一 : 34%的Facebook外部流量来自谷歌等搜索引擎

PageLever发布的报告图标
新浪科技讯 北京时间8月29日下午消息,根据美国创业公司PageLever发布的最新调查,有超过三分之一的Facebook外部流量是来自搜索引擎,所以搜索引擎优化对于Facebook来说十分重要。
该调查由PageLever的杰夫·魏德曼(Jeff Widman)负责,他通过Facebook应用程序接口(API)来收集外部流量原始数据,并使用PageLever分析工具来组织数据并分离搜索引擎 推荐数据。在今年1月1日到6月30日期间,魏德曼查看了至少10,000名用户的1000个网页访问数据。
结果显示,33.98%的外部流量是来自谷歌、雅虎和必应搜索引擎,其中谷歌流量占据27.57%,雅虎占据4.11%,必应占据2.3%。该搜索引擎流量在Facebook全部流量中的比重为9.5%。
虽然PageLever的此次研究并不是主要对搜索引擎优化进行的调查,但结果表明搜索引擎优化对于外部流量和整体页面访问量来说十分重要。(晓明)
二 : 基于内容的图片搜索引擎
1、项目背景及研究目的和意义
项目背景:
图像是用各种观测系统以不同形式和手段观测客观世界而获得的,可以直接或间接作用于人眼并进而产生视知觉的实体,科学研究和统计表明,人类从外界获得的信息约有75%是从图像中获得的[1]。通过绘画或摄影、摄像得到的图像是人类获取信息的重要手段,这些图像以雕刻或纸张印刷的形式保留下来便于人们浏览、查询。但是当计算机以及互联网出现时,图像的浏览、查询发生了根本性的变化。图片搜索也在人们的生活中越来越普及化,因此目前图片搜索引擎很发达,而图片搜索主要分为基于文本的图片搜索引擎、基于内容的图片搜索引擎以及基于语义的图片搜索引擎。其中最为成熟的是基于文本的图片搜索引擎,基于文本的图片搜索引擎的搜索方式是以文本为关键字进行图片搜索。
在基于文本的图片搜索技术研究的早期,图片被作为数据库中存储的一个对象,并人工地用文本对其进行描述。这种方法比较简单易行,一般是使用数据库管理系统(DBMS)来实现,当然,这种方式的缺点也是很明显的:一是需要人工对图片进行注释,工作量相当大,特别是图片数据量非常大时,人工标注是不切实际的;二是人工标注不可避免的会带来主观性和不精确性,因为不同的人对同一幅图片的理解可能是不相同的。所以说在互联网环境下,对网上的海量图片数据进行人工注释是不现实的。
随着信息搜索技术的不断成熟,互联网网页信息自动采集和标引作为搜索引擎的重要组成部分,也得到了深入的研究,首先是广泛应用于文本搜索引擎中,同时也使用来对图片搜索引擎技术进行改进,因为,与文件系统中独立的图片文件不同,互联网上的图片是作为网页的一部分出现的,具有相关的上下文环境,图片所在网页的标题、图片的提示文字、图片的文件名称、与图片密切环绕的文字以及网页中的其它文字,都可以作为对图片进行描述的依据。目前谷歌、雅虎、百度提供的图片搜索服务,都主要是基于这种技术的。
然而,利用网页上的文字来对网页中的图片进行标注,是非常困难、非常不 精确的。例如说这样一个情况:有一个主题为“奥巴马打蓝球遭肘击缝 12 针,太岁头上动土谁如此大胆”的网页,页面中开头位置放置有一张奥巴马刚缝完针的照片,当用户输入“篮球”作为关键词,希望得到一些篮球的特写图片,结果
却把奥巴马的这张照片搜索出来了。这就是用网页文字内容对图片进行自动标注造成的不准确的结果。因此基于内容的搜索引擎是目前搜索引擎技术发展的一个重要课题。
基于内容的搜索引擎尝试直接分析图片文件,将它们根据特征分类。用户可以通过提交一幅图片来表达自己的搜索意图(比如用户希望能够搜索到含有类似图片的网站),搜索引擎系统通过对用户提交的图片文件进行分析、比对,输出检索到的信息。目前,基于内容的图片搜索引擎还处在探索阶段,目前还不存在得到广泛运用的通用搜索引擎[2]。有一些研究机构正在尝试从事特定范围的基于内容的图片搜索引擎研究,如针对特定的图片资料库建立搜索引擎,或者对特定类型的图片资料进行检索等[3]。
鉴于基于内容的图片搜索引擎的重要性,国内外已纷纷投入人力财力物力广泛开展研究并研制成一些系统[4,5]。
