一 : 调控一体化资料整理和分析 65
调控一体化资料整理和分析
编写:孙一民 2011-03-01
1. 前言
调控一体化是当前比较热的技术概念,通过百度收集了一些论文。这些论文80%以上与配网调控一体化相关,其他部分和变电调控一体化相关。查阅《国家电网智能化规划总报告》,调控一体化概念确实是针对10kV及配电网;变电的规划目标是智能化。国网还颁布了一个针对调控一体化的技术规范:《配网调控一体化管理规范》。《国家电网智能化规划总报告》对于智能电网的分环节投资规划如下:
配电投资规模略大于变电。调控一体化概念业内是如何解读的,大体有如下几种:
? 将调度及变电运行管理模式改为“调控中心+运维操作站”模式。
? 调控一体化工作将完成变电站无人值班改造,大幅提高电网自动化水平,实现电网调度业
务和运行监控业务的融合。
? 强化电网运行管理,优化业务流程,提高工作效率和电网事故快速处置能力,电网集约化
管理水平会得到全面提升。
? 将电网监控和调度发令进行整合,形成“调控中心+操作班”模式,将使路桥电网调度逐步
告别传统管理模式,向着实现调度、监视、操作一体化,集约化、精益化的目标模式转变。
2. 调控一体化概念模型
实现调度、监视、操作一体化,集约化、精益化的目标模式,变电站端实现无人值班。调控一体化的技术平台需要哪些支持,这是我们关注的重点。从网上收集了一些工程案例,归纳如下:
? 数据一体化
SCADA/EMS 系统采集稳态数据,PMU 采集动态数据,故障录波器采集暂态数据,是电网数据采集的现状。电子式互感器和时间同步服务器的成熟应用,数据采集的三个专项功能将进行一体化整合。整合的结果就是《智能电网关键设备规划》所描述的测控装置。三态数据的一体化要求数据库管理系统应是关系数据库和动态数据库的组合。
? 平台一体化
基础平台需支持电网实时监控、调度计划、安全校核和调度管理四大类核心应用。目前EMS系统、WAMS系统、动态预警系统、负荷预测系统、发电计划安全校核系统都是各自独立的系统。这些子系统的平台统一就有如下优势:
1) 集成各种量测数据,简化接口设计。
2) 实现一体化维护,减轻维护工作量。
3) 实现一体化监视和操作,方便使用。
4) 共享硬件资源,减少硬件投资。
? 五防一体化
五防作为独立的系统运行,已不能满足调控一体化的要求。五防和监控系统的一体化,将简化操作的环节,实现集约化管理。
? 操作程序化
调控一体化操作跨越多个电压等级,对操作人员的经验和知识要求很高。程序化操作将操作流程、知识和经验通过程序来实现,通过自动化水平的提高,防范误操作事件的发生。 ? 界面规范化
多个变电站的操作集中到调度端,在调度端实现了人机界面的统一。变电站端的维护工作站如果不能实现界面的统一,将增加运维人员操作的难度。
? 安防综合化
无人值守变电站的安全防范已经成为安全生产自动化的重要组成部分,通过变电站安全防范系统不仅可以远程巡视各类设备的运行情况、人员的操作记录,还能实时获得来自事故现场的报警信息,对可能或已经发生的异常现象及时处理并保存现场的图像资料,为分析事故原因提供第一手的资料。安防综合系统由五大子系统组成:
1) 环境监测
2) 遥视
3) 火灾报警
4) 安防报警
5) 门禁识别
? 检修状态化
在线监测系统对变电站高压设备已经发生、正在发生、或可能发生的故障进行分析、判断和预报,明确故障的性质、类型、程度和原因,指出故障发展的趋势及后果,提出控制故障发展和消除故障的有效对策。将设备检修策略从常规的“定期检修“变成“状态检修“。变电站在线监测系统分类:
1) 变压器在线监测
2) 电容型设备在线监测
3) ZnO避雷器在线监测
4) 断路器在线监测
5) GIS设备在线监测
3. 需求分析
需求分析侧重于变电站侧,因为我们的产品主要是面向变电站。调度端及配网主站部分将由南
京配网事业部组织相关人员进行需求分析。 3.1. 数据一体化
三态数据的一体化是智能电网的大势所趋,前面也谈到了目前的现状是三态数据由三种不同的装置来采集。三态数据的一体化依赖于电子式互感器,最近得到一个消息:南瑞集团正在积极研制基于物联网的非电磁感应式有源电子式互感器。这部分市场和电子式互感器是密不可分的关系。从变电站侧来看,动态数据库肯定在运维工作站或一体化信息平台。动态数据库目前有2个知名的系统:PI数据库和eDNA数据库。这两个数据库本质上全是纯文件系统的存储方式,主要是面向数据。变电站侧数据存储在何处?这个问题应该会分两个阶段:过渡阶段和全面建设阶段。过渡阶段期间,三态数据会存放在变电站的运维工作站。全面建设阶段三态数据会存储在一体化信息平台。在《智能电网关键设备研制规划》中,明确要求一体化信息平台是嵌入式系统。PI和eDNA数据库的嵌入式平台应用开发能否成功,决定了一体化信息平台开发的成败。
