一 : MindMapper使用入门 教程
MindMapper使用入门 教程
1. 从系统左上图标或按ctrl+shift+n,可以打开新建文件窗口,其中有很多模版和例子供参考选用。
2. 输入一个主题后,如果要输入它的分支,可以按空格,系统自动添加一个新的分支。也可以直接输入分支内容,系统自动作为子分支添加到该主题下。
3. 快速添加多个主题有几种方式,
a) 按shift+数字n,则系统自动在当前选中主题周围添加n个分支/
b) 按ctrl+空格,系统弹出如下窗口,可以在其中输入多行文字,输入完后,系统自动将他们作为子分支添加在当前选定的主题上,如果输入文字时候有的文字前面有空格,则它们作为上面文字的子主题。这样可以快速输入。
4. 快速从别的程序中拷贝内容到思维导图中做为主题。
a) 按insert选项签中的自动复制模式进入自动复制模式,然后无论在其它什么程序如ie,word等等中,用鼠标选中的内容,自动当作当前主题的子分支添加到思维导图软件中。
b) 也可以按f6进入或退出自动复制模式。
5. 浮动主题,在导图中可以输入任意个浮动主题,即其与页面中心主题可以没有联系。可以采用插入float topic的方式来插入。或者直接用鼠标在背景上点击后,即可在鼠标位置输入浮动主题。
6. Double click left or right sizing handles to remove extra horizontal spaces
Double click up or down sizing handles to remove extra vertical spaces
7. 针对主题可以加notes,按f3按钮或按notes按钮可以为主题加文本或图片备注。
8. 放大或缩小导图可以通过键盘上的 = 号或 - 号。
9. Roll Down、 Roll Up可以用来将思维导图的某个topic下局部分枝压缩或展开。
10. 可以选择某区域后点击鼠标右键用print area 将该区域打印,或者选择某个主题后 点击鼠标右键选则Division Print,则只打印该主题下面涵盖的分支。
二 : Cucumber入门1 - 传统流程下的使用
第一次看到Cucumber和BDD(Behavior Driven Development, 行为驱动开发),是在四年前。[www.61k.com)那时才开始工作,对软件测试工具相当着迷。只要是开源的、免费的,我就一定要下载,安装,试用。有的工具用途单一、好懂(如Jmeter,Watir);有的工具,则涉及到一些软件领域的独有概念,不好懂,(如STAF,Cucumber)。好懂的,我上手、试用、推广,不亦乐乎;不好懂的,就只能丢在一边,这里面就包括Cucumber。
再次看到Cucumber,已是两年前。我对软件开发的理解也深了些,这一看,可真是个好东西。之后我与Cucumber间发生的故事,稍后慢慢向大家交代。这开篇的第一章,我想献给如当年的我一样,偶然见到了Cucumber和BDD,却不明所以将之丢在一边的家伙们。
初闻Cucumber的人,第一件事一定是来到Cucumber的首页,第一眼看到的一定是
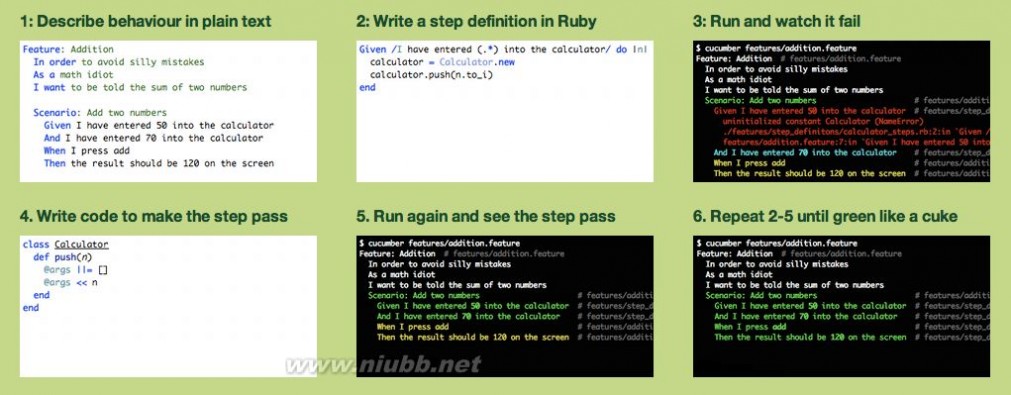
很不幸的是,这六张图不太好懂。因为它们按照BDD的流程来编写的。为了让它们好懂些,我们抛开BDD,采用传统的软件开发模型(设计->编码->测试)来看它。传统流程如下:
图1,这是一个被测系统——用ruby编写的计算器。

为了便于大家理解,我试着修改了一些。
class Calculator def push(n) #记数 @args ||= [] #初始化空数组 @args << n end def sum() #返回所有数字和 sum = 0 @args.each do |i| sum += i end @result = sum end def result @result end end
计算器Calculator提供两个功能: 记数push;加和sum。push将数字一一记录在@args数组中;sum则将所有@args数组中的数字累加得和,存入@result中。写完了被测系统,我们来编写测试用例。
图2,这是为了测试上述计算器,使用Cucumber描述的测试用例。

原图中的英文描述,被我翻译成了中文。:
Feature: 计算器 Scenario: 两数相加 Given 我有一个计算器 And 我向计算器输入50 And 我向计算器输入70 When 我点击累加 Then 我应该看到结果120
支持中、英等自然语言,是Cucumber的特点之一。在Cucumber的帮助文档里,声明它支持包括简体中文、繁体中文、日文、韩文和英文在内的45种语言。
注意:我并未将所有英文都翻译成中文,而是留下了几个关键字:
它们的含义与原有自动化测试工具中的概念相同,类比如下:
| Cucumber | Unit Test |
|---|---|
| Feature (功能) | test suite (测试用例集) |
| Scenario(情景) | test case (测试用例) |
| Given(给定) | setup(创建测试所需环境) |
| When(当) | test(触发被测事件) |
| Then(则) | assert(断言,验证结果) |
Cucumber放弃了原有的关键字,而选择了左边五种,只是为了更加流畅地支持自然语言。使用Cucumber的关键字,创建了测试用例,接下来,要如何使用Cucumber来运行它呢?
图3,这是运行Cucumber时的画面。
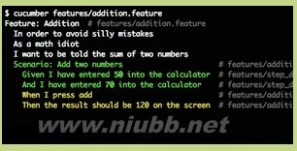
在一台安装好Cucumber的机器上,运行上述测试用例,便可以看到下列输出:
Feature: 计算器 Scenario: 两数相加 # features/calculator.feature:3 Given 我有一个计算器 # features/calculator.feature:4 And 我向计算器输入50 # features/calculator.feature:5 And 我向计算器输入70 # features/calculator.feature:6 When 我点击累加 # features/calculator.feature:7 Then 我应该看到结果120 # features/calculator.feature:8 1 scenario (1 undefined) 5 steps (5 undefined) 0m0.005s You can implement step definitions for undefined steps with these snippets: Given /^我有一个计算器$/ do pending # express the regexp above with the code you wish you had end Given /^我向计算器输入(\d+)$/ do |arg1| pending # express the regexp above with the code you wish you had end When /^我点击累加$/ do pending # express the regexp above with the code you wish you had end Then /^我应该看到结果(\d+)$/ do |arg1| pending # express the regexp above with the code you wish you had end
Cucumber首先输出的是测试用例的描述,然后3行总结性地输出:本功能(Feature)有1个情景(1 scenario);5个步骤(5 steps),全部5个步骤均未定义(undefined);运行耗时0.005秒。这里出现了两个新名词:步骤(steps)和步骤定义(step definitions)。在Cucumber中,以关键字Given, And, When, Then开头的每一行,为一个步骤。在两数相加的情景中,一共有5行。因此,结果显示:5个步骤。
如何定义一个步骤,在Cucumber的运行结果中也给出了详细的办法。在3行总结性输出后,紧接着便是:You can implement…即:你可以使用下面的代码段实现步骤定义,然后是4个小的代码段。这些代码段,便是Cucumber依照情境中我们使用的5个步骤,帮助我们生成的步骤定义框架。每个框架都将内容部分空白出来,等待填充。下面,我们来进行步骤定义。
扩展:cucumber入门 / cucumber使用教程 / 移花宫奇遇入门流程
图4, 这是一个步骤定义的代码示范。
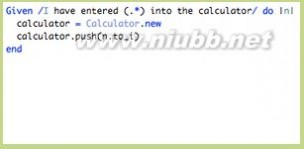
我们依照图2的样子,向中文步骤中填入代码,如下:
