<1>增加字段
mysql> alter table mytable——mySQL 添加字段
-> add column mycolumn2 int first , 其中还有 after column 排在指定的列之后
-> add primary key (mycolumn2); ——mySQL 添加主键
alter table test1 add nob int identity(1,1) not null ——MSSQL 添加字段
alter table test1 add primary key (nob); ——MSSQL 添加主键
sql数据库入门 SQL数据库基础知识集合
alter table [dbo].[Article2] add default ((1)) for [IsOnIndex] ——MSSQL添加默认约束
alter table [dbo].[Article2] with check add constraint [ck_KeywordsLength2] check ((len([Keywords])<(10))) ——新建check
alter table [dbo].[Article2] check constraint [ck_KeywordsLength2] ——MSSQL把ck_KeywordsLength2添加check约束集合
alter table [dbo].[Article2] with check add constraint [ck_ArticleType2] check (([Type]=(2) OR [Type]=(1) OR [Type]=(0)))
<2>修改字段
mysql> alter table mytables
-> add primary key ( lastname );
mysql> alter table mytable——mySQL 不改变名字,改类型
-> modify mycolumn2 varchar(20); -> change column firstname firstName varchar(30) ,——mySQL 改变名字、类型
exec sp_rename 'a1.name ', 'Name ', 'column ' ——MSSQL 只改变名字
alter table test1 alter column ID varchar(200) null ——MSSQL 不改变名字,改类型
alter table test1 drop Constraint constraintname; ——MSSQL 删除约束
alter table test1 add primary key (nob); ——MSSQL 添加主键约束
alter table Articles2 add constraint fk_job_id foreign key (Id) references Article3(Id); ——MSSQL添加外键约束
alter table dbo.Article2 add constraint uk_Id unique nonclustered (Id); ——MSSQL添加唯一约束
alter table [dbo].[Article2] add constraint uk_Id default ((1)) for [IsOnIndex] ——MSSQL添加默认约束
alter table [dbo].[Article2] with check add constraint [ck_KeywordsLength2] CHECK ((len([Keywords])<(10))) ——新建check
alter table [dbo].[Article2] chenk constraint [ck_KeywordsLength2] ——MSSQL把ck_KeywordsLength2添加check约束集合
alter table [dbo].[Article2] with check add constraint [ck_ArticleType2] check (([Type]=(2) OR [Type]=(1) OR [Type]=(0))) alter table [dbo].[Article2] with check add constraint [ck_KeywordsLength2] check ((len([Keywords])<(10))) ——新建check
alter table [dbo].[Article2] check constraint [ck_KeywordsLength2] ——MSSQL把ck_KeywordsLength2添加check约束集合
备注:最后一栏column/database/index/object等等,还有约束的修改只能是先删除再新建。(www.61k.com)
还能够建立联合主键,就使用利用两个字段来确定一条数据,一般这样的数据不会进行修改。

<3>删除字段
mysql> alter table mytable ——mySQL
-> drop column mycolumn2;
alter table test1 drop column nob; ——MSSQL 删除字段
alter table test1 drop Constraint constraintname; ——MSSQL 删除约束
11、连接词 and、or 、not
<1>and:A and B,即是A与B 要同时成立。 <2>or:A或者B,只要其中一个成立就成立 <3>not:not A and B,当A不成立而且B成立;A and not B,当A成立而且B不成立; not (A and B),当A与B都不成立 1、<:小于 2、>:大于 3、<=:小于或者等于
4、>=:大于或者等于
5、<>:不等于;=等于
6、is null 或者是 not null
7、<?D?: field的第一个字母早于D;>?A?:field的第一个字母要晚于A
13、匹配关键字LIKE、通配符“%”与占位符 “_”与区间关键字“between”与集合关键字“in“
①:where field Like ‘%CA%’,filed字段里面包含CA字符的所有结果;
②:where field Like ‘CA%’,field字段前面是CA字符的结果;
③:where field Like ‘%CA’,field字段后面是CA字符的结果;
③:where field Like ‘_CA%’,field字段前面第二第三个是CA的结果;
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
④:where field between 20 and 30 在20与30之间 或者 between ?A? and ?Z? 在A与Z之间。
