一 : 百度站长平台:百度图片搜索收录展现有何要求?

61阅读(61k.com)12月18日消息 近日百度站长平台发布文章对“百度图片搜索收录排序”这一问题进行了说明分析。据百度官方表示,很多站长对百度图片收录排序问题持有疑问,因此百度学院就此采访了百度图片搜索的相关负责人,从而了解到了百度图片搜索收录排序的基本原则。据悉,希望在百度图片搜索中收录和展现的图片应该具有包括“图片所在的网页维度”、“图片所在的网站维度”、以及“图片自身维度”这三个维度。
以下为来自百度站长学院的详细内容:
一,图片所在网页维度
1、图片所在网页主题与网站经营方向、主题一致。百度图片搜索认为,与网站主题一致的网页会受到站长的更多重视,其页面上的图片更可信
2、图片周边有可信的、精准的、针对图片的相关描述,包括上下文描述、图片说明、alt属性、图片title,以及图片anchor
3、图片所在网页没有权限。这点与百度网页搜索的要求是一致的,同样认为需要用户登录才可浏览的网页用户体验非常不好,蜘蛛也无法完成填写用户名和密码的工作
4、图片链接不要写在JS里,不要使用异步加载等方式进行展现,现阶段百度对JS的解析成功率还有待提升
二,图片所在网站维度
1、目前百度网页搜索与百度图片搜索共用Baiduspider,网站如果想在图片搜索有较好表现的话,首先要对Baiduspider充分友好,保证Baiduspider对站点的抓取解析和收录。
2、百度图片搜索会参考网站在百度网页搜索体系中的评价打分,一般来说如果网站在网页搜索体系中拥有可信度、不存在恶意作弊和过度SEO行为的话,在图片搜索中也会有较好的表现
3、网站所在服务器稳定,网站打开速度流畅。百度图片搜索当然不希望用户看到相关图片后,满怀希望地点击网页地址换来的却是长久无尽的等待
三,图片自身维度
1、图片尽量清晰。百度图片搜索排序时,在其他条件相当的情况下,更高清的图片可以得到优先展现
2、与清晰度相似的是图片尺寸,尺寸大小应与所表现的内容相匹配,并非越大越好,尺寸小的图片也不一定就会受到歧视
3、图片内容主体突出,视觉效果好。如果图片上有水印,水印应该位于图片边角位置,不对主体造成遮挡
4、稀缺图片资源最受百度图片搜索青睐,但在此提醒一下站长,如果您的图片属于优质稀缺资源,千万别忘了给图片配上靠谱儿的说明文字
注:相关网站建设技巧阅读请移步到建站教程频道。
二 : 搭建内网搜索平台
本文是自己在公司发的文章,搭建公司内部的搜索平台。(www.61k.com)
很早就有一个想法,我们公司大量业务知识,中心内部交流培训和技术业务文章分享也不少,希望能有一个平台可以检索它们并且很方便的搜索到它们。
检索数据的方式可以像爬虫一样去抓取指定网站的内容,也可以通过任何人手工上传自己的文章,并且能很及时的对上传的文章建立索引并能搜索到它们。
要建立这样的平台,肯定需要花费很多时间才能完成,因为是业余时间来做这个功能,为了能花费较少时间并且多了解一些框架和技术,我开发了部分代码并用一些开源项目帮助搭建了一个这样的平台。
爬虫我用了Nutch1.5.1,通过访问Solr3.6来建立Lucene索引,搜索过程通过Lucene3.6来获取需要的数据,中文分词用了IKAnalyzer2012_u6,搜索页面的项目用的Struts2,一些数据用的Mongodb2.2.1来存储,Nutch是通过Cygwin运行的。
搭建上述的框架,花费了我很多时间,遇到了很多问题,这些问题可能也和操作系统有关系,我是WIN7 64位的,有的问题通过网络也没有搜索到相关问题说明,是自己通过反复看日志猜出来的解决办法。因此对于其他系统搭建这样的框架,不一定完全具有参考性。
一、爬虫和搭建数据中心
安装过程:
首先需要在已经安装JDK环境的机器下,把Cygwin,Nutch,Solr下载后分别解压或安装。
因为Nutch命令是shell脚本,Cygwin的目的是windows环境下模拟Linux环境执行,在http://www.cygwin.com/ 下载setup.exe文件,然后运行,我选择的离线下载,因为安装包比较大会下载很久,离线下载完毕后再安装它,安装目录不要有空格和中文目录。
Nutch从http://nutch.apache.org/ 下载apache-nutch-1.5.1-bin.zip文件后,直接解压即可,但我下载的内容bin文件夹里没有nutch文件,我再单独下载apache-nutch-1.5.1-src.zip文件,再把src里的nutch文件放到之前下载的bin文件夹里。然后把apache-nutch-1.5.1-bin.zip解压后的文件复制到Cygwin文件夹的home/机器名/里。Nutch擅长做爬虫,并且把爬取的数据按照特定结构存储起来,由于大数量的文件存储,Nutch发展起了一个现在很出名的顶级项目:Hadoop,它实现功能类试Google的GFS和Mapduce算法,用来解决分布式的计算的问题,但我也没用过,对它们不了解。把Nutch目录放到Cygwin文件夹下后,需要配置环境变量NUTCH_HOME到该目录。由于需要JDK环境,还需要配置NUTCH_JAVA_HOME环境变量到JDK的文件夹里,并且这里的JDK所在文件夹不能有中文名词和空格。