Given /^我有一个计算器$/ do @c = Calculator.new end Given /^我向计算器输入(\d+)$/ do |num| @c.push(num.to_i) end When /^我点击累加$/ do @c.sum end Then /^我应该看到结果(\d+)$/ do |result| @c.result.should == result.to_i end
步骤定义的过程,就是向代码段——步骤定义框架——中填入代码的过程,即:用代码来描述你期望的,该步骤应该执行的动作。完整的步骤定义是一个函数,它:
因为有了正则表达式的匹配,5个步骤仅需要4个步骤定义。“我向计算器输入50、70”两个步骤,都可以用“我向计算器输入(\d+)”一个正则表达式来描述。匹配值被自动提取出来作为参数,传入代码。注意:所有匹配值,即参数,都是以字符串的形式传递,因此,我加入了num.to_i 与 result.to_i,将得到的字符串转为整形。步骤定义完成,再次执行Cucumber。屏幕将会显示一片绿色。
图5,它是一个执行Cucumber测试用例,并成功通过的画面。
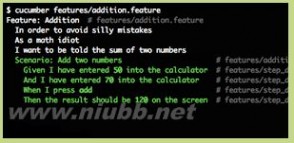
步骤定义完成后,再次运行Cucumber。Cucumber会找到步骤定义,并按照其代码去执行。结果如下:
Feature: 加法 Scenario: 两数相加 # features/calculator.feature:3 Given 我有一个计算器 # features/step_definitions/a.rb:2 And 我向计算器输入50 # features/step_definitions/a.rb:6 And 我向计算器输入70 # features/step_definitions/a.rb:6 When 我点击累加 # features/step_definitions/a.rb:10 Then 我应该看到结果120 # features/step_definitions/a.rb:14 1 scenario (1 passed) 5 steps (5 passed) 0m0.003s
步骤定义被我保存在文件夹step_definitions下的a.rb当中。步骤定义所在文件与起始行数,被打印在每个步骤结尾,以方便查找和修改。最后,Cucumber总结性地输出运行结果:1个情景,5个步骤,全部通过。
图6, 这是一个执行Cucumber测试用例,但失败的画面。

为了让这个已经十分简单的计算器产生bug,我只好将它改错为:
class Calculator def sum() sum = 0 @args.each do |n| sum = n #此处原为:sum += n end @result = sum end end
再次运行Cucumber,结果为:
Feature: 加法 Scenario: 两数相加 # features/calculator.feature:3 Given 我有一个计算器 # features/step_definitions/a.rb:2 And 我向计算器输入50 # features/step_definitions/a.rb:6 And 我向计算器输入70 # features/step_definitions/a.rb:6 When 我点击累加 # features/step_definitions/a.rb:10 Then 我应该看到结果120 # features/step_definitions/a.rb:14 expected: 120 got: 70 (using ==) (RSpec::Expectations::ExpectationNotMetError) ./features/step_definitions/a.rb:15:in `/^我应该看到结果(\d+)$/' features/calculator.feature:8:in `Then 我应该看到结果120' Failing Scenarios: cucumber features/calculator.feature:3 # Scenario: 两数相加 1 scenario (1 failed) 5 steps (1 failed, 4 passed) 0m0.004s
失败的步骤是用红色标示出来的。在最后一个步骤中,Cucumber期待的结果为120,但得到的是70。注意:失败的情景列表(Failing Scenarios)里列出的是:“两数相加”这个情景所在的文件与起始行数。这是因为一个功能文件内,可能含有多个情景,这种输出可以便于找到出错的情景。
接下来的总结性结果为:1个情景失败(1 failed),5个步骤中,4个通过,1个失败。
作为自动化测试工具的Cucumber,就介绍到这里。
在继续之前,我们先回顾一下本章内容。
回顾:
扩展:cucumber入门 / cucumber使用教程 / 移花宫奇遇入门流程
三 : MAT使用入门
本人博客地址:http://androidperformance.com
本文博客地址:http://androidperformance.com/2015/04/11/AndroidMemory-Usage-Of-MAT/
本文微博地址:http://weibo.com/270099576
MAT简介
MAT(Memory Analyzer Tool),一个基于Eclipse的内存分析工具,是一个快速、功能丰富的JAVA heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗。使用内存分析工具从众多的对象中进行分析,快速的计算出在内存中对象的占用大小,看看是谁阻止了垃圾收集器的回收工作,并可以通过报表直观的查看到可能造成这种结果的对象。
MAT
当然MAT也有独立的不依赖Eclipse的版本,只不过这个版本在调试Android内存的时候,需要将DDMS生成的文件进行转换,才可以在独立版本的MAT上打开。不过Android SDK中已经提供了这个Tools,所以使用起来也是很方便的。
MAT工具的下载安装
这里是MAT的下载地址:https://eclipse.org/mat/downloads.php,下载时会提供三种选择的方式:
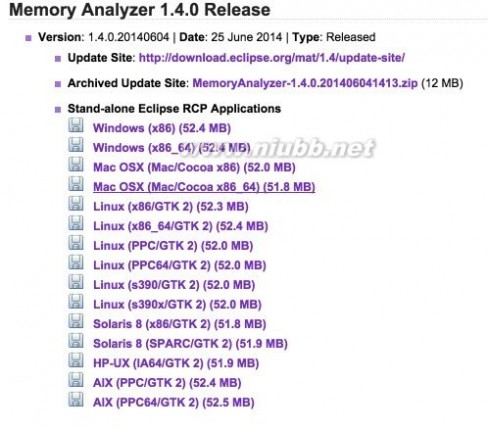
Download MAT
Update Site 这种方式后面会有一个网址:比如http://download.eclipse.org/mat/1.4/update-site/,安装过Eclipse插件的同学应该知道,只要把这段网址复制到对应的Eclipse的Install New Software那里,就可以进行在线下载了。
MAT with eclipse
Archived Update Site 这种方式安装的位置和上一种差不多,只不过第一种是在线下载,这一种是使用离线包进行更新,这种方式劣势是当这个插件更新后,需要重新下载离线包,而第一种方式则可以在线下载更新。
Stand-alone Eclipse RCP Applications 这种方式就是把MAT当成一个独立的工具使用,不再依附于Eclipse,适合不使用Eclipse而使用Android Studio的同学。这种方式有个麻烦的地方就是DDMS导出的文件,需要进行转换才可以在MAT中打开。
下载安装好之后,就可以使用MAT进行实际的操作了。
Android(Java)中常见的容易引起内存泄露的不良代码
使用MAT工具之前,要对Android的内存分配方式有基本的了解,对容易引起内存泄露的代码也要保持敏感,在代码级别对内存泄露的排查,有助于内存的使用。
Android主要应用在嵌入式设备当中,而嵌入式设备由于一些众所周知的条件限制,通常都不会有很高的配置,特别是内存是比较有限的。如果我们编写的代码当中有太多的对内存使用不当的地方,难免会使得我们的设备运行缓慢,甚至是死机。为了能够使得Android应用程序安全且快速的运行,Android的每个应用程序都会使用一个专有的Dalvik虚拟机实例来运行,它是由Zygote服务进程孵化出来的,也就是说每个应用程序都是在属于自己的进程中运行的。一方面,如果程序在运行过程中出现了内存泄漏的问题,仅仅会使得自己的进程被kill掉,而不会影响其他进程(如果是system_process等系统进程出问题的话,则会引起系统重启)。另一方面Android为不同类型的进程分配了不同的内存使用上限,如果应用进程使用的内存超过了这个上限,则会被系统视为内存泄漏,从而被kill掉。
常见的内存使用不当的情况查询数据库没有关闭游标
描述:
程序中经常会进行查询数据库的操作,但是经常会有使用完毕Cursor后没有关闭的情况。如果我们的查询结果集比较小,对内存的消耗不容易被发现,只有在常时间大量操作的情况下才会复现内存问题,这样就会给以后的测试和问题排查带来困难和风险。
示例代码:
Cursor cursor = getContentResolver().query(uri ...); if (cursor.moveToNext()) { ... ... }修正示例代码:
Cursor cursor = null;try { cursor = getContentResolver().query(uri ...); if (cursor != null && cursor.moveToNext()) { ... ... } } finally { if (cursor != null) { try { cursor.close(); } catch (Exception e) { //ignore this } }}构造Adapter时,没有使用缓存的 convertView
描述:以构造ListView的BaseAdapter为例,在BaseAdapter中提供了方法:
public View getView(int position, View convertView, ViewGroup parent)来向ListView提供每一个item所需要的view对象。初始时ListView会从BaseAdapter中根据当前的屏幕布局实例化一定数量的view对象,同时ListView会将这些view对象缓存起来。当向上滚动ListView时,原先位于最上面的list item的view对象会被回收,然后被用来构造新出现的最下面的list item。这个构造过程就是由getView()方法完成的,getView()的第二个形参 View convertView就是被缓存起来的list item的view对象(初始化时缓存中没有view对象则convertView是null)。
由此可以看出,如果我们不去使用convertView,而是每次都在getView()中重新实例化一个View对象的话,即浪费资源也浪费时间,也会使得内存占用越来越大。ListView回收list item的view对象的过程可以查看:android.widget.AbsListView.java --> void addScrapView(View scrap) 方法。
示例代码:
public View getView(int position, View convertView, ViewGroup parent) {View view = new Xxx(...);... ...return view;}示例修正代码:
public View getView(int position, View convertView, ViewGroup parent) {View view = null;if (convertView != null) {view = convertView;populate(view, getItem(position));...} else {view = new Xxx(...);...}return view;}关于ListView的使用和优化,可以参考这两篇文章:
Using lists in Android (ListView) - Tutorial
]()
Making ListView Scrolling Smooth
Bitmap对象不在使用时调用recycle()释放内存
描述:有时我们会手工的操作Bitmap对象,如果一个Bitmap对象比较占内存,当它不在被使用的时候,可以调用Bitmap.recycle()方法回收此对象的像素所占用的内存。
另外在最新版本的Android开发时,使用下面的方法也可以释放此Bitmap所占用的内存
Bitmap bitmap ;...bitmap初始化以及使用...bitmap = null;释放对象的引用
描述:这种情况描述起来比较麻烦,举两个例子进行说明。
示例A:
假设有如下操作
public class DemoActivity extends Activity { ... ... private Handler mHandler = ... private Object obj; public void operation() { obj = initObj(); ... [Mark] mHandler.post(new Runnable() { public void run() { useObj(obj); } }); }}我们有一个成员变量 obj,在operation()中我们希望能够将处理obj实例的操作post到某个线程的MessageQueue中。在以上的代码中,即便是mHandler所在的线程使用完了obj所引用的对象,但这个对象仍然不会被垃圾回收掉,因为DemoActivity.obj还保有这个对象的引用。所以如果在DemoActivity中不再使用这个对象了,可以在[Mark]的位置释放对象的引用,而代码可以修改为:
public void operation() { obj = initObj(); ... final Object o = obj; obj = null; mHandler.post(new Runnable() { public void run() { useObj(o); } }}示例B:
假设我们希望在锁屏界面(LockScreen)中,监听系统中的电话服务以获取一些信息(如信号强度等),则可以在LockScreen中定义一个PhoneStateListener的对象,同时将它注册到TelephonyManager服务中。对于LockScreen对象,当需要显示锁屏界面的时候就会创建一个LockScreen对象,而当锁屏界面消失的时候LockScreen对象就会被释放掉。
但是如果在释放LockScreen对象的时候忘记取消我们之前注册的PhoneStateListener对象,则会导致LockScreen无法被垃圾回收。如果不断的使锁屏界面显示和消失,则最终会由于大量的LockScreen对象没有办法被回收而引起OutOfMemory,使得system_process进程挂掉。
总之当一个生命周期较短的对象A,被一个生命周期较长的对象B保有其引用的情况下,在A的生命周期结束时,要在B中清除掉对A的引用。
其他
Android应用程序中最典型的需要注意释放资源的情况是在Activity的生命周期中,在onPause()、onStop()、onDestroy()方法中需要适当的释放资源的情况。由于此情况很基础,在此不详细说明,具体可以查看官方文档对Activity生命周期的介绍,以明确何时应该释放哪些资源。
使用MAT进行内存调试
要调试内存,首先需要获取HPROF文件,HPROF文件是MAT能识别的文件,HPROF文件存储的是特定时间点,java进程的内存快照。有不同的格式来存储这些数据,总的来说包含了快照被触发时java对象和类在heap中的情况。由于快照只是一瞬间的事情,所以heap dump中无法包含一个对象在何时、何地(哪个方法中)被分配这样的信息。
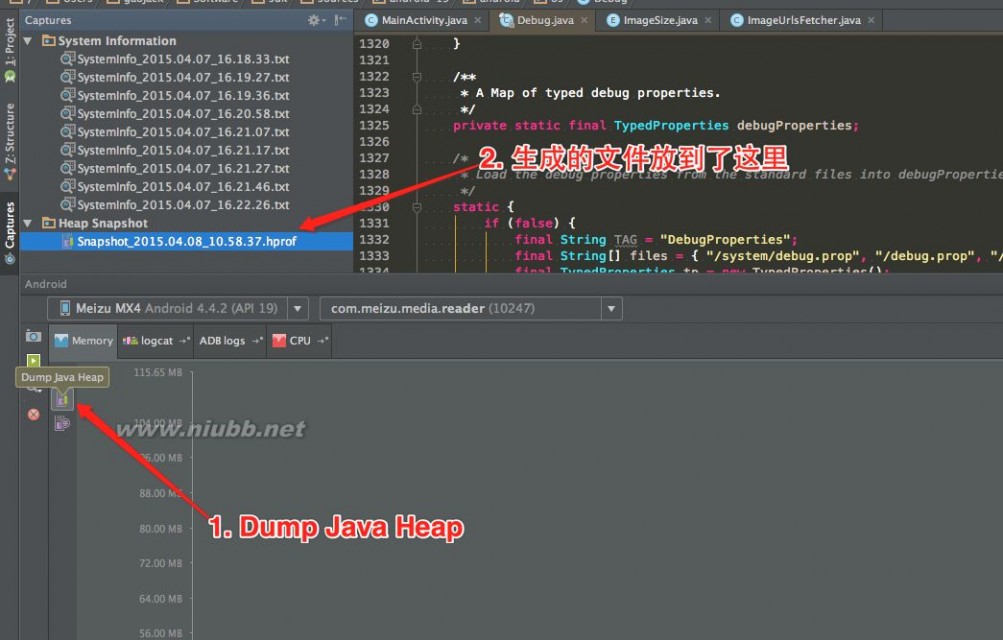
使用Eclipse获取HPROF文件这个文件可以使用DDMS导出,DDMS中在Devices上面有一排按钮,选择一个进程后(即在Devices下面列出的列表中选择你要调试的应用程序的包名),点击Dump HPROF file 按钮:
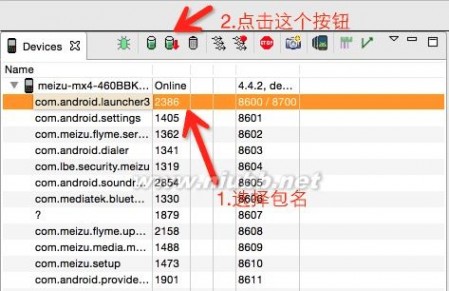
Dump HEAP with DDMS
选择存储路径保存后就可以得到对应进程的HPROF文件。eclipse插件可以把上面的工作一键完成。只需要点击Dump HPROF file图标,然后MAT插件就会自动转换格式,并且在eclipse中打开分析结果。eclipse中还专门有个Memory Analysis视图 ,得到对应的文件后,如果安装了Eclipse插件,那么切换到Memory Analyzer视图。使用独立安装的,要使用Android SDK自带的的工具(hprof-conv 位置在sdk/platform-tools/hprof-conv)进行转换
hprof-conv xxx.xxx.xxx.hprof xxx.xxx.xxx.hprof转换过后的.hprof文件即可使用MAT工具打开了。
使用Android Studio获取HPROF文件使用Android Studio同样可以导出对应的HPROF文件:
Android-Studio
最新版本的Android Studio得在文件上右键转换成标准的H(www.61k.com]PROF文件,在可以在MAT中打开。
MAT主界面介绍
这里介绍的不是MAT这个工具的主界面,而是导入一个文件之后,显示OverView的界面。
打开经过转换的hprof文件:
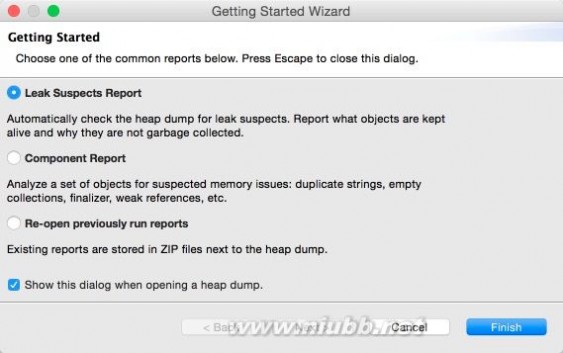
open hprof
如果选择了第一个,则会生成一个报告。这个无大碍。

