一 : 关于fork函数中的内存复制和共享
原来刚刚开始做Linux下面的多进程编程的时候,对于下面这段代码感到很奇怪,
#include<unistd.h>
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<stdarg.h>
#include<errno.h>
#define LEN 2
void err_exit(char *fmt,...);
int main(int argc,char *argv[])
{
pid_t pid;
int loop;
for(loop=0;loop<LEN;loop++)
{
if((pid=fork()) < 0)
err_exit("[fork:%d]: ",loop);
else if(pid == 0)
{
printf("Child processn");
}
else
{
sleep(5);
}
}
return 0;
}
为什么这段程序会创建3个子进程,而不是两个,为什么在第20行后面加上一个return 0;就创建的又是两个子进程了?原来一直搞不明白,后来了解了C语言程序的存储空间布局以及在fork之后父子进程是共享正文段(代码段CS)之后才明白这其中的缘由!具体原理是啥,且容我慢慢道来!
首先得明白一个东西就是C程序的存储空间布局,如下图所示:
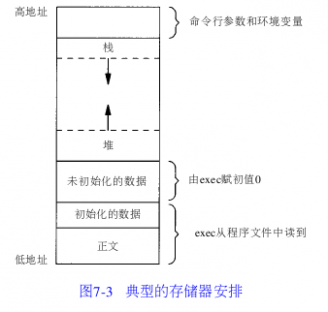
原图出自《UNIX环境高级编程》7.6节)
当一个C程序执行之后,它会被加载到内存之中,它在内存中的布局如上图,分为这么几个部分,环境变量和命令行参数、栈、堆、数据段(初始化和未初始化的)、正文段,下面挨个来说明这几段分别代表了什么:
环境变量和命令行参数:这些指的就是Unix系统上的环境变量(比如$PATH)和传给main函数的参数(argv指针所指向的内容)。
。www.61k.com)数据段:这个是指在C程序中定义的全局变量,如果没有初始化,那么就存放在未初始化的数据段中,程序运行时统一由exec赋值为0。否则就存放在初始化的数据段中,程序运行时由exec统一从程序文件中读取。(了解汇编的朋友们想必知道汇编语言中的数据段DS,这和汇编中的数据段其实是一个东西)。
堆:这一部分主要用来动态分配空间。比如在C语言中用malloc申请的空间就是在这个区域申请的。
正文段:C语言代码并不是直接执行的,而是被编译成了机器指令才能够在电脑上执行,最终生成的机器指令就是存放在这个区域(汇编中的代码段CS指的就是这片区域)。
栈:个人感觉这是C程序内存布局最关键的部分了。这个部分主要用来做函数调用。具体而言怎么说呢,程序刚开始栈中只有main这一个函数的内容(即main的栈帧),如果main函数要调用func函数,那么func函数的返回地址(main函数的地址),func函数的参数,func函数中定义的局部变量,还有func函数的返回值等等这些都会被压入栈中,这时栈中就多了func函数的内容(func的栈帧)。然后func函数运行完了之后再来弹栈,把它原来压的内容去掉(即清除掉func栈帧),此时栈中又只剩下了main的栈帧。(这片区域就是汇编中的栈段SS)
OK,这就是C程序的存储器布局。这里我联想到另外一点,就是全局变量和静态变量是存储在数据段中的,而局部变量是存储在栈中的,栈中数据在函数调用完之后一弹栈就没了,这就是为什么全局变量的生存周期比局部变量的生存周期要长的原因。
