一 : AMD推土机FX处理器最新架构详细解析
AMD推土机FX处理器最新架构详细解析
第1页:Bulldozer FX处理器最新架构解析
在加州举行的年度高性能处理器研讨会Hot-Chips 23上,IBM、Intel、AMD等各大巨头都没有公布全新的产品或者技术,而是继续翻出老一套进行深入宣传和“布道”,AMD最重点的当然就是“推土机”了。

推土机的核心架构图我们已经见识过很多次了,但这种来自AMD官方、详细标注各个模块名称和相对大小的却不多见,而且它第一次公开了推土机处理器的核心面积:八核心型号为315平方毫米。做为对比,32nm Gulftown六核心为240平方毫米,32nm Sandy Bridge四/双核心为216/149平方毫米,45nm Phenom II X6/X4分别为346/258平方毫米。

推土机处理器全部核心缩微图
从图上可以清晰地看到推土机的四个模块(八个核心)、四组2MB二级缓存、四组2MB三级缓存、四条HT总线、DDR3内存控制器、北桥模块、I/O输入输出等等。六核心和四核心型号都是在此基础上屏蔽部分模块(核心)和缓存而来的。

推土机处理器核心其中一个模块缩微图一张架构图和架构特性简介:推土机的家族编号为Family 15h,是AMD K8以来的首个全新设计处理器架构,最大特点就是每两个整数核心加一个浮点核心组成一个模块,进行资源的共享。
第2页:Bulldozer FX处理器采用新平台
首先,推土机处理器代表的是一个新的平台,它的桌面版本Zambeizi将改用新接口Socket AM3+,可支持低电压内存,为HT 3.0每个链接提供了最高2.0A ILDT电流,从而将HT总线速度提升到最高5.2GT/s,IDDR电流也增加到最高4.0A。

主板Socket AM3+插座具备向下兼容性,即新主板仍可安装Socket AM3接口的Phenom II/Athlon II系列处理器,但反过来不行,也就是AM3插座的主板无法使用AM3+推土机处理器。
推土机将主要搭配990FX、990X、970北桥芯片和SB950南桥芯片,理论上也向下兼容8系列芯片组,但老主板需要硬件改造或者BIOS刷新才行,而且可能无法发挥推土机的全部实力。因为老主板可能不支持IOMMU技术,未来AMD“Next-Generation GPU”下一代显卡具备X86内存寻址特性,它可以和CPU一样调用系统内存,CPU通过MMU内存控制器访问内存,而GPU则是通过IOMMU实现内存调用。
这种新技术允许系统设备在虚拟内存中进行寻址,也就是将虚拟内存地址映射为物理内存地址,让实体设备可以在虚拟的内存环境中工作,这样可以帮助系统扩充内存容量,提升性能。
另外推土机处理器还集成了两个72-bit DDR3-1866内存控制器通道,可以支持Unbuffered DIMM内存。

FX-8150结构图:这是AMD官方文档第一次明确提及FX-8150的型号命名,最终证实了它的存在,只是这里并未提及频率规格,仅仅在总体架构上做了简单示意。负责各个模块、核心同步的系统请求队列(SRQ)其实也不是新技术,从AMD第一代双核心Athlon 64 X2就有了。

内存控制器方面,此次也做了改进和调整,推土机处理器每个核心die具备两个DDR3内存控制器,每个控制器可以协调内存调用顺序,进而达到更好的性能,这点特别对于多核心die和多芯片系统使用内存有很大帮助,可以解决内存的性能瓶颈。
DDR3内存控制器除了支持DDR3-1866以外,还具备新的省电特性,支持低电压DDR3内存,具备快速自刷新、addr/cmd/bank三态无效以及让PX电路待机操作等等。