Leak Suspects
选择OverView界面:
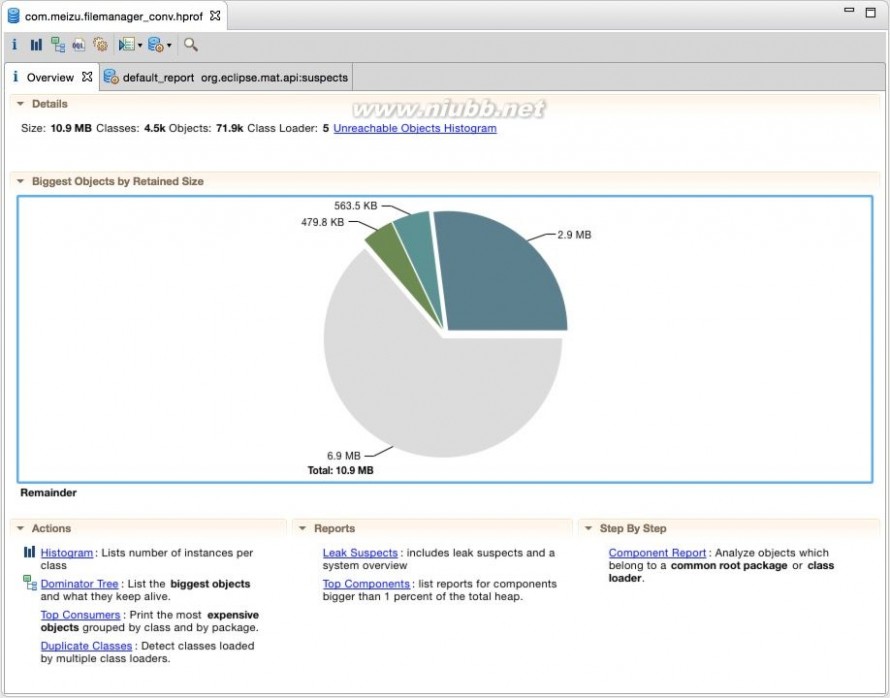
System OverView
我们需要关注的是下面的Actions区域
Histogram:列出内存中的对象,对象的个数以及大小
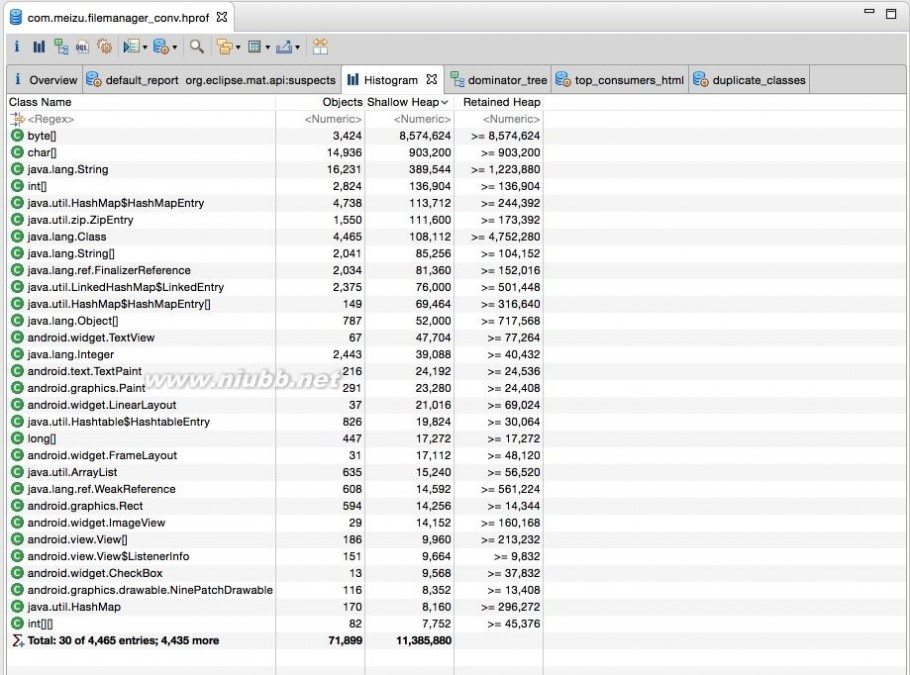
Histogram
Dominator Tree:列出最大的对象以及其依赖存活的Object (大小是以Retained Heap为标准排序的)
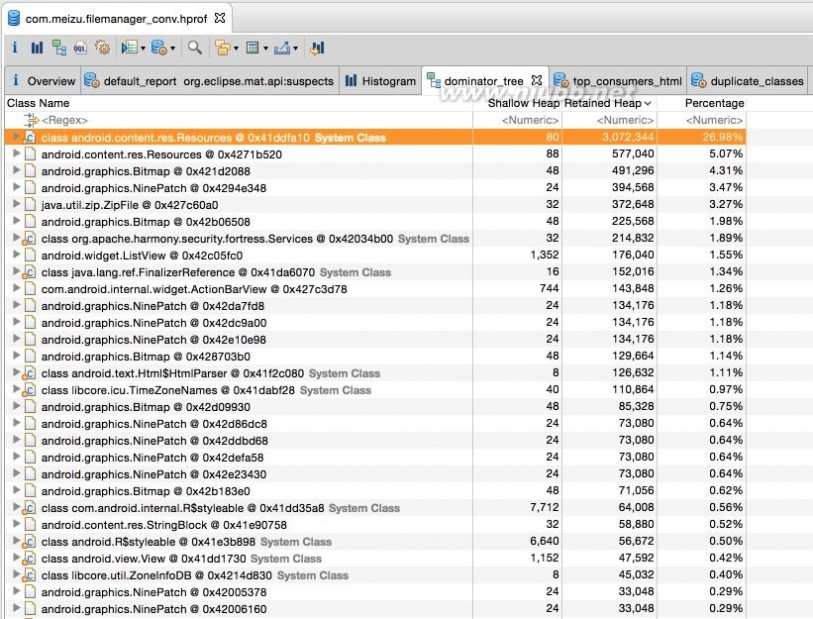
Dominator Tree
Top Consumers : 通过图形列出最大的object
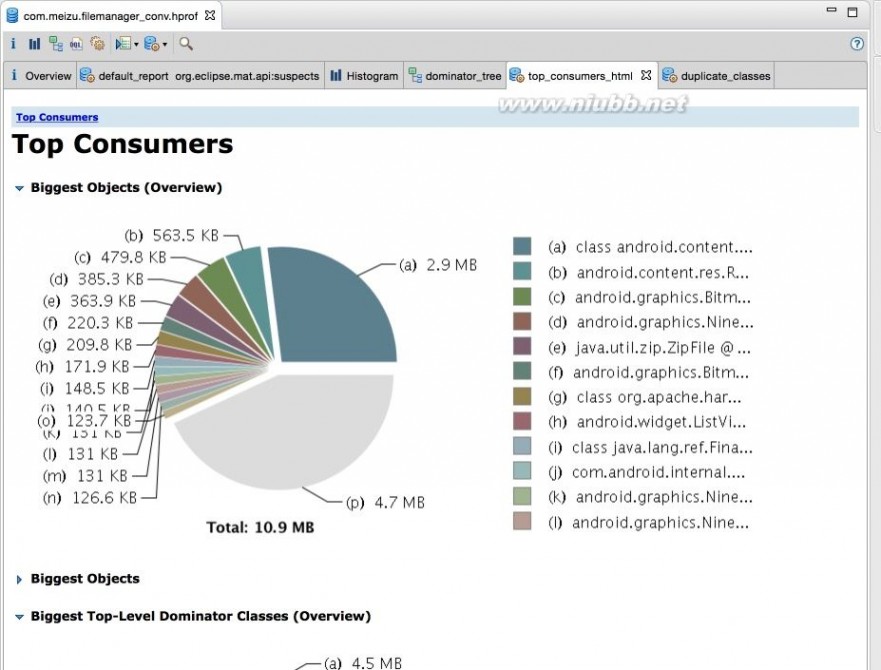
Top Consumers
Duplicate Class:通过MAT自动分析泄漏的原因
一般Histogram和 Dominator Tree是最常用的。
MAT中一些概念介绍要看懂MAT的列表信息,Shallow heap、Retained Heap、GC Root这几个概念一定要弄懂。
Shallow heap
Shallow size就是对象本身占用内存的大小,不包含其引用的对象。
常规对象(非数组)的Shallow size有其成员变量的数量和类型决定。
数组的shallow size有数组元素的类型(对象类型、基本类型)和数组长度决定
因为不像c++的对象本身可以存放大量内存,java的对象成员都是些引用。真正的内存都在堆上,看起来是一堆原生的byte[], char[], int[],所以我们如果只看对象本身的内存,那么数量都很小。所以我们看到Histogram图是以Shallow size进行排序的,排在第一位第二位的是byte,char 。
Retained Heap
Retained Heap的概念,它表示如果一个对象被释放掉,那会因为该对象的释放而减少引用进而被释放的所有的对象(包括被递归释放的)所占用的heap大小。于是,如果一个对象的某个成员new了一大块int数组,那这个int数组也可以计算到这个对象中。相对于shallow heap,Retained heap可以更精确的反映一个对象实际占用的大小(因为如果该对象释放,retained heap都可以被释放)。
这里要说一下的是,Retained Heap并不总是那么有效。例如我在A里new了一块内存,赋值给A的一个成员变量。此时我让B也指向这块内存。此时,因为A和B都引用到这块内存,所以A释放时,该内存不会被释放。所以这块内存不会被计算到A或者B的Retained Heap中。为了纠正这点,MAT中的Leading Object(例如A或者B)不一定只是一个对象,也可以是多个对象。此时,(A, B)这个组合的Retained Set就包含那块大内存了。对应到MAT的UI中,在Histogram中,可以选择Group By class, superclass or package来选择这个组。
为了计算Retained Memory,MAT引入了Dominator Tree。加入对象A引用B和C,B和C又都引用到D(一个菱形)。此时要计算Retained Memory,A的包括A本身和B,C,D。B和C因为共同引用D,所以他俩的Retained Memory都只是他们本身。D当然也只是自己。我觉得是为了加快计算的速度,MAT改变了对象引用图,而转换成一个对象引用树。在这里例子中,树根是A,而B,C,D是他的三个儿子。B,C,D不再有相互关系。把引用图变成引用树,计算Retained Heap就会非常方便,显示也非常方便。对应到MAT UI上,在dominator tree这个view中,显示了每个对象的shallow heap和retained heap。然后可以以该节点位树根,一步步的细化看看retained heap到底是用在什么地方了。要说一下的是,这种从图到树的转换确实方便了内存分析,但有时候会让人有些疑惑。本来对象B是对象A的一个成员,但因为B还被C引用,所以B在树中并不在A下面,而很可能是平级。
为了纠正这点,MAT中点击右键,可以List objects中选择with outgoing references和with incoming references。这是个真正的引用图的概念,
outgoing references :表示该对象的出节点(被该对象引用的对象)。
incoming references :表示该对象的入节点(引用到该对象的对象)。
为了更好地理解Retained Heap,下面引用一个例子来说明:
把内存中的对象看成下图中的节点,并且对象和对象之间互相引用。这里有一个特殊的节点GC Roots,这就是reference chain(引用链)的起点:
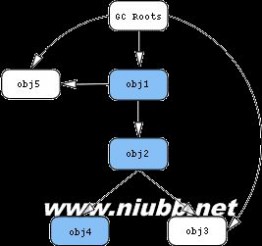
Paste_Image.png
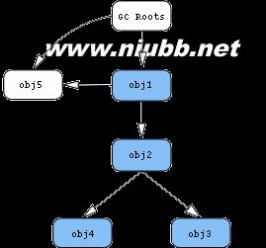
Paste_Image.png
从obj1入手,上图中蓝色节点代表仅仅只有通过obj1才能直接或间接访问的对象。因为可以通过GC Roots访问,所以左图的obj3不是蓝色节点;而在右图却是蓝色,因为它已经被包含在retained集合内。
所以对于左图,obj1的retained size是obj1、obj2、obj4的shallow size总和;
右图的retained size是obj1、obj2、obj3、obj4的shallow size总和。
obj2的retained size可以通过相同的方式计算。
GC Root
GC发现通过任何reference chain(引用链)无法访问某个对象的时候,该对象即被回收。名词GC Roots正是分析这一过程的起点,例如JVM自己确保了对象的可到达性(那么JVM就是GC Roots),所以GC Roots就是这样在内存中保持对象可到达性的,一旦不可到达,即被回收。通常GC Roots是一个在current thread(当前线程)的call stack(调用栈)上的对象(例如方法参数和局部变量),或者是线程自身或者是system class loader(系统类加载器)加载的类以及native code(本地代码)保留的活动对象。所以GC Roots是分析对象为何还存活于内存中的利器。
MAT中的一些有用的视图
Thread OvewView
Thread OvewView可以查看这个应用的Thread信息:
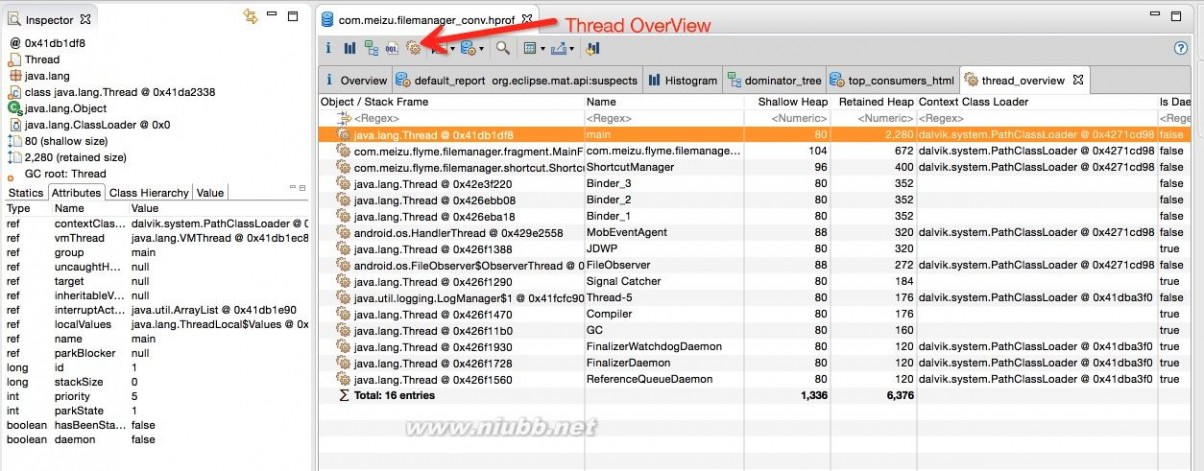
Thread OvewView
Group
在Histogram和Domiantor Tree界面,可以选择将结果用另一种Group的方式显示(默认是Group by Object),切换到Group by package,可以更好地查看具体是哪个包里的类占用内存大,也很容易定位到自己的应用程序。
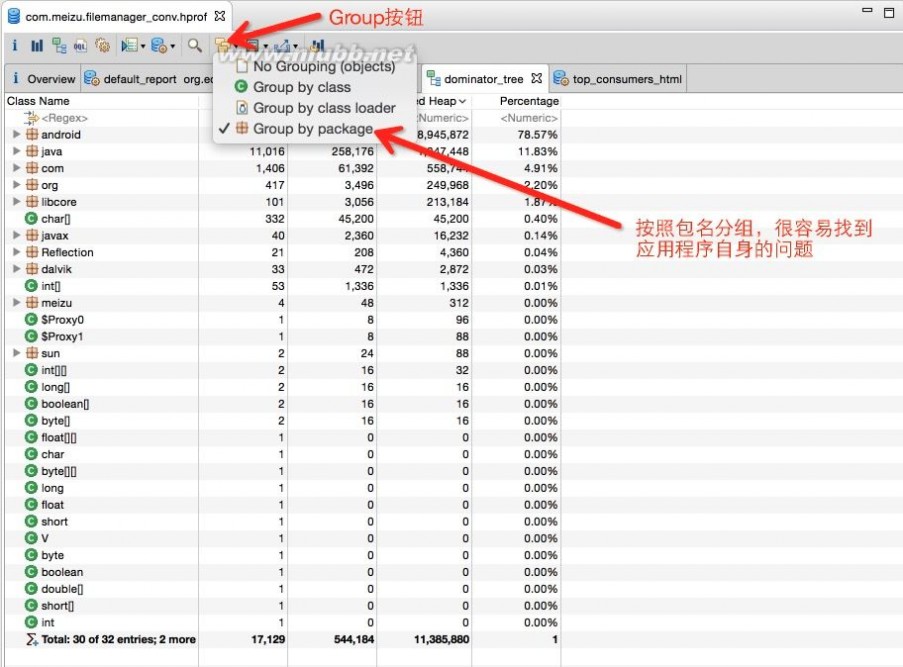
Group
Path to GC Root
在Histogram或者Domiantor Tree的某一个条目上,右键可以查看其GC Root Path:
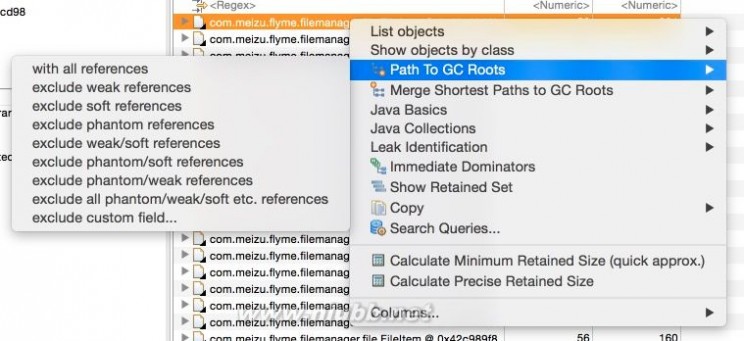
Path to GC Root
这里也要说明一下Java的引用规则:
从最强到最弱,不同的引用(可到达性)级别反映了对象的生命周期。
Strong Ref(强引用):通常我们编写的代码都是Strong Ref,于此对应的是强可达性,只有去掉强可达,对象才被回收。
Soft Ref(软引用):对应软可达性,只要有足够的内存,就一直保持对象,直到发现内存吃紧且没有Strong Ref时才回收对象。一般可用来实现缓存,通过java.lang.ref.SoftReference类实现。
Weak Ref(弱引用):比Soft Ref更弱,当发现不存在Strong Ref时,立刻回收对象而不必等到内存吃紧的时候。通过java.lang.ref.WeakReference和java.util.WeakHashMap类实现。
Phantom Ref(虚引用):根本不会在内存中保持任何对象,你只能使用Phantom Ref本身。一般用于在进入finalize()方法后进行特殊的清理过程,通过 java.lang.ref.PhantomReference实现。
点击Path To GC Roots --> with all references
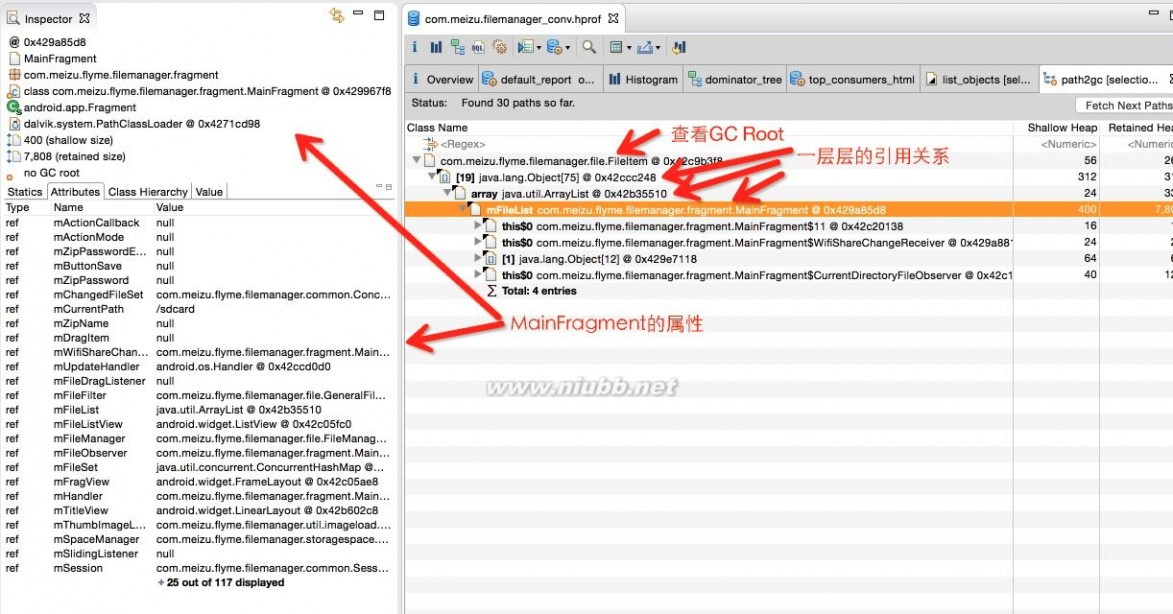
Path To GC Roots
参考文档
Shallow and retained sizes