Solr在http://lucene.apache.org/solr/ 地方下载,下载非源码压缩文件后直接解压就行,Solr是基于Lucene的一个项目,它擅长做数据索引,通过指定URL供其他系统调用,可以建立Lucene结构的索引。Solr3.6开源项目也有自己的页面可以测试分词,测试搜索功能等,可以简单测试下中文分词和搜索功能。同时需要创建一个环境变量SOLR_HOME指向Solr所在目录,比如我指向的D:\solr3.6\。
中文分词用的IKAnalyzer2012_u6,在http://code.google.com/p/ik-analyzer/ 下载后,下载后就一个IKAnalyzer2012_u6.jar包和一个IKAnalyzer.cfg.xml文件,IKAnalyzer.cfg.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典
<entry key="ext_dict">ext.dic;</entry>
-->
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
为了让Solr能用中文分词,把中文分词的配置文件IKAnalyzer.cfg.xml放到solr3.6\example\work\Jetty_0_0_0_0_8983_solr.war__solr__k1kf17\webapp\WEB-INF\classe目录下,把IKAnalyzer2012_u6.jar包放到solr3.6\example\work\Jetty_0_0_0_0_8983_solr.war__solr__k1kf17\webapp\WEB-INF\lib目录下,文件夹Jetty..每个机器可能会不一样,IKAnalyzer.cfg.xml配置文件可以配置扩展的名词和停止词,分别用来被中文分词识别的名词和作为分词中断的标识。在solr3.6\example\work\Jetty_0_0_0_0_8983_solr.war__solr__k1kf17\webapp\WEB-INF\classes目录增加扩展词典:ext.dir,ext.dir内容里每一行表示一个新名称,但第一行会被忽略,从第二行开始新增自己的新名词,比如我新增如下图:
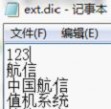
然后需要把配置文件中的<entry key="ext_dict">ext.dic;</entry> 取消注释,使ext.dic可以被识别,中文分词Jar包和配置文件配置好后,需要把IK集成到Solr里。首先需要把Nutch下的conf文件夹里的schema.xml文件粘贴到solr3.6\example\solr\conf文件夹里,该Schema记录了索引的字段类型和设置字段的存储方式等,但默认字段类型没有中文字段类型,需要新增一个fieldType为text_cn的类型如下:
<fieldType name="text_cn"
positionIncrementGap="100">
<analyzer type="index">
<tokenizer isMaxWordLength="false"/>
<filter ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter />
</analyzer>
<analyzer type="query">
<tokenizer isMaxWordLength="true"/>
<filter ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter />
</analyzer>
</fieldType>
然后把field为标题和内容的类型修改为text_cn,把默认为:
<field name="content" type="text" stored="false" indexed="true"/>
<field name="title" type="text" stored="true" indexed="true"/>
修改为:
<field name="content" type="text_cn" stored="true" indexed="true"/>
<field name="title" type="text_cn" stored="true" indexed="true"/>
把类型修改为新增的中文类型,并且由于搜索时需要显示内容,把content字段设置为可存储。通过上面从操作就把IK中文分词集成到Solr里了。
配置完成后,可以用Solr来测试下中文分词,把filed设置为type,并且type的值输入刚才新增的类型text_cn,通过http://127.0.0.1:8983/solr/admin/analysis.jsp搜索:中国航信,如下:
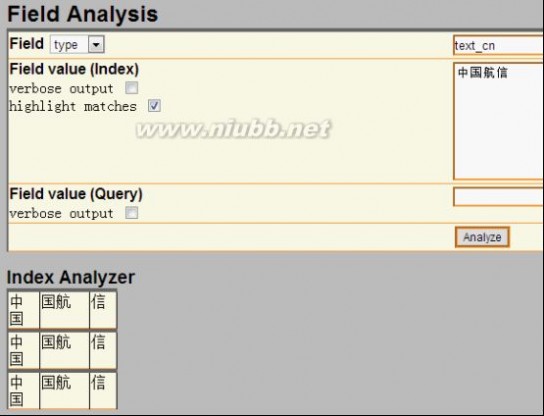
上图是还没有新增自己的扩展字段ext.dic的结果,按照上面描述的方法增加了ext.dic字段后,航信作为了一个新名词,然后再搜索后结果如下:

航信被识别出来了,作为一个单独的名词。现在中文分词和自己扩展的新名词就都可以用了。lawson
Mongodb从http://www.mongodb.org/下载后,直接解压即可,把解压后的Mongodb放到一个非中文目录下,然后在控制台下,输入Mongod即可开启服务,一般要设置数据库文件所在目录,需要增加-dbpath参数,默认mongodb的端口是27017端口,可以通过-port修改其他端口,但启动后无需任何密码即可连接进来并查询数据,因此开启Mongodb服务时,需要增加-auth参数,这样远程就需要密码才能连接起来查询数据了。通过输入Mongo,即可作为Mongodb客户端访问。下面列举几个客户端常用命令:
1、Show dbs可以查看当前所有数据库。
2、show collections可以查看当前数据库的所有集合。
3、use searcher可以切换到searcher数据库。
4、db.mginfo.find()可以查看当前数据库的mginfo集合的数据。
5、db.addUser(‘user’,’pwd’);可以新增当前数据库的用户,服务端如果用-auth参数启动后,客户端需要db.auth(‘user’,’pwd’);鉴权后才能正常读取Mongodb的数据。
因此正常情况下,服务端运行mongod -dbpath=D:\mongodb\data –auth
客户端就可以通过用户密码访问对应数据库了,可视化查看界面可以用MongoVUE来查看mongodb的数据用户信息。Java客户端包我用的mongo-2.9.3.jar包,操作语句比如:
Mongo mongo = new Mongo("localhost", 27017);
DB db = mongo.getDB("searcher");
if (db.authenticate("user", "pwd".toCharArray())) {
DBCollection users = db.getCollection("mginfo");
users.insert(object);
}
通过客户端mongo也同时需要鉴权才能查询和操作数据了。
搭建爬虫过程:
安装完毕后,首先需要用Nutch去爬数据,到Cygwin的安装目录运行Cygwin.bat或者桌面快捷方式运行Cgywin,然后cd到Nutch的目录,在Nutch目录下先建一个txt文档,用于保存需要爬的网站,每个网站一行,比如保存为url.txt,然后比如运行:bin/nutch crawl url.txt -dir crawlDir -depth 5 -topN 5000 -threads 100,如下图:
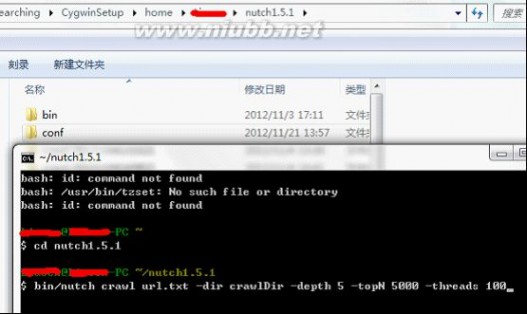
然后就可以爬取url.txt文档里记录的网站内容了,这里-depth表示爬取网站的深度,这里为5层,-topN表示每层最多个URL记录,这里为5000个,-threads表示一共多少个线程执行,这里为开启100个线程做抓取网站的工作,但实际每个网站是几个线程来爬取,需要在单独的配置节点配置,fetcher.threads.per.queue这个节点的值表示每个配置的网站用几个线程来抓取。
然后开始等待爬取网站,爬取结束后,crawlDir文件夹下多了crawldb、linkdb、segments文件夹,里面包括.data.crc,.index.crc,data,index文件。这些都是Nutch抓取后的数据文件。
Nutch抓取完毕后,需要把这些文件发送给solr建立索引,首先需要启动solr,solr默认用jetty作为web服务器,进入solr的安装目录,比如我的是D:\solr3.6\,然后进入example目录执行:java -jar start.jar,则可用jetty的方式启动solr网站,默认端口是8983,如下图: lawson
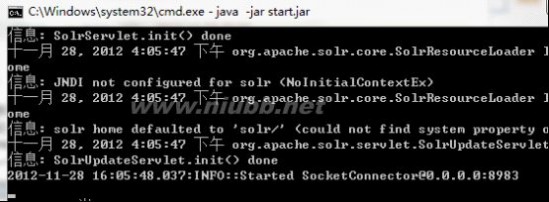
Solr启动后,就可以在Cgywin里通过命令把Nutch抓取的数据发送给Solr建立索引,通过命令:bin/nutch solrindex http://localhost:8983/solr/ crawlDir/crawldb -linkdb crawlDir/linkdb crawlDir/segments/*,如下图:
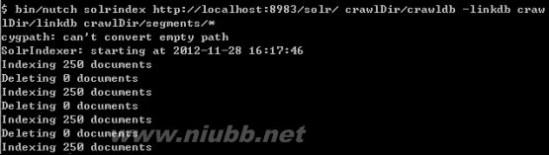
现在Solr里的D:\solr3.6\example\solr\data文件夹里已经保存有lucene格式的索引以及数据文件了。
然后可以用Solr测试下现在的搜索结果,通过访问http://127.0.0.1:8983/solr/admin/,搜索标题为:航旅天空:
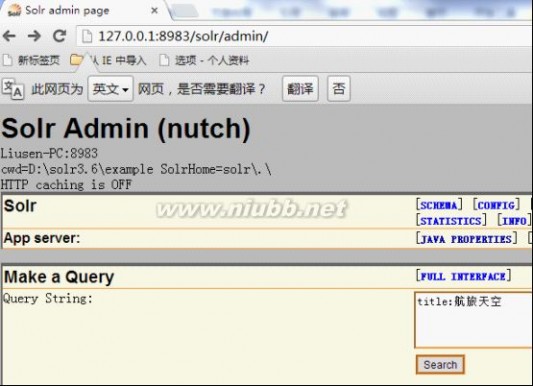
搜索结果如下:
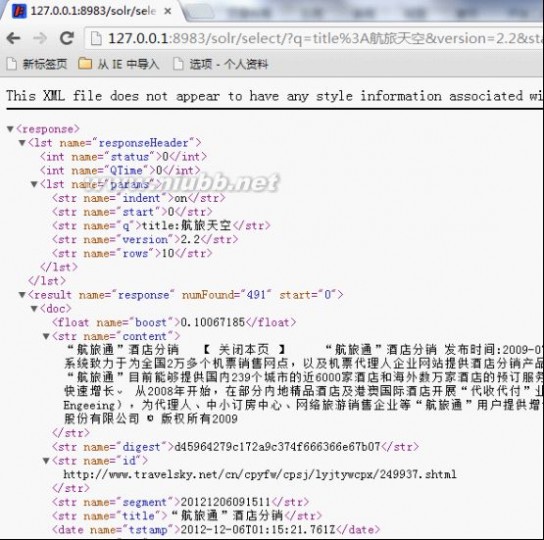
如Solr的结果,一共查找到491条记录。现在说明Lucene正常建立了索引并能成功查询出结果了。