⑤:where field in (1,2,3) filed(类型相同)是1,2,3中的其中一个 或者 where field in (‘1’,‘2’,‘3’)field在‘1’、‘2’、‘3’中的其中之一,即是filed的类型要
与in里面的类型相同。
14、SQL语句select、insert、delete、update
①:select field from table
②:insert into table (fields) values (values)
③:delete from table where field 条件
④:update table set field = value where field 条件,例子:update table set table.column2= Right(table,2)
⑤:SQL语句是可以结合运算的。Update set const=const=1; 12、符号 <、>、=、<=、=>、<>、null
sql数据库入门 SQL数据库基础知识集合
15、SQL字符串处理函数
①:Right (column,2) 从右边开始截取2位的字符
②:Substring _index( column,“,”,2) 截取第二个逗号(字符)前的字符串
③:Substring (column,numberA,numberB) 截取列中,从A位开始读取后面B位的字符串
④:Upper(column) 转换大写、
⑤:Lower (column) 转换小写
⑥:Reverse(column) 反转字符串的顺序
⑦:Ltim( colum ) 左去除空
⑧:Rtrim( column) 右去除空
⑨:Length (column) 获取字符长度,返回一个int,但是在MSSQL len(Keywords)<10
16、数据表约束Constraint(唯一、非空、检查、主键、外键)
<1>唯一约束:Constraint uq_ArticleTitle Unique,——唯一约束
alter table dbo.Article2 add constraint uk_Id unique nonclustered (Id); ——MSSQL添加唯一约束 唯一约束即是指定的列的值在此列中只出现一次,null也是不能出现第二次的。(www.61k.com) <2>非空约束:Content Text Not Null, alter table student add constraint codenn check(code is not null);
非空约束指定列不能为空。
<3>检查约束:Constraint ck_ArticleType Check([Type] in (0,1,2)), alter table [dbo].[Article2] with check add constraint [ck_KeywordsLength2] check ((len([Keywords])<(10))) check约束是功能最强大的约束,其中可以写很多逻辑条件进去。 <4>主键约束:Constraint pk_Article Primary Key(Id), —— 4、主键约束 alter table test1 add primary key (nob); ——MSSQL 添加主键约束 主键约束是指此列为唯一标识,一般配合identity(1,1)使用。 <5>外键约束:Constraint fk_Article foreign key(scoreId) references student(id)——5、外键约束,为主表student建立外键关系 alter table Articles2 add constraint fk_job_id foreign key (Id) references Article3(Id); ——MSSQL添加外键约束 B表中使用外键约束字段ID,那么确保B表中的输入的ID的值与A表中ID的值匹配。A表ID为主键,B表ID为外键,B的ID依赖与A的ID的存在。
17、case when then语句
<1>一般使用:
select case column when value1 then operate1 end when value2 then operate2 end else operate3 end from table 返回的operate的值
<2>结合连接词 :
select ('Disk'+Ltrim(Rtrim(Convert(char,a.Disk_ID)))+'Movie'+Rtrim(Ltrim(Convert(char,b.Movie_ID)))) as 编号, b.Movie_Name as 影片名称,a.RentCount as 租借次数, (case a.States when 0 then '没租' when 1 then '已租出'
when 2 then '已预定' when 3 then '损毁' end ) as 状态 from (tbl_MovieDisk a inner join tbl_Movies b
on a.Movie_ID=b.Movie_ID) left join tbl_MovieTypes e on b.Type_ID=e.Type_ID;
<3>结合组函数转置:
select [sid],
sum ([mark]) as 总分,
avg ([mark]) as 平均分,
avg ( case when [cid]=1 then [mark] end) as [database],
avg (case when [cid]=2 then [mark] end) as [C#],
avg (case when [cid]= 3 then [mark] end) as [xml]
from tbl_marks
group by [sid] –-对查询结果字段中没有聚合函数的字段进行分组修饰
18、排序关键字 order by column(顺序) 与 order by column desc(倒序)MSSQL的功能都不是单一、独立的,所以必须对结果集合进行收缩
create table #tmp1
(
name nvarchar(20),
name2 nvarchar(20)
)
select * from #tmp1;
insert into #tmp1 (name) values ('A');
insert into #tmp1 (name,name2) values (1,1);
insert into #tmp1 (name,name2) values ('a',1);
insert into #tmp1 (name,name2) values (1,'b');
insert into #tmp1 (name,name2) values (1,'?');
insert into #tmp1 (name,name2) values (1,'B');