Virage公司的VIR(Visual Information Retrieval)图像引擎提供了四种可视属性进行图像的检索(颜色、成分、纹理、形状)[13]。每种属性被赋予0到10的权值。该软件对选出的基础图像的色调、色彩以及饱和度进行分析,然后再图像库中查找与这些颜色属相相近的图像。成分特性是指相关颜色区域的近似程度。用户可设定一个或多个属性的权值优化检索。由于要在众多图像特征中配比权值,所以VIR仍然算是一种需要人为参与的图像检索系统。
国内对于图片搜索系统研究相对较晚。国防科技大学的多媒体信息查询和检索系统MIRC,描述了多媒体内容和结构特征以及信息检索数据模型,支持基于内容的多媒体信息查询和检索[6]。根据用户提供的图像或视频帧例子,基于颜色和轮廓特征进行查询。浙江大学的基于内容多媒体检索系统WebscopeCBR,支持基于关键字、全局颜色、局部纹理、对象形状、颜色布局、纹理布局等的查询。但在系统中众多的图像特征依然是独立的状态,未能有效的联合众多图像特征进行检索。
本项目将对现阶段基于内容的图片搜索引擎进行优化、改进,减少人为参与所带来的搜索结果的不准确性。
研究目的和意义:
文本信息无法完全描述图片信息的矛盾已非常显著,人们对于搜索引擎的准确率的要求正随着互联网数据量的增长而提高,因此传统的图片搜索引擎就很难满足需求,相似图片搜索引擎应运而生。
一般的图片搜索引擎通过对图象信息的文字描述来进行检索,而且对于用户来说,不可能在查询时候很精确地用文字对图象进行合理的描述,因此提高查询结果的准确率显得尤为重要。
相似图片搜索是一种新的在线图片搜索引擎:不像其它图片搜索引擎是根据提交的关键字进行搜索,而是根据上传的图片去搜索相似的图片。相似图片搜索是用颜色、纹理、形状以及区域等视觉特征,根据例图在大量图像中集中进行检索,实现了图像视觉特征的检索。这种以图搜图的查询模式是对“以关键字搜图”的一大突破[7]。
基于内容的图片搜索引擎能广泛应用于遥感图像处理、空间探测、医疗图片检索、商标图片检索、建筑工程图、天气预报、公安图像侦查、艺术馆藏资料管理和数字化图书馆等许多领域。伴随着Internet的发展,多媒体数据特别是数字图像信息成为网上的重要资源,而这些资源的内容检索都离不开基于内容的图片搜索引擎技术[8]。
2 项目研究目标、研究内容和拟解决的关键问题
研究目标:
本项目主要研究“以图搜图”的搜索方式,对图像特征提取进行深入分析。完成对图像区域分割、图像特征提取和相似度对比的设计与实现,从而提出一套完整的系统设计方案,并且实现一个初步的基于内容的图片搜索引擎系统。由于图像处理的计算量较大,本项目拟使用分布式计算提高速度。
基于本项目的研究,将能够向“以图搜视频”这一良好的发展前景迈进一步。 研究内容:
1、图像区域分割
本项目拟用图像区域分割方法先将图片分割成多个区域,再对每个区域进行图像特征提取并与对应区域进行对比。相对于直接对整张图片进行特征提取而仅仅对比一次而言,本项目先分割后提取、对比的方法能够提高图片搜索的准确率。
2、图像特征提取
图片搜索需要对两张图片进行对比,但如果逐像素对比会消耗大量时间,所以本项目先对图像进行特征提取,通过特征进行对比,从而提高搜索速度。本项目将采用感知哈希算法对图像特征进行提取,感知哈希算法提取出的特征值组成一个向量。
3、图片相似对比
感知哈希算法所产生的向量(亦称指纹)代表着原图与数据库中的图片对比后的相似程度。指纹中如果不相同的数据位不超过5,就说明两张图片很相似;如果大于10,就说明这是两张不同的图片。本项目将在生成两张图片的指纹的基础上,计算出两图间的相似度,以相似度作为排序的标准。
拟解决的关键问题:
1、图像区域分割:本项目将采用区域生长技术对图像进行分割。区域生长的基本思想是将具有相似性质的像素集合起来构成区域。具体先对每个需要分割的区域找一个种子像素作为生长的起点,然后将种子像素周围邻域中与种子像素有相同或相似性质的像素(根据某种事先确定的生长或相似准则来判定)合并到种子像素所在的区域中。将这些新像素当作新的种子像素继续进行上面的过程,直到再没有满足条件的像素可被包括进来,这样一个区域就长成了。
2、图像特征提取: 1) 缩小图片尺寸:最快速的去除高频和细节,只保留结构明暗的方法就
是缩小尺寸。将图片缩小到8x8的尺寸,总共64个像素,摒弃不同