遇到的问题:
我在部署上面环境和搭建过程中遇到很多问题,比如:
1、Nutch爬取网站时,会报错:Failed to set permissions of cygwin,最后经过大量资料查阅,问题应该是nutch的lib文件夹下hadoop-core-1.0.3.jar文件有个权限判断引起的,但由于对hadoop和cygwin不够熟悉内部细节,就下载了hadoop-core-1.0.3.jar的源代码,把FileUtil类的checkReturnValue方法修改了,把里面的代码全部注释了,最后解决了这个权限问题。
2、还有报错:No agents listed in 'http.agent.name' property,这是因为默认Nutch配置文件没有设置爬取网站的爬虫User-Agent头,需要设置一个,修改conf/nutch-default.xml的property节点下的<name>http.agent.name</name>的value值即可。
3、启动Solr后,访问http://127.0.0.1:8983/solr/admin/有时也有报错:in solr.xml org.apache.solr.common.SolrException: Schema Parsing Failed: multiple points,这个问题是因为Solr下的conf配置文件schema.xml有问题导致的,网络基本没有搜索到这个问题,根据报错内容,我发现该XML文件的根节点:<schema name="nutch" version="1.5.1">配置的1.5.1可能和报错内容有关系,就修改成<schema name="nutch" version="1.5">,结果就没有问题了。
4、除了上面3个会影响最基本爬取数据的问题,还遇到下面3个比较麻烦的问题:
l 有一个内部网站需要登录才能访问,Nutch不能爬取需要登录后才能访问的网页内容。
l 有一个内部网站有robots.txt文件,并且里面限制了爬取所有页面,Nutch会识别该robots.txt,并不爬取这个网站的内容。
l 有一个内部技术论坛用JForum搭建的,这个开源论坛有识别是否爬虫的功能,Nutch默认被当做爬虫,不能爬取了。
针对第一个问题,经过分析,发现这个网站实际就是通过设置cookie,并且可以设置cookie永久有效,因此只需要修改下抓取网站的源码,设置好cookie就行了,Nutch的jar包大多是通过插件的方式注入的,Nutch抓取网页内容是用protocol-http.jar包的HttpResponse类的构造函数执行抓取操作,构造函数为HttpResponse(HttpBase http, URL url, CrawlDatum datum),内部用Socket的方式构造http请求协议头和内容来获取远程网页的内容,根据不同域名增加类试:
reqStr.append("Cookie: ");
reqStr.append("IS_NEED=1;...;");
reqStr.append("\r\n");
的Http请求头,则可对该域名下的所有网站都带cookie去获取远程网页数据了。
第二个问题Nutch内部默认会判断robots.txt文件,为了修改更简单,我直接修改了apache-nutch-1.5.1.jar包的org.apache.nutch.fetcher.Fetcher下的私有类:FetcherThread的run方法,代码如下:
RobotRules rules = protocol.getRobotRules(fit.url, fit.datum);
/* if (!rules.isAllowed(fit.u)) {
// unblock
fetchQueues.finishFetchItem(fit, true);
if (LOG.isDebugEnabled()) {
LOG.debug("Denied by robots.txt: " + fit.url);
}
output(fit.url, fit.datum, null, ProtocolStatus.STATUS_ROBOTS_DENIED, CrawlDatum.STATUS_FETCH_GONE);
reporter.incrCounter("FetcherStatus", "robots_denied", 1);
continue;
}*/
把判断当前robots.txt内容是否允许爬取网站的逻辑注释掉了,即它还是去分析robots.txt文件,但分析完成后不判断它是否禁止了爬取该网站。
第三个问题是因为该网站以前挂的公网,虽然现在挂内网了,但robots.txt一直存在,这个程序以代码的方式判断是否爬虫,并判断是否屏蔽它的访问,我下载了JForum的源码,发现它主要是通过资源文件:clickstream-jforum.xml配置的Host和user-agent的value值作为爬虫黑名单,Host我肯定不满足,只要修改User-agent头即可,Nutch可以修改nutch-default.xml配置文件,把 <name>http.agent.name</name>节点的值修改下即可,修改后爬取的记录如:
