一 : QQ实验室新作QQ慧眼新鲜体验 即时翻译
QQ慧眼新鲜体验 前言
总感觉当我们的手机越来越智能时,我们也逐渐变得越来越懒,哈。这不,又出现了一款利用手机摄像头实现即时翻译的软件,QQ慧眼,没错,它也是腾讯推出的一款产品。能想到的此类软件中最早的一款,应该是国外的Word Lens,当然,还有我们早在年初评测的看译全能王,他们都是通过手机摄像头获取单词,然后进行翻译,而至于这款QQ慧眼的表现如何,下面就来体验一番。
QQ慧眼 官方网站
QQ慧眼新鲜体验 即时翻译
初次使用QQ慧眼需要等待一段时间,因为需要加载数据。待大约5、6秒之后,QQ慧眼显示其主界面,左上角为语言切换键,支持中英互译、法译中和德译中。当我们用屏幕取词时,需要将屏幕的中心对准单词,而且需要保持一定距离,总体来说,想要保证取词的准确性,有些费时有点儿难度。


进入QQ慧眼


更改语言并翻译
如果觉得使用摄像头对焦的方式取词不够稳定,那么可以选择将它照下来,再慢慢识别。在图中,以蓝色标记出来的均为QQ慧眼识别出的单词,但是有些词语却是分开的,比如图中的“短信”就被分为两个字分别翻译这个现象不仅仅出现在“中文译英文”中,“英译中”也出现了类似情况。

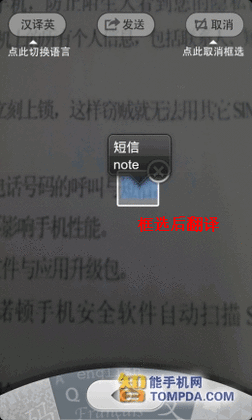
拍照后翻译
QQ慧眼新鲜体验 单词查询
QQ慧眼除了能够通过摄像头识别单词以外,还支持查词功能。不论是搜索中文单词还是英文单词,QQ慧眼提供的结果均来源于网络,并提供多个解释,但似乎许多解释都是重复的。笔者试着输入一个未完成的单词,但是软件并不提供单词联想功能。


查询单词


不具备词汇联想功能
点评:
每个单词都有多个意思,但是在利用摄像头取词翻译时,我们通常只能看到一个释义,所以QQ慧眼在平时应急来用还算说得过去,但要是想用它替代手机中的翻译软件,还是差了一些火候。QQ慧眼的功能切入点很好,但仍有待完善。
二 : 机器翻译-从实验室走向市场

冯志伟与日本机器翻译第一人者长尾真
机器翻译软件从实验室走向市场
冯志伟
机器翻译研究如何用计算机来进行不同自然语言之间的翻译,它是自然语言计算机处理的1个历史悠久的部门,是横跨语言学、数学、计算机科学的综合性学科,也是计算机软件应用的1个重要领域。随着计算机网络的迅速普及和推广,随着信息高速公路的发展,网络上不同语言之间交际越来越普遍,语言的障碍也显得越来越严重,机器翻译是克服信息时代的语言障碍的不可缺少的手段,它在现代信息社会中的巨大作用将会越来越明显。由于自然语言的极端复杂性,机器翻译是当代科学技术的10大难题之一。
早在在17世纪,一些有识之士就提出了采用机器词典来克服语言障碍的想法。笛卡儿(Descartes)和莱布尼兹(Leibniz)都试图在统一的数字代码的基础上来编写词典。在17世纪中叶,贝克(CaveBeck)、基尔施(Athanasius Kircher)和贝希尔(Johann JoachimBecher)等人都出版过这类的词典。由此开展了关于“普遍语言”的运动,一些人试图在逻辑原则和图形符号的基础上,创造出1种无歧义的语言,这样一来,人们就不必再由于误解而产生交际方面的困惑了。维尔金斯(JohnWilkins) 在《关于真实符号和哲学语言的论文》(An Essay towards a Real Character andPhilosophical Language,1668)中提出的中介语(Interlingua)是这方面最著名的成果,这种中介语的设计试图将世界上所有的概念和实体都加以分类和编码,有规则地列出并描述所有的概念和实体,并根据它们各自的特点和性质,给予不同的记号和名称。
1903年,古图拉特(Couturat)和洛(Leau)在《通用语言的历史》一书中指出,德国学者里格(W. Rieger)曾经提出过1种数字语法(Zifferngrammatik),这种语法加上词典的辅助,可以利用机械将1种语言翻译成其他多种语言,首次使用了“机器翻译”(德文是ein mechanisches Uebersetzen)这个术语。
本世纪30年代之初,亚美尼亚裔的法国工程师阿尔楚尼(G.B.Artsouni)提出了用机器来进行语言翻译的想法,并在1933年7月22日获得了一项“翻译机”的专利,叫做“机械脑”(mechanicalbrain)。这种机械脑的存储装置可以容纳数千个字元,通过键盘后面的宽纸带,进行资料的检索。阿尔楚尼认为它可以应用来记录火车时刻表和银行的帐户,尤其适合于作机器词典。在宽纸带上面,每一行记录了源语言的1个词项以及这个词项在多种目标语言中的对应词项,在另外一条纸带上对应的每个词项处,记录着相应的代码,这些代码以打孔来表示。要查询的词项也利用键盘打孔来表示,检索1个词项的时间大约时十到十五秒。阿尔楚尼的原型机于1937年正式展出,引起了法国邮政、电信部门的兴趣。但是,由于不久爆发了第二次世界大战,阿尔楚尼的机械脑无法安装使用。
