这几天轰动硅谷的 GPT-3 是什么来头?
相信不太了解 AI 的朋友这几天也或多或少看到了一些关于 GPT-3 的重磅消息,甚至有媒体称其为 “继比特币之后又一个轰动全球的现象级新技术”。
请注意,现在站在你面前的是:互联网原子弹,人工智能界的卡丽熙,算力吞噬者,黄仁勋的新 KPI ,下岗工人制造机,幼年期的天网 —— 最先进的 AI 语言模型 GPT-3。

言归正传,OpenAI 的研究人员在上个月发表了一篇论文,描述了 GPT-3 的开发,正式发布了这个由 1750 亿个参数组成的 AI 语言模型。
在 NLP 领域中,通常采用 ELMo 算法的思想,即通过在大量的语料上预训练语言模型,然后再将预训练好的模型迁移到具体的下游NLP任务,从而提高模型的能力。GPT 模型是 OpenAI 在 2018 年提出的一种新的 ELMo 算法模型,该模型在预训练模型的基础上,只需要做一些微调即可直接迁移到各种 NLP 任务中,因此具有很强的业务迁移能力。
GPT 模型主要包含两个阶段。第一个阶段,先利用大量未标注的语料预训练一个语言模型,接着,在第二个阶段对预训练好的语言模型进行微改,将其迁移到各种有监督的 NLP 任务,并对参数进行 fine-tuning。
简而言之,在算法固定的情况下,预训练模型使用的训练材料越多,则训练好的模型任务完成准确率也就越高。
那么 1750 亿是什么概念?曾有人开玩笑说,“要想提高 AI 的准确率,让它把所有的测试数据都记下来不就行了?” 没想到如今真有人奔着这个目标去做了……
在 GPT-3 之前,最大的 AI 语言模型是微软在今年 2 月推出的 Turing NLG,当时拥有 170 亿参数的 Turing NLG 已经标榜是第二名 Megatron-LM 的两倍。没错,仅短短 5 个月的时间,GPT-3 就将头号玩家的参数提高了 10 倍!Nivdia 的黄老板看了看年初刚画的产品算力曲线,发现事情并不简单。
OpenAI 曾于 2019 年初发布 GPT-2,这一基于 Transformer 的大型语言模型共包含 15 亿参数、在一个 800 万网页数据集上训练而组成,这在当时就已经引起了不小的轰动。整个 2019 年,GPT-2 都是 NLP 界最耀眼的明星之一,与 BERT、Transformer XL、XLNet 等大型自然语言处理模型轮番在各大自然语言处理任务排行榜上刷新最佳纪录。而 GPT-2 得益于其稳定、优异的性能在业界独领风骚。
而 GPT-3 的参数量足足是 GPT-2 的 116 倍,实现了对整个 2019 年的所有大型自然语言处理模型的降维打击。
GPT-3 的论文长达 72 页,作者多达 31 人。来自 OpenAI、约翰霍普金斯大学的 Dario Amodei 等研究人员证明了在 GPT-3 中,对于所有任务,模型无需进行任何梯度更新或微调,而仅通过与模型的文本交互指定任务和少量示例即可获得很好的效果。
GPT-3 在许多 NLP 数据集上均具有出色的性能,包括翻译、问答和文本填空任务,这还包括一些需要即时推理或领域适应的任务,例如给一句话中的单词替换成同义词,或执行 3 位数的数学运算。
当然,GPT-3 也可以生成新闻报道,普通人很难将其生成的新闻报道与人类写的区分开来。是不是细思极恐?
通常来说,自然语言处理任务的范围从生成新闻报道到语言翻译,再到回答标准化的测试问题。那么训练这个庞然大物需要消耗多少资源呢?