推土机的8MB三级缓存既可以共享使用,也可以独立被使用,同时还具备ECC保护功能,如果是单bit数据则有校正的功能,如果是双bit的话,则有检测的功能。
同时还具备Probe Filter探测过滤功能,处理器内部北桥模块可以对数据传输进行优化过滤,以提升系统性能。
第3页:Bulldozer比AVX更全面的指令集
2007年8月,AMD抢先宣布了SSE5指令集(之前从SSE到SSE4均为Intel制定),当时表示该指令集将于2009年推出的Bulldozer处理器中采用。但Intel随即表示,不会支持SSE5。转而在2008年3月,Intel宣布了Sandy Bridge微架构(Intel Tick-Tock策略:45nm Nehalem - 32nm Westmere - 32nm Sandy Bridge),其中将引入全新的AVX指令集。4月份,Intel公布了AVX指令集规范,随后开始不断进行更新。迫于竞争压力,AMD不得不选择支持Intel提出的AVX(高级矢量扩展)指令集,同时采用AVX架构重新改写AMD的SSE5指令集,重定义为XOP(eXtended Operations指令扩展),CVT16(半精度浮点转换)以及FMA4(4操作数乘加)。
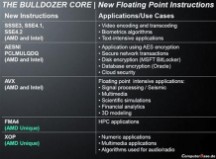
正是由于指令集方面的变动,AMD付出了惨重代价的,最终导致了Bulldozer处理器推迟了数年之久。根据AMD的高级架构师Dave Christie的说法,AMD在2007年宣布的SSE5指令集主要包括以下几项革新:3操作数指令甚至4操作数指令,置换与条件移动指令,乘加指令以及其他一系列解决现有SSE指令集缺陷的新指令。
而Intel在2008年4月公布的AVX指令集中,同样包含了SSE5指令集的多项新特性,包括3操作数指令/4操作数指令支持,乘加指令以及部分置换指令等,但实现形式与SSE5不同。并且,AVX指令集还加入了一些SSE5中没有的新特性:SIMD浮点指令长度加倍,为旧版SSE指令增加3操作数指令支持,为未来的指令扩展预留大量OpCode空间等。
由于SSE5和AVX指令集功能类似,并且AVX包含更多的优秀特性,因此AMD决定支持AVX指令集,避免让软件开发者因为要面对两套不同指令集而徒增开发难度。
不过,由于AVX指令集的制定权在Intel手中,未来还可能进行修改。AMD只能保证,其首款支持AVX指令集产品支持目前的最新版本:2009年1月发布的AVX第五版规范。并且,FMA乘加指令只支持到2008年8月的AVX第三版规范。
再来看FMA的问题。AMD此前在SSE5中就对FMA乘加指令进行了深入的开发,而Intel在2008年12月对AVX中的该指令定义进行了大幅度修改,仅支持3操作数乘加。AMD对此并不赞同,因此将保留旧版定义,并将其重新命名为FMA4(4操作数乘加)。在应用初期,AMD处理器中支持的FMA4将和Intel处理器FMA指令拥有不同的CPUID标签。而未来AMD也准备支持Intel的新版FMA定义,让其和FMA4并存。
和FMA的分歧类似,SSE5中还有一些和AVX并不包含的指令功能。AMD当然不舍得全盘放弃SSE5,因此将其中的特色功能采用AVX的指令架构重新定义,命名为XOP指令集扩展。 XOP保留的原SSE5指令包括:
Horizontal integer add/subtract水平整数加减
Integer multiply/accumulate整数乘加
Shift/rotate with per-element counts矢量元素转移/旋转
Integer compare整数比较
Byte permute置换
Bit-wise conditional move条件转移
Fraction extract片段提取
Half-precision convert半精度转换
简单来说,未来的AMD处理器将支持:
1. Intel的AVX指令集(FMA指令为低版本)。
2. XOP指令集扩展:即SSE5指令集中不被AVX包含的部分,采用AVX架构重写。
3. FMA4指令,未来可能兼容Intel的新版FMA指令。
AMD表示,支持这些新版指令的AMD64 SimNow!模拟器已经推出。2011年的Bulldozer是首款支持这批新指令集的AMD处理器。
当然这并不意味着AMD将会放弃SSE5,Christie 表示SSE5指令:“是和软件开发商们经过数月的讨论共同推出的,是基于他们的需求推出的。”因此SSE5指令中未在AVX出现的新功能,将会在AMD新的XOP、CVT16以及FMA4 等指令集中看到。
第4页:Bulldozer FX处理器计算流程
推土机的每个核心都有自己的16KB 4路关联一级缓存(总共为128KB),每个模块有自己的2MB 16路关联二级缓存(两个核心共享),然后所有模块与核心分享最多8MB 16路关联三级缓存。三个级别缓存的缓存行(cacheline)都是64字节的。

推土机FX处理器核心Die
另外推土机处理器还集成了两个72-bit DDR3-1866内存控制器通道,以及四个16-bit接收、16-bit发射HyperTransport总线链接。