3.2. 平台一体化
平台一体化是对调度和配网主站端的要求,变电站侧没有具体的需求。
3.3. 五防一体化
一体化五防的技术规范,在南网已经实施了一年多。传统五防厂家的产品只剩下五防锁具和地线管理系统。在线式五防和微机五防相比具有很多优势,目前推广是否顺利取决于在线五防锁具的可靠性。
3.4. 操作程序化
要实现调控一体化就必须先实现操作程序化,程序化操作在全国已有很多成功的运行案例。
3.5. 界面规范化
去年广电在积极地推进界面统一规范的科技项目,在南方电网要实现这一点比较容易,但是国网还没有相关的规范,更没有试点地区。
3.6. 安防综合化
无人值守变电站,必须配置安防系统。安防系统能否顺利和全面地推广取决于安防解决方案和系统集成的成本。安防的市场应该很大,江苏省的安防系统一直由一个三产公司承建,安防系统的市场和商务部分还需要仔细地调研。
3.7. 检修状态化
在线监测在南网推进的力度比较大,但可以合作的在线监测设备供应商只有少数几家。我们公司只研制了高压测温产品,埋地电缆的光栅测温系统还在积极地调研中。
4. 技术可行性分析
4.1. 数据一体化
三态数据一体化的推进力度取决于电子式互感器的技术成熟度。与之相关的测控装置的技术:
1) 嵌入式实时数据库PI、eDNA的应用
2) 故障录波
3) PMU
的预研和技术储备工作要尽快开展,争取主动。 4.2. 五防一体化
在线式五防和现有的一体化五防相比,在调控一体化模式中,更能体现集约化管理的优势。我们已经有在线式五防的工程经验,如何更紧密地和在线式五防锁具厂家合作,发挥我们的技术优势,是我们应该关注的重点。
4.3. 操作程序化
公司在程序化操作的工程经验和技术储备还是比较深厚。程序化操作目前有2种模式:远动工作站模式和间隔测控装置模式。这两种模式的应用技术需要总结、提升和沉淀。程序化操作没有立项,但应该做一次完整地生产移交。
4.4. 界面规范化
界面规范化存在地区版本的差异,并且是由客户驱动的。我们应尽快高质量地实现广电的界面技术规范,做好版本管理和模块的兼容设计。
4.5. 安防综合化
安防综合化对公司来说是一个全新的项目,准备就安防出一套完整的解决方案,在此就不赘述。
4.6. 检修状态化
在线监测对公司来说是一个全新的项目,准备就在线监测出一套完整的解决方案,在此就不赘述。
二 : 中文转换为完整拼音算法原理分析
最近由于项目需要,对简体中文转拼音的算法作了一些了解,然而在google找到的大多是获得简体中文拼音首字母的算法,好不容易让我找到了一个sunrise.spell的类,专门用于中文转完整拼音,觉得的确做得不错,于是对它的算法作了一些分析,总的来说觉得还是比较简单的,拿出来与大家分享。[www.61k.com)
我们先来学习一些准备知识。GB2312编码对于我们中国人是再熟悉不过了,我先简单的分析一下它的编码规则。GB2312编码包括符号、数字、字母、日文、制表符等,当然最主要的部分还是中文,它采用16位编码方式,简体中文的编码范围从B
通 过上面的方法,我们就可以通过一个二维坐标对每一个中文字进行定位,从而建立一个二维表来实现中文和拼音的对应关系。当然我们会忽略一些特殊情况,比如汉 字的多音字问题。由于一个拼音可能对应多个汉字,而拼音的组合本来就不多,因此我们首先建立一个拼音音节表,代码如下,里面列出了所有可能的组合情况,该 表是一维数组。
readonly static string[] _spellMusicCode = new string[]{
"a", "ai", "an", "ang", "ao", "ba", "bai", "ban", "bang", "bao",
"bei", "ben", "beng", "bi", "bian", "biao", "bie", "bin", "bing", "bo",
"bu", "ca", "cai", "can", "cang", "cao", "ce", "ceng", "cha", "chai",
"chan", "chang", "chao", "che", "chen", "cheng", "chi", "chong", "chou", "chu",
"chuai", "chuan", "chuang", "chui", "chun", "chuo", "ci", "cong", "cou", "cu",