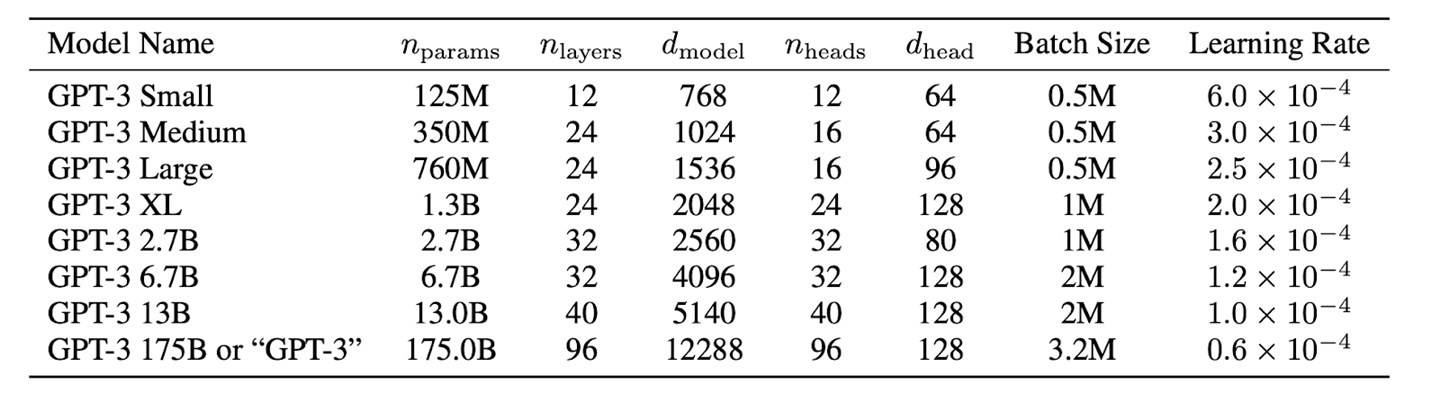
OpenAI 方面表示: “我们在 cuDNN 加速的 PyTorch 深度学习框架上训练所有AI模型。每个模型的精确架构参数都是基于 GPU 的模型布局中的计算效率和负载平衡来选择的。所有模型都在微软提供的高带宽集群中的 NVIDIA V100 GPU 上进行训练。”
根据微软早前公布的信息,我们发现微软给 OpenAI 提供的这台超级计算机是一个统一的系统,该系统拥有超过 285000 个 CPU 核心,10000 个 GPU 和每秒 400G 的网络,是一台排名全球前 5 的超级计算机。

GPT-3 就是在微软这霸道的 “无限算力” 加持下诞生的,据悉其训练成本约为 1200 万美元。
既然训练 GPT-3 需要如此苛刻的超级环境,民间的什么 2080 Ti、线程撕裂者等家用级设备自然都是弟弟,那么我们普通用户要怎么来用这个玩意儿呢?
目前,OpenAI 开放了少量 GPT-3 的 API 测试资格,商业公司、研究学者和个人开发者都可以申请,获得资格的用户可以通过远程调用的方式体验 GPT-3 的强大。当然,这个资格并不容易拿到……
在国外,“ 拿到 GPT-3 测试资格 ” 已经成为了一个“炫富”的新梗……
当然也有早期成功抢到测试资格的用户。因为 GPT-3 是一个史无前例的庞大语言模型,所以几乎所有可以用文字表达的工作它都能胜任,你可以指导它回答问题、写文章、写诗歌、甚至写代码。
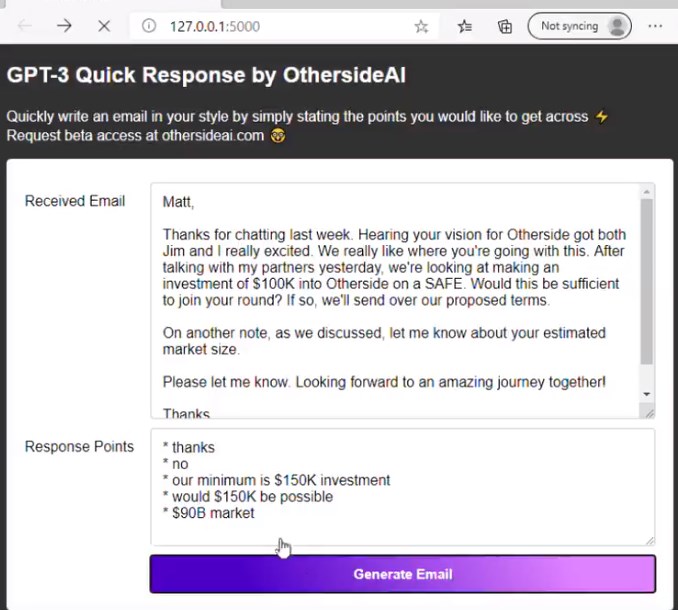