尺寸、比例带来的图片差异。
2) 简化色彩:将缩小后的图片转为64级灰度,也就是说所有像素点总
共64种颜色。(简化色彩公式:Gray = 0.299 R + 0.587 G + 0.114B)
3) 计算平均值:计算所有64个像素的灰度平均值。
4) 比较像素的灰度:将每个像素的灰度与平均值进行比较,大于或等于
平均值,记为1;小于平均值,记为0。
5) 计算哈希值:将上一步的比较结果,组合在一起,组成一个1行64
列的向量,这就是这张图片的指纹。组合的次序并不重要,只需保
证所有图片采用同样次序(例如,自左到右、自顶向下、big-endian)。
3、图片相似对比:实验显示,感知哈希算法对图片的形状特征较为敏感,但无法很好地辨别出颜色的不同,因此本项目将在原算法的基础上添加图片颜色识别算法,以此提高图片搜索算法得准确率。在相似度匹配运算中,首先将数据库中的图片的颜色与例图(用户输入的图片)对比,将搜索范围缩小为同颜色的图片;然后对例图与数据库中图片的指纹进行对比,排除不相似的图片,并根据图片相似度进行排序得到最佳匹配图片序列。
3 项目研究的实施方案及拟采取的研究方法和技术路线
3.1 实施方案:
1) 对感知哈希算法的每一个步骤进行了解、分析:
a. 查询有关图像处理以及感知哈希算法的论文,找出缩小图片尺寸的算法,并进行分析,为感知哈希算法的实现奠定基础;
b. 确定指纹组合的次序;
c. 查询有关颜色识别的论文,并对其进行分析;
d. 将颜色识别与感知哈希算法融合在一起,形成一套有更高准确率的算法。
2) 将上一步的算法置于分布式平台中,建立一个基于分布式计算的图片搜索
引擎模型;
3) 根据模型将技术模块分为图像特征提取模块与分布式搜索引擎模块,并设
计出技术架构;
4) 根据技术架构,将开发工作分配给项目成员,并监督完成情况;
5) 将各成员实现的模块汇总,并进行测试工作;
6) 对项目产品进行优化,并根据产品进行总结。
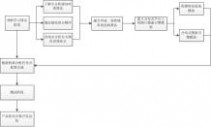
图一:实施方案图
3.2 拟采取的研究方法和技术路线:
1) 本项目各阶段安排与预计的进度如下:
a. 2013.03—2013.04:查阅有关图像特征提取的文献,并对其做细致的研究;
b. 2013.05—2013.06:根据我们的分析结果,建立基于内容的图片搜索引擎模型;
c. 2013.07—2013.08:根据建立的图片搜索引擎模型,设计出各个模块的技术架构;
d. 2013.09:根据设计出的架构,完成系统文档的编写;
e. 2013.10—2013.12:根据系统文档,完成系统的开发以及测试工作; f. 2014.02—2014.03:项目研究优化和总结。
2) 技术路线
图2:项目拟采用的技术路线图
4 项目的可行性分析
4.1 团队实力:
a. 项目组马凡琳同学曾荣获华中赛数学建模二等奖,对常用建模知识有较深
的了解;
b. 项目组于立同学具有很强的编程能力,曾荣获第六届计算机设计大赛软件
开发组二等奖、第四届中国大学生服务外包创新创业大赛三等奖等; c. 项目组于立同学搭建过Hadoop框架,对分布式技术有一定程度上的了解,
对本项目的完成与实现有很大的帮助;
d. 项目组其他成员均来自计算机学院,熟悉Java语言,具有一定的编程能
力。
4.2 技术实现
在模型构建层面,我们鉴于大数据时代的到来,把项目建立在分布式的基础之上,并针对图像处理的特殊需求,筛选出合适的图像处理技术,以构建基于内容的图片搜索引擎模型。在后台信息管理系统方面,我们将使用基于SSH框架的J2EE技术进行开发。在集群环境中,首先通过爬虫程序对网络中的图片资源进行抓取,从而在其中提取图像特征,并进行死链检查(死链为服务器地址已改变的链接),最后生成缩略图,通过建立的索引提供用户的查询以满足用户的需求。 5 项目的创新之处(50字以内)
1) 通过感知哈希算法将图片搜索转化为传统的文本搜索
2) 这种以图搜图的查询模式是对“以关键字搜图”的一大突破
6 项目预期成果
1) 建立一个基于内容的图片搜索引擎模型;
2) 开发一套基于B/S构架的搜索系统;
参考文献:
[1] 章毓晋.图像处理和分析[M].1999.
