一 : 面临被K的如何重新恢复收录
昨天打开收录查询网站, 查询网站收录情况!一看把自己吓了一跳,谷歌收录从28000减到了4000多,这对一个新站来说,可是一个不小的打击! 前几天听朋友说,这是谷歌在调整,很正常的,所以一直没在意这些,今天包括主负域名都大量减了近5分之4的收录,这下我彻底的急了,百度搜索问题,找答案,原来以为百度是万能的,自从封网门之后,从万能变成了无能,这是代表着什么?经济衰退吗?中国的互联网真的要倒退10年吗?做站长的我,心情只有一个字形容(哎)。
也许做站长的都和我一样,经过封网门之后,心也累的不堪一击了!一直坚持做站的我,,现在的心情也只能抱着混一天是一天的思想,说不定,那天自己的站也就关门大吉了! 希望越重,失望越重。
呵呵,好像走题了!言归正传,百度查了好多关于这方面的资料,好多文章都说,这是被K前的征兆。晕了,这可怎么好,前几天用PR预测软件,测试了下自己的站(安庆视窗)也许会到PR4,心情一直很好,今天看了,这些文章,心真的那个急啊,真的是无法用文章来形容了。在百度上也找不到相对的解决办法。难道真的没办法在短时间内恢复收录吗?
正在郁闷的我,突然想到以前有篇SEO的文章,写到如果发现自己的站要被K的话,要及时抢救,也许会有挽回的希望,哈哈,还好记性不错,文章内容也大致的记得,他是这么说的,首先找个软件搜索下目前的热门关键词,选排前三的关键词,在百度搜索其相关文章。将文章内容也稍微修改下,变成伪原创!发布在自己的网站,用粗体显示在网站首页上,然后在其没恢复收录的时候,千万不要使用采集器和复制别人没有价值的文章,然后在蛛蛛经常去的网站,发表有自己网站连接的文章!! 这样也许会恢复你站的权重和收录,我抱着试下的心情,去做了,从早上开始,一直重复做着同样的事情,一直到了6点钟去妈妈家吃饭回来后! 惊喜的发现奇迹出现了,用软件查询自己的站安庆视窗既然收录全部恢复了。反连也恢复了,我以为是假的,又去查询下别人的站,他们的到目前还没收录,没想到这办法也是不是办法的办法啊,这里只是简单的介绍了下,我也不会SEO,只是觉得有用的经验和大家分享下,给那些新手看看,毕竟这也是我做站的心得啊,说的不好,大家别拿砖头砸我啊??最多以后不发表文章了!嘿嘿
欢迎大家和小站做个连接 安庆视窗 www.517aq.com QQ:39901706本文转自:安庆视窗
二 : 百度已支持Canonical标签 避免重复内容收录
今日百度站长平台发布公告称:百度开始支持Canonical标签,如果站长添加了该标签,就代表站长向百度推荐了某个网页作为最规范的网页版本,每个页面中仅有一个canonical标签。同时百度最后又说明:不保证完全遵守该标签。
简单来说canonical标签可以为搜索引擎指明当前页面权重的侧重点在于哪个链接,从而有助于SEO。canonical 是 Google、雅虎、微软等搜索引擎一起推出的一个标签,它的主要作用是用来解决由于网址形式不同内容相同而造成的内容重复问题。这个标签对搜索引擎作用非常大,简单的说它可以让搜索引擎只抓取你想要强调的内容[www.61k.com)。
比如本博客为了评论功能会在URL加入特殊字符如:
#cmt194776
那么在网页上加入
<link rel="canonical"href=""/>
zblog代码的写法也比较简单,在head上加入一下代码即可:(建议discuz论坛使用)
<link rel="canonical"href="<#article/url#>"/>
三 : 怎么避免网站大量重复URL被百度收录?
