一 : 《大规模web服务开发技术》阅读笔记
第5课 大规模数据处理的难点 -- 内存和磁盘
单台Linux服务器瓶颈分析
1、查看平均负载
用top、uptime命令查看平均负载;
1、平均负载很低,系统吞吐量无法提升 --------->检查软件设置是否异常,网络、主机是否存在故障
2、平均负载很高,用sar或vmstat命令查看cpu使用率和I/O等待率
2、确认CPU、I/O是否存在瓶颈;
>如果是CPU负载过高:
1、使用sar或top命令确认是用户程序的瓶颈还是系统程序的问题;
2、用ps命令查看可见进程的状态和CPU使用时间,进一步确认问题进程;
3、确定进程后,使用strace进行跟踪或用oprofile进行剖测;
如果是排除程序失控、磁盘、内存处于理想状态,则需要增加服务器、改善程序逻辑和算法;
>如果是I/O负载过高:
多半是程序发出的I/O请求过多导致负载过高或者是发生页面交换导致频繁访问磁盘,使用sar或vmstat确认交换区状态;
如果是发生页面交换引起:
1. 用ps确认是否有进程消耗了大量内存
2. 如果是程序问题消耗大量内存的,需要改进程序;
3. 如果是因为内存安装不足,则增加内存,无法增加内存的情况,需要考虑分布式
如果不是发生页面交换引起(可能是用于缓存的内存不足):
1.如果增加内存可以扩大缓存,则增加内存;
2.如果增加内存还是无法解决问题,则考虑分布式或增加缓存服务器;
第6课:可扩展的要点
CPU负载的扩展(较简单)
1、增加相同结构的服务器,通过负载均衡器来分散;
2、如:web应用服务器、网络爬虫等;
I/O负载的扩展(较复杂)
1、借助数据库
2、大规模数据
第7课:处理大规模数据的基础知识
处理大规模数据的三个重点:
写程序的技巧:
* 尽量在内存中完成,:将磁盘寻道次数降到最低;可以实现分布式,有效利用局部性;
* 使用能应对数据量增加的算法,例如:线性搜索 -->二叉树搜索,O(n) -->O(logn)
* 有时可以利用数据压缩和搜索的技术
处理大规模数据之前的三大前提知识:
* 操作系统的缓存
* 以分布式为前提应用RDBMS时必须要做的事情
* 大规模环境中的算法和数据结构
第9课:降低I/O负载的策略
以缓存为前提,降低I/O负载的策略:
* 如果数据规模小于物理内存,则全部缓存;
* 如果数据规模大于物理内存,可以考虑数据压缩(使用数据压缩,在从缓存中读取时是否要进行解压,这是否会增加计算负载呢?);
* 如果数据规模大于物理内存 ,可以就是扩展到多台服务器。(www.61k.com)为分散CPU负载,只需要简单增加服务器,为分散I/O负载,需要考虑局部性;
* 考虑经济成本的平衡性
linux页面缓存策略:(只要可能linux就会把空闲的内存用作页面缓存使用)
1. 从磁盘读取数据
2. 如果数据在缓存中不存在且有空闲的内存
3. 建立新的缓存
4. 如果没有空闲内存供缓存使用,则替换旧的缓存
5. 进程要求分配内存时,其优先级高于页面缓存;
 服务器刚启动时,不要投入生产环境,因为建立缓存需要时间,如果在没有缓存的情况下,大规模的访问造成频繁的读写磁盘,可能会引起宕机;启动后要将经常使用的数据库文件cat一遍,使其放入缓存中;
服务器刚启动时,不要投入生产环境,因为建立缓存需要时间,如果在没有缓存的情况下,大规模的访问造成频繁的读写磁盘,可能会引起宕机;启动后要将经常使用的数据库文件cat一遍,使其放入缓存中;
 如何cat?
如何cat?
第10课:利用局部性的分布式
所谓局部性就是Locality,根据访问模式实施分布式;
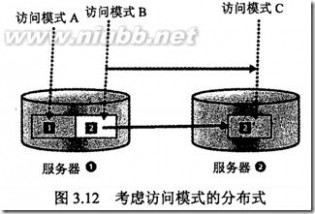
我理解是按一定的业务规则将访问进行分流,这样单台服务器只要保存对应规则部分的缓存数据即可, 那么应用请求分配由谁来完成呢?是LVS?
那么应用请求分配由谁来完成呢?是LVS?
常用的局部性分布式技术是:Partitioning(分区)
简单的说就是将一个数据库分割到不同的机器上,
* 最简单的分割方法:以表为单位分割,比如表A、B在机器1上,表C、D在机器2上;分割原则是看表的容量和机器缓存容量的匹配上;
这样的分割是否意味着不同机器的表之间必须是弱关系的,不能有关联的需求?
