智能语音行业已经进入蓬勃发展的时代,随着智能设备的逐渐增多,用户对语音交互的需求越来越大。在AIoT时代,智能设备的自然语言交互能力成为与用户沟通的重要一环。当用户对智能设备产生需求并进行对话时,语音的唤醒和识别能力直接决定了用户对设备的好感度。
依托于小爱同学、小米多款智能设备,小米持续深耕语音技术,希望在智能家庭、智能车载等丰富的使用场景之下,更进一步解放对用户语音识别环境的条件限制,让用户体验更自然、更自由、无压力的语音交互方式,更好地理解用户意图,为用户提供极致的智能语音交互体验。
多通道端到端语音技术,让用户在“自由场景自由说”
目前,业内各家的近讲语音唤醒和识别能力已经达到了较高的水平,在近距离、安静的环境下,用户与智能设备的语音交互已经基本无障碍。然而,在强噪声干扰、强房间混响、说话距离远、设备自身播放音源等条件下,智能设备与用户进行连续地自然语音交互仍然具有挑战性。
如何让远场语音性能达到和近讲相近的水平,一直是困扰业界语音工程师的一大难题。鉴于此,小米语音团队的“多通道端到端语音技术”自研能力,取得比“传统多通道阵列增强模块加单通道语音技术”更好的性能。
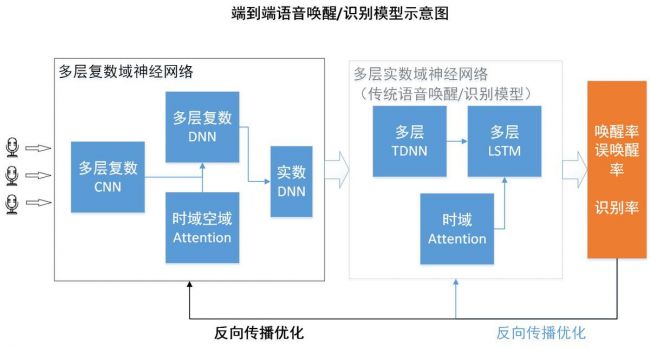
为了在远场声音中更准确的识别出目标语音,传统多通道阵列增强技术会使用空间滤波或语音分离算法,但这些算法引入了较多先验假设,在一些不符合假设的场景下,性能会明显下降。另外,传统多通道阵列处理技术是由多个技术模块串联组成,多个麦克风的数据会被送入回声消除、降噪、去混响、寻向和波束形成等模块,几个模块单独进行优化,优化目标并不一致。
小米从2018年开始验证端到端语音唤醒和识别的思路,目标即从充满噪声、混响和回声的多个麦克风中直接学习语音特征,提升真实环境中的识别率和稳定性。经过一系列的校验,小米多通道端到端语音技术有三大明显优势。第一,端上的计算量变小,较之前减少了50%,缩短了所有的计算路径和时长;其次,端上的存储量变小,在原有的基础上大幅减少,减轻了存储压力;最后,“多通道端到端语音技术”直接用一个网络中的不同级去替代之前的多个模块,最后有一个一致的优化目标,避免误差的逐级传播。整个模型用一套神经网络表述,大幅减小系统设计复杂度,可以明显降低运算负荷。从大规模训练数据中习得的深度神经网络,比基于传统信号处理的方式,使用的先验假设少,可以涵盖更多的实际场景
从近讲到远场,小米自研技术拓宽了语音的想象力
据小米语音工程师介绍,尽管传统信号处理具有一些方面的不足,但是其能够较好地处理麦克风阵列信号的相位,利用物理学中朴素的法则“同向相加,异向相消”对不想要的信号分量进行抑制。因此,小米的多通道语音识别模型不仅采用了更先进的深度神经网络,也同时继承了传统信号处理理论对相位处理的精髓,将传统前端算法和深度神经网络的优势进行互补,也即将传统信号处理的概念进一步拓展,充分利用深度神经网络的非线性处理能力,提出一种全神经网络语音识别模型。
在语音识别大牛Daniel Povey加入小米后,小米的语音交互在原有的基础上更进一步。终于让多通道端到端语音方案性能超过了传统方案。经过数据测试,多通道端到端语音技术让远场语音识别性能相对提升了10%,使用户与智能设备的交互更加顺畅。
从3G时代,到4G时代,再到5G时代,智能语音交互也发生着巨大的变革。多通道端到端的语音技术不仅让用户交互方式更加自由,同时也降低了硬件的产品功耗。从近讲的唤醒识别到远场的唤醒识别,从单通道到多通道,小米自研语音技术旨在帮助用户在自由的场景下实现自由说的目标。未来,小米将智能语音技术落地至更多应用场景,不断突破自研技术,为用户提供更加极致的语音交互体验。
版权声明:本文内容由网友上传(或整理自网络),原作者已无法考证,版权归原作者所有。61k阅读网免费发布仅供学习参考,其观点不代表本站立场。
本文标题:从近讲到远场,小米自研语音技术让用户“自由场景自由说”61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1