insert into #tmp1 (name,name2) values (1,'A');
select name2 from #tmp1 order by name2;
①:对于数字1到9,顺序是1-9,由小到大;而倒序是9-1;
②:对于数字1到9,而且夹杂a-z与A-Z,顺序是aABbcCDd 小大大小模式;
sql数据库入门 SQL数据库基础知识集合
③:对于字母a到z,顺序是a-z;而倒序是z-a;
④:对于字母a到z,即是夹杂a-z与A-Z,没有排序的时候:aABbcCDd 小大大小模式;
⑤:其实是MSSQL对大小写都是同等对待。(www.61k.com)select tmpChar from #tmp1 group by tmpChar,只出现一组的a-g,而且是不区分大小写的,导致了。
⑥:order by的多组合,先执行列1再在列1的区域里面再进行列2的排序select tmpChar from #tmp1 order by tmpChar desc倒序,tmpNum asc顺序; ⑦:对于符号的排序的问题,我们有时候要对nvarchar类型的字段进行排序,里面有很多特殊的字符,那么顺序是:!“&‘(*+=@
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
⑧:一般规律是:顺序上到下 ,null 非字母字符 数字 大写字母 小写字母 非字母字符
19、分组关键字 group by
create table #tmp2
(
[Count] int,
name2 nvarchar(20)
)
select * from #tmp2;
insert into #tmp2 ([Count],name2) values (1,1)
insert into #tmp2 ([Count],name2) values (2,1)
insert into #tmp2 ([Count],name2) values (3,2)
insert into #tmp2 ([Count],name2) values (4,2)
insert into #tmp2 ([Count],name2) values (5,3)
select name2 from #tmp2 group by name2;OK
select [Count],name2 from #tmp2 group by name2;wrong
select [Count],name2 from #tmp2 group by name2,[Count]; OK
select SUM([Count]) as 汇总 ,name2 from #tmp2 group by name2; OK
①:指定的列进行分组,返回的结果集合要是包含其他的列(没有组函数运算),那么需要把其他的列依次加入到分组集合中。
20、聚合SUM()、AVG()、COUNT()、MAX()、MIN()
①:SUM(),汇总聚合函数
②:AVG(),平均聚合函数; ③:COUNT(),计数聚合函数; ④:MAX(),求最大值聚合函数; ⑤:MIN(),求最小值聚合函数。
备注:使用聚合函数在查询范围后一定要使用group by 对聚合函数以外的列进行分组。而且所有的对象是除字符类型的所有数值类型。 ②:在结果集合里面,除分组集合中的列外,其他列必须有组函数修饰。
21、子查询、范围匹配关键字in与聚合函数后的查询子句Having
①:子查询是指当一个查询是令一个查询的条件的时候。即是:查询出来的结果是另外一个查询的搜索域或者条件。
①-1:
搜索域(双重嵌套)
select ss.studentid, ts.[name], ss.totalmark from
(
条件(返回的集合区间) select Name
from AdventureWorks.Production.Product
where ListPrice =
( select ListPrice
from AdventureWorks.Production.Product
where Name = 'Chainring Bolts' )
①-2:集合in、having、exists
②:in是确定指定的值是否与子查询或列表区域中的值相匹配。返回一个bool
区间条件:· select s.studentid, sum( mark ) as TotalMark from ( tbl_students s inner join tbl_marks m on s.studentId = m.sid ) inner join tbl_courses c on m.cid = c.courseId inner join tbl_students ts on ss.studentid = ts.studentid group by s.studentId ) ss
select FirstName, LastName, e.Title
from HumanResources.Employee as e
JOIN Person.Contact as c on e.ContactID = c.ContactID
where e.Title in ('Design Engineer', 'Tool Designer', 'Marketing Assistant');
GO
Check约束:Constraint ck_ArticleType Check([Type] in (0,1,2)), –-check约束中的使用
③:Having是指定组或聚合的搜索条件,相当于group by后的where。
Having 只能与 select 语句一起使用。Having 通常在 group by 子句中使用。如果不使用 group by 子句,则 Having 的行为与 where 子句一样。在 Having 子句中不能使用 text、image 和 ntext 数据类型
select SalesOrderID, sum(LineTotal) as SubTotal –-此处有聚合函数
sql数据库入门 SQL数据库基础知识集合
from Sales.SalesOrderDetail
group by SalesOrderID
Having sum(LineTotal) > 100000.00 –Having不能使用text、image、ntext,Having使用的时候必须跟在分组之后。[www.61k.com] order by SalesOrderID ;
22、内连接inner join table on ,外连接 right join table on 、 Left join table on与全连接 full join table on
现在有table A 与 table B。A、B表有主外键关于 ID主外键关系。A表是主表,B表是子表。A是影片表,B是影碟表,ID是MovieID。 Create table #tmpMovie
(
MovieID int ,