2012-12-05 05:40:37 127.0.0.1 GET /robots.txt - 88 - 127.0.0.1 MozillaLiu/Nutch-1.5.1 404 0 2 0
User-agent里的Nutch-1.5.1从哪里来的呢?通过源码,我才发现这个是另外一个配置节点的值:
<property>
<name>http.agent.version</name>
<value>liu1</value>
<description>A version string to advertise in the User-Agent
header.</description>
</property>
通过这样配置后,爬虫爬取记录就变为:
2012-12-05 05:54:11 127.0.0.1 GET /robots.txt - 88 - 127.0.0.1 MozillaLiu/liu1 404 0 2 0
现在访问记录就没有任何异样的名称了。最终解决了JForum搭建的这个技术论坛,爬虫能正常爬取这个网站的数据了。
http://lawson.cnblogs.com
通过上述方法解决了我搭建搜索平台的主要问题,但是比如需要登录才能抓取的网页、有robots.txt写明禁止爬虫爬取的问题,虽然让我的爬虫爬取了,但感觉还是抓取这样的数据还是比较暴力,但因为是内网数据,只是用于内部搜索方便大家,因此就让它暴力一点把。
二、平台搭建
平台数据有两个来源:1、来自爬虫的数据和建立的索引数据;2、用户手工上传的文档,因为主要是上传分享的知识,因此上传的文档支持doc,docx,ppt,pptx,pdf。通过上述的介绍,爬虫的数据已经有了,现在需要编写支持用户上传文档的逻辑,并建立Lucene索引和用户搜索的平台。
要实现对用户手工上传文档进行索引并可查询,需要做下面三步:
1、首选需要处理上传文档的解析工作,解析成可以识别的文字文档
2、然后对解析后的文档建立索引,并通过数据库持久化保存一些必要的信息。
3、开发前台页面,能通过用户的搜索信息查询出结果。
http://lawson.cnblogs.com
首先对Office文档的操作,可以用开源项目POI来读取文档内容,在http://poi.apache.org/下载后,解压即可,我是用的3.8版本,比如读取.doc文档代码比如:
org.apache.poi.hwpf.extractor.WordExtractor doc = null;
try {
doc = new WordExtractor(new FileInputStream(filePath));
} catch (Exception e) {
e.printStackTrace();
}
if (null != doc) {
result = doc.getText();
}
读取.docx文档代码比如:
XWPFWordExtractor docx = null;
try {
OPCPackage packages = POIXMLDocument.openPackage(filePath);
docx = new XWPFWordExtractor(packages);
} catch (XmlException e) {
e.printStackTrace();
} catch (OpenXML4JException e) {
e.printStackTrace();
}
if (null != docx) {
result = docx.getText();
}
读取.ppt文档代码比如:
StringBuffer content = new StringBuffer("");
try {
SlideShow ss = new SlideShow(new HSLFSlideShow(path));
Slide[] slides = ss.getSlides();
for (int i = 0; i < slides.length; i++) {
TextRun[] t = slides[i].getTextRuns();
for (int j = 0; j < t.length; j++) {
content.append(t[j].getText());
}
content.append(slides[i].getTitle());
}
} catch (Exception e) {
System.out.println(e.toString());
}
读取.pptx文档代码比如:
OPCPackage slideShow;
String reusltString = null;
try {
slideShow = POIXMLDocument.openPackage(path);
XMLSlideShow xmlSlideShow = new XMLSlideShow(slideShow);
XSLFSlide[] slides = xmlSlideShow.getSlides();
StringBuilder sb = new StringBuilder();