1933年,苏联发明家特洛扬斯基(П.П.ТРОЯНСКИЙ)设计了用机械方法把1种语言翻译为另1种语言的机器,并在同年9月5日登记了他的发明。特洛扬斯基认为翻译可以分为3个阶段,第1个阶段由只懂源语言的编辑,将输入的原文分析成特定的逻辑形式,将带有屈折词尾的变形词还原成原形词,并分析出各个单词的句法功能,为此,他创造了一套逻辑分析符号。第二阶段是利用他的翻译机,把源语言的原形词和逻辑符号转换成目标语言的原形词和符号。第三阶段由只懂目标语言的编辑,把目标语言的原形词和符号转换成目标语言。特洛扬斯基认为,他的翻译机只能在第二阶段作为自动词典来使用。不过他相信,只要能够建造出一部专门处理逻辑分析过程的机器,总有一天,上述的整个翻译程序都能够用机器来实现。特洛扬斯基这种认识,已经超越了“机器词典”的简单想法,比阿尔楚尼又进了1步。1939年,特洛扬斯基在他的翻译机上增加了1个用“光元素”操作的存储装置;1941年5月,这部实验性的翻译机已经可以运作;1948年,他计划在此基础上研制一部“电子机械机”(electro-mechanicalmachine)。但是,由于当时苏联的科学家和语言学家对此反映十分冷淡,特洛扬斯基的翻译机没有得到支持,最后以失败告终了。
机器翻译系统的研制是从40年代末期开始的。可以分为草创期、复苏期、发展期3个时期。
(1)草创期(1954年-1970年):
1946年,美国宾夕法尼亚大学的埃克特(J. P.Eckert)和莫希莱(J.W.Mauchly)设计并制造出了世界上第一台电子计算机ENIAC,电子计算机惊人的运算速度,启示着人们考虑翻译技术的革新问题。因此,在电子计算机问世的同一年,英国工程师布斯(A.D.Booth)和美国洛克菲勒基金会副总裁韦弗(W.Weaver)在讨论电子计算机的应用范围时,就提出了利用计算机进行语言自动翻译的想法。1947年3月6日,布斯与韦弗在纽约的洛克菲勒中心会面,韦弗提出,“如果将计算机用在非数值计算方面,是比较有希望的”。在韦弗与布斯会面之前,韦弗在1947年3月4日给控制论学者维纳(N.Wiener)写信,讨论了机器翻译的问题,韦弗说:“我怀疑是否真的建造不出一部能够作翻译的计算机?即使只能翻译科学性的文章(在语义上问题较少),或是翻译出来的结果不怎么优雅(但能够理解),对我而言都值得一试。”可是,维纳给韦弗泼了一瓢冷水,他在4月30日给韦弗的回信中写道:“老实地说,恐怕每1种语言的词汇,范围都相当模糊;而其中表示的感情和言外之意,要以类似机器翻译的方法来处理,恐怕不是很乐观的。”不过韦弗仍然坚持自己的意见。1949年,韦弗发表了一份以《翻译》为题的备忘录,正式提出了机器翻译问题。在这份备忘录中,他除了提出各种语言都有许多共同的特征这一论点之外,还有两点值得我们注意:
第一,他认为翻译类似于解读密码的过程。他说:“当我阅读一篇用汉语写的文章之际,我可以说,这篇文章实际上是用英语写的,只不过它是用另外1种奇怪的符号编了码而已,当我在阅读时,我是在进行解码。”备忘录中记载了1个有趣的故事,布朗大学数学系的吉儿曼(R.E.Gilmam)曾经解读了一篇长约一百个词的土耳其文密码,而他既不懂土耳其文,也不知道这篇密码是用土耳其文写的。韦弗认为,[www.61k.com)吉尔曼的成功足以证明解读密码的技巧和能力不受语言的影响,因而可以用解读密码的办法来进行机器翻译。
第二,他认为原文与译文“说的是同样的事情”,因此,当把语言A翻译为语言B时,就意味着,从语言A出发,经过某一“通用语言”(UniversalLanguage)或“中间语言”(Interlingua),然后转换为语言B,这种“通用语言”或“中间语言”,可以假定是全人类共同的。
可以看出,韦弗把机器翻译仅仅看成1种机械的解读密码的过程,他远远没有看到机器翻译翻译在词法分析、句法分析以及语义分析等方面的复杂性。
由于学者的热心倡导,实业界的大力支持,美国的机器翻译研究一时兴盛起来。1954年,美国乔治敦大学在国际商用机器公司(IBM公司)的协同下,用IBM-701计算机,进行了世界上第一次机器翻译试验,把几个简单的俄语句子翻译成英语,接着,苏联、英国、日本也进行了机器翻译试验,机器翻译出现热潮。
早期机器翻译系统的研制受到韦弗的上述思想的很大影响,许多机器翻译研究者都把机器翻译的过程与解读密码的过程相类比,试图通过查询词典的方法来实现词对词的机器翻译,因而译文的可读性很差,难于付诸实用。
1964年,美国科学院成立语言自动处理谘询委员会(Automatic Language Processing AdvisoryCommittee,简称ALPAC委员会),调查机器翻译的研究情况,并于1966年11月公布了1个题为《语言与机器》的报告,简称ALPAC报告,对机器翻译采取否定的态度,报告宣称:“在目前给机器翻译以大力支持还没有多少理由”;报告还指出,机器翻译研究遇到了难以克服的“语义障碍”(semantic barrier)。
在ALPAC报告的影响下,许多国家的机器翻译研究低潮,许多已经建立起来的机器翻译研究单位遇到了行政上和经费上的困难,在世界范围内,机器翻译的热潮突然消失了,出现了空前萧条的局面。
不过,尽管在萧条时期,法国、日本、加拿大等国,仍然坚持着机器翻译研究,于是,在 70 年代初期,机器翻译又出现了复苏的局面。
(2)复苏期(1970年-1976年):
在这个复苏期,研究者们普遍认识到,原语和译语2种语言的差异,不仅只表现在词汇的不同上,而且,还表现在句法结构的不同上,为了得到可读性强的译文,必须在自动句法分析上多下功夫。
早在1957年,美国学者英格维(V. Yingve)在《句法翻译的框架》(Framework for SyntacticTranslation)一文中就指出,1个好的机器翻译系统,应该分别地对原语和译语都作出恰如其分的描写,这样的描写应该互不影响,相对独立。英格维主张,机器翻译可以分为3个阶段来进行。
第一阶段:用代码化的结构标志来表示原语文句的结构;
第二阶段:把原语的结构标志转换为译语的结构标志;