MovieName nvarchar(30)
)
select * from #tmpMovie; --6条数据,2条没用
insert into #tmpMovie (MovieID,MovieName)values (1,'影片');
insert into #tmpMovie (MovieID,MovieName)values (2,'影片');
insert into #tmpMovie (MovieID,MovieName)values (3,'影片');
insert into #tmpMovie (MovieID,MovieName)values (4,'影片');
insert into #tmpMovie (MovieID,MovieName)values (5,'影片');--多余的
insert into #tmpMovie (MovieID,MovieName)values (6,'影片');--多余的
create table #tmpDisk
(
DiscID int,
DiscName nvarchar(30),
MovieID int
)
select * from #tmpDisk; --10条数据,4条没用
insert into #tmpDisk (DiscID,DiscName,MovieID) values (1,'影碟',1);
insert into #tmpDisk (DiscID,DiscName,MovieID) values (2,'影碟',1);
insert into #tmpDisk (DiscID,DiscName,MovieID) values (3,'影碟',2);
insert into #tmpDisk (DiscID,DiscName,MovieID) values (4,'影碟',2);
insert into #tmpDisk (DiscID,DiscName,MovieID) values (5,'影碟',3);
insert into #tmpDisk (DiscID,DiscName) values (6,'影碟');--为空
insert into #tmpDisk (DiscID,DiscName,MovieID) values (7,'影碟',4);
insert into #tmpDisk (DiscID,DiscName) values (8,'影碟');--为空
insert into #tmpDisk (DiscID,DiscName,MovieID) values (9,'影碟',7); --影片不存在
insert into #tmpDisk (DiscID,DiscName,MovieID) values (10,'影碟',8); --影片不存在
--内连A,6条
select a.MovieID from #tmpMovie a inner join #tmpDisk b on a.MovieID=b.MovieID;
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
--内连B,6条
select b.MovieID from #tmpDisk b inner join #tmpMovie a on a.MovieID=b.MovieID;--效果一致
--左连接A,6条+A2条
select * from #tmpMovie a left join #tmpDisk b on a.MovieID=b.MovieID;
--左连接B,6条+B4条
select * from #tmpDisk b left join #tmpMovie a on a.MovieID=b.MovieID;
--右连接A,6条+B4条
select * from #tmpMovie a right join #tmpDisk b on a.MovieID=b.MovieID;
--右连接B,6条+A2条
select * from #tmpDisk b right join #tmpMovie a on a.MovieID=b.MovieID;
--外连接A,6条+A2条+B4条
select * from #tmpMovie a full join #tmpDisk b on a.MovieID=b.MovieID;
--外连接B,6条+A2条+B4条
select * from #tmpDisk b full join #tmpMovie a on a.MovieID=b.MovieID;
①:内连接,select ID from A inner join B on A.ID = B.ID,查询出A中依赖于B中有的,即是A与B共有的。
select ID from B inner join A on A.ID = B.ID,查询出B中依赖于A中有的。与上面一样。
内连,只查询出A与B中共有的数据,不会出现对应ID为null的情况。不完全的查询,没有null的存在。
②:左连接:select * from A Left join B on A.ID=B.ID,先查询出A的,再根据A的结果查询B,B中没A的会以A列为null的形式出现。5 左连接,只根据左表的ID对应查询出右表的数据,右表不存在时将出现null的情况。左全右不全 Select * from B Right join A on A.ID=B.ID,先查询A的,再根据A的结果查询B,A中没B的会以B列为null的形式出现。 右连接,只根据右表的ID对应查询出左表的数据,左表不存在时将出现null的情况。右全左不全 全连接,把A、B表的数据全部显示,实际上是内、左、右连接的并集。共有的,两边独自的。笛卡尔积, ④:全连接:select * from A full join B on A.ID=B.ID,即是在查询出A与B共有的数据的同时,一并把A有B没有,B有A没有的数据全部显示。
备注:凡是出现连接字段(主键没外键、外键没主键)的数据一律称为数据冗余。 影片 NULL NULL NULL select * from B Left join A on A.ID=B.ID,先查询出B的,再根据B的结果查询A,A中没B的会以B列为null的形式出现。10影碟8 NULL NULL ③:右连接:select * from A Right join B on A.ID=B.ID,先查询B的,再根据B的结果查询A,B中没A的会以A列为null的形式出现。
sql数据库入门 SQL数据库基础知识集合
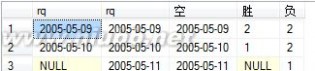
23、SQL语句执行顺序

24、使用临时表标记# #temp,模拟转置效果
create table #tmp(rq varchar(10),shengfu nchar(1))
insert into #tmp values('2005-05-09','胜')