[2] 焦隽,姜远,黎铭等. 一种在无标注图像库中进行的基于关键词的检索方法
[J].模式识别与人工智能. 2009.
[3] Xu L, Oja E. Randomized Hough transform (RHT) : Basic mechanisms,
algorithms, and computational complexities [J]. CVGIP Image Understanding,1993, (2):131-154.
[4] Eakins J,Graham M.Content-based Image Retricval[R].A Report to the JISC
Technology Applications Programme,1999,12,22.
[5] 庄越挺,潘云鹤.基于内容图像检索综述[J].模式识别与人工智能,
1999,12 :170-178.
[6] 李国辉,曹莉华,柳伟等.多媒体信息查询和检索系统MIRC[J].小型微机计
算机系统,1999,20(9):672-676.
[7] 戚红梅.基于内容的图像信息资源检索技术进展研究[J].情报杂志,2008,1:
124-127.
[8] 董卫军,周明全,耿国华.基于内容的图像检索技术研究[J].计算机工程,
2005,31(10):162-163.
三 : 百度谷歌和搜狐搜索引擎的特点比较93
百度,谷歌,搜狐搜索引擎特点比较
相同点:从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。 不同点:
Google 的搜索服务绝不仅仅是简单的信息目录。而且Google 目录中收录了 10 亿多个网址,这在同类搜索引擎中是首屈一指的。这些网站的内容是相当涉猎广泛的。 与大多数其它搜索引擎的区别在于:
(1)Google 只显示相关的网页, Google 不仅能搜索出包含所有关键词的结果,并且还对网页关键词的接近度进行分析。
(2)Google 按照关键词的接近度确定搜索结果的先后次序,优先考虑关键词较为接近的结果,节省时间。Google 储存网页的快照,当存有网页的服务器暂时出现故障时您仍可浏览该网页的内容。如果找不到服务器,Google 储存的网页快照也可救急。虽然网页快照中的信息可能不是最新的,但在网页快照中查找资料要比在实际网页中快得多。
百度
中文搜索引擎的老大。(1)其基于字词结合的信息处理方式,就相当
巧妙解决了中文信息的理解问题,极大地提高了搜索的准确性和查全率。(2)百度还支持主流的中文编码标准。并且能够在不同的编码之间转换。 (3)百度搜索支持二次检索(又称渐进检索或逼进检索)可在上次检索结果中继续检索,逐步缩小查找范围,直至达到最小、最准确的结果集。 (4)还有就是百度智能性、可扩展的搜索技术保证最快最多的收集互联网信息。拥有目前世界上最大的中文信息库,为用户提供最准确、最广泛、最具时效性的信息提供了坚实基础。 搜狐
搜狐也是一个不错的中文的搜索引擎。适合按照其分类表进行浏览查找,不适合进行关键词查找。搜狐设有独立的目录索引,并采用百度搜索引擎技术,提供网站、网页、类目、新闻、黄页、中文网址、软件等多项搜索选择。搜狐搜索范围以中文网站为主,支持中文域名。相对于其它的搜索引擎,搜狐中文检索系统具有以下的强劲优势:独特的中文分词功能;完美的分数评估体系;自行定义搜索专题。
四 : 基于内容的图片搜索引擎
1、项目背景及研究目的和意义
项目背景:
图像是用各种观测系统以不同形式和手段观测客观世界而获得的,可以直接或间接作用于人眼并进而产生视知觉的实体,科学研究和统计表明,人类从外界获得的信息约有75%是从图像中获得的[1]。(www.61k.com)通过绘画或摄影、摄像得到的图像是人类获取信息的重要手段,这些图像以雕刻或纸张印刷的形式保留下来便于人们浏览、查询。但是当计算机以及互联网出现时,图像的浏览、查询发生了根本性的变化。图片搜索也在人们的生活中越来越普及化,因此目前图片搜索引擎很发达,而图片搜索主要分为基于文本的图片搜索引擎、基于内容的图片搜索引擎以及基于语义的图片搜索引擎。其中最为成熟的是基于文本的图片搜索引擎,基于文本的图片搜索引擎的搜索方式是以文本为关键字进行图片搜索。