第三阶段:构成译语的输出文句。
英格维的这些主张,在这个时期广为传播,并被机器翻译系统的开发人员普遍接受,因此,这个时期的机器翻译系统几乎都把句法分析放在第一位,并且在句法分析方面取得了很大的成绩。
这个时期机器翻译的另1个特点是语法(grammar)与算法(algorithm)分开。
早在1957年,英格维就提出了把语法与“机制”(mechanism)分开的思想。英格维所说的“机制”,实质上就是算法。所谓语法与算法分开,就是要把语言分析和软件程序设计分开,程序设计工作者提出规则描述的方法,而语言学工作者使用这种方法来描述语言的规则。语法和算法分开,是机器翻译技术的1大进步,它非常有利于程序设计工作者与语言工作者的分工合作。
这个复苏期的机器翻译系统的典型代表是法国格勒诺布尔理科医科大学自动翻译中心(GETA)的机器翻译系统。这个自动翻译中心的主任沃古瓦(B.Vouquois)教授明确地提出,1个完整的机器翻译过程可以分为如下6个步骤:
(1)原语词法分析,(2)原语句法分析,(3)原语译语词汇转换,(4)原语译语结构转换,(5)译语句法生成,(6)译语词法生成。
其中,第一、第二步只与原语有关,第五、第6步只与译语有关,只有第三、第4步牵涉到原语和译语二者。这就是机器翻译中的“独立分析-独立生成-相关转换”的方法。他们用这种研制的俄法机器翻译系统,已经接近实用水平。
(3)繁荣期(1976年--现在)。
繁荣期的最重要的特点,是机器翻译研究走向了实用化,出现了1大批实用化的机器翻译系统,机器翻译软件产品开始进入市场,变成了商品,由机器翻译系统的实用化引起了机器翻译软件的商品化。
机器翻译的繁荣期是以1976年加拿大蒙特利尔大学与加拿大联邦政府翻译局联合开发的实用性机器翻译系统 TAUM-METEO正式提供天气预报服务为标志的。这个机器翻译系统投入实用之后,每小时可以翻译6万-30万个词,每天可以翻译1500-2000篇天气预报的资料,并能够通过电视、报纸立即公布。TAUM-METEO系统是机器翻译发展史上的1个里程碑,它标志着机器翻译由复苏走向了繁荣。
传统的机器翻译系统,按其翻译方式来分。可大致分为直译式、转换式和枢轴式3种类型。
1.直译式:把原语的词或句子直接替换成译语的词或句子,必要时对词序进行适当的调整。这种直译式广泛地应用于早期的机器翻译系统中。目前,仍然有不少系统采用直译式来进行机器翻译。1个极端的例子就是袖珍旅游翻译机,这种翻译机存贮着原语的常用句子及其相应的译语的译文,翻译时直接查出其对应物就可以。比较复杂的直译式是句法直译式、语义直译式。在直译时要进行词语的选择和词序的变换。
2.转换式:在原语和译语之间设定能在一定程序上表现语义关系的中间表达式,根据中间表达式所处平面的不同,又可分为句法转换式和语义转换式。句法转换式一般以树形图作为句法结构的中间表达式,语义转换式一般采用语义网络作为中间表达式。在采用语义转换式的机器翻译系统中,在表层结构上出现歧义的句子,在语义的中间表达式这一平面上不会再有歧义。因此转换规则的数目不多,这是其优点。但其缺点是为了得到这样的中间表达式,需要进行大量的分析和运算,而且由这样的中间表达式去生成译文也是十分困难的。
3.枢轴式:把语义转换式推到极限,用中间表达式来表示不依赖于任何具体语言的普遍意义,这种普遍意义就是枢轴。在枢轴式中,原语和译语之间不再需要进行什么转换,转换规则的数目减少到零,翻译的过程就是首先把原语的文句变为枢轴中的普遍意义,再由普遍意义生成译文。由于完全取消了转换规则,所以,原语的分析和译语的生成都比较复杂。
传统的机器翻译方法都是基于规则的机器翻译方法,由于分析技术的限制,大多数都以句法直译式和句法转换式为其主流。
除了传统的机器翻译方法之外,近年来还出现了基于经验的机器翻译方法。所谓“基于经验”,一是指基于统计,一是指基于实例。基于经验的机器翻译系统的研制,需要大规模真实语料库的支持。
1993年7月在日本神户召开的第四届机器翻译高层会议(MT Summit IV)上,英国著名学者哈钦斯(J.Hutchins)在他的特约报告中指出,自1989年以来,机器翻译的发展进入了1个新纪元。这个新纪元的重要标志是,在基于规则的技术中引入了语料库方法,其中包括统计方法,基于实例的方法,通过语料加工手段使语料库转化为语言知识库的方法,等等。这种建立在大规模真实文本处理基础上的机器翻译,是机器翻译研究史上的一场革命,它将会把自然语言的计算机处理推向1个崭新的阶段。
早在1949年,韦弗在他的备忘录中,就提出了使用统计学的办法来解决机器翻译问题,但是,由于当时尚缺乏高性能的计算机和联机语料,采用基于统计的机器翻译在技术上还不成熟。现在,这种局面已经大大改变了,计算机在速度和容量上多有了大幅度的提高,也有了大量的联机语料可供统计使用,因此,在90 年代,基于统计的机器翻译又兴盛起来。
基于统计的机器翻译把机器翻译问题看成是1个噪音信道问题,如图所示:
S → 噪音信道 → T
可以这样来看机器翻译:1种语言S由于经过了1个噪音信道而发生了扭曲变形,在信道的另一端呈现为另1种语言T,翻译问题实际上就是如何根据观察到的语言T,恢复最为可能的语言S。语言S是信道意义上的输入,在翻译意义上就是目标语言,语言T是信道意义上的输出,在翻译意义上就是源语言。从这种观点看来,1种语言中的任何1个句子都有可能是另外1种语言中的某几个句子的译文,只是这些句子的可能性各不相同,机器翻译就是要找出其中可能性最大的句子,也就是对所有可能的目标语言S计算出概率最大的1个作为源语言T的译文。由于S的数量巨大,可以采用栈式搜索(stacksearch)的方法。栈式搜索的主要数据结构是表结构,表结构中存放着当前最有希望的对应于T的S,算法不断循环,每次循环扩充一些最有希望的结果,直到表中包含1个得分明显高于其它结果的S时结束。栈式搜索不能保证得到最优的结果,它会导致错误的翻译,因而只是1种次优化算法。