insert into #tmp values('2005-05-09','胜')
insert into #tmp values('2005-05-09','负')
insert into #tmp values('2005-05-09','负')
insert into #tmp values('2005-05-10','胜')
insert into #tmp values('2005-05-10','负')
insert into #tmp values('2005-05-10','负')
insert into #tmp values('2005-05-11','负')
select * from #tmp;
类型转换函数
Cast ,Convert;
insert into #tmp values (cast ?string? as datetime);
insert into #tmp values ( Convert (datetime,?strings?) );
where DateDiff ( dd , 开始时间,结束时间) =0 返回的是一个整数
笛卡尔积1(T1、T2都有共有K)
select *
from
( select rq, count(rq) a1 from #tmp where shengfu='胜' group by rq) a, ( select rq, count(rq) b1 from #tmp where shengfu='负' group by rq) b 笛卡尔积2 (T1与T2)
select * from tbl_Type,tbl_Movie

isnull与full outer join
select a.rq, b.rq, isnull( a.rq, b.rq ) AS 空 , a.胜, b.负
from
( select rq, count(*) as 胜 from #tmp where shengfu='胜' group by rq ) a full outer join ( select rq, count(*) as 负 from #tmp where shengfu='负'group by rq ) b on a.rq=b.rq
cast
select
rq, count( case when shengfu = '胜' then 1 end ) as '胜',
sum( case when shengfu = '负' then 1 end ) as '负'
from #tmp
group by rq
pivot
select rq, [胜], [负], [胜] + [负] as 总场数
sql数据库入门 SQL数据库基础知识集合
from #tmp pivot
(
count( shengfu )
for shengfu in ( [胜], [负] )
) as pvt
25、转置 转置一般有两种办法,一种是case+聚合函数、分组,一种是 pivat
①:case when then 结合聚合函数与分组,值得注意的是结果字段要是没聚合函数修饰,那么就要在查询域后对field进行分组 select [sid],
sum ([mark]) as 总分,
avg ([mark]) as 平均分,
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
avg ( case when [cid]=1 then [mark] end) as [database],
avg (case when [cid]=2 then [mark] end) as [C#],
avg (case when [cid]= 3 then [mark] end) as [xml]
from tbl_marks
group by [sid] –-对查询结果字段中没有聚合函数的字段进行分组修饰
②:pivot语句, select 'AverageCost' as Cost_Sorted_By_Proction_Days,–-排除子查询只能够piovt中的字段就是剩下的唯一字段进行默认分组
[0], [1], [2], [3], [4] --对应的列
From -- 记得在查询域中不能包含non-pivoted column,即是除了最后单一分组字段,其余字段必须是pivoted column
(
select DaysToManufacture, StandardCost
from Production.Product) as SourceTable
PIVOT for DaysToManufacture IN ([0], [1], [2], [3], [4] –for old field in 集合
)
) as PivotTable

; ( avg(StandardCost) -–对原来行的数据的目标列进行聚合函数的修饰
Select *
From –- 筛选子查询字段信息,排除no pivoted 集合的 column
(
select [sid], [cid], [mark]
from tbl_marks) p
pivot
(
sum (mark)
for [cid] in
( [1], [2], [3] )
) as pvt
26、创建视图
在不影响任何关联应用程序的情况下对表进行更改,这种抽象化使安全性得以提高。(www.61k.com)而且可以封装一些复杂的查询,可以快速地获取所需要的数据。一般是DBA来设定数据库的视图, 封装内部数据库的数据关系,范式修改数据容易了,视图让我们查询复杂关系的数据变得容易。
create view vMoneyUsing as
select * from MoneyUsing;
if exists (select * from dbo.sysobjects where id=OBJECT_ID(N'[dbo].[vMovieDiskTypeAll]') and OBJECTPROPERTY(id,N'IsView')=1)
drop view [dbo].[vMovieDiskTypeAll];
create view vMovieDiskTypeAll as
SELECT tbl_Type.TypeID, tbl_Type.TypeCode, tbl_Type.TypeName, tbl_Type.TypeDate, tbl_Movie.MovieID, tbl_Movie.MovieCode, tbl_Movie.MovieName, tbl_Movie.MovieContent, tbl_Movie.MovieDate, tbl_Disk.DiskID, tbl_Disk.DiskCode, tbl_Disk.DiskCharge, tbl_Disk.DiskState, tbl_Disk.RentRecordID, tbl_Disk.DiskCount, tbl_Disk.DiskDate, tbl_RentRecord.RenRecordCode,