很多同学会有这样的疑惑,索引量工具显示索引量数值很高但流量总也上不去,也没有发现我们站内有低质内容,百度这是要闹哪样?如果各位同学还有工作经验等内容想分享、或者对已有内容持相反意见者,欢迎给站长学院投稿。
首先声明,我们只谈论有检索意义的URL,也就是用户会从搜索引擎查找的页面。其他页面按照常用的方法做屏蔽就好了。鉴于很多站长都爱讨论整体的收录量,我必须泼一下冷水,也许你的有效收录是1/10。
URL参数
也叫URL query,是一个最复杂,最容易被忽视,最容易被妥协的问题。他是网站运营中必不可少的元素,如果简单的去除,其他部门就无法工作了。 静态化是的话题,URL参数经常被用于以下几方面:
同一个实体的不同状态展示,比如同一个酒店,在不同时间点会有不同的房间库存:http://www.travel.com/hotel/123/?checkindate=2015-06-09&checkoutdate=2015-06-10
为了统计不同渠道的流量:http://www.a.com/?tracking=website_a
为了统计不同渠道,具体模块的点击量:http://www.a.com/?tracking=website_a&click_spot=zone_abc
调试:http://www.a.com/product/item123/?debug=true
全世界最奇葩的是亚马逊,居然把统计参数放到了路径中http://www.amazon.cn/abc/dp/B005TZHJEQ/ref=lp_2130608051_1_1
出现这种问题的坏处有几点:
1. 浪费搜索引擎对你网站的各项配额,从而影响其他正常的页面。
2. 丢失很多本应拿到的链接加分,站外渠道的链接往往是最优质的。同一个URL的分值可能分散成几十份。
3. SEO的流量被统计到别的渠道(因为tracking字段写的是别的渠道,而且被收录被点击)
4. 往往形成一种局面,产品用一套URL,SEO用另一套URL, 甚至不同渠道用不同的URL,后期开发和维护的成本极高。
为了解决这个问题,首先要弄清URL的定义。以我的理解,每一个URL是一个静态的、独立不重复的、有意义的实体,一般也有检索意义(就是有人会搜)。比如一个人、一辆车、一条道路、一个零件。而不能混入各种"状态",比如这个人生病的时候,难道就不是他自己了么? 一件商品在促销的状态难道是另一件商品了么?
理论上canonical标签就可以解决这个问题了, 但是从实际测试结果看,百度对这个标签的支持优先级非常低, 几乎可以忽略不计。那么我的解决方案是这样的:
1. 建立好网站的思维导图和元信息。
2. 所有和SEO元信息相关的参数都放到路径中去
3. 所有和SEO元信息不相干的参数都放到#后边,因为#后边不影响web服务器返回的内容。简单的说就是用"#"替代"?"。
4. 每个页面中都利用js获取#后边的参数对,通过二次请求发回给统计服务器
5. 如果#后边的参数影响页面内容,比如酒店的入住日期。那么这部分内容用ajax加载就行,他是不稳定的,不属于页面内容的一部分。(当然还有变通的办法,暂不赘述。)
6. 原始的#锚点定义肯定会冲突,定义一个#后边的变量,并用js控制屏幕滚动,来保证原始锚点的作用。
有人可能会想到,根据ua判断,如果是搜索引擎爬虫,就用跳转的方式去掉URL参数。但效率最高的方法必然是从一开始就不展示错误URL。那么前面的例子优化后就变成了:
http://www.travel.com/hotel/123/#checkindate=2015-06-09&checkoutdate=2015-06-10
http://www.a.com/#tracking=website_a
http://www.a.com/#tracking=website_a&click_spot=zone_abc
http://www.a.com/product/item123/#debug=true
其实很多网站早就使用这种方式了,但是还有很多网站由于开发效率无法及时实现。所以对于一般的小网站,一定要考虑开发成本,不要轻易冒进。只要能避免问题的发生,变通的方法是很多的。
路径中使用非必要元素
很多网站仿照亚马逊的做法,把商品名体现在URL中,然后再通过id来决定页面展示的内容:http://www.amazon.cn/博集典藏馆043•基督山伯爵-亚历山大•仲马/dp/B005TZHJEQ/
这样虽然可以提高一些相关性,但是很危险。在长期甚至短期的时间内,大量商品的名称是非常可能有变化的,那么URL也就跟着变化。成本也是非常高的,因为加大了技术实现难度,不管从站内还是站外,每次增加链接都是一个很麻烦的事情。
在我接手艺龙SEO之前,URL被全部改成了这样,对我早期的工作造成了非常巨大的负担:http://www.a.com/Shangrila_International_Hotel-12345678-hotel/
通过日志分析发现基本所有的百度蜘蛛发起的请求都被301跳转了一次(日志分析方法可参考SEO健康度 )。细致调查后发现,从SEO拼接规则到后台的汉字和翻译数据被一直修改。也就是说,这个URL相关的元素有:
1. 中文 (非必要元素)
2. 由中文翻译的英文 (非必要元素)
3. id (必要元素)
而当时负责SEO的同事把英文和id拼接在了URL中,那么这样一个URL先后变成过:
http://www.a.com/Shangrila_International_Hotel-12345678-hotel/
http://www.a.com/Xianggelila_International_Hotel-12345678-hotel/
http://www.a.com/XiangGeLiLa_International_Hotel-12345678-hotel/
http://www.a.com/Shangrila_guoji_Hotel-12345678-hotel/
跟"相关性"比,URL的唯一性和稳定性更重要。所以针对这个问题,URL的最佳策略应该是:http://www.a.com/hotel/12345678/
如果这个id是隶属于一个分类下的,比如城市,那么就可以是:http://www.a.com/hotel/beijing/123/
从技术角度说, id一般是数据库的primary key,可以是数字也可以是字符串,那么这个时候URL是一维的; id也可以是联合的唯一索引,那么URL就是二维的,就像上面的(bejing,123)缺一不可。电商类网站列表页经常用到三维以上。
大小写
如果网站的技术架构用的是开源系统,一般是不会有这个问题的。如果使用了微软的技术架构,这个问题非常常见:
http://www.a.com/newyork/
http://www.a.com/Newyork/
http://www.a.com/NewYork/
我的建议是统一使用小写,大写自动跳转为小写(小心301死循环!)。
目录的规范
很多网站同时存在这样的URL,无形中把收录量扩大了一倍:
http://www.a.com/product/123
http://www.a.com/product/123/
上边第一个路径的意思是在product目录下有一个123文件。第二个路径的意思是在product目录下有一个123目录,这个目录下可能有很多文件,但是他代表众多文件中的index.html或index.php或default.aspx等优先级最高的那个文件。为了避免歧义,我定义文件都是用".html"结尾的。
为了减少重复收录,那么按我的习惯是:
http://www.a.com/product/123 => http://www.a.com/product/123/
http://www.a.com/product/123 =>
总结
1. 所有部门统一使用SEO定义的URL,屏蔽非SEO URL的入口。
2. 用"#"替代"?"