基于统计的机器翻译进行概率计算时,采用隐马尔可夫模型(Hidden Markov Model,简称H美眉)。隐马尔可夫模型是马尔可夫模型的扩展。马尔可夫模型描述的是1个随机过程,而隐马尔可夫模型中有2个随机过程,1个随机过程描述观察值(例如,具体的单词)和状态(例如, 该单词可能标注的词类)之间的概率关系,即观察值是状态的概率函数,另1个随机过程描述状态之间(例如,词类标记与词类标记之间)的转移关系。作为外界的观察者来说,只能看到状态产生的观察值,而看不到状态之间的转移,状态之间的转移是隐藏的,所以叫做隐马尔可夫模型。近年来,利用隐马尔可夫模型在词性标注方面取得了较好的结果,从而推动了基于统计的机器翻译的研究。
基于实例的机器翻译的思想最早是由日本机器翻译专家长尾真(MakotoNagao)提出来的。他在1984年发表了《采用类比原则进行日-英机器翻译的1个框架》一文,探讨日本人初学英语时翻译句子的基本过程,长尾真认为,初学英语的日本人总是记住一些最基本的英语句子以及一些相对应的日语句子,他们要对比不同的英语句子和相对应的日语句子,并由此推论出句子的结构。参照这个学习过程,在机器翻译中,如果我们给出一些英语句子的实例以及相对应的日语句子,机器翻译系统来识别和比较这些实例及其译文的相似之处和相差之处,从而挑选出正确的译文。长尾真指出,人类并不通过做深层的语言学分析来进行翻译,人类的翻译过程是:首先把输入的句子正确地分解为一些短语碎片,接着把这些短语碎片翻译成其它语言的短语碎片,最后再把这些短语碎片构成完整的句子,每个短语碎片的翻译是通过类比的原则来实现的。因此,我们应该在计算机中存储一些实例,并建立由给定的句子找寻类似例句的机制,这是1种由实例引导推理的机器翻译方法,也就是基于实例的机器翻译方法。
在基于实例的机器翻译系统中,系统的主要知识源是双语对照的翻译实例库,实例库主要有2个字段,1个字段保存源语言句子,另1个字段保存与之对应的译文,每输入1个源语言的句子时,系统把这个句子同实例库中的源语言句子字段进行比较,找出与这个句子最为相似的句子,并模拟与这个句子相对应的译文,最后输出译文。
基于实例的机器翻译系统中,翻译知识以实例和义类词典的形式来表示,易于增加或删除,系统的维护简单易行,如果利用了较大的翻译实例库并进行精确的对比,有可能产生高质量译文,而且避免了基于规则的那些传统的机器翻译方法必须进行深层语言学分析的难点。在翻译策略上是很有吸引力的。
要进行基于实例的机器翻译需要研究如下问题:
第一,正确地进行双语自动对齐(alignment):在实例库中要能准确地由源语言例句找到相应的目标语言例句,在基于实例的机器翻译系统的具体实现中,不仅要求句子一级的对齐,而且还要求词汇一级甚至短语一级的对齐。
第二,建立有效的实例匹配检索机制:很多研究者认为,基于实例的机器翻译的潜力在于充分利用短语一级的实例碎片,也就是在短语一级进行对齐,但是,利用的实例碎片越小,碎片的边界越难于确定,歧义情况越多,从而导致翻译质量的下降,为此,要建立一套相似度准则(similaritymetric),以便确定2个句子或者短语碎片是否相似。
第三,根据检索到的实例生成与源语言句子相对应的译文:由于基于实例的机器翻译对源语言的分析比较粗,生成译文时往往缺乏必要的信息,为了提高译文生成的质量,可以考虑把基于实例的机器翻译与传统的基于规则的机器翻译方法结合起来,对源语言也进行一定深度的分析。
我国是继美国、苏联、英国之后,世界上第4个开展机器翻译研究工作的国家。当今在机器翻译方面居于先进水平的日本,是在1958年才开始进行机器翻译的,起步比我国为晚。
与国外机器翻译的发展情况相比较,我国机器翻译除了有草创期、复苏期和繁荣期之外,由于文化革命的影响,还有1个非常特别的时期--停滞期,而且,由于我国机器翻译在理论上和方法上以及设备上的底子都很薄,我国机器翻译的每1个时期又都比国外机器翻译的同样时期稍微滞后。
(1)草创期(1956年--1966年)
在这个时期,我国学者对机器翻译进行了初步的探索和试验。1956年,国家便把机器翻译研究列入了我国科学工作的发展规划,成为其中的1个课题,课题的名称是:“机器翻译、自然语言翻译规则的建立和自然语言的数学理论”。1957年,中国科学院语言研究所与计算技术研究所合作,开展俄汉机器翻译的研究。1959年,他们在我国制造的10四大型通用电子计算机上,进行了俄汉机器翻译试验,翻译了九个不同类型的、较为复杂的句子。在这个草创时期,北京外国语学院、北京俄语学院、广州华南工学院、哈尔滨工业大学也分别成立了机器翻译研究组,开展俄汉或英汉机器翻译的试验。
(2)停滞期(1966年--1975年)
在这个时期,除了极少数的机器翻译研究者在极端恶劣的条件下继续进行理论探索之外,没有进行任何的机器翻译研究和试验。
(3)复苏期(1975年--1987年)