for (XSLFSlide slide : slides) {
CTSlide rawSlide = slide.getXmlObject();
CTGroupShape gs = rawSlide.getCSld().getSpTree();
@SuppressWarnings("deprecation")
CTShape[] shapes = gs.getSpArray();
for (CTShape shape : shapes) {
CTTextBody tb = shape.getTxBody();
if (null == tb)
continue;
CTTextParagraph[] paras = tb.getPArray();
for (CTTextParagraph textParagraph : paras) {
CTRegularTextRun[] textRuns = textParagraph.getRArray();
for (CTRegularTextRun textRun : textRuns) {
sb.append(textRun.getT());
}
sb.append("\r\n");
}
}
}
reusltString = sb.toString();
} catch (IOException e) {
e.printStackTrace();
}
上面就完成了常见的幻灯片培训和技术分享文档的读取了。
对PDF文件的读取可以通过开源项目PDFBox来处理,在http://pdfbox.apache.org/下载后解压即可,我是用的1.7.1版本,在官网下载下来只有pdfbox-1.7.1.jar包,但它还依赖了很多其他开源Jar包,需要下载的有bcprov-jdk15on-147.jar,commons-logging.jar,fontbox-1.6.0.jar,icu4j-50rc.jar,JempBox-0.2.0.jar,才能正常读取PDF文档,当然这些jar包可能其他版本也是可以用的。读取PDF文档代码比如:
FileInputStream fis = new FileInputStream(filePath);
String result = "";
try {
PDFParser p = new PDFParser(fis);
p.parse();
PDFTextStripper ts = new PDFTextStripper();
result = ts.getText(p.getPDDocument());
System.out.println(result);
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
这样就能读取出PDF的文档内容了。
文档内容获取后,需要对它们建立索引,通过Lucene的API可以很方便的为这些内容建立索引数据文件,需要注意的是,需要对文档内容进行存储,代码如下:
Field fieldcontent = new Field("content", info.getContentString(), Store.YES, Index.ANALYZED);
doc.add(fieldcontent);
并且IndexWriter写索引文件时,需要用IKAnalyzer作为分析器。
对于用户搜索信息,最好能像百度一样可以对搜索的关键词进行高亮显示,Lucene提供了lucene-highlighter-3.6.0.jar包,来对搜索高亮效果等进行处理,处理语句如下:
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<b><font color='red'>", "</font></b>");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(showContentString));
String str = highlighter.getBestFragment(tokenStream, showContentString);
这样根据highlighter的getBestFragment方法获取到首先找到的文档内容里符合搜索条件的文档内容,并且符合搜索条件的数据用font color为red的标签框起来了。默认str的长度只为100,即返回100长度的文档内容,可以通过下面的方法修改:
Fragmenter fragmenter = new SimpleFragmenter(150);
highlighter.setTextFragmenter(fragmenter);
这样返回的就是150字符长度的内容了。
通过上面搭建的工作和代码编写的工作,网站功能已经基本开发完毕,搜索“航旅天空”的效果如下:

搜索到的数据都是爬虫爬取的结果,如果是别人主动分享的文档,搜索“B2B 自动出票 汇付 本票通”效果如下:

查询的第一条结果是人工上传的分享文档,链接直接是一个分享PPT的下载地址并且如果上传人填写了名字,查询时会显示上传人的姓名。
现在一个简易版的搜索平台就搭建好了,有相关问题欢迎沟通!