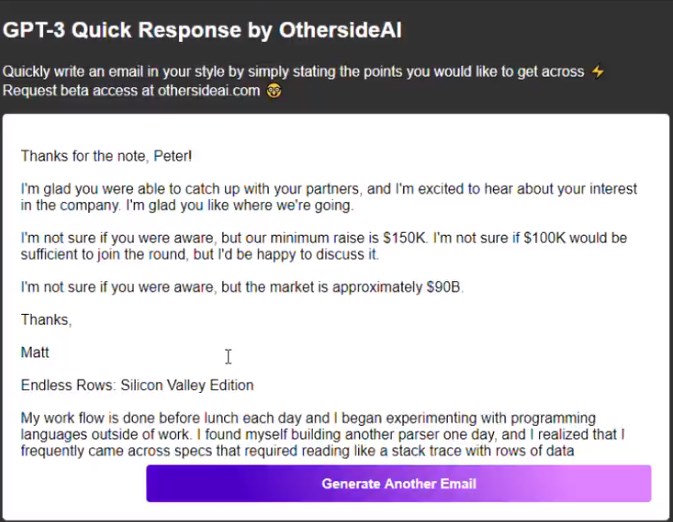
首先来看最基本的语言表达功能,下面是网友用 GPT-3 开发的自动回复邮件工具,只需要输入几个简要的回复关键词,GPT-3 就能自动生成一篇文笔流畅的回复邮件:
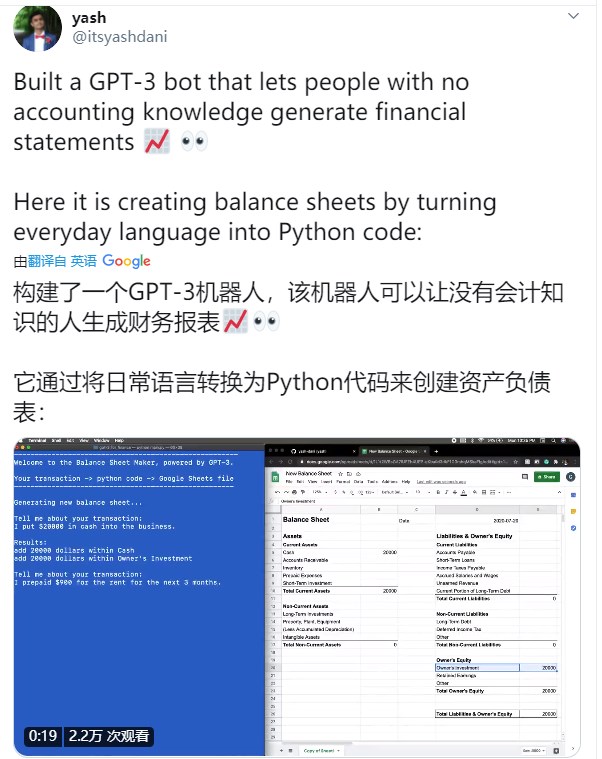
更深入一些,下面这位名叫 yash 的网友用 GPT-3 开发了一个 Python 驱动的财务报表,它可以将日常语言转换成 Python 代码来创建资产负载表:输入“我今天投入了两万美元”、“后三个月的房租预付了 900 美元”这样的自然语言,程序就能自动修改资产负债表上相应的项目数值。
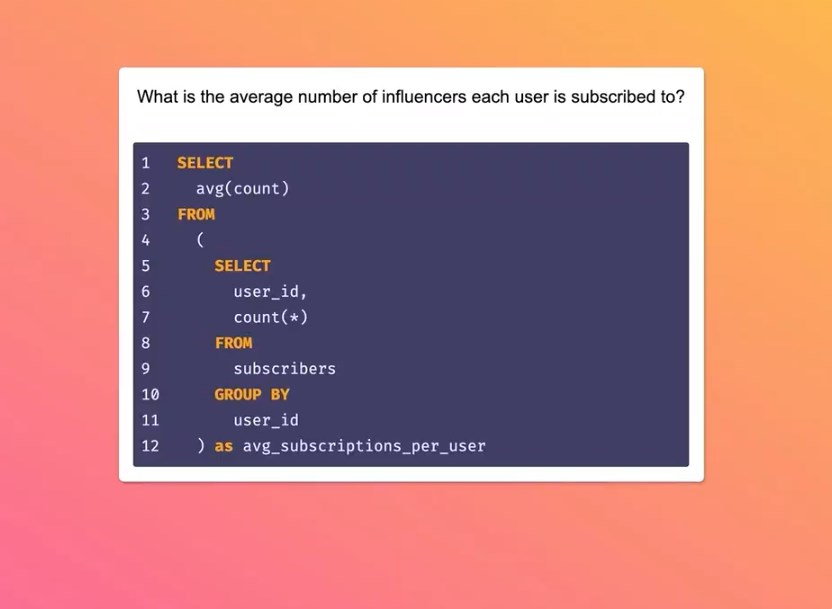
网友 Faraar Nishtar 调用 GPT-3 写了一个小工具,能直接输入自然文字生成他想要的 SQL 查询代码:
网友 Sharif Shameem 开发出了一个新产品 Debuild。这是一个调用了 GPT-3 API 的网页 app 快速生成器,在输入框里用自然语言进行描述,它就可以快速输出你想要的用户界面,比如输入“生成一个像西瓜一样的按钮”:
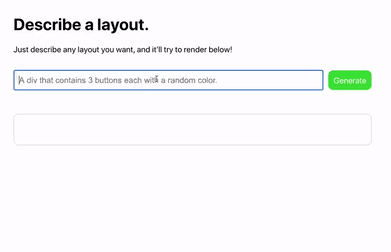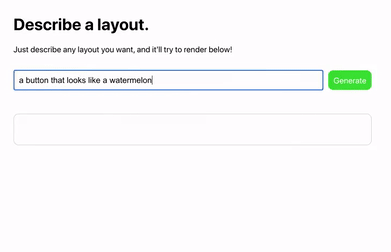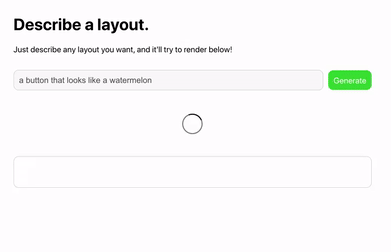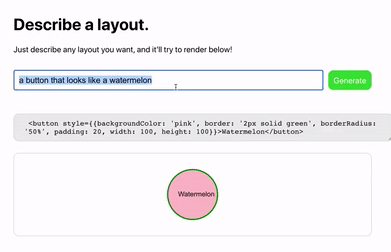