在这个时期,我国机器翻译研究重振旗鼓,开始复苏,继续进行机器翻译研究。1975年11月,在中国科学技术情报研究所设立了1个由情报所、语言所和计算所等单位的工作人员组成的机器翻译协作研究组,以冶金题录5000条为试验材料,制定英汉机器翻译方案并上机试验。1978年5月,在计算所111机上进行抽样试验,抽样20条,达到了预期的效果。在这个时期,我国学者还开展了法汉、德汉、日汉以及汉-法/英/日/俄/德多语言机器翻译试验,取得了一定的成效。
(4)繁荣期(1987年--现在)
这个时期是以中国软件技术公司的“译星1号”机器翻译系统的问世为标志的。继“译星1号”之后,一系列的实用化商品化的机器翻译系统如雨后春笋般地推向市场,北京的“高立”系统、陕西的“朗威”系统、天津的“通译”系统、深圳的LIGHT系统都拥有了一定数量的用户,我国的机器翻译迈向了实用化和商品化的阶段,机器翻译软件从实验室走向了市场。在这个时期,我国也开展了基于实例的机器翻译研究,并取得了初步的成果。
谷歌最近开始4两种语言的自动翻译免费服务,是机器翻译发展史上的重大进展。
机器翻译是国际10大科技难题之一,由于自然语言是十分复杂和丰富的,不可能用电子计算机表达得淋漓尽致,因此,机器翻译与人工翻译总是会存在一定的差距。人类对于自然语言的认识是没有止境的,机器翻译软件的研究和探索也是没有止境的。
参考文献
1. W. J.Hutchens, latest Development in MT Technology: Beginning a New Erain MT Research. In : Proceedings of Machine Translation Summit-IV,Kobe, Japan, 1993.
2.冯志伟,自动翻译,上海知识出版社,1987年。
3.冯志伟,自然语言机器翻译新论,语文出版社,1994年。
4.冯志伟,自然语言的计算机处理,上海外语教育出版社,1996年。
三 : _机器翻译_还是_机器辅助翻译_对_机器翻译_之管见

第23卷第3期
2002年9月
大连理工大学学报(社会科学版)
JournalofDalianUniversityofTechnology(SocialSciences)
Vol.23,No.3.Sept
2002
“机器翻译”还是“机器辅助翻译”
——对“机器翻译”之管见
张治中, 俞可怀
(大连理工大学外语系,辽宁大连116024)
摘 要:“机器翻译”容易给人们造成错觉:似乎机器——计算机可以像人一样进行翻译活动。文章就机器能否像人一样地翻译这一问题进行探讨,试图通过对翻译活动的本质分析来揭示机器不能独立翻译,只能辅助人类的翻译活动。 关键词:人工翻译;机器翻译;语言学;结构主义;意义 中图分类号:H085
文献标识码:A
文章编号:10082407X(2002)0320054205
一、引 言
[]
“‘机器翻译’。器翻译’世纪40年代
[4]
。Systran“机器翻译”的定义:是利用语言结language)的语言结构转targetlanguage)的语言结构。“结构主义者认为在各种复杂的表面现象的下面都有着一种普遍性的规律,这些规律就是结构,人们通过分割归并作品的各种结构就可弄清语言信息变成文艺作品的奥
[4]秘”。
20世纪60年代,乔姆斯基的生成转换语法问世
“机器翻译”,大多数从事手工翻译人
士不以为然,他们根本就不相信翻译会机械化;少数人则或多或少有一点担心,害怕有一天机器会把他们取而代之[3]。这两种观点都是错误的。尽管“机器翻译”已经走过了半个多世纪,对它了解的人并不太多。对所谓的“机器翻译”,我们既不能全盘否定,也不应该全盘肯定。首先,“机器翻译”这一概念就不准确,这一提法也不科学,其次,机器是否能够独立“翻译”。
和计算机语言学研究的成功,使计算机科学得到迅猛
发展,机器翻译的研究开发人员从中获得鼓励和信心。
2.“机器翻译”的理论基础——结构主义受到挑战结构主义思想给人们带来了理性化的思维,破坏了原来“语文学”式的神秘性和主观直觉的研究方式,使人感觉到语言学研究有规律可循。翻译研究也摆脱了主观性而走向客观性分析的道路。但是由于结构主义翻译观只顾文本,忽视语境,与现实隔离,排除翻译主体性,使翻译研究走向了唯科学主义。
20世纪后半叶,结构主义受到了来自各种哲学思
二、对“机器翻译”概念的质疑
1.“机器翻译”是结构主义的产物
“机器翻译”的想法产生正是结构主义语言学的观点盛行时期。随着人类对语言结构规律的研究发现,语言学家认为以此他们为翻译找到了理论依据,从而给翻译加上了科学主义的色彩。奈达、巴尔胡达罗夫以及彼得?纽马克等人的翻译观都是从结构主义理论开始的。“结构主义把文学作品当作一种符号体系来研究,
潮的挑战,如现象学、解释哲学、解构主义等等。在文学
批评上德?曼是解构主义代表性人物,提出了“没有文本具有确定的意义”,否定了结构主义的翻译理论基础。胡塞尔的意向性理论认为符号本无意义,是人们通过意向性行为才使得符号产生意义,意义是在人的意
收稿日期:2002201203
作者简介:张治中(19582),男,汉族,吉林九台人,大连理工大学外语系讲师,主要从事英汉语言比较与翻译研究;俞可怀(19422),男,汉族,
江苏江宁人,大连理工大学外语系教授,硕士生导师,主要从事英汉翻译理论与实践研究。
? 1994-2010 China Academic Journal Electronic Publishing House. All rights reserved. http://www.61k.com

第3期
张治中,俞可怀:“机器翻译”还是“机器辅助翻译”
4.翻译是一种复杂的心理活动
?55?