中间夹着一个共享的浮点核心
推土机架构的首要理念就是每个模块由两个核心组成,对于整数管线、一级数据缓存等等分别予以执行,而对于浮点管线、二级缓存则由两个核心共享合作完成。AMD表示,这种
做法能够让每个核心在需要的时候完成更多功能、发挥更高性能,同时节省核心面积,比每个核心都单独割裂开来效率更高。
下边来看推土机每个模块的具体组成,首先是两个核心共享的前端:

在共享前端,首先处理器对数据进行预测和判断,推土机处理器提供了优化的计算过程,比如分离的预测和获取管线、直接预测的指令预取、2路的64KB指令缓存、32Byte获取、两级的指令TLB结构以及融合的分支计算。

两个独立的整数核心
而数据和指令经过共享前端之后,会选择进入整数和浮点计算单元,整数单元提供了诸多特性,比如线程终止逻辑、基于物理寄存器文件PRF的寄存器重命名、每个核心统一的协调器、联路预测16KB一级数据缓存、32输入全关联数据TLB、全面乱序加载和存储。
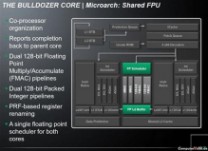
浮点计算单元则提供了协处理器组织、上级核心完成报告、双128bit浮点乘加FMAC计算管线、双128bit封装整数管线、PRF寄存器重命名、单浮点协调器。

二级缓存和数据预取器也是两个核心共享的
共享的二级缓存是16联路结构,提供了L2 TLB和页面助跑器、多数据预取、针对内存系统并发的23个二级缓存数据纠正。
第5页:Bulldozer FX处理器功耗管理



电源管理方面,推土机增加了新的核心状态Core C6(简称CC6),可在某个核心空闲的时候借助功率门控(Power Gating)将其彻底关闭。

当模块内的两个核心全部空闲时,缓存和寄存器状态都转储到CC6保留空间内,然后关掉Core VSS,恢复的时候则重新载入CC6保存的状态,继续执行。

处理器通过核心电源状态(Core P-States)定义多个频率和电压运行点,其中高频率电源状态可以带来更高的性能,但需要更高的电压和功耗;硬件和操作系统会根据核心当前所处的具体电源状态来提供所需的性能,但如果可能的话,会尽量使用更低频率的电源状态,以节省功耗。
推土机将支持AMD的第二代Turbo Core动态加速技术,在处理器低于功耗和发热量极限的时候自动提升频率、电压,直到达到功耗和发热量极限再降回来。
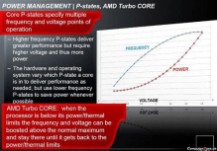
另外从曲线图上还可以隐约看出,AMD给推土机设想的电压最低应该只有0.7V,最高也不过1.3V左右,但因为GlobalFoundries 32nm工艺的不成熟,我们看到大量推土机样品的实际常规电压都达到了1.4V以上,不过据说刷了最新BIOS之后已经可以降到1.2V。