了解了C程序在存储器的布局之后,我们再来了解fork的内存复制机制,关于这个,我们只需要了解一句话就够了,“子进程复制父进程的数据空间(数据段)、栈和堆,父、子进程共享正文段。”也就是说,对于程序中的数据,子进程要复制一份,但是对于指令,子进程并不复制而是和父进程共享。具体来看下面这段代码(这是我在上面那段代码上稍微添加了一点东西):
/* 这个程序会创建3个子进程,理解这句话,父子进程复制数据段、栈、堆,共享正文段
*
*/
#include<unistd.h>
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<stdarg.h>
#include<errno.h>
#define BUFSIZE 512
#define LEN 2
void err_exit(char *fmt,...);
int main(int argc,char *argv[])
{
pid_t pid;
int loop;
for(loop=0;loop<LEN;loop++)
{
printf("Now is No.%d loop:n",loop);
if((pid=fork()) < 0)
err_exit("[fork:%d]: ",loop);
else if(pid == 0)
{
printf("[Child process]P:%d C:%dn",getpid(),getppid());
}
else
{
sleep(5);
}
}
return 0;
}
为什么上面那段代码会创建三个子进程?我们来具体分析一下它的执行过程:
首先父进程执行循环,通过fork创建一个子进程,然后sleep5秒。
再来看父进程创建的这个子进程,这里我们记为子进程1.子进程1完全复制了这个父进程的数据部分,但是需要注意的是它的正文段是和父进程共享的。也就是说,子进程1开始执行代码的部分并不是从main的 { 开始执行的,而是主函数执行到哪里了,它就接着执行,具体而言就是它会执行fork后面的代码。所以子进程1首先会打印出它的ID和它的父进程的ID。然后继续第二遍循环,然后这个子进程1再来创建一个子进程,我们记为子进程11,子进程1开始sleep。
子进程11接着子进程1执行的代码开始执行(即fork后面),它也是打印出它的ID和父进程ID(子进程1),然后此时loop的值再加1就等于2了,所以子进程2直接就返回了。
那个子进程1sleep完了之后也是loop的值加1之后变成了2,所以子进程1也返回了!
然后我们再返回去看父进程,它仅仅循环了一次,sleep完之后再来进行第二次循环,这次又创建了一个子进程我们记为子进程2。然后父进程开始sleep,sleep完了之后也结束了。
那么那个子进程2怎么样了呢?它从fork后开始执行,此时loop等于1,它打印完它的ID和父进程ID之后,就结束循环了,整个子进程2就直接结束了!
这就是上面那段代码的运行流程,进程间的关系如下图所示:
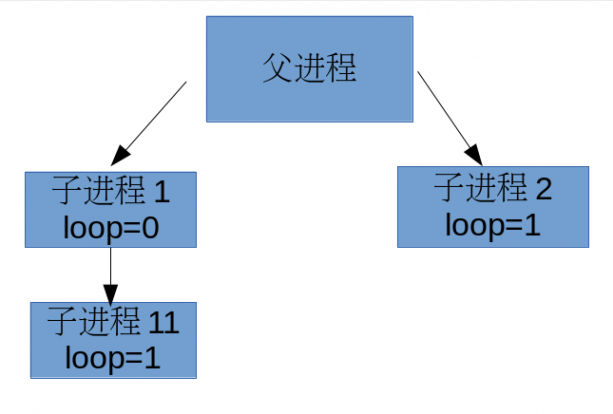
上图中那个loop=%d就是当这个进程开始执行的时候loop的值。上面那段代码的运行结果如下图:
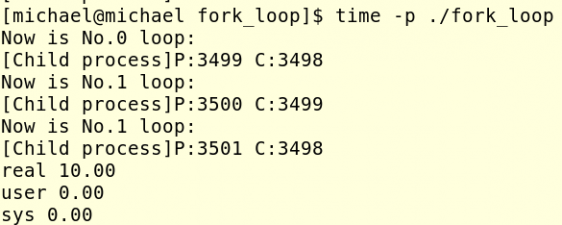
这里这个3498进程就是我们的主进程,3499就是子进程1,3500就是子进程11,3501就是子进程2。
最后,我们再来回答一下我们开始的时候提出的那个问题,为什么在子进程的处理部分“ if(pid == 0) ”最后加一个return 0,就会创建两个子进程了,就是因为子进程1运行到这里直接就结束了,不再进行第二遍循环了,所以就不会再去创建那个子进程11了,所以最后一共就是创建了两个子进程啊!