"cuan", "cui", "cun", "cuo", "da", "dai", "dan", "dang", "dao", "de",
"deng", "di", "dian", "diao", "die", "ding", "diu", "dong", "dou", "du",
"duan", "dui", "dun", "duo", "e", "en", "er", "fa", "fan", "fang",
"fei", "fen", "feng", "fu", "fou", "ga", "gai", "gan", "gang", "gao",
"ge", "ji", "gen", "geng", "gong", "gou", "gu", "gua", "guai", "guan",
"guang", "gui", "gun", "guo", "ha", "hai", "han", "hang", "hao", "he",
"hei", "hen", "heng", "hong", "hou", "hu", "hua", "huai", "huan", "huang",
"hui", "hun", "huo", "jia", "jian", "jiang", "qiao", "jiao", "jie", "jin",
"jing", "jiong", "jiu", "ju", "juan", "jue", "jun", "ka", "kai", "kan",
"kang", "kao", "ke", "ken", "keng", "kong", "kou", "ku", "kua", "kuai",
"kuan", "kuang", "kui", "kun", "kuo", "la", "lai", "lan", "lang", "lao",
"le", "lei", "leng", "li", "lia", "lian", "liang", "liao", "lie", "lin",
"ling", "liu", "long", "lou", "lu", "luan", "lue", "lun", "luo", "ma",
"mai", "man", "mang", "mao", "me", "mei", "men", "meng", "mi", "mian",
"miao", "mie", "min", "ming", "miu", "mo", "mou", "mu", "na", "nai",
"nan", "nang", "nao", "ne", "nei", "nen", "neng", "ni", "nian", "niang",
"niao", "nie", "nin", "ning", "niu", "nong", "nu", "nuan", "nue", "yao",
"nuo", "o", "ou", "pa", "pai", "pan", "pang", "pao", "pei", "pen",
"peng", "pi", "pian", "piao", "pie", "pin", "ping", "po", "pou", "pu",
"qi", "qia", "qian", "qiang", "qie", "qin", "qing", "qiong", "qiu", "qu",
"quan", "que", "qun", "ran", "rang", "rao", "re", "ren", "reng", "ri",
"rong", "rou", "ru", "ruan", "rui", "run", "ruo", "sa", "sai", "san",
"sang", "sao", "se", "sen", "seng", "sha", "shai", "shan", "shang", "shao",
"she", "shen", "sheng", "shi", "shou", "shu", "shua", "shuai", "shuan", "shuang",
"shui", "shun", "shuo", "si", "song", "sou", "su", "suan", "sui", "sun",
"suo", "ta", "tai", "tan", "tang", "tao", "te", "teng", "ti", "tian",