向活动中显示自身的。现象学认为现实世界是当然存
在的,但在本质上只与先验主观性相关联,所以先验自我才是意向活动的基础,意向活动、意向对象之间的关系是一种构造关系,即“赋予意义”。他把“人”这一主体概念引进了结构主义语言学的那个封闭的符号系统[4]。
70年代出现、80年代形成的认知语言学认为:人
《翻译的艺术》HerbertCushingTolman在他的
(ArtofTranslation)一书中说:“翻译的心理过程由两部分组成:第一,我们必须掌握原文作者的思想;第二,我们必须用译文的语言把原文作者的思想表达出
[8]来”。翻译是一种心理活动,一种思维加工活动。翻译者需要利用自己固有知识和体验对文本内容分析加工,获取意义,然后再用符合译文语言习惯的语言表达出来。
孙致礼在谈到文学翻译的科学性时说:“翻译首先
在形成有意义的概念及进行推理的过程中,人类的生理结构、身体经验以及人类丰富的想象力发挥了重要的作用;任何语言形式本身没有意义,它们只作为线索激活我们脑中已经存在的意义——身体经验,并依据自身体验而有意义[5]。
由此可见,仅靠文本分析,忽略现实,没有“人”这一主体参与的“机器翻译”,是站不住脚的。
3.翻译是以人为主体的跨语际交际活动
要解决一个精确理解的问题,而要做到这一点,译者必
须具有十分扎实的外语基础,必须具备一定的语言学、语法学、语义学、修辞学、文体学等方面的知识,否则,‘精确的理解’就会变成一句空话,翻译就会带有很大的盲目性。另外,一个译者还要熟知原文语言和译文语言之间的差异;惟有如此,,,译出读者喜闻乐[9]
《当代翻译理论》中写道,“翻译,是双语间意义的对应转换。这里所说的‘意义’,包括概念意义(conceptivemeaning)、语境意义(contextualmeaning)、形式意义(formmeaning)、风格意义(stylisticmeaning)、形象意义(figurative。“翻译meaning)和文化意义(culturalmeaning)……”涉及的是从形式到内容、从语音到语义、从达意到传
[10]
情、从语言到文化的多层次、多方位语际转换。”要完成这样复杂的任务,尚不能像人一样思维的机器是不可能的。我们可以在翻译系统的程序中输入相关的知识,但是我们人类无法保证机器会使用这些知识进行有目的的思维加工以获取原文的“意义”,即理解原
根据WolframWilss的观点,翻译是一种语言交
际活动,是一项跨语际交际活动。能胜任这一活动的主体只能是人。“交际活动只发生在人类社会群体中,是以其社会环境和知识为基础的。类交际活动,,靠精确的逻辑,,可能是劝说,可
[3]能是威胁,,也可能是奉承。”
翻译是两种权力话语作用下的产物。文本不是存在于真空中,文本的作者不可避免的要受其生存环境下的政治、文化影响。文本中注定要渗入源语政治、文化、传统、道德理念、风俗,当然,这些都是作者潜意识使然。译者同样在翻译过程中在译文中渗入目的语文化。根据弗雷德里克?詹姆逊的观点,任何一种翻译活动都是根据译语文化的需要对原作的一种重写和同化。与此同时,翻译活动自始至终受翻译活动本身的目的所左右。
德国的功能学派认为,翻译活动是有目的的行为。其奠基人汉斯?施密尔还特别强调:“因为发生的环境置于某一文化背景之中,不同的文化又具有不同的风俗习惯和价值观,因此,翻译也非一对一的语言转换活
[6]动。”“翻译似乎很容易是由于对以下两点的认识错
文,无法正确表达出原文的意义、功能、风格。既然无法
真正理解原文,那么,“机器翻译”的结构主义起码的“科学色彩”也无从谈起。
机器不能理解原文,它能做的只是机械的转码,“因为一个翻译需要以下三方面的知识:独立于上下文的语言知识,即语义学知识、与上下文相关的语言知识,即语用学知识和普通常识??世界知识,即非语言知识”。
¨
早在1949年,J.E.Holmstrom听说研究人员在研究机器翻译的可行性时说道:“机器翻译的文学风格将非常可怕,将会出现比人工翻译时更愚蠢可笑的错误”,因为“翻译是艺术。在翻译过程中每一步都要求人在两个辞典中没有条文规范的选项中做出选择;不是
误造成的:一、翻译不仅仅是语言层面的操作活动;二、
[7]翻译不仅仅是保留原意的操作活动”。翻译是一种为
了某种目的的文化构建。由此可见,人的目的取向和主观能动性不可忽略,舍此便没有理解,更不能有令人满意的翻译文本。
? 1994-2010 China Academic Journal Electronic Publishing House. All rights reserved. http://www.61k.com

?56?