MAT的wiki:http://wiki.eclipse.org/index.php/MemoryAnalyzer
四 : awk 用法(使用入门)
awk 用法:awk ' pattern {action} '
变量名 含义
ARGC 命令行变元个数
ARGV 命令行变元数组
FILENAME 当前输入文件名
FNR 当前文件中的记录号
FS 输入域分隔符,默认为一个空格
RS 输入记录分隔符
NF 当前记录里域个数
NR 到目前为止记录数
OFS 输出域分隔符
ORS 输出记录分隔符
1、awk '/101/' file 显示文件file中包含101的匹配行。[www.61k.com]
awk '/101/,/105/' file
awk '$1 == 5' file
awk '$1 == "CT"' file 注意必须带双引号
awk '$1 * $2 >100 ' file
awk '$2 >5 && $2<=15' file
2、awk '{print NR,NF,$1,$NF,}' file 显示文件file的当前记录号、域数和每一行的第一个和最后一个域。
awk '/101/ {print $1,$2 + 10}' file 显示文件file的匹配行的第一、二个域加10。
awk '/101/ {print $1$2}' file
awk '/101/ {print $1 $2}' file 显示文件file的匹配行的第一、二个域,但显示时域中间没有分隔符。
3、df | awk '$4>1000000 ' 通过管道符获得输入,如:显示第4个域满足条件的行。
4、awk -F "|" '{print $1}' file 按照新的分隔符“|”进行操作。
awk 'BEGIN { FS="[: \t|]" }
{print $1,$2,$3}' file 通过设置输入分隔符(FS="[: \t|]")修改输入分隔符。
Sep="|"
awk -F $Sep '{print $1}' file 按照环境变量Sep的值做为分隔符。
awk -F '[ :\t|]' '{print $1}' file 按照正则表达式的值做为分隔符,这里代表空格、:、TAB、|同时做为分隔符。
awk -F '[][]' '{print $1}' file 按照正则表达式的值做为分隔符,这里代表[、]
5、awk -f awkfile file 通过文件awkfile的内容依次进行控制。
cat awkfile
/101/{print "\047 Hello! \047"} --遇到匹配行以后打印 ' Hello! '. \047代表单引号。
{print $1,$2} --因为没有模式控制,打印每一行的前两个域。
6、awk '$1 ~ /101/ {print $1}' file 显示文件中第一个域匹配101的行(记录)。
7、awk 'BEGIN { OFS="%"}
{print $1,$2}' file 通过设置输出分隔符(OFS="%")修改输出格式。
8、awk 'BEGIN { max=100 ;print "max=" max} BEGIN 表示在处理任意行之前进行的操作。
{max=($1 >max ?$1:max); print $1,"Now max is "max}' file 取得文件第一个域的最大值。
(表达式1?表达式2:表达式3 相当于:
if (表达式1)
表达式2
else
表达式3
awk '{print ($1>4 ? "high "$1: "low "$1)}' file
9、awk '$1 * $2 >100 {print $1}' file 显示文件中第一个域匹配101的行(记录)。
10、awk '{$1 == 'Chi' {$3 = 'China'; print}' file 找到匹配行后先将第3个域替换后再显示该行(记录)。
awk '{$7 %= 3; print $7}' file 将第7域被3除,并将余数赋给第7域再打印。
11、awk '/tom/ {wage=$2+$3; printf wage}' file 找到匹配行后为变量wage赋值并打印该变量。
12、awk '/tom/ {count++;}
END {print "tom was found "count" times"}' file END表示在所有输入行处理完后进行处理。
13、awk 'gsub(/\$/,"");gsub(/,/,""); cost+=$4;
END {print "The total is $" cost>"filename"}' file gsub函数用空串替换$和,再将结果输出到filename中。
1 2 3 $1,200.00
1 2 3 $2,300.00
1 2 3 $4,000.00
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>1000&&$4<2000) c1+=$4;
else if ($4>2000&&$4<3000) c2+=$4;
else if ($4>3000&&$4<4000) c3+=$4;
else c4+=$4; }
END {printf "c1=[%d];c2=[%d];c3=[%d];c4=[%d]\n",c1,c2,c3,c4}"' file
通过if和else if完成条件语句
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>3000&&$4<4000) exit;
else c4+=$4; }
END {printf "c1=[%d];c2=[%d];c3=[%d];c4=[%d]\n",c1,c2,c3,c4}"' file
通过exit在某条件时退出,但是仍执行END操作。
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>3000) next;
else c4+=$4; }
END {printf "c4=[%d]\n",c4}"' file
通过next在某条件时跳过该行,对下一行执行操作。
14、awk '{ print FILENAME,$0 }' file1 file2 file3>fileall 把file1、file2、file3的文件内容全部写到fileall中,格式为
打印文件并前置文件名。
15、awk ' $1!=previous { close(previous); previous=$1 }
{print substr($0,index($0," ") +1)>$1}' fileall 把合并后的文件重新分拆为3个文件。并与原文件一致。
16、awk 'BEGIN {"date"|getline d; print d}' 通过管道把date的执行结果送给getline,并赋给变量d,然后打印。
17、awk 'BEGIN {system("echo \"Input your name:\\c\""); getline d;print "\nYour name is",d,"\b!\n"}'
通过getline命令交互输入name,并显示出来。
awk 'BEGIN {FS=":"; while(getline< "/etc/passwd" >0) { if($1~"050[0-9]_") print $1}}'
打印/etc/passwd文件中用户名包含050x_的用户名。
18、awk '{ i=1;while(i<NF) {print NF,$i;i++}}' file 通过while语句实现循环。
awk '{ for(i=1;i<NF;i++) {print NF,$i}}' file 通过for语句实现循环。
type file|awk -F "/" '
{ for(i=1;i<NF;i++)
{ if(i==NF-1) { printf "%s",$i }
else { printf "%s/",$i } }}' 显示一个文件的全路径。
用for和if显示日期
awk 'BEGIN {
for(j=1;j<=12;j++)
{ flag=0;
printf "\n%d月份\n",j;
for(i=1;i<=31;i++)
{
if (j==2&&i>28) flag=1;
if ((j==4||j==6||j==9||j==11)&&i>30) flag=1;
if (flag==0) {printf "%02d%02d ",j,i}
}
}
}'
19、在awk中调用系统变量必须用单引号,如果是双引号,则表示字符串
Flag=abcd
awk '{print '$Flag'}' 结果为abcd
awk '{print "$Flag"}' 结果为$Flag
===============================
$awk 'BEGIN{total=0}{total+=$4}END{print total}' a.txt -----对a.txt文件的第四个域进行求和!