tbl_RentRecord.AsscciatorID,tbl_Associator.AsscciatorCode,tbl_Associator.AsscciatorName,tbl_Associator.AsscciatorBalance,tbl_Associator.AsscciatorPhone, tbl_RentRecord.EmployeeID, tbl_Employee.EmployeeName, tbl_Employee.EmployeeTel,
tbl_RentRecord.RentRecordState, tbl_RentRecord.RentRecordDateStart, tbl_RentRecord.RentRecordDateEnd
FROM tbl_Associator INNER JOIN tbl_RentRecord ON tbl_Associator.AsscciatorID = tbl_RentRecord.AsscciatorID INNER JOIN tbl_Employee ON tbl_RentRecord.EmployeeID = tbl_Employee.EmployeeID RIGHT OUTER JOIN tbl_Disk ON tbl_RentRecord.DiskID = tbl_Disk.DiskID RIGHT OUTER JOIN tbl_Movie ON tbl_Disk.MovieID = tbl_Movie.MovieID RIGHT OUTER JOIN
tbl_Type ON tbl_Movie.TypeID = tbl_Type.TypeID
select * from vMovieDiskTypeAll;
27、创建函数function
sql数据库入门 SQL数据库基础知识集合

create function MathMax
(
)
RETURNS int –2、声明返回的数据类型
AS
BEGIN
declare @max int
if(@a > @b) begin set @max= @a; end else begin set @max=@b; end --1、定义参数 @a int , @b int
return @max –3、返回值
END
GO
Select dbo.MathMax(dbo.MathMax(3,4),5)
28、创建索引
数据库DB就像是一个字典,索引就是根据指定字段制成的快速指向。[www.61k.com)由于只是指向数据对象标识,真正的数据是存储在DB中,所以查询速度极快。但是额外的内存与硬盘花销也是一个需要考虑的问题。比如:增加、删除、修改时数据库都要对索引进行维护,但是这样也是为了最后查询的效率的提升,特别适合W行级别的数据查询。而索引可以分为:隐式索引(针对单个字段)、唯一索引(唯一约束)、函数索引(函数(字段))与聚簇索引clusrered(主键)。
<1>视图创建索引
<2>代码创建索引
①:隐式索引:
create index ixTableColumn on table(column)
②:唯一索引
不允许具有索引值相同的行,从而禁止重复的索引或键值。系统在创建该索引时检查是否有重复的键值,并在每次使用 INSERT 或 UPDATE 语句添加数据时进行检查建立唯一约束的时候自动生成(而且unique关键字是可以用在聚簇与非聚簇索引中的)
create unique index ixTableColumn on table(column)
③:函数索引(函数(field)):
create index ixTableColumn on table( upper(column)) ;
④:聚簇索引
使用聚簇索引查找数据几乎总是比使用非聚簇索引快。每张表只能建一个聚簇索引,并且建聚簇索引需要至少相当该表120%的附加空间,以存放该表的副本和索引中间页。
一般使用对象:主键列,该列在where子句中使用并且插入是随机的;按范围存取的列,如pri_order > 100 and pri_order < 200;在group by或order by中使用的列;不经常修改的列;在连接操作中使用的列。
create clustered index ixTableColumn table(column)
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
但是此时如果表中有重复的记录,当你试图用这个语句建立索引时,会出现错误。
有重复记录的表也可以建立索引;你只要使用关键字allow_dup_row
create clustered index ixTableColumn table(column) with allow_dup_row
⑤:组合索引
对N个字段建立了一个索引。在一个复合索引中,你最多可以对16个字段进行索引。
create index ixTableColum1Column2 ON table(column1,column2)
⑥:全文索引(针对超长文本,一般是博文 text):
sql数据库入门 SQL数据库基础知识集合

全文索引条件:表中的含有唯一约束(唯一索引)的列可以升级为全文索引,但是每个表只可以有一个全文索引,存放在指定的索引目录里,可以通过向导创建,也可以通过SQL创建。(www.61k.com)
1、 启动全文索引
use MoviesDB;
exec sp_fulltext_database 'enable'
2、创建全文目录(fulltext catalog 存放全文索引的文件)
create fulltext catalog ixCatalog
3、创建唯一索引 (unique)
create unique index ixTableColumn1 on table(column)
4、创建全文索引 (fulltext index)
create fulltext index on table(column1,column2)key index ixTableColumn1 on ixCatalog
注:ixTableColumn1是指已存在的基于指定表的唯一索引名.而不是唯一索引列名.如果索引不存在,需要先创建唯一索引.
代码创建索引成功后回出现:This command did not return data,and it did not return any rows (此命令不会返回行数据)
5、使用全文索引 (select contain freetext)
主要使用contains,freetext进行查询假设已有一个表table,已为字段field 创建全文索引,那么要查询含有周杰伦或者jay的所有记录的语句为:
select * from table where contains(fieldname,'"周杰伦" or "jay"')
也可以使用匹配模式进行包含条件组合,还可以使用and连接条件.