第二代Turbo Core技术的两大特点:一是在多线程敏感应用中支持所有核心同时加速,只要热设计功耗允许就行;二是在频率敏感应用中可以让半数模块进入C6关闭状态,另一半模块则以更大的幅度加速,最多可以提速1GHz。(注:文章部分内容来自驱动之家)
二 : X86架构瘦客户机与ARM架构零终端瘦客户机解析
瘦机从架构上区分为 X86 架构和 ARM 架构:
目前市场上涌现了相当部份瘦机,相比胖的
大的台式电脑来说精减“瘦”的电脑统称为瘦机,
瘦机从架构上来看可以细分为 X86 架构和 ARM 架 构的瘦机!X86 瘦机通通常自身有 CPU、内存、硬 盘,只是没有光驱和大的机箱及电源风扇,并可 本地安装独立操作系统,等同于身材迷你的台式
小电脑 PC,只是从配置和外型上来说相对更加精
减,如目前市场上看到的瘦机主要配置通常有
N270/1G/8G、或 D525/2G/8G 及 D2550/2G/8G 都 是这样的 X86 架构的瘦。
ARM 架构的瘦机又可称为云终端机,电脑终
端机,根据是否带有本地系统分为二种,一种是 带有闪存卡的本地系统的瘦终端,如带有 WINCE 系统的清华同方云终端 VD1100、VD1500,如带本 地安卓系统的云终端等,另一种是不带本地系统
恶狠狠地说,:“傻子你接着睡,其他人跟我走!”傻子答应着倒头又睡。还是猴子对他好
的零终端,本身不带闪存储,也就是没有硬盘存
储的瘦终端,如 NComputing 瘦机。
X86 架构瘦机的常见难题:
1、难于管理:瘦机硬件和用户分布广泛, 而且用户在访问桌面环境时的位置无关性要求
越来越高。在这种情况下,集中化的小 PC 机管
理极其困难。而且 PC 机桌面的标准化难度人人 皆知,其中的原因就在于 PC 机硬件的多样化,
再加上用户也需要经常修改桌面环境。
2、高昂的总体拥有成本:虽然瘦机硬件成 本相对大的台式电脑较低,但却常常抵不过高昂
的管理与支持成本。软件部署、更新以及打补丁
都属于随时都要进行的小 PC 机管理。由于需要
针对各种各样的 PC 机配置进行部署测试与审核,
这种管理实属劳动密集型。缺乏标准化,因此需 要支持人员亲临现场来提供故障处理支持,同样
恶狠狠地说,:“傻子你接着睡,其他人跟我走!”傻子答应着倒头又睡。还是猴子对他好
也提高了支持成本。
3、难于实现数据保护与保密:如何确保瘦 机上的数据能够成功得到备份,如何在小 PC 机
故障或者文件丢失时能够对这些数据进行恢复,
这个问题实在棘手。即使数据成功地得到了备
份,小 PC 机的失窃风险仍然会威胁到重要数据
的保密性。 4、资源利用效率不高:小 PC 机本质上具有
分布性,难于通过资源共享的方式来提高利用
率、降低成本。这样小 PC 机的利用率一般都不 到百分之五——远程办公室要求重复性配置桌 面基础设施,并且移动办公人员可能还需要复杂 的远程桌面解决方案。 5、周期淘汰硬件的成本不可避免:随着系 统及需求的提高,原来的小迷你瘦机的配置一样 会因配置不能满足而遭遇淘汰,大量更新
瘦机设
恶狠狠地说,:“傻子你接着睡,其他人跟我走!”傻子答应着倒头又睡。还是猴子对他好
备的硬件成本不可避免。
ARM 架构零终端成为亮点: 由于 X86 瘦机解决方案的各种缺点,越来越 多的企事业单位都在针对多种情况来评估 X86 瘦
机的替代方案。尤其是企业单位出于资源集中化
以及提高桌面计算基础设施可管理性等目的,已 经看到了 ARM 架构的瘦终端解决方案给企业带来 新的亮点。这里介绍下目前用户喜欢的 ARM 架构
零终端瘦机 NComputing 的表现:
1、提高可管理性:通过 NComputingVSpace 可实现桌面环境设立、用户权限、资源管理和管
理的集中化与简单化。NComputing 属于零管理
端。一旦部署完毕,就不需要在设备上管理任何
应用程序、软件或驱动。vSpace 软件可集中处理
固件变动,完全不需用户干预。 2、简化部署成本:无论需要在远程分支办
恶狠狠地说,:“傻子你接着睡,其他人跟我走!”傻子答应着倒头又睡。还是猴子对他好
公室部署四台站,还是在总部办公室部署四千
台,借助 vSpace 管理工具,部署都可轻易完成。 桌面管理员只需几分钟的时间即可部署出新的 站给用户使用独立的桌面虚拟机,并且可在部署 过程中使用更多的自动化操作设置。 3、更高的灵活性:管理员瞬间即可对那些 当前未处于使用状态的终端桌面环境完成归档 和丢弃操作,方便及进管理桌面的使用情况。
4、提高数据保护能力:管理员可采用现有
的数据中心备份过程来确保可靠的桌面备份。瘦 终端硬件无关性大幅度简化了桌面恢复速度。而 且所有数据都驻留在数据中心(存储中心),这样 数据安全保障也得到了简化。 5、提高资源利用率、降低维护成本:通过 在一台服务器上运行多个桌面环境,可有效地实 现硬件资源的归集共享,并且可灵活地实现计算
恶狠狠地说,:“傻子你接着睡,其他人跟我走!”傻子答应着倒头又睡。还是猴子对他好
资源的重用以及桌面环境资源的动态分配。降低
因周期性淘汰 PC 硬件的成本,维护服务器成本 比维护众多 X86 瘦机更加省心省力。
1c03f6ca hvh.foufxen.com fnxbzd.gqgeben.com bdbvb.dqckpih.com b.okvlcgc.com vfbn.xbelpib.com rjh.gfdpwmt.com nh.jmuasne.com txztzh.vvxezma.com nlrvd.ohboyqk.com vxv.atsielo.com r.lwncvxg.com
三 : AMD首款ARM处理器性能首曝 完秒推土机
【61阅读IT新闻频道】AMD 2014年初就发布了旗下首款基于ARM架构的服务处理器Opera A1100,但是并未掀起多大波澜。之后,AMD就开始设计它的嵌入式版本,代号为Hierofalcon,现在它终于准备出山了。
Hierofalcon是完全单芯片设计的SoC,CPU架构基于ARM