对于产品经理或前端设计师,只需要在设计软件 Figma 中加入 GPT-3 插件,就可以打字生成你想要的前端效果:
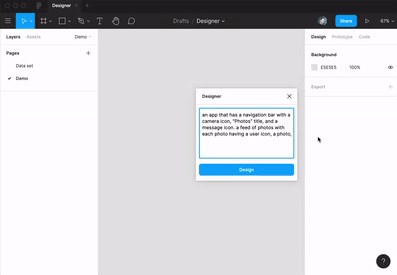
也有开发者给 GPT-3 做了图灵测试,结果发现它的回答很有意思:

“如果在十年前用同样的问题做测试,我会认为答题者一定是人。现在,我们不能再以为 AI 回答不了常识性的问题了。”
古人云,“熟读唐诗三百首,不会作诗也会吟。” 从人类历史到软件代码,庞大的 GPT-3 模型囊括了互联网中很大一部分用文字记录下来的人类文明,这些记录造就了其强大的文字任务处理能力。
AI 语言模型参数量级近年来呈指数倍发展,随着在摩尔定律下人类设备算力的提升,在未来的某一天,或许真的将会出现一个无限接近熟读人类历史所有文明记录的超级模型,届时是否会诞生出一个真正的人工智能呢?

最后引用神经网络之父、图灵奖获得者 Geoffrey Hinton 早前对 GPT-3 的一番评论:
“ 鉴于 GPT-3 在未来的惊人前景,可以得出结论:生命、宇宙和万物的答案,就只是 4.398 万亿个参数而已。”
版权声明:本文内容由网友上传(或整理自网络),原作者已无法考证,版权归原作者所有。61k阅读网免费发布仅供学习参考,其观点不代表本站立场。
本文标题:互联网原子弹,算力吞噬者:1750 亿参数的 AI 模型 GPT-3 引爆硅谷61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1