"tiao", "tie", "ting", "tong", "tou", "tu", "tuan", "tui", "tun", "tuo",
"wa", "wai", "wan", "wang", "wei", "wen", "weng", "wo", "wu", "xi",
"xia", "xian", "xiang", "xiao", "xie", "xin", "xing", "xiong", "xiu", "xu",
"xuan", "xue", "xun", "ya", "yan", "yang", "ye", "yi", "yin", "ying",
"yo", "yong", "you", "yu", "yuan", "yue", "yun", "za", "zai", "zan",
"zang", "zao", "ze", "zei", "zen", "zeng", "zha", "zhai", "zhan", "zhang",
"zhao", "zhe", "zhen", "zheng", "zhi", "zhong", "zhou", "zhu", "zhua", "zhuai",
"zhuan", "zhuang", "zhui", "zhun", "zhuo", "zi", "zong", "zou", "zu", "zuan",
"zui", "zun", "zuo", "", "ei", "m", "n", "dia", "cen", "nou",
"jv", "qv", "xv", "lv", "nv"
};
首先输入汉字“我”,首先程序初始化一个GB2312编码对象
System.Text.Encoding encoding = System.Text.Encoding.GetEncoding("GB2312");
然后通过该对象获得“我”的编码数组
byte[] local = encoding.GetBytes(“我”);
local中的值应该是local[0]=206; local[1]=210
假设我们的二维数组叫_spellCodeIndex那么我们就通过_spellCodeIndex[local[0]-129,local[1]-64]获得“我”对应的拼音音节索引值,即327
再查音节组合表,得索引327对应的是"wo",这样就完成了中文到拼音的转换
完整c#类可以在这里下载。
三 : H.264整数DCT公式推导及蝶形算法分析
这是网上的一篇文章, 我重新读了一下, 然后做了一些整理
1.为什么要进行变换
空间图像数据通常是很难压缩的:相邻的采样点具有很强的相关性(相互关联的),而且能量一般平均分布在一幅图像中,从而要想丢掉某些数据和降低数据精度而不明显影响图像质量,就要选择合适的变换,方法,使图像易于被压缩。[www.61k.com)适合压缩的变换方法要有这样几个性质:
(1).可以聚集图像的能量(将能量集中到少数有意义的数值上),如下图:
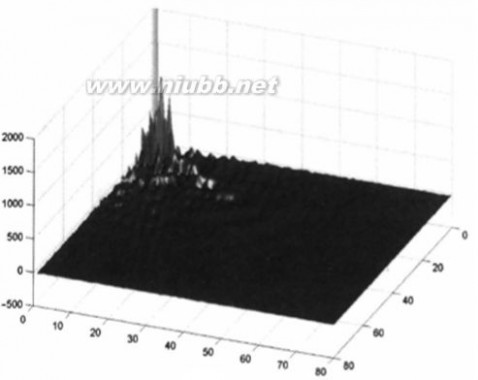
举个例子说明, 左图是变换前的数据, 右图是变换后的数据:
可以看出,经变换后,数据的能量基本上集中到左上方(低频信号)了,而变换后的数据完全可以通过反变换还原成原来的数据。为了达到压缩文件的目的,我们就可以丢弃掉一些能量低的数据(高频信号),而对图像质量影响很小。
2.具体变换过程
4x4的DCT变换矩阵如下:

这样我们就得到了,如下矩阵:

进行推导得到如下:
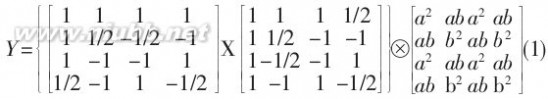
在上式中, 虽然乘以 1/2 的操作可以用右移来实现 , 但这样会产生截断误差 . 因此, 将1/2提到矩阵外面, 并与右边的点乘合并, 进而得到如下的算式:

在JM编码器中,变换过程只包括了
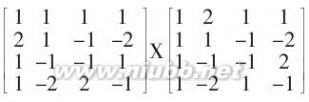
后面的点乘实际上是在量化过程中进行,因为后面的点乘还有实数运算,实数运算将不可避免地产生精度误差,而且运算量巨大。而量化本身就会丢失一些信号,因些,这些实数运算放在量化过程中将大大的降低变换的运算率同时又不明显影响精度?
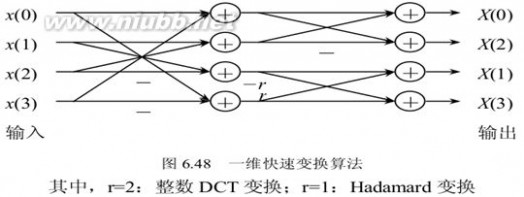
然而,4X4的矩阵运算如果按常规算法的话仍要进行64次乘法运算和48次加法,这将耗费较多的时间,于是在H.264中,有一种改进的 算法(蝶形算法)可以减少运算的次数。这种矩阵运算算法构造非常巧妙,利用构造的矩阵的整数性质和对称性,可完全将乘法运算转化为加法运算.