$ awk '/^(no|so)/' test -----打印所有以模式no或so开头的行。
$ awk '/^[ns]/{print $1}' test -----如果记录以n或s开头,就打印这个记录。
$ awk '$1 ~/[0-9][0-9]$/(print $1}' test -----如果第一个域以两个数字结束就打印这个记录。
$ awk '$1 == 100 || $2 < 50' test -----如果第一个或等于100或者第二个域小于50,则打印该行。
$ awk '$1 != 10' test -----如果第一个域不等于10就打印该行。
$ awk '/test/{print $1 + 10}' test -----如果记录包含正则表达式test,则第一个域加10并打印出来。
$ awk '{print ($1 > 5 ? "ok "$1: "error"$1)}' test -----如果第一个域大于5则打印问号后面的表达式值,否则打印冒号后面的表达式值。
$ awk '/^root/,/^mysql/' test ----打印以正则表达式root开头的记录到以正则表达式mysql开头的记录范围内的所有记录。如果找到一个新的正则表达式root开头的记录,则继续打印直到下一个以正则表达式mysql开头的记录为止,或到文件末尾。
===============================
Table of Contents
1. awk简介
awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk的处理文本和数据的方式是这样的,它逐行扫描文件,从第一行到最后一行,寻找匹配的特定模式的行,并在这些行上进行你想要的操作。如果没有指定处理动作,则把匹配的行显示到标准输出(屏幕),如果没有指定模式,则所有被操作所指定的行都被处理。awk分别代表其作者姓氏的第一个字母。因为它的作者是三个人,分别是Alfred Aho、Brian Kernighan、Peter Weinberger。gawk是awk的GNU版本,它提供了Bell实验室和GNU的一些扩展。下面介绍的awk是以GUN的gawk为例的,在linux系统中已把awk链接到gawk,所以下面全部以awk进行介绍。
2. awk命令格式和选项
2.1. awk的语法有两种形式
awk [options] 'script' var=value file(s)
awk [options] -f scriptfile var=value file(s)
2.2. 命令选项
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
赋值一个用户定义变量。
从脚本文件中读取awk命令。
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
打印简短的版权信息。
打印全部awk选项和每个选项的简短说明。
打印不能向传统unix平台移植的结构的警告。
打印关于不能向传统unix平台移植的结构的警告。
打开兼容模式。但有以下限制,不识别:\x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
使用program-text作为源代码,可与-f命令混用。
打印bug报告信息的版本。
3. 模式和操作
pattern {action} 如$ awk '/root/' test,或$ awk '$3 < 100' test。
两者是可选的,如果没有模式,则action应用到全部记录,如果没有action,则输出匹配全部记录。默认情况下,每一个输入行都是一条记录,但用户可通过RS变量指定不同的分隔符进行分隔。
3.1. 模式
模式可以是以下任意一个:
/正则表达式/:使用通配符的扩展集。
关系表达式:可以用下面运算符表中的关系运算符进行操作,可以是字符串或数字的比较,如$2>%1选择第二个字段比第一个字段长的行。
模式匹配表达式:用运算符~(匹配)和~!(不匹配)。
模式,模式:指定一个行的范围。该语法不能包括BEGIN和END模式。
BEGIN:让用户指定在第一条输入记录被处理之前所发生的动作,通常可在这里设置全局变量。
END:让用户在最后一条输入记录被读取之后发生的动作。
3.2. 操作
操作由一人或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大括号内。主要有四部份:
变量或数组赋值
输出命令
内置函数
控制流命令
4. awk的环境变量
Table 1. awk的环境变量
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔。 |
| $0 | 完整的输入记录。 |
| ARGC | 命令行参数的数目。 |
| ARGIND | 命令行中当前文件的位置(从0开始算)。 |
| ARGV | 包含命令行参数的数组。 |
| CONVFMT | 数字转换格式(默认值为%.6g) |
| ENVIRON | 环境变量关联数组。 |
| ERRNO | 最后一个系统错误的描述。 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔)。 |
| FILENAME | 当前文件名。 |
| FNR | 同NR,但相对于当前文件。 |
| FS | 字段分隔符(默认是任何空格)。 |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配。 |
| NF | 当前记录中的字段数。 |
| NR | 当前记录数。 |
| OFMT | 数字的输出格式(默认值是%.6g)。 |
| OFS | 输出字段分隔符(默认值是一个空格)。 |
| ORS | 输出记录分隔符(默认值是一个换行符)。 |
| RLENGTH | 由match函数所匹配的字符串的长度。 |
| RS | 记录分隔符(默认是一个换行符)。 |
| RSTART | 由match函数所匹配的字符串的第一个位置。 |
| SUBSEP | 数组下标分隔符(默认值是\034)。 |
5. awk运算符
Table 2. 运算符
| 运算符 | 描述 |
|---|---|
| = += -= *= /= %= ^= **= | 赋值 |
| ?: | C条件表达式 |
| || | 逻辑或 |
| && | 逻辑与 |
| ~ ~! | 匹配正则表达式和不匹配正则表达式 |
| < <= > >= != == | 关系运算符 |
| 空格 | 连接 |
| + - | 加,减 |
| * / & | 乘,除与求余 |
| + - ! | 一元加,减和逻辑非 |
| ^ *** | 求幂 |
| ++ -- | 增加或减少,作为前缀或后缀 |
| $ | 字段引用 |
| in | 数组成员 |
6. 记录和域
6.1. 记录
awk把每一个以换行符结束的行称为一个记录。
记录分隔符:默认的输入和输出的分隔符都是回车,保存在内建变量ORS和RS中。
$0变量:它指的是整条记录。如$ awk '{print $0}' test将输出test文件中的所有记录。
变量NR:一个计数器,每处理完一条记录,NR的值就增加1。如$ awk '{print NR,$0}' test将输出test文件中所有记录,并在记录前显示记录号。
6.2. 域
记录中每个单词称做“域”,默认情况下以空格或tab分隔。awk可跟踪域的个数,并在内建变量NF中保存该值。如$ awk '{print $1,$3}' test将打印test文件中第一和第三个以空格分开的列(域)。
6.3. 域分隔符
内建变量FS保存输入域分隔符的值,默认是空格或tab。我们可以通过-F命令行选项修改FS的值。如$ awk -F: '{print $1,$5}' test将打印以冒号为分隔符的第一,第五列的内容。
可以同时使用多个域分隔符,这时应该把分隔符写成放到方括号中,如$awk -F'[:\t]' '{print $1,$3}' test,表示以空格、冒号和tab作为分隔符。
输出域的分隔符默认是一个空格,保存在OFS中。如$ awk -F: '{print $1,$5}' test,$1和$5间的逗号就是OFS的值。
7. gawk专用正则表达式元字符
以下几个是gawk专用的,不适合unix版本的awk。
匹配一个单词开头或者末尾的空字符串。
匹配单词内的空字符串。
匹配一个单词的开头的空字符串,锚定开始。
匹配一个单词的末尾的空字符串,锚定末尾。
匹配一个字母数字组成的单词。
匹配一个非字母数字组成的单词。
匹配字符串开头的一个空字符串。
匹配字符串末尾的一个空字符串。
8. POSIX字符集
9. 匹配操作符(~)
用来在记录或者域内匹配正则表达式。如$ awk '$1 ~/^root/' test将显示test文件第一列中以root开头的行。
10. 比较表达式
conditional expression1 ? expression2: expression3,例如:$ awk '{max = {$1 > $3} ? $1: $3: print max}' test。如果第一个域大于第三个域,$1就赋值给max,否则$3就赋值给max。
$ awk '$1 + $2 < 100' test。如果第一和第二个域相加大于100,则打印这些行。
$ awk '$1 > 5 && $2 < 10' test,如果第一个域大于5,并且第二个域小于10,则打印这些行。
11. 范围模板
范围模板匹配从第一个模板的第一次出现到第二个模板的第一次出现之间所有行。如果有一个模板没出现,则匹配到开头或末尾。如$ awk '/root/,/mysql/' test将显示root第一次出现到mysql第一次出现之间的所有行。
12. 一个验证passwd文件有效性的例子
$ cat /etc/passwd | awk -F: '\$2 == "*" {printf("line %d, no password: %s\n",NR,$0)}'
cat把结果输出给awk,awk把域之间的分隔符设为冒号。 | |