转载请注明来自: http://lawson.cnblogs.com
三 : 百度站长平台:搜索关键词工具再次升级
继去年5月份百度站长搜索关键词升级后,最近该功能又再次升级,并且亮点颇多。
1、增加展现量和点击量的热门关键词和热门页面,提供十分详细的搜索数据,具体到某个关键词的展现量和点击量。
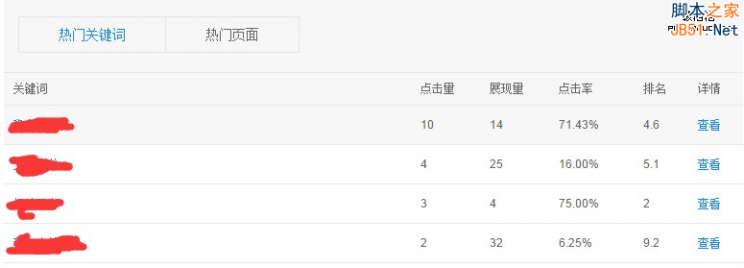
2、点击量和展示量的数据精准到每天的每个时间段,可以轻松查看每天的访问数据,还有对比前一日功能。
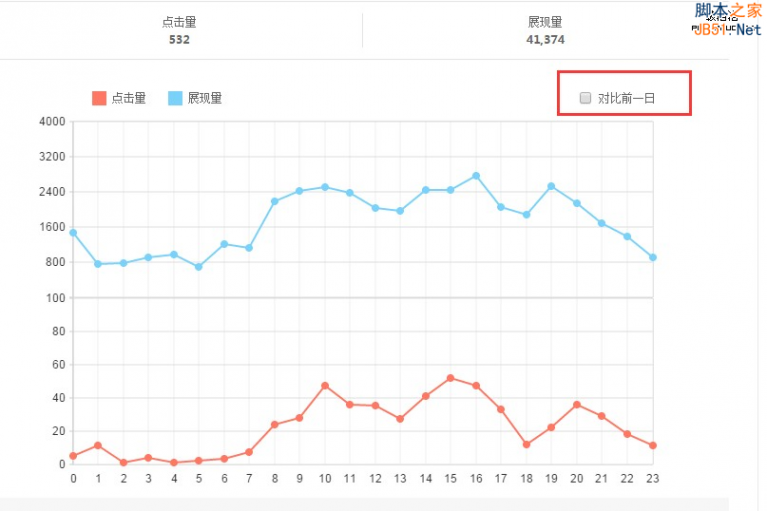
3、不在局限于之前只能查看最近7天和最近30天两个选项,而是可以自主定义查询范围,更加人性化。
4、增加移动搜索的数据查看。

5、提供全部数据下载,这点做得很好。csv文件默认编码是UTF-8,excel打开乱码的话,记事本另存为编码ANSI即可。

这次工具升级感觉真的很实用,和CNZZ的数据进行对比有轻微的差距,也算合理。
------------
以下摘自站长平台:
搜索关键词工具里出现的展现量、点击量、点击率、排名都是什么?
展现量:搜索用户在百度搜索引擎查询某关键词时,看到您网站的次数;
点击量:搜索用户在百度搜索引擎查询某关键词时,点击进入您网站的次数,即该关键词下,您网站从百度获得的流量;
点击率:点击量和展现量的比值,在一定程度上表征了网站的优化空间,点击率越小,网站的优化空间越大;
排名:在热门关键词和热门页面列表中给出的排名是平均排名,表征在相应时间段内,搜索用户在查询某关键词时,落地页在百度搜索结果页的平均排名,是统计数据。
热门关键词和热门页面分别指什么?
热门关键词:用户在百度搜索引擎中进行查询时,您网站获得流量(点击量)较多的关键词。工具最多可以提供5W个关键词,默认按点击量降序排序。您可以通过热门关键词,查看用户通过相应的关键词访问了哪些页面。
热门页面:用户在百度搜索引擎中进行查询时,您网站中获得流量(点击量)较多的URL。工具最多可以提供5W个热门页面,默认按点击量降序排序。您可以通过热门页面,查看到达相应页面的关键词。
使用搜索关键词工具能给您带来什么?