3. 统一使用小写
4. 保证目录的规范
5. 把不规范的URL跳转到规范的URL
四 : excel如何禁止和避免重复输入姓名?
在进行数据处理时,有时候需要输入人员姓名,人数众多时,重复输入的姓名一下子是难以察觉的,为避免重复数据,需要在录入的时候就进行输入限制的设置。
步骤
1、打开excel工作薄,现在需要对表格中的姓名进行输入编辑。
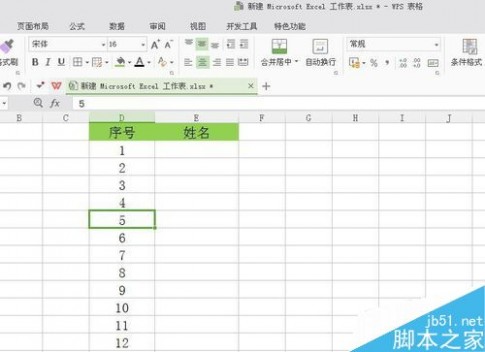
2、选中【姓名】那一整列,选择数据-有效性,数据有效性就是防止在单元格中输入无效数据。
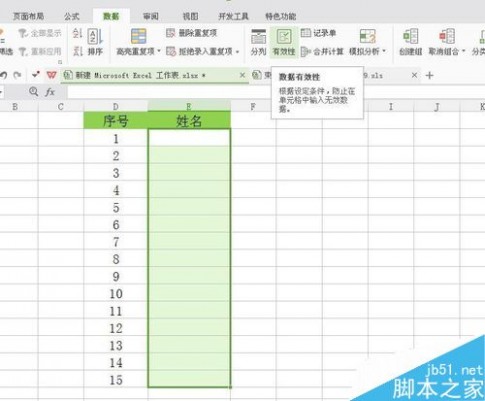
3、跳出数据有效性的对话框,在设置中条件中,允许选择自定义,公式输入=countif($E$2:E2,E2)=1,确定。E就是姓名所在列,E2就是姓名输入中的第一个单元格。

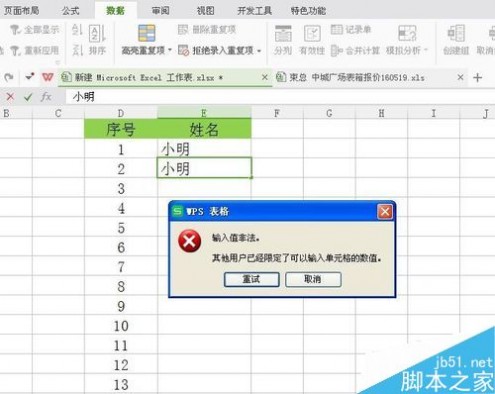
4、试着连续输入两个【小明】,跳出警示框,提示输入值非法。这时候就点击重试。
5、点击重试之后,会回到重复输入的单元格,可重新输入。
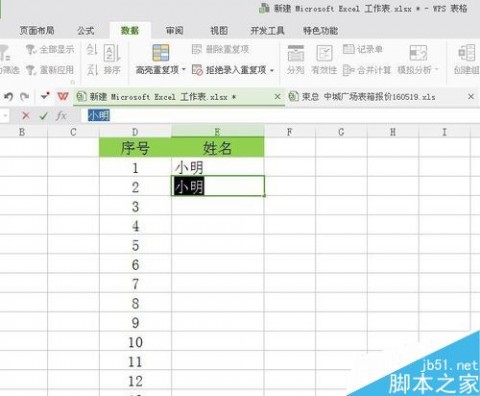
6、输入小红之后,不再跳出警示框,可以接着继续输入。

以上就是excel如何禁止和避免重复输入姓名方法介绍,操作很简单的,大家学会了吗?希望这篇文章能对大家有所帮助!
本文标题:如何避免重复性收录-面临被K的如何重新恢复收录61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1