<3>使用索引
索引一旦创建成功,需要修改时必须先删除再创建:
一般执行查询的时候数据库系统会自动调用索引。
Drop index table.ixTableColumn
<4>全文索引扩展(使用系统存储过程)
1、 库
exec sp_fulltext_database 'enable'—启用全文索引功能
2、 目录
exec sp_fulltext_catalog 'ixTableColum','drop'--删除
exec sp_fulltext_catalog 'ixTableColum','create'--创建
3、表
exec sp_fulltext_table 'table','create','catalog','column'--创建
exec sp_fulltext_table 'table','active','catalog','column'—启动
exec sp_fulltext_table 'table','start_full','catalog','column'—同上
exec sp_fulltext_table 'table','deactive','catalog','clumn'—冻结
exec sp_fulltext_table 'table','drop','catalog','clumn'—删除
4、列
exec sp_fulltext_column 'table','column','add'--添加
exec sp_fulltext_column 'table','column','drop'—删除
5、检查填充情况
While fulltextcatalogproperty('catalog','populateStatus')<>0--检查全文目录填充情况
begin
waitfor delay '0:0:5'--如果全文目录正处于填充状态,则等待秒后再检测一次
END
6、使用全文索引(调用关键字contain、freetext)
select * from table where contains(columnname,'美赞臣'or ‘宝洁’) –显式使用全文索引查询
29、创建事务
很多时候我们的操作都不是一步完成的,而是由多次的修改插入删除所完成的
在银行数据库里面 ,张三存了1W ,那么转账呢? 那么得至少写两条SQL语句 防止程序出现灾难与数据错误,所以在高度自动化的时代,我们就必须搞好。五角大楼的事务例子,
sql数据库入门 SQL数据库基础知识集合
利用计算机技术去处理,
一般是从4个方面去理解。(www.61k.com)ACID
A、 原子性 就是执行的时候要么整个完成,要么整个失败,就是两条语句构成一个整体,C#是不支持的,而且不论什么状态下都高度保持这样的原子性
B、一致性 指的是数据库是一条条的执行,但是在外部观察不会出现瞬时的不同步,也就是说我们在任何时候查询数据库,就是转得时候也是已经完成业务的(不论什么时候查询,都是保持一致的,就是业务都是执行完毕的,保证瞬时执行的完整性)
I、隔离性 就是虽然是一条条地改,但是对于事务外的对象是完全隔离的,但是外部查询是依赖于一致性的,在事务之外是查询不到的。但是Oracle是可以做到的,还是可以直接查询
D、持久性 一旦事务提交成功那么堆事务的修改是持久更新的,不会因为断电而悲剧。将被持久地存下来。需要DBA提供后备的支持的。支持多种方式的,分布式的话,就是同时在4个地方存储,银行不是那么低级地存得,要求全部都是实时的备份
create database myBankDB;
use myBankDB;
create table bank
(
账户 int identity(1,1),
存款 int
)
begin transaction
insert into bank values(10000);
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
insert into bank values(10000);
insert into bank values(10000);
select * from myBankDB.dbo.bank;
update myBankDB.dbo.bank set 存款=20000 where 账户>10 and 账户<55;
delete from myBankDB.dbo.bank;
commit;
rollback;
开始执行了begin transaction
再执行一半的语句这个时候
停止服务rollback,就会返回原来执行那一条的状态
直到运行至commit才完成事务,要不系统自动回滚
ALTER procedure [dbo].[prReturnDisk]
(
@EmployeeID int,
@RentRecordID int,
@Account int
)
as
declare @AccountRecordCode nvarchar(50)
declare @RentRecordState int
declare @DiskID int
declare @DateStrat datetime
declare @DateEnd datetime
declare @Cost float
begin try
begin transaction
select @AccountRecordCode=MAX(AccountRecordID)+1 from tbl_Account;--获取编号
select @RentRecordState=tbl_RentRecord.RentRecordState from tbl_RentRecord;--判断租借记录
if @RentRecordState = 1
begin
insert into tbl_Account (AccountRecordCode,EmployeeID,RentRecordID,Account)
values('Account'+@AccountRecordCode,@EmployeeID,@RentRecordID,@Account);--还碟子
update tbl_RentRecord set RentRecordState=0,RentRecordDateEnd=GETDATE() where RentRecordID=@RentRecordID;
select @DiskID=DiskID,@DateStrat =RentRecordDateStart,@DateEnd=RentRecordDateEnd from tbl_RentRecord where
RentRecordID=@RentRecordID;