大连理工大学学报(社会科学版) 第23卷
可换算符号的直接的简单替换,而是译者根据自己的人格和他受到的全部教育素养所做出的价值选择”。当
¨
时,J.E.Holmstrom做这番评论是在第一台翻译机器展示的五年前的事。但是,后来,类似的评论反复出现。“将来还会出现”,JohnHutchins说。有人会提出,“机器翻译”的对象是科技文体,不是文学作品。事实上,无论哪一种文体都蕴含着孕育它的文化的痕迹,都反映其民族思维特点[11]。认知语言学认为“隐语在我们的生活中到处可见”,科技文体也不例外。隐语就是文学语言手法。可见,科技文体中也存在某些文学语言的表达形式,也透着载体语言的文化气息。此外,各种文体在翻译过程中,从理解到表达的思维过程都是相似的。
在过去的50多年里,“机器翻译”做了很多尝试,可是,词与句子的“歧义”问题至今尚未解决。“导致‘机器翻译’研究的困难很多,包括一词多意,歧义结构和
[6]
其他语法问题”。翻译活动中涉及到两种不同语言的表达形式,在翻译过程中需要像归纳、演绎这样的思维加工的能力。下面就选了一段说明文体(体)用Systran翻译系统进行了:原文:Collocatithat“fittogether”;i.elepatternsandphrasesorgroupsofordsthatwetypicallyuseto2gether.Theyincludewhathavetraditionallybeenconsideredvocabularyitems,aswellasstructuralpatternswhichmayseemclosertotraditionalgram2marandcombinationsofwordsthatsimply“goto2.gether”
所载的信息,根本不能称之为“翻译”,仅仅是“转码”而已。
计算机人性化目前尚不可能实现,虽然研究开发人员试图让计算机学会记忆、具备学习功能,但目前其进展速度十分有限。即使计算机已经学会记忆并具备学习功能——有些辅助翻译软件具备简单的学习记忆
功能(例如,我国北京实达的“雅信”翻译软件),但是仍然无法突破不会思维的障碍,不可能翻译出与人工翻译相媲美的译文来。况且它学习、记忆的步伐要永远落后于时代,机器对于刚出现的,或者特殊的表达形式根本就不会处理,根本不会“翻译”。要获得地道的完整的译文必须要经过人工修改、加工。
三、机器只能辅助翻译,
不能独立翻译
到了世纪的研究进入了,“机器翻译”,a机器翻译(machinetranslation):全部翻译由机器完成,但是其结果必须经人工修订;(b)辅助手段(computeraidsfortranslators):翻译活动由人工进行,机器翻译只是作为人们翻译时使用的辅助工具;(3)非翻译人员为获取梗概大意偶尔使用的机器翻译系统(translationsystemsforthe“occasional”non2
[3]
translatoruser)。
“机器翻译”的提法不JohnHutchins等人提出了
合适,应该是机器辅助翻译。“机器翻译”给人造成很多误解,使人对其产生过高的期望值,因为“翻译”一词会给人以错觉,以为机器可以像人一样进行翻译操作。“在公众看来,翻译就意味着与原文的内容风格接近的译文,就应该和人工翻译得一样好,没有区别;否则不
[3]
能叫翻译。”“机器翻译”应该改为机器辅助翻译。这
机译:搭配是一起适合的词的收集;即他们是可预
言的模式和我们典型使用的短语或者多组词一起.他们包含什么已经传统地被把看作以及结构上模式,其可以似乎是更接近简单和谐的词的传统语法和结合的词汇项目.
人译:搭配是像“fittogether”这样的词的组合,即一种固定形式,可预见的、常常一起使用的词组,包括传统上我们称之为词项的词语、看上去与传统语法关系密切的句型结构、以及仅仅是一起使用的一些词的组合。
“翻译”出的句子不通顺,不符合文Systran系统所
法,不具备可读性。这个系统连断句都出现了错误。由此可见,Systran系统不具备分析结构、断句、辨析词义、选择词语、组成合乎语法的句子的思维加工能力。该系统既没有正确“理解”原文,也没能“表达”出原文
符合计算机作为人类辅助工具的属性。
计算机科学的发展和计算机语言学的发展,使人们对计算机在辅助翻译方面抱有很大希望。从上面列举Systran系统翻译的例子我们可以看出,词的这一层次的转换准确率高达95%以上。如果作为辅助翻译,该系统是很有效的。值得注意的是,人与计算机在处理要翻译的材料时的速度差别甚大。以Systran翻译系统为例,它每秒可处理3700字,而人工翻译每天只能翻译2000-3000字。由于互联网发展神速,要翻译的多种语言的信息,远远超过人工翻译的承受能力。
? 1994-2010 China Academic Journal Electronic Publishing House. All rights reserved. http://www.61k.com

第3期
张治中,俞可怀:“机器翻译”还是“机器辅助翻译”
?57?
因此,计算机辅助翻译研究的大学和开发机构一直在
探索着,试图开发出实用的、能满足需要的翻译软件。
计算机辅助翻译研究人士认为,“机器翻译”与人工翻译并不矛盾,“机器翻译”和人工翻译都需要,要根据所要翻译的材料而定。他们认为,翻译可分为三种情况:即目的是为传播的翻译;目的是为了接受、吸收文字所载信息的翻译;面对面的口译。第一种翻译的最终译本需要有符合出版要求的质量,必须由人工翻译。第二种翻译是应付信息爆炸时代的无奈之举,是为了收集信息的目的所提供的短命的、暂时性的文献,译文不需要校对,这种翻译是机器进行的,是转码。而第三种则是现场翻译,只有口译员才能胜任,机器是不可能的。
现在来讨论一下第二种翻译,看一看机器处理过的信息是否具备基本的可读性。这是一篇外贸信函选段,使用的机器翻译软件是最新的东方快车XP迷你版翻译软件。
原文:Weconfirmyourfaxof2ndJulyaskingustomakeyoufirmofferforWalnutmeat.