如果域的数量(NF)不等于7,就执行下面的程序。 | |
printf打印字符串"line ?? does not have 7 fields",并显示该条记录。 | |
如果第一个域没有包含任何字母和数字,printf打印“no alpha and numeric user id" ,并显示记录数和记录。 | |
如果第二个域是一个星号,就打印字符串“no passwd”,紧跟着显示记录数和记录本身。 |
13. 几个实例
$ awk '/^(no|so)/' test-----打印所有以模式no或so开头的行。
$ awk '/^[ns]/{print $1}' test-----如果记录以n或s开头,就打印这个记录。
$ awk '$1 ~/[0-9][0-9]$/(print $1}' test-----如果第一个域以两个数字结束就打印这个记录。
$ awk '$1 == 100 || $2 < 50' test-----如果第一个或等于100或者第二个域小于50,则打印该行。
$ awk '$1 != 10' test-----如果第一个域不等于10就打印该行。
$ awk '/test/{print $1 + 10}' test-----如果记录包含正则表达式test,则第一个域加10并打印出来。
$ awk '{print ($1 > 5 ? "ok "$1: "error"$1)}' test-----如果第一个域大于5则打印问号后面的表达式值,否则打印冒号后面的表达式值。
$ awk '/^root/,/^mysql/' test----打印以正则表达式root开头的记录到以正则表达式mysql开头的记录范围内的所有记录。如果找到一个新的正则表达式root开头的记录,则继续打印直到下一个以正则表达式mysql开头的记录为止,或到文件末尾。
14. awk编程
14.1. 变量
在awk中,变量不需要定义就可以直接使用,变量类型可以是数字或字符串。
赋值格式:Variable = expression,如$ awk '$1 ~/test/{count = $2 + $3; print count}' test,上式的作用是,awk先扫描第一个域,一旦test匹配,就把第二个域的值加上第三个域的值,并把结果赋值给变量count,最后打印出来。
awk可以在命令行中给变量赋值,然后将这个变量传输给awk脚本。如$ awk -F: -f awkscript month=4 year=2004 test,上式的month和year都是自定义变量,分别被赋值为4和2004。在awk脚本中,这些变量使用起来就象是在脚本中建立的一样。注意,如果参数前面出现test,那么在BEGIN语句中的变量就不能被使用。
域变量也可被赋值和修改,如$ awk '{$2 = 100 + $1; print }' test,上式表示,如果第二个域不存在,awk将计算表达式100加$1的值,并将其赋值给$2,如果第二个域存在,则用表达式的值覆盖$2原来的值。再例如:$ awk '$1 == "root"{$1 ="test";print}' test,如果第一个域的值是“root”,则把它赋值为“test”,注意,字符串一定要用双引号。
内建变量的使用。变量列表在前面已列出,现在举个例子说明一下。$ awk -F: '{IGNORECASE=1; $1 == "MARY"{print NR,$1,$2,$NF}'test,把IGNORECASE设为1代表忽略大小写,打印第一个域是mary的记录数、第一个域、第二个域和最后一个域。
14.2. BEGIN模块
BEGIN模块后紧跟着动作块,这个动作块在awk处理任何输入文件之前执行。所以它可以在没有任何输入的情况下进行测试。它通常用来改变内建变量的值,如OFS,RS和FS等,以及打印标题。如:$ awk 'BEGIN{FS=":"; OFS="\t"; ORS="\n\n"}{print $1,$2,$3} test。上式表示,在处理输入文件以前,域分隔符(FS)被设为冒号,输出文件分隔符(OFS)被设置为制表符,输出记录分隔符(ORS)被设置为两个换行符。$ awk 'BEGIN{print "TITLE TEST"}只打印标题。
14.3. END模块
END不匹配任何的输入文件,但是执行动作块中的所有动作,它在整个输入文件处理完成后被执行。如$ awk 'END{print "The number of records is" NR}' test,上式将打印所有被处理的记录数。
14.4. 重定向和管道
awk可使用shell的重定向符进行重定向输出,如:$ awk '$1 = 100 {print $1 > "output_file" }' test。上式表示如果第一个域的值等于100,则把它输出到output_file中。也可以用>>来重定向输出,但不清空文件,只做追加操作。
输出重定向需用到getline函数。getline从标准输入、管道或者当前正在处理的文件之外的其他输入文件获得输入。它负责从输入获得下一行的内容,并给NF,NR和FNR等内建变量赋值。如果得到一条记录,getline函数返回1,如果到达文件的末尾就返回0,如果出现错误,例如打开文件失败,就返回-1。如:
$ awk 'BEGIN{ "date" |getlined; print d}' test。执行linux的date命令,并通过管道输出给getline,然后再把输出赋值给自定义变量d,并打印它。
$ awk 'BEGIN{"date" |getlined; split(d,mon); print mon[2]}' test。执行shell的date命令,并通过管道输出给getline,然后getline从管道中读取并将输入赋值给d,split函数把变量d转化成数组mon,然后打印数组mon的第二个元素。
$ awk 'BEGIN{while( "ls" |getline) print}',命令ls的输出传递给geline作为输入,循环使getline从ls的输出中读取一行,并把它打印到屏幕。这里没有输入文件,因为BEGIN块在打开输入文件前执行,所以可以忽略输入文件。
$ awk 'BEGIN{printf "What is your name?"; getline name < "/dev/tty" } $1 ~name {print "Found" name on line ", NR "."} END{print "See you," name "."} test。在屏幕上打印”What is your name?",并等待用户应答。当一行输入完毕后,getline函数从终端接收该行输入,并把它储存在自定义变量name中。如果第一个域匹配变量name的值,print函数就被执行,END块打印See you和name的值。
$ awk 'BEGIN{while (getline < "/etc/passwd" > 0) lc++; print lc}'。awk将逐行读取文件/etc/passwd的内容,在到达文件末尾前,计数器lc一直增加,当到末尾时,打印lc的值。注意,如果文件不存在,getline返回-1,如果到达文件的末尾就返回0,如果读到一行,就返回1,所以命令 while (getline < "/etc/passwd")在文件不存在的情况下将陷入无限循环,因为返回-1表示逻辑真。
可以在awk中打开一个管道,且同一时刻只能有一个管道存在。通过close()可关闭管道。如:$ awk '{print $1, $2 | "sort" }' test END {close("sort")}。awd把print语句的输出通过管道作为linux命令sort的输入,END块执行关闭管道操作。
system函数可以在awk中执行linux的命令。如:$ awk 'BEGIN{system("clear")'。
fflush函数用以刷新输出缓冲区,如果没有参数,就刷新标准输出的缓冲区,如果以空字符串为参数,如fflush(""),则刷新所有文件和管道的输出缓冲区。
14.5. 条件语句
awk中的条件语句是从C语言中借鉴过来的,可控制程序的流程。
14.5.1. if 语句
格式: {if (expression){ statement; statement; ... } }$ awk '{if ($1 <$2) print $2 "too high"}' test。如果第一个域小于第二个域则打印。
$ awk '{if ($1 < $2) {count++; print "ok"}}' test.如果第一个域小于第二个域,则count加一,并打印ok。
14.5.2. if/else语句,用于双重判断
格式: {if (expression){ statement; statement; ... } else{ statement; statement; ... } }$ awk '{if ($1 > 100) print $1 "bad" ; else print "ok"}' test。如果$1大于100则打印$1 bad,否则打印ok。
$ awk '{if ($1 > 100){ count++; print $1} else {count--; print $2}' test。如果$1大于100,则count加一,并打印$1,否则count减一,并打印$1。
14.5.3. if/else else if语句,用于多重判断。
格式: {if (expression){ statement; statement; ... } else if (expression){ statement; statement; ... } else if (expression){ statement; statement; ... } else { statement; statement; ... } }14.6. 循环
awk有三种循环:while循环;for循环;special for循环。
$ awk '{ i = 1; while ( i <= NF ) { print NF,$i; i++}}' test。变量的初始值为1,若i小于可等于NF(记录中域的个数),则执行打印语句,且i增加1。直到i的值大于NF.