本文永久更新链接地址:
二 : fork函数小结
1.调用一次,返回两次。
2.子进程中fork返回0,父进程中fork返回子进程的PID。原因是:①在子进程中通过调用getppid可以方便的指导父进程的PID;②没有一个函数可以使父进程获得其所有子进程的PID。(所以在fork返回时,将子进程的PID直接返回给父进程)
注:子进程的ID不可能为0,因为PID为0的进程是swapper进程。
3.父、子进程共享正文段,不共享数据、堆、栈段,子进程获得父进程数据、堆、栈段的副本。
注:目前,大多数实现并直接复制父进程的数据、堆栈段,而是使用写时复制(Copy-On-Write)技术,在修改这块内存区域时,才会为被修改的数据创建副本。
4.子进程会获得缓冲区的副本,即fork前进程缓冲区中的数据未被flush掉,则fork后,子进程能够获得父进程缓冲区中的数据。
5.父进程所有被打开的文件描述符都会被复制到子进程中。
注:fork之后处理文件描述符通常有两种情况:
①父进程等待子进程结束;
②父、子进程各自执行不同的正文段(父、子进程各自关闭不需要使用的文件描述符);
6.fork之后父、子进程的区别:
①fork的返回值;
②进程ID不同;
③父进程也不同;
④子进程的tms_utime、tms_stime、tms_cutime和tms_ustime均被设置为0;
⑤父进程设置的文件锁不会被子进程继承;
⑥子进程的未处理的闹钟被清除;
⑦子进程的未处理信号集设置为空集;
7.fork失败的两个主要原因:
①系统中进程数目已经达到上限;
②该实际用户的进程总数达到系统限制;
8.fork的两种用法:
①一个进程希望复制自己,使得父、子进程执行不同的代码段。如父进程监听端口,收到消息后,fork出子进程处理消息,父进程仍然负责监听消息。
②一个进程需要执行另一个程序。如fork后执行一个shell命令。
三 : fork()函数的用法[转]
fork() 基础四 : Linux中fork()函数详解
linux中fork()函数详解(原创!!实例讲解) (转载)
一、fork入门知识
一个进程,包括代码、数据和分配给进程的资源。(www.61k.com]fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,
也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都
复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
我们来看一个例子:
[cpp] view plaincopy
运行结果是:
i am the child process, my process id is 5574
我是爹的儿子
统计结果是: 1
i am the parent process, my process id is 5573
我是孩子他爹
统计结果是: 1
在语句fpid=fork()之前,只有一个进程在执行这段代码,但在这条语句之后,就变成两个进程在执行了,这两个进程的几乎完全相同,
将要执行的下一条语句都是if(fpid<0)……
为什么两个进程的fpid不同呢,这与fork函数的特性有关。
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,
fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
引用一位网友的话来解释fpid的值为什么在父子进程中不同。“其实就相当于链表,进程形成了链表,父进程的fpid(p 意味point)指向子进程的进程id,
因为子进程没有子进程,所以其fpid为0.
fork出错可能有两种原因:
1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
2)系统内存不足,这时errno的值被设置为ENOMEM。
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
每个进程都有一个独特(互不相同)的进程标识符(process ID),可以通过getpid()函数获得,还有一个记录父进程pid的变量,可以通过getppid()函数获得变量的值。
fork执行完毕后,出现两个进程,
有人说两个进程的内容完全一样啊,怎么打印的结果不一样啊,那是因为判断条件的原因,上面列举的只是进程的代码和指令,还有变量啊。
执行完fork后,进程1的变量为count=0,fpid!=0(父进程)。进程2的变量为count=0,fpid=0(子进程),这两个进程的变量都是独立的,
存在不同的地址中,不是共用的,这点要注意。可以说,我们就是通过fpid来识别和操作父子进程的。
还有人可能疑惑为什么不是从#include处开始复制代码的,这是因为fork是把进程当前的情况拷贝一份,执行fork时,进程已经执行完了int count=0;
fork只拷贝下一个要执行的代码到新的进程。