select @Cost=((dbo.fnGetDate(@DateStrat,@DateEnd))*(select tbl_Disk.DiskCharge from tbl_Disk where DiskID=@DiskID)); update tbl_Disk set DiskState=0,RentRecordID=0 where DiskID=@DiskID;
if @Account>@Cost
begin
update tbl_Associator set AsscciatorBalance=AsscciatorBalance+(@Account-@Cost) where AsscciatorID=(select AsscciatorID from tbl_RentRecord where RentRecordID=@RentRecordID);
end
end
commit;
end try
begin catch
rollback
end catch
sql数据库入门 SQL数据库基础知识集合

30、创建存储过程
不同的数据库的语言也是不同的,MSSQL的是TSQL ,存储过程一般是解决复杂的业务逻辑操作(一般是多表的操作)的问题。(www.61k.com]Oracle的PLSQL。在oracle就没有返回值,但是MSSQL有。返回值不是普通的返回值,这个一般不返回计算的结果,一般仅仅是返回整数的类型,若果没有显示返回结果,默认为返回0,一般是判断存储过程的执行状态。
<1>单纯的传参
create procedure proc_test
(
@NewName nvarchar(20),
@OldName nvarchar(20)
)
as
begin transaction
begin try
if exists (select Movie_Name from tbl_Movies)
return 0;
commit;
else
begin
rollback;
end
end try
<2>传参与返回值output
create procedure proc_test
(
)
as
begin transaction
begin try
--scope_identity()--标识当前作用域中新创造的主键
--insert之后马上获取当前状态的唯一标识的问题
declare @key int;
set @key =scope_identity();--赋值
select @key=scope_identity();--赋值
--但是临时变量@key仅仅在与自己的作用域中,要赋值给传出参数
set @number = @key;
commit;
end try
begin catch
rollback;
end catch
--执行
declare @Pan int;
execute @Pan = proc_test 'a','B','C',@number output;
print @Pan;--打印,return的
print @number;--返回的
执行存储过程的名字
Execute proc_name parmmarys ; @NewName nvarchar(20), @OldName nvarchar(20), @Name nvarchar(30), @number int output
Execute proc_UpdateName '精武门','新版精武门' ;
31、创建触发器
触发器(trigger)是个特殊的存储过程, 它的执行不是由程序调用,也不是手工启动,而是由事件来触发,比如当对一个表进行操作( insert,delete, update)时就会激活它执行。触发器经常用于加强数据的完整性约束和业务规则等。 触发器可以从 DBA_TRIGGERS ,USER_TRIGGERS 数据字典中查到。
触发器可以查询其他表,而且可以包含复杂的 SQL 语句。它们主要用于强制服从复杂的业务规则或要求。例如:您可以根据客户当前的帐户状态,控制是否允许插入新订单。 触发器也可用于强制引用完整性,以便在多个表中添加、更新或删除行时,保留在这些表之间所定义的关系。然而,强制引用完整性的最好方法是在相关表中定义主键和外键约束。如果使用数据库关系图,则可以在表之间创建关系以自动创建外键约束。
触发器,可以自己定义,一类是系统级触发器(数据库系统级别),一类是表触发器。
alter trigger [dbo].[tbl_Employee_AspNet_SqlCacheNotification_Trigger]
on [dbo].[tbl_Employee]
for insert, update, delete
as
sql数据库入门 SQL数据库基础知识集合
begin
set nocount on
exec dbo.AspNet_SqlCacheUpdateChangeIdStoredProcedure N'tbl_Employee'
end
微软在framework4.0中asp.net_regsql.exe用命令行执行 C:WindowsMicrosoft.NETFrameworkv4.0.30319aspnet_regsql.exe aspnet_regsql –S WIN-0E92J4Q2A85 –E –d MoviesDB –ed ——启动依赖项
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
aspnet_regsql –S WIN-0E92J4Q2A85 –E –d MoviesDB –lt ——显示监听表
aspnet_regsql –S WIN-0E92J4Q2A85 –E –d MoviesDB –t tablename –et ——为表建立监听触发器
32、时间函数
参考网址:
<1>datepart部分时间提取函数,返回表示指定 date 的指定 datepart 的整数。[www.61k.com)
datepart (datepart,”datetime”)
SELECT DATEPART(YY,'2007-10-30 12:15:32.1234567 +05:10')
datediff(datepart,stratdate,enddate)
<2>datediff时间间隔函数,返回指定的 startdate 和 enddate 之间所跨的指定 datepart 边界的计数(带符号的整数)。
扩展:sql数据库基础知识 / 数据库基础知识 / oracle数据库基础知识
本文标题:数据库基础-肯尼亚山:肯尼亚山-基础数据,肯尼亚山-地理环境61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1