* 有一种分割方法是从数据中间进行分割,即对一个表,比如根据ID的起始字母:a-c在机器1,d-f在机器2等;
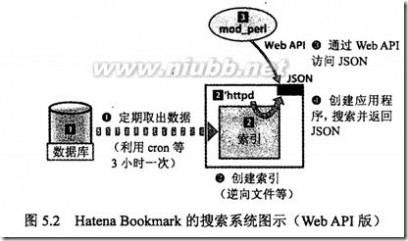
* 还有一种特别的分割方法是根据业务用途,将数据分割成“数据岛”;例如Hatena BookMark是根据HTTP请求的User-Agent和URL进行分离的,例如:一般用户分配到岛1,部分API请求分配到岛2,Google bot、Yahoo!等爬虫分配到岛3;
* 使用局部性的分布式,要求应用程序做相应的修改,同时存在的问题是:如果需要改变分割粒度,需要将数据合并一次后再进行分割,比较麻烦;
第11课:正确应用索引 ----分布式MySQL应用的大前提
* 在设计大数据量的表时,尽量紧凑一些,让记录尽可能的小,因为表结构稍微有错误,数据量就会以GB的单位递增;
* 要注意表设计过程中对冗余列的处理,如果一个表包含冗余列,会浪费存储空间,如果将冗余列分割到另一个表,也许会节省空间(不一定,需要评估),但同时也增加了查询的复杂度,因此在时间和空间的取舍上要进行衡量;
* MySQL中建立索引的数据结构就是B树的变种B+树,B树可以通过调整节点数参数M,使得每个节点的大小在4KB,从而使得磁盘寻道次数和节点访问次数相同;而二叉树是固定为2个节点,因此不具备这样的调节能力;
* 从理论上,B(+)树的复杂度为Olog(n),而线性搜索的复杂度为O(n)
Mysql索引的规则:
* where、order by、group by中指定的列会使用索引
* 何时索引有效?明确添加的索引、主键,UNIQUE约束;
* 想同时应用多个列上的索引,就必须使用复合索引;
* 确认索引是否有效的命令:explain
第12课:MySQL的分布式 -- 以扩展为前提的系统设计
MySQL的Replication:
* master/slave的架构;
* 查询发给slave,更新发给master;通过ORM来控制;
* slave前面放负载均衡器,如:LVS 、MySQL Proxy,从而将查询分散到多台服务器上;
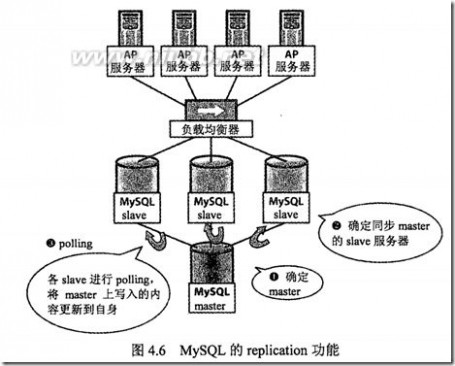
Master/Slave的特征:
查询可以扩展,只需增加Slave服务器即可,但在增加前添加适当的内存;
Master无法扩展,虽然web应用90%以上是读操作,但如果需要扩展,则需要通过对表进行分割或更换实现方法;
- 进行表分割:分散写入操作,将数据文件分散到同一机器的不同磁盘上或不同的机器上
- 不使用RDBMS,采用key-value存储结构,如:Tokyo Tyrant、Redis
第13课:MySQL的横向扩展和Partitioning
以Partitioning为前提的设计:
例如表entry和表tag是一对多的关系,如果要取出包含标签“perl”的书签,需要使用JOIN查询,将两个表关联。但是如果entry和tag表放在不同的机器上,MYSQL就无法实现JOIN(MySQL的FEDERATED表可以实现),只有通过先查找包含“perl”标签的记录,再到entry表中根据eid找对应的entry记录。因此,JOIN查询只能在保证表以后不会被分割到不同机器上的前提下才能使用。
利用where…in…来避免JOIN
select url from entry INNER JOIN bookmark on entry.eid = bookmark.eid where bookmark.uid = 169848 limit 5;
=>
select eid from bookmark where uid = 169848 limit 5;
select url from entry where eid in (0,4,5,6,7);
第14课:特殊用途索引----处理大规模数据
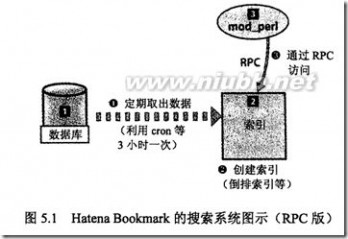
问题:当数据规模超过RDBMS的处理能力时怎么办?