二、fork进阶知识
先看一份代码:
[cpp] view plaincopy
运行结果是:
i son/pa ppid pid fpid
0 parent 2043 3224 3225
0 child 3224 3225 0
1 parent 2043 3224 3226
1 parent 3224 3225 3227
1 child 1 3227 0
1 child 1 3226 0
这份代码比较有意思,我们来认真分析一下:
第一步:在父进程中,指令执行到for循环中,i=0,接着执行fork,fork执行完后,系统中出现两个进程,分别是p3224和p3225
(后面我都用pxxxx表示进程id为xxxx的进程)。可以看到父进程p3224的父进程是p2043,子进程p3225的父进程正好是p3224。我们用一个链表来表示这个关系:
p2043->p3224->p3225
第一次fork后,p3224(父进程)的变量为i=0,fpid=3225(fork函数在父进程中返向子进程id),代码内容为:
[c-sharp] view plaincopy
p3225(子进程)的变量为i=0,fpid=0(fork函数在子进程中返回0),代码内容为:
[c-sharp] view plaincopy
所以打印出结果:
0 parent 2043 3224 3225
0 child 3224 3225 0
第二步:假设父进程p3224先执行,当进入下一个循环时,i=1,接着执行fork,系统中又新增一个进程p3226,对于此时的父进程,
p2043->p3224(当前进程)->p3226(被创建的子进程)。
对于子进程p3225,执行完第一次循环后,i=1,接着执行fork,系统中新增一个进程p3227,对于此进程,p3224->p3225(当前进程)->p3227(被创建的子进程)。
从输出可以看到p3225原来是p3224的子进程,现在变成p3227的父进程。父子是相对的,这个大家应该容易理解。只要当前进程执行了fork,该进程就变成了父进程了,就打印出了parent。
所以打印出结果是:
1 parent 2043 3224 3226
1 parent 3224 3225 3227
第三步:第二步创建了两个进程p3226,p3227,这两个进程执行完printf函数后就结束了,因为这两个进程无法进入第三次循环,无法fork,该执行return 0;了,其他进程也是如此。
以下是p3226,p3227打印出的结果:
1 child 1 3227 0
1 child 1 3226 0
细心的读者可能注意到p3226,p3227的父进程难道不该是p3224和p3225吗,怎么会是1呢?这里得讲到进程的创建和死亡的过程,
在p3224和p3225执行完第二个循环后,main函数就该退出了,也即进程该死亡了,因为它已经做完所有事情了。p3224和p3225死亡后,
p3226,p3227就没有父进程了,这在操作系统是不被允许的,所以p3226,p3227的父进程就被置为p1了,p1是永远不会死亡的,至于为什么,
这里先不介绍,留到“三、fork高阶知识”讲。
总结一下,这个程序执行的流程如下:
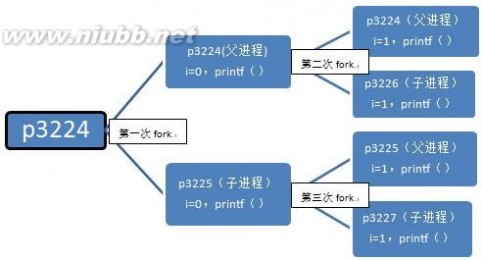
这个程序最终产生了3个子进程,执行过6次printf()函数。
我们再来看一份代码:
[cpp] view plaincopy
它的执行结果是:
father
son
father
father
father
father
son
son
father
son
son
son
father
son
这里就不做详细解释了,只做一个大概的分析。
for i=0 1 2
father father father
son
son father
son
son father father
son
son father
son
其中每一行分别代表一个进程的运行打印结果。
总结一下规律,对于这种N次循环的情况,执行printf函数的次数为2*(1+2+4+……+2N-1)次,创建的子进程数为1+2+4+……+2N-1个。
(感谢gao_jiawei网友指出的错误,原本我的结论是“执行printf函数的次数为2*(1+2+4+……+2N)次,创建的子进程数为1+2+4+……+2N ”,这是错的)
网上有人说N次循环产生2*(1+2+4+……+2N)个进程,这个说法是不对的,希望大家需要注意。
数学推理见http://202.117.3.13/wordpress/?p=81(该博文的最后)。
同时,大家如果想测一下一个程序中到底创建了几个子进程,最好的方法就是调用printf函数打印该进程的pid,也即调用printf("%d/n",getpid());或者通过printf("+/n");
来判断产生了几个进程。有人想通过调用printf("+");来统计创建了几个进程,这是不妥当的。具体原因我来分析。
老规矩,大家看一下下面的代码:
[cpp] view plaincopy
执行结果如下:
fork!