Wewouldinformyouehaveatpresent.,ifyoushouldmakelebid,thereisthepossibilityofyourthese.
As,nodoubt,youareawareoflatetherehasbeenalargedemandforwalnutmeat,andsuchagrowingdemandcanonlyresultinincreasedprices.However,youmayavailyourselvesoftheadvantageofthisstrengtheningmarketifyouwillsendusanimmediatereply.
日增必将导致提价。如果你方立即答复,就可抓住行市
[12]
上涨的机会。
以上机译部分不能称之为译文,原因是它读起来根本不成文。但是,我们承认,从译文中我们可以猜测出50%以上的信息。看来,作为收集那些只需梗概大意的信息时这种“机器翻译”也许是可以使用的。目前,网上信息收集处理多数都使用这种处理手段。
计算机用于翻译,多数情况下作为辅助手段,或者通过控制翻译材料,或者控制原文使用的语言,或者在机器处理后再由人工修改、校定,以确保翻译质量;或者是人机互动式翻译,计算机自动给出可能用得到的词义选项,或句子结构选项供人选择,人机共同完成翻译任务。
四、结 论
诚然,,那么。计算机能,,能否像人一,似乎计算机能像人一样会思维、会翻译的日子不会太远了。其实这是不可能的。就像大猩猩和其他动物无法学会说话一样,计算机也不可能学会像人一样思维,不会取代人,相反它将永远是人类的工具。原因十分简单,计算机没有思维的机制——人脑。
作为辅助工具,计算机有美好的发展前景。作为辅助翻译的计算机软件,无论是机器辅助人的翻译软件(MAHT——MachineAidedHumanTranslation,近来我们称之为CAT——ComputerAidedTranslation),还是人辅助机器的翻译软件(HAMT——HumanAidedMachineTranslation),都有很好的前景。但是,现在的问题是翻译界人士对机器辅助翻译这门翻译学和计算机语言学交叉学科并不重视,投身英汉、汉英机器辅助翻译的研究开发的翻译专业人士寥寥无几。如果只凭少数计算机语言学家的努力,没有翻译理论家和翻译家的参与,是不可能开发出高质量的翻译软件的。机器翻译研究必须立足于翻译理论研究的基础上,只有翻译家、翻译理论家和计算机语言学学者携起手来,才能把计算机辅助翻译及计算机辅助翻译软件的开发研究推向一个新的高度。参考文献:
机译:我们证实你的要求我们为walnutmeat使你成为实盘的7月2日的传真。我们将通知你我们目前有的很少包裹其它地方在提议下面。然而,如果你应该使我们成为一个可接受的出价,有你获得这些的可能性。
作为,没有疑问,你是知道的近来是为walnut2meat的一个大要求在那里,并且如此的一成长要求能
仅仅导致增加的价格。然而,你可以有利你们自己如果你将送我们一个立即的答复,这加强的优点出售。
人译:现确认你方7月2日来电要求我方报核桃仁实盘,并奉告贵公司我们仅有的几批货已报给别人。但是,如果你们的递盘我们可以接受的话,你们有可能得到这些货。
你们一定了解,近来对核桃仁有大量需求,而需求
[1]MARIEKEN.TheSoldiersareintheCoffee—AnIntro2
? 1994-2010 China Academic Journal Electronic Publishing House. All rights reserved. http://www.61k.com

?58?
大连理工大学学报(社会科学版) 第23卷
??ductiontoMachineTranslation[EB??OL].
[8]许钧,郭建中.当代美国翻译理论[M].武汉:湖北教育出
??,
200129211??20022725.
[3]JOHNH.MachineTranslationandhumantranslation:in
版社,2000.3212.
[9]孙致礼.翻译:理论与实践探索[M].南京:译林出版社,
1999.526.
[10]刘宓庆.当代翻译理论[M].北京:中国对外翻译出版社,
1999.41248.
[11]SUSANB,ANDRéL.ConstructingCultures—Essayon
LiteraryTranslation[M].上海:上海外语教育出版,1988.
[12]葛振霖.外贸英文书信课文译文和练习答案:第二版
[M].北京:对外经济贸易大学出版社,2000.24.
??competitionorincomplementation?[EB??OL],2001212??
[4]吕俊.跨越文化障碍——巴比塔的重建[M].南京:东南大
学出版社,2001.51252,962111.
[5]IRAIDEIBARRE—A.What’scognitivelinguistics?A
NewFrameworkfortheStudyofBasque[EB??OL].
??http:??ibs.lgu.ac.uk??sympo??IBS-2000.PDF,2000??
20022622.
[6]CHRISTIANEN.TranslationasaPurposefulActivity—
Machinetranslationor-—OurviewonYUKe2huai
(gesDepartment,DalianUniversityofTechnology,Dalian116024,China)
Abstract:Machinetranslation,atermwhichhasbeenappliedtotheprocessoftranslationfromonelanguagetoanothersinceitsbirth,isquitemisleading.
Forthegeneralpublic,machinetranslationimplies“close”
translation(faithfultothecontentandstyleoftheoriginal),indistinguishablefromthetranslationversionbyacompetenthumantranslator.Thispaper,byexaminingthenatureandtheprocessoftranslation,tendstotellthereadersthatthemechine—acomputer—cannotachievetheleveloftranslationcomparedwiththelevelofhumantranslator,itcanonlyserveasanaidtohumantranslation.
Keywords:machinetranslation;humantranslation;linguistics;structuralism;meaning
? 1994-2010 China Academic Journal Electronic Publishing House. All rights reserved. http://www.61k.com
本文标题:机器辅助翻译实验室-QQ实验室新作QQ慧眼新鲜体验 即时翻译61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1