方法:利用批处理操作从RDBMS中提取出数据,建立索引服务器之类的,再让WEB应用程序通过RPC等访问索引服务器。
第30课:云 vs 自行构建基础设施
Amazon EC2 (Amazon Elastic Compute Cloud),是不负责储存的,储存由S3 (Amazon Simple Storage Service)服务负责,所以得有脚本每次重启时从S3恢复数据库
Amazon S3 (Amazon Simple Storage Service)
Google App Engine
Microsoft Windows Azure
第31课:层和可扩展性
一台服务器的处理能力大概为100万~200万PV(page views)/月左右 4核CPU,8G内存
各层可扩展性:
应用程序服务器,配置相同,不持有状态,容易扩展
数据源(数据库服务器、文件服务器):read的分布式容易,write 的分布式难
第33课:保证冗余性
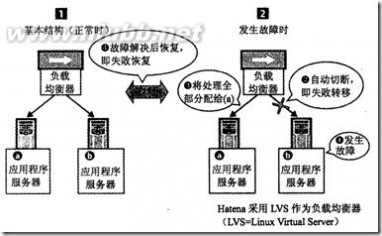
应用程序服务器:
增加服务器数量
用负载均衡器实现失败转移和失败恢复
数据库服务器:
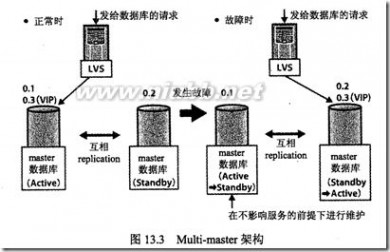
Multi-master:是今年Mysql服务器构建的主要方法。该架构中,服务通常是两台,组成Active/Standby结构。其中,一台是Active,另一台是Standby,通常只向Active写数据。一旦Active停机,Standby通过VRRP协议监视到这一情况,即把自己提升为Active,变成新的master。而停机的那台经过人工修复后变成Standby,或恢复为原来的结构。为了从外部判断哪台是Active,需要用到虚拟IP(VIP),即Active服务器除了原有的IP地址,还会被分配一个服务用的虚拟IP地址。应用程序服务器始终访问这个虚拟IP。切断时将这个虚拟IP分配给新的Active。从而实现master的透明切换。
第38课:网络的分界点
PC路由器的极限:超过1Gbps(30pps,即每秒30万包数据,按每包300字节算,为1Gbps)
一个子网的极限:500台主机
一个数据中心无法实现全球化
CDS:(Content Delivery Network),基本原理就是在世界各地放置服务器,将媒体文件缓存后,用户就可以从最近的服务器下载了。
如:Amazon CloudFront
二 : 百视通开放SDK开发者工具以扩大应用商店规模
腾讯科技讯(宗秀倩) 7月1日消息,上周,在亚洲移动通信博览会上百视通宣布将向开发者开放SDK开发者工具以及面向合作伙伴的“5大助力计划”。与此同时,升级后的智能电视业务平台及智能终端小红机顶盒系列产品也在会上亮相。
去年,百视通在发布高清3D智能云互联网电视机顶盒“小红”同时,还发布了其内置的百视商店。今年百视通进一步发力应用开发。
开发者方面,开发者可通过开发者社区的“自服务平台”,进行合作申请、应用发布以及相关应用管理。开发者通过SDK接入百视通生态,实现与包括“应用管理”、“运营支撑”、“开发者管理”的管理平台对接。使用SDK加入百视通平台的开发者,可以获得协助进行用户信息活动、提炼的“用户管理”,显示应用内产品订购状态、接入百视通电视支付渠道、参与付费应用的启动控制以及通过日志上报方式获得全方位产品信息等5项支持。
在应用开发方面,百视通发布了应用商店“5大助力计划”。百视通在通过电视屏、Pad屏、手机屏、PC屏结合的“一云多屏”方式,为合作伙伴提供多渠道服务同时,还将“TV大数据分享”、“合作渠道嫁接”,“全网推广”, “合作伙伴TV专属号码”,“跨屏服务”等5项措施作为重点助力。
资料显示,百视通已经与百度、新浪、网易、人人网等在健康家庭、娱乐家庭,和新媒体中心等三方面联合开发智慧家庭应用超过200款。
去年6月,百视通发布了“小红”的高清3D智能云互联网电视机顶盒,今年1月,百视通发布智能电视业务平台。上周,百视通宣布对其智能电视业务平台及相关终端进行全面升级。与此同时,百视通还计划将“小红”的硬件配置升级至双核CPU+双核GPU和双波段WIFI,并且在终端植入开机key论证机制,保证终端整机、应用、核心数据的安全,终端可以实现按业务需求的灵活配置,并给到用户最佳的使用体验。
亚洲通信展期间,百视通还宣布,将与上海东方广播进行战略合作。在整合广播内容与新媒体平台,全球新媒体传播、互联网电视等方面展开全方位合作。