I am the parent process, my process id is 3361
I am the child process, my process id is 3362
如果把语句printf("fork!/n");注释掉,执行printf("fork!");
则新的程序的执行结果是:
fork!I am the parent process, my process id is 3298
fork!I am the child process, my process id is 3299
程序的唯一的区别就在于一个/n回车符号,为什么结果会相差这么大呢?
这就跟printf的缓冲机制有关了,printf某些内容时,操作系统仅仅是把该内容放到了stdout的缓冲队列里了,并没有实际的写到屏幕上。
但是,只要看到有/n 则会立即刷新stdout,因此就马上能够打印了。
运行了printf("fork!")后,“fork!”仅仅被放到了缓冲里,程序运行到fork时缓冲里面的“fork!” 被子进程复制过去了。因此在子进程度stdout
缓冲里面就也有了fork! 。所以,你最终看到的会是fork! 被printf了2次!!!!
而运行printf("fork! /n")后,“fork!”被立即打印到了屏幕上,之后fork到的子进程里的stdout缓冲里不会有fork! 内容。因此你看到的结果会是fork! 被printf了1次!!!!
所以说printf("+");不能正确地反应进程的数量。
大家看了这么多可能有点疲倦吧,不过我还得贴最后一份代码来进一步分析fork函数。
[cpp] view plaincopy
问题是不算main这个进程自身,程序到底创建了多少个进程。
为了解答这个问题,我们先做一下弊,先用程序验证一下,到此有多少个进程。
[c-sharp] view plaincopy
答案是总共20个进程,除去main进程,还有19个进程。
我们再来仔细分析一下,为什么是还有19个进程。
第一个fork和最后一个fork肯定是会执行的。
主要在中间3个fork上,可以画一个图进行描述。
这里就需要注意&&和||运算符。
A&&B,如果A=0,就没有必要继续执行&&B了;A非0,就需要继续执行&&B。
A||B,如果A非0,就没有必要继续执行||B了,A=0,就需要继续执行||B。
fork()对于父进程和子进程的返回值是不同的,按照上面的A&&B和A||B的分支进行画图,可以得出5个分支。
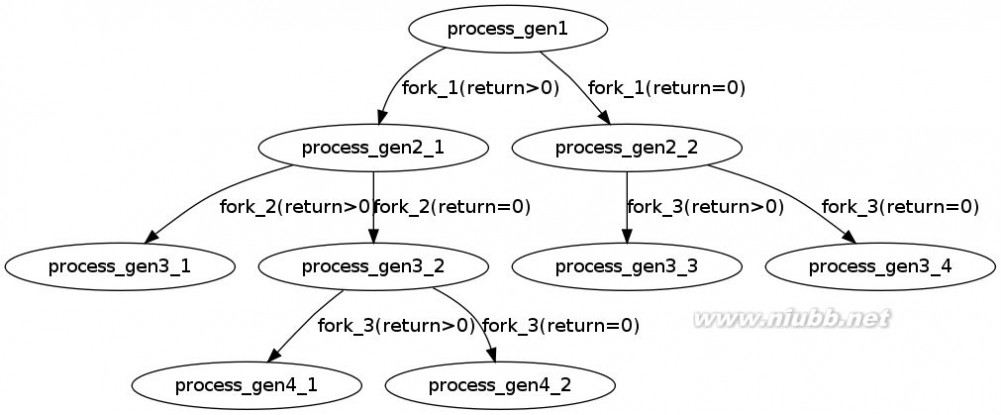
加上前面的fork和最后的fork,总共4*5=20个进程,除去main主进程,就是19个进程了。
三、fork高阶知识
这一块我主要就fork函数讲一下操作系统进程的创建、死亡和调度等。因为时间和精力限制,我先写到这里,下次找个时间我争取把剩下的内容补齐。
原文地址:http://blog.csdn.net/jason314/article/details/5640969

五 : fork函数总结
在Unix/Linux中用fork函数创建一个新的进程。(www.61k.com)进程是由当前已有进程调用fork函数创建,分叉的进程叫子进程,创建者叫父进程。该函数的特点是调用一次,返回两次,一次是在父进程,一次是在子进程。两次返回的区别是子进程的返回值为0,父进程的返回值是新子进程的ID。子进程与父进程继续并发运行。如果父进程继续创建更多的子进程,子进程之间是兄弟关系,同样子进程也可以创建自己的子进程,这样可以建立起定义关系的进程之间的一种层次关系。
程序包含位于内存的多个组成部分,执行程序的过程将根据需要来访问这些内容,包括文本段(text segment)、数据段(data segments)、栈(stack)和堆(heap)。文本段中存放CPU所执行的命令,数据段存放进程操作的所有数据变量,栈存放自动变量和函数数据,堆存放动态内存分配情况数据。当进程被创建时,子进程收到父进程的数据副本,包括数据空间、堆、栈和进程描述符。
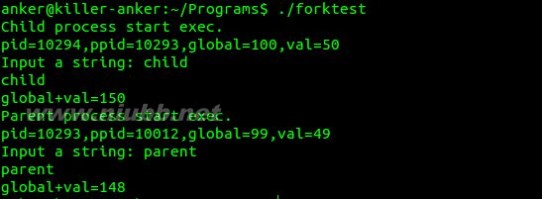
程序1:创建一个子进程,子进程对继承的数据进行修改,然后分别输出父子进程的信息。程序如下:

 View Code
View Code