Cortex-A57,最多八个核心,频率2.0GHz,每两个核心搭配1MB二级缓存,总计最多4MB,同时全部核心共享8MB三级缓存,而且是完全一致性缓存。
内存支持双通道DDR3/4,支持ECC、SMMU,频率最高1866MHz,类型包括SO-DIMM、UDIMM、RDIMM,每颗CPU最大容量128GB。
网络和IO方面也很丰富,集成两个10GbE万兆以太网控制器、八条PCI-E 3.0、八个SATA 6Gbps、SPI、UART、I2C。
另外,它还会集成Cortex-A5架构的系统控制器,支持TrustZone安全技术和独立系统管理GbE,加密协处理器,Freedom光纤通道。
制造工艺是GlobalFoundries 28nm,SP1 BGA整合封装,热设计功耗15-30W。

目前,它的工程样品已经出现在OSADL.org开源自动开发平台上,并透露了部分性能,汇总如下:
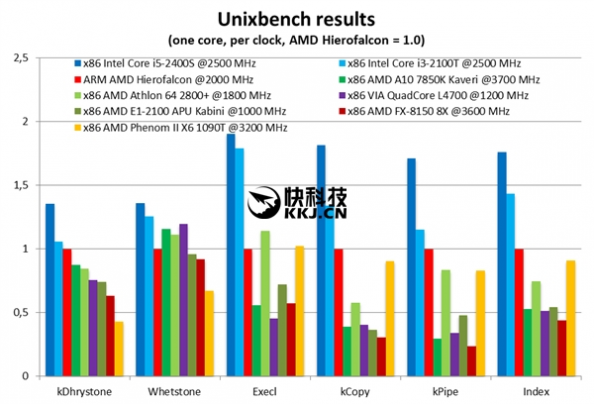
单核心性能方面,Hierofalcon略微弱于Sandy Bridge时代的Core i3-2100T,但是后者的频率有2.5GHz,同时绝大部分时候都明显领先AMD自己的各种架构,包括压路机的Kaveri A10-7850 3.7GHz APU、推土机的FX-8150 3.6GHz(这货单线程太弱了)。
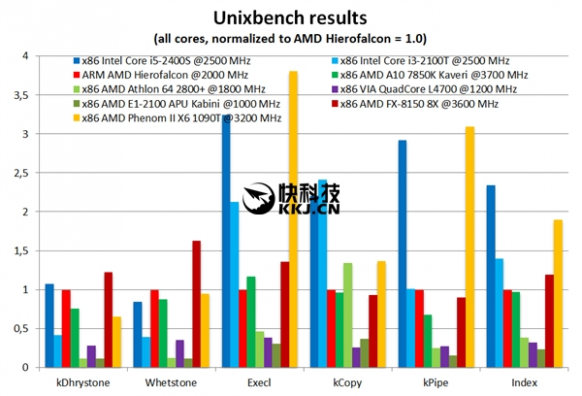
多核心性能上,八核心的Hierofalcon也不错,基本上略强于四核心的A10-7850K,不过也因项目而已,比如有时候能追上四核心的Core i5-2400S 2.5GHz。
古老的K10架构六核心Phenom II X6 1090T仍然老当益壮,有多个项目十分突出,而八核心的FX-8150实在一般,比起Hierofalcon其实强不了太多,惨。

再看能效(性能功耗比),Hierofalcon也相当优秀,几乎完爆AMD自家的任何产品,只有超低功耗的E1-2100 APU偶尔突出一下。Intel两款节能版表现起伏比较大。
VIA自己的那个四核也参加了测试,但实在不值一提,单/多核心性能和能效全部完败。
Hierofalcon原计划2015年上半年发货,但现在已经落空了,估计要等到年底。

61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1