在基于文本的图片搜索技术研究的早期,图片被作为数据库中存储的一个对象,并人工地用文本对其进行描述。这种方法比较简单易行,一般是使用数据库管理系统(DBMS)来实现,当然,这种方式的缺点也是很明显的:一是需要人工对图片进行注释,工作量相当大,特别是图片数据量非常大时,人工标注是不切实际的;二是人工标注不可避免的会带来主观性和不精确性,因为不同的人对同一幅图片的理解可能是不相同的。所以说在互联网环境下,对网上的海量图片数据进行人工注释是不现实的。
随着信息搜索技术的不断成熟,互联网网页信息自动采集和标引作为搜索引擎的重要组成部分,也得到了深入的研究,首先是广泛应用于文本搜索引擎中,同时也使用来对图片搜索引擎技术进行改进,因为,与文件系统中独立的图片文件不同,互联网上的图片是作为网页的一部分出现的,具有相关的上下文环境,图片所在网页的标题、图片的提示文字、图片的文件名称、与图片密切环绕的文字以及网页中的其它文字,都可以作为对图片进行描述的依据。目前谷歌、雅虎、百度提供的图片搜索服务,都主要是基于这种技术的。
然而,利用网页上的文字来对网页中的图片进行标注,是非常困难、非常不 精确的。例如说这样一个情况:有一个主题为“奥巴马打蓝球遭肘击缝 12 针,太岁头上动土谁如此大胆”的网页,页面中开头位置放置有一张奥巴马刚缝完针的照片,当用户输入“篮球”作为关键词,希望得到一些篮球的特写图片,结果
图片 搜索 基于内容的图片搜索引擎
却把奥巴马的这张照片搜索出来了。[www.61k.com)这就是用网页文字内容对图片进行自动标注造成的不准确的结果。因此基于内容的搜索引擎是目前搜索引擎技术发展的一个重要课题。
基于内容的搜索引擎尝试直接分析图片文件,将它们根据特征分类。用户可以通过提交一幅图片来表达自己的搜索意图(比如用户希望能够搜索到含有类似图片的网站),搜索引擎系统通过对用户提交的图片文件进行分析、比对,输出检索到的信息。目前,基于内容的图片搜索引擎还处在探索阶段,目前还不存在得到广泛运用的通用搜索引擎[2]。有一些研究机构正在尝试从事特定范围的基于内容的图片搜索引擎研究,如针对特定的图片资料库建立搜索引擎,或者对特定类型的图片资料进行检索等[3]。
鉴于基于内容的图片搜索引擎的重要性,国内外已纷纷投入人力财力物力广泛开展研究并研制成一些系统[4,5]。
Virage公司的VIR(Visual Information Retrieval)图像引擎提供了四种可视属性进行图像的检索(颜色、成分、纹理、形状)[13]。每种属性被赋予0到10的权值。该软件对选出的基础图像的色调、色彩以及饱和度进行分析,然后再图像库中查找与这些颜色属相相近的图像。成分特性是指相关颜色区域的近似程度。用户可设定一个或多个属性的权值优化检索。由于要在众多图像特征中配比权值,所以VIR仍然算是一种需要人为参与的图像检索系统。
国内对于图片搜索系统研究相对较晚。国防科技大学的多媒体信息查询和检索系统MIRC,描述了多媒体内容和结构特征以及信息检索数据模型,支持基于内容的多媒体信息查询和检索[6]。根据用户提供的图像或视频帧例子,基于颜色和轮廓特征进行查询。浙江大学的基于内容多媒体检索系统WebscopeCBR,支持基于关键字、全局颜色、局部纹理、对象形状、颜色布局、纹理布局等的查询。但在系统中众多的图像特征依然是独立的状态,未能有效的联合众多图像特征进行检索。
本项目将对现阶段基于内容的图片搜索引擎进行优化、改进,减少人为参与所带来的搜索结果的不准确性。
研究目的和意义:
图片 搜索 基于内容的图片搜索引擎