搜索关键词工具不仅能够提供网站天级、周级及月度展现量、点击量数据,还能够提供站点的热门关键词在百度搜索结果中的展现及点击量数据,及网站热门关键词在今天(有大约5小时的数据延迟)、昨天、最近7天、最近30天、30天内自定义时间段等不同时间维度的展现量及点击量数据,最高可展现5W条关键词数据。工具旨在全面帮助站长了解网站在百度搜索引擎中的表现,决定页面及网站的优化方向,为网站运营决策提供分析依据。
本文为烟台SEO http://blog.sina.com.cn/lianlanglenghen 原创,转载请注明出处。
四 : 360搜索上线网络反黑高级算法"悟空算法" 助百万站长抗击黑客攻击
当下,互联网与人们生活的联系日益密切,提供海量信息与服务之外,也存在网站被黑成博彩、色情页面,误导欺骗用户的行为。这些负面因素让网站管理者头疼不已。近日,360搜索发布站长公告,宣布上线网络反黑高级算法“悟空算法”,号召百万站长联合起来,抗击黑客攻击。
触目惊心!互联网黑色产业规模巨大
此前,知名的互联网安全论坛站freebuf上,曝光了互联网黑客黑站的产业链,结果令人触目惊心。仅仅被曝光的这一个团伙,就拥有核心技术团队、财务和市场职能部门,掌握着一万多个域名的后台管理员的用户名和登陆密码,其中甚至包括一些大的新闻媒体站。根据tomsinsight的调查报告,仅黑色产业链的一项,由私人坐庄,私自控制返奖率的黑彩,每年的销售额就达5000亿元。
“黑色产业就像网站里的寄生虫”。黑客不产生价值,但黑客赚的每一分钱,最终都是要由网站和用户来买单。一些网站遭黑之后,最常见是内容被恶意删除篡改,经调查统计,黑客最喜爱将网站伪装成博彩类网站,诱导用户进行非法博彩。此外,黑客还能调取网站服务器内用户的敏感信息,包括账户,密码,个人信息等都有可能遭窃取。接着,这些信息可能被用来诈骗网站的用户。从黑客攻击网站到各类电信网络欺诈,只有一步之遥。
网站被黑后,也影响收录该网站的搜索引擎。比如,在搜索结果中将无法展现正常的标题和摘要,取而代之的是博彩、色情等不良内容,对网站在搜索引擎中的排序、网站流量、声誉和用户体验都会造成极其恶劣的影响,背后隐藏的各种欺诈、钓鱼行为会严重损害网民利益。
据了解,网站被黑风险,一般取决于网站所有者对于网站安全的重视和投入程度,一般不涉及直接交易和以发布信息为主的网站,更容易遭到黑客攻击。诸如教育、政府和企业的主页。相对而言金融,电商类网站不容易遭黑。360搜索做过一个预估,除去影响特别小的站不计入,国内互联网上被黑的规模站在十万左右。
360搜索上线悟空算法 专职“打黑”
360作为一家业内独有“安全”基因的公司,其旗下360搜索也是安全、精准、可信赖的新一代搜索引擎,全面拦截各类钓鱼欺诈等恶意网站,提供更放心的搜索服务。此外作为国内第二大搜索引擎,360搜索日服务4亿互联网用户,打击黑色网站,是360搜索责无旁贷的义务。
360搜索目前上线的“悟空算法”,使用到了先进的机器学习算法,准确率,召回率等各项指标达到了业界领先的水平,误判概率极小。悟空算法做到了完全无需人工介入,小时级快速识别被黑站。360搜索预计,上线悟空算法后,将减少70%被黑非法篡改页面被用户访问的概率。
黑客对网站发起攻击的目的之一就是利用搜索引擎的进行导流,而悟空算法减少了70%的被黑网站的非正常流量,将对黑客这一获益途经造成致命打击。360搜索作为互联网时代流量入口,一直秉承给用户绿色,干净和准确的搜索结果页,悟空算法先进的技术优势,能快速识别被黑网站,让黑客无处遁形。
此外,360搜索还发布公告,主动建立和全国各大站长的联系通道。通过悟空算法检测到被黑网站后,360搜索将第一时间通知站长,提醒加固修补漏洞,减少数据泄露,从源头上防范黑客攻击。此外360搜索还开通站长平台,各大站长能在平台注册,以获知网站被黑通知。此外,站长平台还提供安全扫描功能,漏洞库会第一时间得到补充。
360搜索携手百万站长,共同抗黑
抗击互联网黑色产业链,需要互联网和社会各界的通力配合。不管是互联网安全公司,还是网站平台站长,各地网警须结成“统一战线”,将骗子和黑客陷入“人民战争汪洋大海”之中。
360搜索本身独具安全基因,让它在搜索引擎业内独树一帜。在收录互联网浩如烟海的信息时,360搜索会自动识别屏蔽掉绝大多数带有钓鱼,不良信息的网站。同时,360搜索也致力于协助网站站长,建设更加安全可信的网站环境。对于网站站长和互联网从业者,360搜索安全专家给出以下建议:
首先,须遵循业内的安全规范,不明文存储密码,明文密码存储极容易造成用户数据泄露,黑客拿到大量用户名和密码,给后续电信/互联网诈骗提供黑色通道。今年开学季,多起大学生因考试信息泄露遭遇电信诈骗致死,就给网站安全运维敲响警钟;
其次,对网站的登陆,各级数据库访问等权限做细化控制,形成必要的安全规范;
再次,聘请专业的安全公司做外部审查。360搜索开辟站长平台,能帮助广大站长发现问题网站,并提供安全扫描。站长在日常运维中,检测到来自搜索引擎的流量,如发现博彩,色情,非法等搜索词的比例突增,网站极有可能已经被黑。
本文标题:百度搜索站长平台网站-百度站长平台:百度图片搜索收录展现有何要求?61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1