三 : facebook10大中国应用开发商和应用
本文据appdata、slideshare和china social games的综合数据整理(仅供参考,本文不具评述性)。
目前在facebook平台上活跃着众多来自中国的开发者和他们推出的各个语种的应用。
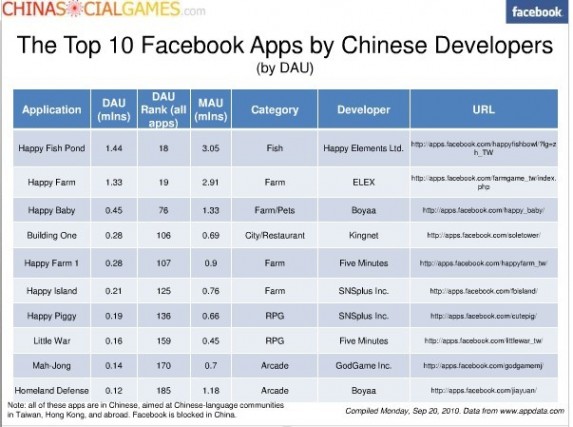
facebook-chinese-app
在前十大(按照每日活跃用户数排名)来自中国开发者推出的应用当中,来自happy elements旗下的happy fish pond以144万DAU位居第一,该应用属于fish类别,月活跃用户有305万,在所有的应用DAU中排名第十八;
第二名,来自elex旗下的happy farm,日活跃用户为133万,该应用属于farm类,月活跃用户291万,在所有应用DAU中排名第十九;
第三名,来自boyaa旗下的happy baby,日活跃用户为45万,该应用属于farm/pets类,月活跃用户133万,在所有应用DAU中排名第七十六;
第四名,来自kingnet旗下的buliding one,日活跃用户为28万,该应用属于city类,月活跃用户69万,在所有应用DAU中排名第一百零六;
第五名,来自five minutes旗下的happy farm 1,日活跃用户为28万,该应用属于farm类,月活跃用户90万,在所有应用DAU中排名第一百零七;
第六名,来自snsplus旗下的happy island,日活跃用户为21万,该应用属于farm类,月活跃用户76万,在所有应用DAU中排名第一百二十五;
第七名,来自snsplus旗下的happy piggy,日活跃用户为19万,该应用属于RPG类,月活跃用户66万,在所有应用DAU中排名第一百三十六;
第八名,来自five minutes旗下的little war,日活跃用户为16万,该应用属于RPG类,月活跃用户45万,在所有应用DAU中排名第一百五十九;
第九名,来自godgame旗下的mah-jong,日活跃用户为14万,该应用属于arcade类,月活跃用户70万,在所有应用DAU中排名第一百七十;
第十名,来自boyaa旗下的homeland defense,日活跃用户为12万,该应用属于arcade类,月活跃用户118万,在所有应用DAU中排名第一百八十五。(source:appdata、slideshare & china social games)
四 : Google发布新编程语言Go 尚未大规模应用
北京时间11月11日消息,据国外媒体报道,Google今天宣布推出名称为Go的新编程语言,旨在让编程人员更轻松、更快速和更高效的编写应用。
Google员工将Go称为一个“试验性语言”,试图融合Python等动态语言的开发速度和C或C++等编译语言的性能和安全。
Google Go团队成员在博客中表示,编译完成的Go程序的运行速度接近C语言。
Google Go语言官网称,希望那些喜欢尝试的用户来体验该语言。Google坦承,Go语言目前尚未在Google内部被使用,至少未被大规模用于生产系统。
Google表示,Go是一门伟大的系统编程语言,它支持多任务处理,使用全新和轻量级的面向对象设计,另外还支持真闭包(true closures)和反射(reflection)等非常酷的功能。
今年9月份,Google还启动了一个类Java编程语言项目,名字为“Noop”。
五 : 谷歌将大规模推广Voice 用户可直接发送邀请
北京时间10月14日消息,据国外媒体报道,谷歌周二在一片博客文章中宣布,将大规模推广Google Voice电话软件的应用。在未来几个星期,已经注册Voice的用户可以邀请其他人注册。
每个用户一开始只能获得三个邀请,但是谷歌表示,计划在未来放出更多的邀请。
谷歌Voice最近在媒体中收到了广泛的关注,其中包括苹果公司不允许其进入iPhone应用程序商店的争议,还有美国联邦通信委员会(FCC)开始调查该服务,因为谷歌不允许Voice服务进入某些农村地区。
通过谷歌Voice的服务,用户只需通过一个电话号码,就可以接通其他任何一个电话号码,还可以免费拨打本地和长途电话。其他功能还包括:语音信箱、通话历史、电话会议、阻止特定电话和将语音电话转换为文本。(文/向兆琹)
本文标题:开发大规模web应用-《大规模web服务开发技术》阅读笔记61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1