文本信息无法完全描述图片信息的矛盾已非常显著,人们对于搜索引擎的准确率的要求正随着互联网数据量的增长而提高,因此传统的图片搜索引擎就很难满足需求,相似图片搜索引擎应运而生。(www.61k.com]
一般的图片搜索引擎通过对图象信息的文字描述来进行检索,而且对于用户来说,不可能在查询时候很精确地用文字对图象进行合理的描述,因此提高查询结果的准确率显得尤为重要。
相似图片搜索是一种新的在线图片搜索引擎:不像其它图片搜索引擎是根据提交的关键字进行搜索,而是根据上传的图片去搜索相似的图片。相似图片搜索是用颜色、纹理、形状以及区域等视觉特征,根据例图在大量图像中集中进行检索,实现了图像视觉特征的检索。这种以图搜图的查询模式是对“以关键字搜图”的一大突破[7]。
基于内容的图片搜索引擎能广泛应用于遥感图像处理、空间探测、医疗图片检索、商标图片检索、建筑工程图、天气预报、公安图像侦查、艺术馆藏资料管理和数字化图书馆等许多领域。伴随着Internet的发展,多媒体数据特别是数字图像信息成为网上的重要资源,而这些资源的内容检索都离不开基于内容的图片搜索引擎技术[8]。
2 项目研究目标、研究内容和拟解决的关键问题
研究目标:
本项目主要研究“以图搜图”的搜索方式,对图像特征提取进行深入分析。完成对图像区域分割、图像特征提取和相似度对比的设计与实现,从而提出一套完整的系统设计方案,并且实现一个初步的基于内容的图片搜索引擎系统。由于图像处理的计算量较大,本项目拟使用分布式计算提高速度。
基于本项目的研究,将能够向“以图搜视频”这一良好的发展前景迈进一步。 研究内容:
61阅读提醒您本文地址:
1、图像区域分割
图片 搜索 基于内容的图片搜索引擎
本项目拟用图像区域分割方法先将图片分割成多个区域,再对每个区域进行图像特征提取并与对应区域进行对比。(www.61k.com]相对于直接对整张图片进行特征提取而仅仅对比一次而言,本项目先分割后提取、对比的方法能够提高图片搜索的准确率。
2、图像特征提取
图片搜索需要对两张图片进行对比,但如果逐像素对比会消耗大量时间,所以本项目先对图像进行特征提取,通过特征进行对比,从而提高搜索速度。本项目将采用感知哈希算法对图像特征进行提取,感知哈希算法提取出的特征值组成一个向量。
3、图片相似对比
感知哈希算法所产生的向量(亦称指纹)代表着原图与数据库中的图片对比后的相似程度。指纹中如果不相同的数据位不超过5,就说明两张图片很相似;如果大于10,就说明这是两张不同的图片。本项目将在生成两张图片的指纹的基础上,计算出两图间的相似度,以相似度作为排序的标准。
拟解决的关键问题:
1、图像区域分割:本项目将采用区域生长技术对图像进行分割。区域生长的基本思想是将具有相似性质的像素集合起来构成区域。具体先对每个需要分割的区域找一个种子像素作为生长的起点,然后将种子像素周围邻域中与种子像素有相同或相似性质的像素(根据某种事先确定的生长或相似准则来判定)合并到种子像素所在的区域中。将这些新像素当作新的种子像素继续进行上面的过程,直到再没有满足条件的像素可被包括进来,这样一个区域就长成了。
2、图像特征提取: 1) 缩小图片尺寸:最快速的去除高频和细节,只保留结构明暗的方法就
是缩小尺寸。将图片缩小到8x8的尺寸,总共64个像素,摒弃不同
尺寸、比例带来的图片差异。
2) 简化色彩:将缩小后的图片转为64级灰度,也就是说所有像素点总
共64种颜色。(简化色彩公式:Gray = 0.299 R + 0.587 G + 0.114B)
3) 计算平均值:计算所有64个像素的灰度平均值。
4) 比较像素的灰度:将每个像素的灰度与平均值进行比较,大于或等于
平均值,记为1;小于平均值,记为0。
5) 计算哈希值:将上一步的比较结果,组合在一起,组成一个1行64
列的向量,这就是这张图片的指纹。组合的次序并不重要,只需保
证所有图片采用同样次序(例如,自左到右、自顶向下、big-endian)。
图片 搜索 基于内容的图片搜索引擎