$ awk '{for (i = 1; i<NF; i++) print NF,$i}' test。作用同上。
breadcontinue语句。break用于在满足条件的情况下跳出循环;continue用于在满足条件的情况下忽略后面的语句,直接返回循环的顶端。如:
{for ( x=3; x<=NF; x++) if ($x<0){print "Bottomed out!"; break}} {for ( x=3; x<=NF; x++) if ($x==0){print "Get next item"; continue}}next语句从输入文件中读取一行,然后从头开始执行awk脚本。如:
{if ($1 ~/test/){next} else {print} }exit语句用于结束awk程序,但不会略过END块。退出状态为0代表成功,非零值表示出错。
14.7. 数组
awk中的数组的下标可以是数字和字母,称为关联数组。
14.7.1. 下标与关联数组
用变量作为数组下标。如:$ awk {name[x++]=$2};END{for(i=0;i<NR;i++) print i,name[i]}' test。数组name中的下标是一个自定义变量x,awk初始化x的值为0,在每次使用后增加1。第二个域的值被赋给name数组的各个元素。在END模块中,for循环被用于循环整个数组,从下标为0的元素开始,打印那些存储在数组中的值。因为下标是关健字,所以它不一定从0开始,可以从任何值开始。
special for 循环用于读取关联数组中的元素。格式如下:
{for (item in arrayname){ print arrayname[item] } }$ awk '/^tom/{name[NR]=$1}; END{for(i in name){print name[i]}}' test。打印有值的数组元素。打印的顺序是随机的。用字符串作为下标。如:count["test"]
用域值作为数组的下标。一种新的for循环方式,for (index_value in array) statement。如:$ awk '{count[$1]++} END{for(name in count) print name,count[name]}' test。该语句将打印$1中字符串出现的次数。它首先以第一个域作数组count的下标,第一个域变化,索引就变化。
delete 函数用于删除数组元素。如:$ awk '{line[x++]=$1} END{for(x in line) delete(line[x])}' test。分配给数组line的是第一个域的值,所有记录处理完成后,special for循环将删除每一个元素。
14.8. awk的内建函数
14.8.1. 字符串函数
sub函数匹配记录中最大、最靠左边的子字符串的正则表达式,并用替换字符串替换这些字符串。如果没有指定目标字符串就默认使用整个记录。替换只发生在第一次匹配的时候。格式如下:
sub (regular expression, substitution string): sub (regular expression, substitution string, target string)
实例:
$ awk '{ sub(/test/, "mytest"); print }' testfile $ awk '{ sub(/test/, "mytest"); $1}; print }' testfile第一个例子在整个记录中匹配,替换只发生在第一次匹配发生的时候。如要在整个文件中进行匹配需要用到gsub
第二个例子在整个记录的第一个域中进行匹配,替换只发生在第一次匹配发生的时候。
gsub函数作用如sub,但它在整个文档中进行匹配。格式如下:
gsub (regular expression, substitution string) gsub (regular expression, substitution string, target string)
实例:
$ awk '{ gsub(/test/, "mytest"); print }' testfile $ awk '{ gsub(/test/, "mytest" , $1) }; print }' testfile第一个例子在整个文档中匹配test,匹配的都被替换成mytest。
第二个例子在整个文档的第一个域中匹配,所有匹配的都被替换成mytest。
index函数返回子字符串第一次被匹配的位置,偏移量从位置1开始。格式如下:
index(string, substring)
实例:
$ awk '{ print index("test", "mytest") }' testfile实例返回test在mytest的位置,结果应该是3。
length函数返回记录的字符数。格式如下:
length( string ) length
实例:
$ awk '{ print length( "test" ) }' $ awk '{ print length }' testfile第一个实例返回test字符串的长度。
第二个实例返回testfile文件中第条记录的字符数。
substr函数返回从位置1开始的子字符串,如果指定长度超过实际长度,就返回整个字符串。格式如下:
substr( string, starting position ) substr( string, starting position, length of string )
实例:
$ awk '{ print substr( "hello world", 7,11 ) }'上例截取了world子字符串。
match函数返回在字符串中正则表达式位置的索引,如果找不到指定的正则表达式则返回0。match函数会设置内建变量RSTART为字符串中子字符串的开始位置,RLENGTH为到子字符串末尾的字符个数。substr可利于这些变量来截取字符串。函数格式如下:
match( string, regular expression )
实例:
$ awk '{start=match("this is a test",/[a-z]+$/); print start}' $ awk '{start=match("this is a test",/[a-z]+$/); print start, RSTART, RLENGTH }'第一个实例打印以连续小写字符结尾的开始位置,这里是11。
第二个实例还打印RSTART和RLENGTH变量,这里是11(start),11(RSTART),4(RLENGTH)。
toupper和tolower函数可用于字符串大小间的转换,该功能只在gawk中有效。格式如下:
toupper( string ) tolower( string )
实例:
$ awk '{ print toupper("test"), tolower("TEST") }'split函数可按给定的分隔符把字符串分割为一个数组。如果分隔符没提供,则按当前FS值进行分割。格式如下:
split( string, array, field separator ) split( string, array )
实例:
$ awk '{ split( "20:18:00", time, ":" ); print time[2] }'上例把时间按冒号分割到time数组内,并显示第二个数组元素18。
14.8.2. 时间函数
systime函数返回从1970年1月1日开始到当前时间(不计闰年)的整秒数。格式如下:
systime()
实例:
$ awk '{ now = systime(); print now }'strftime函数使用C库中的strftime函数格式化时间。格式如下:
systime( [format specification][,timestamp] )
Table 3. 日期和时间格式说明符
| 格式 | 描述 |
|---|---|
| %a | 星期几的缩写(Sun) |
| %A | 星期几的完整写法(Sunday) |
| %b | 月名的缩写(Oct) |
| %B | 月名的完整写法(October) |
| %c | 本地日期和时间 |
| %d | 十进制日期 |
| %D | 日期 08/20/99 |
| %e | 日期,如果只有一位会补上一个空格 |
| %H | 用十进制表示24小时格式的小时 |
| %I | 用十进制表示12小时格式的小时 |
| %j | 从1月1日起一年中的第几天 |
| %m | 十进制表示的月份 |
| %M | 十进制表示的分钟 |
| %p | 12小时表示法(AM/PM) |
| %S | 十进制表示的秒 |
| %U | 十进制表示的一年中的第几个星期(星期天作为一个星期的开始) |
| %w | 十进制表示的星期几(星期天是0) |
| %W | 十进制表示的一年中的第几个星期(星期一作为一个星期的开始) |
| %x | 重新设置本地日期(08/20/99) |
| %X | 重新设置本地时间(12:00:00) |
| %y | 两位数字表示的年(99) |
| %Y | 当前月份 |
| %Z | 时区(PDT) |
| %% | 百分号(%) |
实例:
$ awk '{ now=strftime( "%D", systime() ); print now }' $ awk '{ now=strftime("%m/%d/%y"); print now }'14.8.3. 内建数学函数
Table 4.
| 函数名称 | 返回值 |
|---|---|
| atan2(x,y) | y,x范围内的余切 |
| cos(x) | 余弦函数 |
| exp(x) | 求幂 |
| int(x) | 取整 |
| log(x) | 自然对数 |
| rand() | 随机数 |
| sin(x) | 正弦 |
| sqrt(x) | 平方根 |
| srand(x) | x是rand()函数的种子 |
| int(x) | 取整,过程没有舍入 |
| rand() | 产生一个大于等于0而小于1的随机数 |
14.8.4. 自定义函数
在awk中还可自定义函数,格式如下:
function name ( parameter, parameter, parameter, ... ) { statements return expression # the return statement and expression are optional }15. How-to
如何把一行竖排的数据转换成横排?
awk '{printf("%s,",$1)}' filename
awk中使用NR和FNR的一些例子
一般在awk里面输入文件是多个时,NR==FNR才有意义,如果这个值为true,表示还在处理第一个文件。
NR==FNR 這個一般用於讀取兩個或者兩個以上的文件中,用於判斷是在讀取第一個文件。。
test.txt 10行内容
test2.txt 4行内容
awk '{print NR,FNR}' test.txt test2.txt
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
10 10
11 1
12 2
13 3
14 4
现在有两个文件格式如下:
#cat account
张三|000001
李四|000002
#cat cdr
000001|10
000001|20
000002|30
000002|15
想要得到的结果是将用户名,帐号和金额在同一行打印出来,如下:
张三|000001|10
张三|000001|20
李四|000002|30
李四|000002|15
执行如下代码
#awk -F \| 'NR==FNR{a[$2]=$0;next}{print a[$1]"|"$2}' account cdr
注释:
由NR=FNR为真时,判断当前读入的是第一个文件account,然后使用{a[$2]=$0;next}循环将account文件的每行记录都存入数组a,并使用$2第2个字段作为下标引用.
由NR=FNR为假时,判断当前读入了第二个文件cdr,然后跳过{a[$2]=$0;next},对第二个文件cdr的每一行都无条件执行 {print a[$1]"|"$2},此时变量$1为第二个文件的第一个字段,与读入第一个文件时,采用第一个文件第二个字段$2为数组下标相同.因此可以在此使用 a[$1]引用数组。
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($1>=0.1 && $1<0.2) c1+=1;
else if ($1>=0.2 && $1<0.3) c2+=1;
else if ($1>=0.3 && $1<0.4) c3+=1;
else if ($1>=0.4 && $1<0.5) c4+=1;
else if ($1>=0.5 && $1<0.6) c5+=1;
else if ($1>=0.6 && $1<0.7) c6+=1;
else if ($1>=0.7 && $1<0.8) c7+=1;
else if ($1>=0.8 && $1<0.9) c8+=1;
else if ($1>=0.9 ) c9+=1;
else c10+=1; }
END {printf "%d\t%d\t%d\t%d\t%d\t%d\t%d\t%d\t%d\t%d\t",c1,c2,c3,c4,c5,c6,c7,c8,c9,c10} ' /NEW
示例/例子:
awk '{if($0~/^>.*$/) {tmp=$0; getline; if( length($0)>=200) {print tmp"\n"$0; } }}' filename
awk '{if($0~/^>.*$/) {IGNORECASE=1; if($0~/PREDICTED/) {getline;} else {print $0; getline; print $0; } }}' filename
awk '{if($0~/^>.*$/) {IGNORECASE=1; if($0~/mRNA/) {print $0; getline; print $0; } else {getline;} }}' filename
awk '{ temp=$0; getline; if($0~/unavailable/) {;} else {print temp"\n"$0;} }' filename
substr($4,20) ---> 表示是从第4个字段里的第20个字符开始,一直到设定的分隔符","结束.
substr($3,12,8) ---> 表示是从第3个字段里的第12个字符开始,截取8个字符结束.
一、awk字符串转数字
$ awk 'BEGIN{a="100";b="10test10";print (a+b+0);}'
110
只需要将变量通过”+”连接运算。自动强制将字符串转为整型。非数字变成0,发现第一个非数字字符,后面自动忽略。
二、awk数字转为字符串
$ awk 'BEGIN{a=100;b=100;c=(a""b);print c}'
100100
只需要将变量与””符号连接起来运算即可。
三、awk字符串连接操作(字符串连接;链接;串联)
$ awk 'BEGIN{a="a";b="b";c=(a""b);print c}'
ab
$ awk 'BEGIN{a="a";b="b";c=(a+b);print c}'
0
把文件中的各行串联起来:
awk 'BEGIN{xxxx="";}{xxxx=(xxxx""$0);}END{print xxxx}' temp.txt
awk 'BEGIN{xxxx="";}{xxxx=(xxxx"\",\""$0);}END{print xxxx}' temp.txt
61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1