这里来分析一下蝶形算法,这个蝶形算法和一般FFT的蝶形算法不同,由于我没有找到相关论文,能找到的书和网络资料又语焉不详,只好自己推导。上面的JM代码就是计算下面三个4x4矩阵的过程。
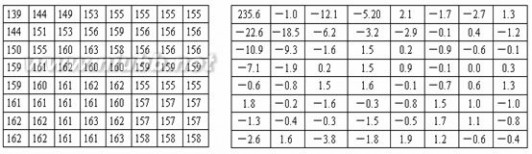
分析一下前两个矩阵的乘法,只分析他们结果矩阵的第一列。有什么办法可以减少运算量呢?首先采用传统方法计算,得到结果:
X[0] = x[00]+x[10]+x[20]+x[30]
X[1] = 2*x[00]+x[10]-x[20]-2*x[30]
X[2]= x[00]-x[10]-x[20]+x[30]
X[3] = x[00]-2x[10]+2x[20]-x[30]
计算代价是16次乘法12次加法,考虑到矩阵的1的乘法可以省略,去除8个乘1,还需要8次乘法和12次加法。那么我们再仔细思考他们的相 关性,从一般算法意义上来说,可以用空间代价换时间代价,比如设置中间变量来减少计算次数。用不同的颜色把需要重复运算的部分标上,作为中间变量。
X[0] = x[00]+x[10]+x[20]+x[30]
X[1] = 2*x[00]+x[10]-x[20]-2*x[30]
X[2]= x[00]-x[10]-x[20]+x[30]
X[3] = x[00]-2x[10]+2x[20]-x[30]
那么提取出来的中间变量将是:
x[00]+x[30]
x[00]-x[30]
x[10]+x[20]
x[10]-x[20]
存储了这四个中间变量,我们对比看看蝶形图,和图中第一层的算式相符合。用这些中间变量来组合,就可以把最终的X[0]..X[3], 计算出来。这样,就把运算量降低到2个乘法和8个加法,剩余的运算就是叠代这个算法。
所以,可以得出以下结论:
在JM8.6代码中这个碟形算法, 出现的地方很多, 只要牵扯到变换, 就有这种算法. 包括Hadamard变换. 在多个函数中出现, 其实现是一样的.
H.264中DCT变换中所使用的蝶形算法
然而,4X4的矩阵运算如 果按常规算法的话仍要进行64次乘法运算和48次加法,这将耗费较多的时间,于是在H.264中,有一种改进的算法(蝶形算法)可以减少运算的次数。这种 矩阵运算算法构造非常巧妙,利用构造的矩阵的整数性质和对称性,可完全将乘法运算转化为加法运算。
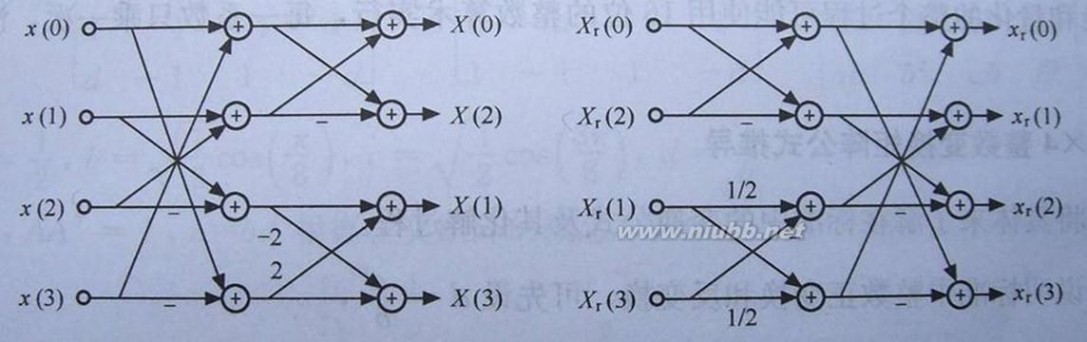

扩展:h264 dct / 整数dct变换 / 整数dct

变换过程在JM中代码实现如下:
// Horizontal transform水平变换,其实就是左乘Cf,
for (j=0; j < BLOCK_SIZE && !lossless_qpprime; j++)
{
for (i=0; i < 2; i++)
{
i1=3-i;
m5[i]=img->m7[i][j]+img->m7[i1][j];
m5[i1]=img->m7[i][j]-img->m7[i1][j];
}
img->m7[0][j]=(m5[0]+m5[1]);
img->m7[2][j]=(m5[0]-m5[1]);
img->m7[1][j]=m5[3]*2+m5[2];
img->m7[3][j]=m5[3]-m5[2]*2;
}
// Vertical transform垂直变换,其实就是右乘CfT
for (i=0; i < BLOCK_SIZE && !lossless_qpprime; i++)
{
for (j=0; j < 2; j++)
{
j1=3-j;
m5[j]=img->m7[i][j]+img->m7[i][j1];
m5[j1]=img->m7[i][j]-img->m7[i][j1];
}
img->m7[i][0]=(m5[0]+m5[1]);
img->m7[i][2]=(m5[0]-m5[1]);
img->m7[i][1]=m5[3]*2+m5[2];
img->m7[i][3]=m5[3]-m5[2]*2;
}
Xkfz007
2011年9月6日 14:09:22
扩展:h264 dct / 整数dct变换 / 整数dct
本文标题:资料分析计算公式整理-调控一体化资料整理和分析 6561阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1