3、图片相似对比:实验显示,感知哈希算法对图片的形状特征较为敏感,但无法很好地辨别出颜色的不同,因此本项目将在原算法的基础上添加图片颜色识别算法,以此提高图片搜索算法得准确率。[www.61k.com)在相似度匹配运算中,首先将数据库中的图片的颜色与例图(用户输入的图片)对比,将搜索范围缩小为同颜色的图片;然后对例图与数据库中图片的指纹进行对比,排除不相似的图片,并根据图片相似度进行排序得到最佳匹配图片序列。
3 项目研究的实施方案及拟采取的研究方法和技术路线
3.1 实施方案:
1) 对感知哈希算法的每一个步骤进行了解、分析:
a. 查询有关图像处理以及感知哈希算法的论文,找出缩小图片尺寸的算法,并进行分析,为感知哈希算法的实现奠定基础;
b. 确定指纹组合的次序;
c. 查询有关颜色识别的论文,并对其进行分析;
d. 将颜色识别与感知哈希算法融合在一起,形成一套有更高准确率的算法。
2) 将上一步的算法置于分布式平台中,建立一个基于分布式计算的图片搜索
引擎模型;
3) 根据模型将技术模块分为图像特征提取模块与分布式搜索引擎模块,并设
计出技术架构;
4) 根据技术架构,将开发工作分配给项目成员,并监督完成情况;
5) 将各成员实现的模块汇总,并进行测试工作;
6) 对项目产品进行优化,并根据产品进行总结。
图片 搜索 基于内容的图片搜索引擎
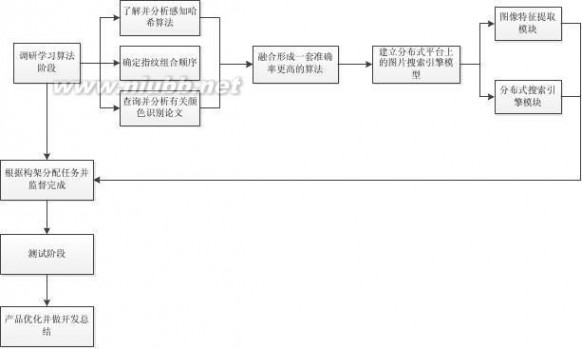
图一:实施方案图
3.2 拟采取的研究方法和技术路线:
1) 本项目各阶段安排与预计的进度如下:
a. 2013.03—2013.04:查阅有关图像特征提取的文献,并对其做细致的研究;
b. 2013.05—2013.06:根据我们的分析结果,建立基于内容的图片搜索引擎模型;
c. 2013.07—2013.08:根据建立的图片搜索引擎模型,设计出各个模块的技术架构;
d. 2013.09:根据设计出的架构,完成系统文档的编写;
e. 2013.10—2013.12:根据系统文档,完成系统的开发以及测试工作; f. 2014.02—2014.03:项目研究优化和总结。(www.61k.com]
2) 技术路线
图片 搜索 基于内容的图片搜索引擎
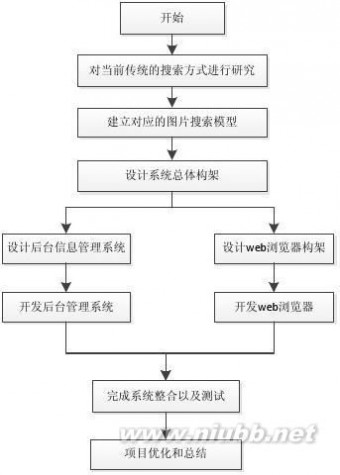
图2:项目拟采用的技术路线图
4 项目的可行性分析
4.1 团队实力:
a. 项目组马凡琳同学曾荣获华中赛数学建模二等奖,对常用建模知识有较深
的了解;
b. 项目组于立同学具有很强的编程能力,曾荣获第六届计算机设计大赛软件
开发组二等奖、第四届中国大学生服务外包创新创业大赛三等奖等; c. 项目组于立同学搭建过Hadoop框架,对分布式技术有一定程度上的了解,
对本项目的完成与实现有很大的帮助;
d. 项目组其他成员均来自计算机学院,熟悉Java语言,具有一定的编程能
力。(www.61k.com)
4.2 技术实现
图片 搜索 基于内容的图片搜索引擎
在模型构建层面,我们鉴于大数据时代的到来,把项目建立在分布式的基础之上,并针对图像处理的特殊需求,筛选出合适的图像处理技术,以构建基于内容的图片搜索引擎模型。(www.61k.com]在后台信息管理系统方面,我们将使用基于SSH框架的J2EE技术进行开发。在集群环境中,首先通过爬虫程序对网络中的图片资源进行抓取,从而在其中提取图像特征,并进行死链检查(死链为服务器地址已改变的链接),最后生成缩略图,通过建立的索引提供用户的查询以满足用户的需求。 5 项目的创新之处(50字以内)
61阅读提醒您本文地址:
1) 通过感知哈希算法将图片搜索转化为传统的文本搜索
2) 这种以图搜图的查询模式是对“以关键字搜图”的一大突破
6 项目预期成果
1) 建立一个基于内容的图片搜索引擎模型;
2) 开发一套基于B/S构架的搜索系统;
参考文献:
[1] 章毓晋.图像处理和分析[M].1999.