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <string.h> 4 #include <unistd.h> 5 #include <errno.h> 6 #include <sys/types.h> 7 8 int add(int a,int b); 9 //全局变量10 int global = 99;11 char buf[] = "Input a string: ";12 13 int main()14 {15 pid_t pid;16 int val,ret;17 char *str;18 val =49;19 str = (char*)malloc(100*sizeof(char));20 memset(str,0,100*sizeof(char));21 if((pid = fork()) == -1)22 {23 perror("fork() error");24 exit(-1);25 }26 if(pid == 0) //子进程27 {28 printf("Child process start exec.n");29 global++;30 val++;31 }32 if(pid >0) //父进程33 { 34 sleep(10); //等待子进程执行35 printf("Parent process start exec.n");36 }37 printf("pid=%d,ppid=%d,global=%d,val=%dn",getpid(),getppid(),global,val);38 write(STDOUT_FILENO,buf,strlen(buf));39 read(STDIN_FILENO,str,100);40 write(STDOUT_FILENO,str,strlen(str));41 ret = add(global,val);42 printf("global+val=%dn",ret);43 exit(0);44 }45 46 int add(int a,int b)47 {48 return (a+b);49 }fork函数执行后程序结构图如下:

子进程与父进程并行执行,因此在父进程中sleep(10),让子进程先执行,然后再执行父进程。
程序执行结果如下所示:
如何创建多个子进程呢?在开发并发服务器时,用到的进程池模型需要先创建指定书目的子进程。举个例子,假如我们现在需要创建2个子进程,很容易想到的是调用一个循环,执行fork函数2次即可。尝试一下是否可行呢?代码如下:
View Code
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <string.h> 4 #include <unistd.h> 5 #include <errno.h> 6 #include <sys/types.h> 7 8 int main() 9 {10 int i;11 pid_t pid;12 printf("pid=%d , ppid=%dn",getpid(),getppid());13 //通过一个循环创建对个子进程14 for(i=0;i<2;++i)15 {16 pid = fork();17 if(pid == 0)18 {19 printf("create child process successfully.n");20 printf("pid=%d , ppid=%dn",getpid(),getppid());21 printf("i=%dn",i);22 }23 else if(pid== -1)24 {25 perror("fork() error");26 exit(-1);27 }28 else29 {30 sleep(3);31 printf("parent process.n");32 printf("pid=%d , ppid=%dn",getpid(),getppid());33 printf("i=%dn",i);34 }35 }36 37 exit(0);38 }程序执行结果如下:
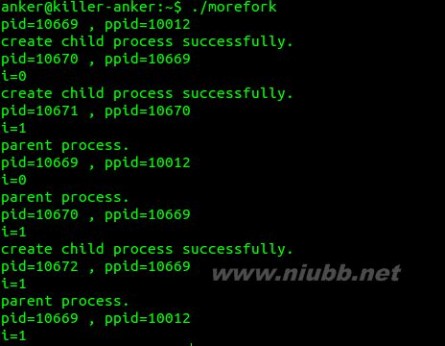
从结果来看,子进程的数目不是2而是3,这是为什么呢?先简单的分析一下:从结果看出父进程ID为10669,子进程的ID分别为:10670、10671、10672。
父子进程之间的关系如下:
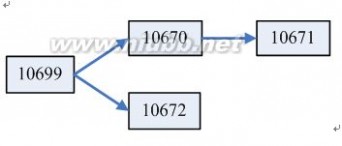
ID为10670的子进程也调用fork函数,创建了一个进程。因为fork函数创建的进程是父进程的一份拷贝,保存了当前的数据空间、堆、栈及共享代码区域。正确的方式应该是在子进程中跳出,停止继续fork。改进的代码如下:
View Code
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <string.h> 4 #include <unistd.h> 5 #include <errno.h> 6 #include <sys/types.h> 7 8 int main() 9 {10 int i;11 pid_t pid;12 printf("pid=%d , ppid=%dn",getpid(),getppid());13 for(i=0;i<2;++i)14 {15 pid = fork();16 if(pid == 0)17 {18 printf("create child process successfully.n");19 printf("pid=%d , ppid=%dn",getpid(),getppid());20 printf("i=%dn",i);21 //子进程跳出循环,防止子进程继续创建子进程22 break;23 }24 else if(pid== -1)25 {26 perror("fork() error");27 exit(-1);28 }29 else30 {31 sleep(3);32 printf("parent process.n");33 printf("pid=%d , ppid=%dn",getpid(),getppid());34 printf("i=%dn",i);35 //父进程继续创建子进程36 continue;37 }38 }39 40 exit(0);41 }程序执行结果如下:

从结果可以看出这父进程(ID为10789)创建了两个子进程(ID分别为:10790、10791)。
现有有这样一个面试题,程序如下:
1 #include <stdio.h> 2 #include <unistd.h> 3 #include <stdlib.h> 4 #include <sys/types.h> 5 6 int main() 7 { 8 pid_t pid1; 9 pid_t pid2;10 11 pid1 = fork();12 pid2 = fork();13 14 printf("pid1=%d,pid2=%dn",pid1,pid2);15 exit(0);16 }要求如下:
已知从这个程序执行到这个程序的所有进程结束这个时间段内,没有其它新进程执行。
1、请说出执行这个程序后,将一共运行几个进程。
2、如果其中一个进程的输出结果是“pid1:1001, pid2:1002”,写出其他进程的输出结果(不考虑进程执行顺序)。
这个题目考查fork函数的理解。fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程,父子进程并行的执行剩下的部分。
程序的执行过程如下:
(1)程序开始执行时候系统分配一个进程进行执行,称该进程为主进程P,进程ID题目未给,
(2)主进程执行到第一个fork函数的时候,创建一个新的子进程P1,有题目可知进程ID为1001,fork函数有两个返回值,返回pid=0代表子进程P1,pid1>0代表父进程P。
(3)现在有两个进程P和P1,分别执行剩下部分,
(4)P进程(父进程,所以pid1=1001)调用fork创建子进程P2,返回两个值中pid2=1002表示P2的进程ID返回给父进程P,pid2=0子进程P2本身,所以输出pid1=1001, pid2=1002和pid1=1001,pid2=0。
(5)P1进程(子进程,所以pid1=0)调用fork创建子进程P3,进程ID类推为1003,返回两个值中pid2=1003表示P3的进程ID返回给父进程P1,pid2=0标识进程P3本身。所以输出pid1=0,pid2=1003和pid1=0,pid2=0。
(6)执行整个结束。
根据以上分析可知答案:
1、一共执行了四个进程。(P0, P1, P2, P3)
2、另外几个进程的输出分别为:
pid1:1001, pid2:0
pid1:0, pid2:1003
pid1:0, pid2:0
上机测试如下:

测试结果如下:

测试结果虽然不是1001,但是可以看出理论分析过程是正确的。
题目来自:
本文标题:fork函数-关于fork函数中的内存复制和共享61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1