[2] 焦隽,姜远,黎铭等. 一种在无标注图像库中进行的基于关键词的检索方法
[J].模式识别与人工智能. 2009.
[3] Xu L, Oja E. Randomized Hough transform (RHT) : Basic mechanisms,
algorithms, and computational complexities [J]. CVGIP Image Understanding,1993, (2):131-154.
[4] Eakins J,Graham M.Content-based Image Retricval[R].A Report to the JISC
Technology Applications Programme,1999,12,22.
[5] 庄越挺,潘云鹤.基于内容图像检索综述[J].模式识别与人工智能,
1999,12 :170-178.
[6] 李国辉,曹莉华,柳伟等.多媒体信息查询和检索系统MIRC[J].小型微机计
算机系统,1999,20(9):672-676.
[7] 戚红梅.基于内容的图像信息资源检索技术进展研究[J].情报杂志,2008,1:
124-127.
图片 搜索 基于内容的图片搜索引擎
[8] 董卫军,周明全,耿国华.基于内容的图像检索技术研究[J].计算机工程,
2005,31(10):162-163.
61阅读提醒您本文地址:
五 : 谷歌的变化和搜索引擎优化的未来
濒临死亡的SEO一直是热门话题之一对于SEOER在相当一段时间。一些搜索引擎优化的专业人士担心,他们的职业生涯受到威胁,因为搜索引擎正在不断改进自己的技术。搜索引擎的进程中彻底改造自己的排名战略打击垃圾邮件发送者和改善用户体验。例如,谷歌目前正在改善的意图和行为为基础的搜索,以便提供更相关的搜索结果。或者通俗的说个性搜索,智能搜索。那么,这一切意味着未来的搜索引擎优化?死亡的是搜索引擎优化的必然结果?
人们一直在预测年底SEO降不再神话。虽然它的某些事情上的搜索引擎优化前总是变化,搜索引擎正在变得更聪明了,SEO的不断适应这些变化,就像过去一样。只要网站的搜索引擎列表的网站,而不需要付出一笔费用,搜索引擎优化将继续存在,改变的只是优化的手段和技术。
谷歌的改进和什么是SEO的未来
在寻求打击垃圾邮件和改善用户体验,谷歌是在执行过程中的一系列变化中的行为和意图的搜索。每个人谁进行搜索特定任期将有不同的结果的基础上他们的位置和搜索历史记录。由于这些变化,搜索引擎优化的切换只针对关键字,以更专注于提高流量和转换。。一种可能性是,链接建设在未来的搜索引擎优化重要性将远远降低,因为谷歌将确定的价值基础上的网站的访问者进行的。最终目标的网站将提供引人注目的内容,吸引游客阅读,分享,书签,等等。
社会媒体化的投入,通过投票的另一个特色是搜索引擎的完美补充(完善),以提供用户控制的排名。搜索引擎用户可能有机会投票支持他们喜欢的网站和网站将获得排名基于这种票。该模型将类似内容上看到社会投票网站如Digg和Reddit。当然,搜索引擎会找到一种办法,以确保票自然是为了防止黑帽SEO的从愚弄搜索引擎程序。而现在已经有迹象显示这中现象的可能性很大,但是,最近一次的PR更新,Google降低了tw的页面权重,这又是什么预兆?
谷歌和其他搜索引擎都在努力提高在SEO中的地位。最初,这将使得搜索引擎优化的专业人士的工作难度更大,但最终的结果是积极的,也是公平的。垃圾邮件发送者和黑帽SEO的将有更多的困难成功地实现其不择手段的努力和搜索引擎用户将提供的内容,显然这更有意义。
用户,而不是机器
与往常一样,其目的是网站管理员和SEO专业人员应时刻提醒自己是面对用户。有的朋友花那么多时间试图欺骗搜索引擎,他们忘记了他们是谁,最终服务还是用户!您的网站要优化,但您始终应优先满足用户的需求和提供解决方案。如果一定要说SEO的未来方向,用户需求和行为将决定最终排名。不管搜索引擎怎样改变,SEM怎样发展,其实SE和SEOER是走在一条路上,搜索引擎优化的成功取决于你的能力通过网站的内容和社会媒体营销。
所以SEOER完全不用悲观,相反,微笑着前进才是最重要的。
本文标题:基于谷歌的搜索引擎-34%的Facebook外部流量来自谷歌等搜索引擎61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1