一 : 百度搜索异常 搜索任意关键词均现链家地产推广
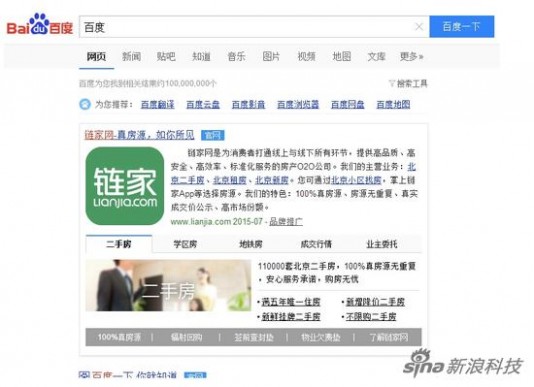
百度搜索出现异常
新浪科技讯 7月13日消息,今日下午百度搜索出现异常,搜索任意关键词,均出现链家地产的品牌推广专区。
百度方面回应表示,这是系统方面出现的BUG,将在5分钟内修复。
目前搜索已恢复正常。
二 : 从百度搜索关键词到相关公司打来推销电话,隐私信息
[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?网友蒙面大侠对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
估计是品友类型的公司,叫RTB,实时广告。百度搜索了,你的cookie或用户名触发到营销公司,营销公司结合购买的资料,合法或非法的,
形成一个星型的数据模型(就是以某个用户名或cookie或网卡序列号为中心,填充该用户到过什么网站,使用什么资料,以及买过了的线下资料的数据库),恰好你的手机号码在某个网站或原来的历史资料注册过,
例如,很多wap网站可以获取手机号码
马上通过中间平台实时通知平安,一个用户卖几十块。
所以马上给你推送广告
网友石晓杰对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
我的第一个回答,感谢!
---------------------------正文-------------------
本人医疗营销行业,和这个差不多,我们也有用到这个技术!
可以肯定的说,不是百度的问题,而是你访问网站的问题.
现在的程序可以获取到网站访客的QQ(如果你是pc用户),和获取到网站访客的电话号码(如果你是用的手机访问的)
我们现在用的是第一种实时的获取访客的访问信息(是实时的监控你的动向哦.),包括:
1、访客所在地
2、当前在访问那个页面
3、ip地址,浏览器版本,分辨率,系统等
4、历史轨迹(以前是否访问过,访问的那些页面)
5、来源(访客是百度搜索进来的还是直接输入URL进来的,如果是搜索进来的,搜索的关键词是什么)
6、等等很多你想想不到的信息
下面是截图:

注:上图获取的只是基本信息,并不会获取你的QQ或者电话号码,当然这个也是可以获取的,你需要付费买这个功能.
还有一种就是可以获取到网站访客的电话号码,或者QQ号的: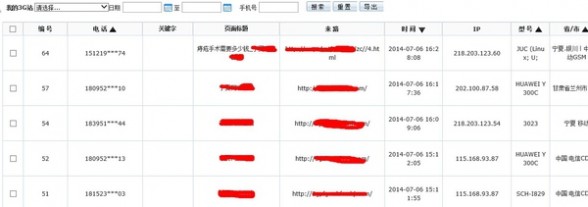
注:本人属于测试用户,并不是付费版,所以电话号码显示不全。 获取QQ的同理....
你访问了网站,对方获取了你的信息,如果你和他们有了合作,那就没事了,如果没有合作,那你就等着他们电话+QQ的找你吧!
这样回答的是否清楚呢?
补充:获取到QQ号码和电话号码的几率一般在40%左右,市场上面有很多这样的产品,不过一般不了解的都找不到,能获取到QQ和电话并不是说他们有后门,恰恰相反,QQ一直在防止用户隐私泄露,所以导致我们使用的这种产品也经常更新,有时候QQ更新了会出现获取不到QQ号码的情况,所以一般这种产品我们也经常换着用,那个好用就用那个.
网友sky对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
背景介绍:
平安是百度战略合作伙伴(2013年5月双发达成了jbp(joint business plan,联合发展计划)战略合作协议),平安每年在百度的投放金额超过绝大多数电商网站,百度任何最新的营销技术和平台都会优先由平安尝试。去年,百度也加入了火热的RTB(广告实时竞价)市场,依靠百度NB的技术实力推出了自己的百度BES平台。
具体解释:
前面也有朋友谈到了RTB,这种广告模式包含如下几个参与方(详见:在广告投放的RTB 「实时竞价」领域内,AdExchange、DSP、SSP、DMP 是什么意思?):
实时竞价广告交易平台(Ad Exchange):广告交易所
需求方平台(DSP):广告提供方,代表广告主,需求做广告的人
供给方平台(SSP):流量提供方,代表媒体,生产、售卖流量的人
数据管理平台(DMP):给访问广告的人打标记标签的人
平安加入的是DSP,他有做广告的需求。题主可能上过的一些娱乐网站,游戏网站,在线小说网站加入的是SSP,他们可以通过RTB广告将流量变现。而题主在加入RTB广告平台网站上的浏览行为及个性特征(例如因注册所暴露的电话号码、搜索特征、电商网站浏览的产品)会被DMP进行记录,形成 @池静若 提到的用户模型。
举个例子来看( @者也 说到的就是这个例子) :
?场景:
?1、小明逛京东想给小丽买副皮手套,收藏后没下单,想等活动促销;
?2、第三天小明去网易看新闻,看到收藏的京东皮手套广告,看没降价也没下单;
?3、第五天小明去网易看新闻,又出现京东皮手套广告,发现降价果断下单。
?背后:
?1、网易加入了Google的SSP平台,京东加入Google的DSP平台,京东告诉Google:“小明来我这了,记下来” ;
?2、Google告诉京东说:“小明去网易看新闻了,在页面的右边有俩广告位,尺寸是多少,在第几屏,买吗?” 同时,还告诉了当当,谁价高给谁;
?3、京东跟Google说:“我要买,我出价多少,我想展示皮手套广告,广告图片和链接如下”。
?4、Google经过比较,京东比当当出价高,小明点开网易后,发现了京东皮手套广告。
换到题主这里,题主搜索”平安保险“相关关键词,一方面,百度SEM系统(关键词搜索广告)会在搜索列表中呈现包含平安广告在内的保险广告+自然搜索结果;另一方面,百度RTB系统会像前面例子中google呼喊京东、当当那样,问各家(或某家)保险公司有没有开发这个潜在客户的兴趣,平安竞价后,客户浏览百度知道或其他平台时可呈现平安的广告,当然,客户的特征(通常不仅包含百度上的搜索特征,还包括加入RTB的数以万计网站的浏览特征。强调这点,是因为客户的电话号码也可能是在其他游戏、小说网站暴露,甚至在平安网站计算车险价格时暴露,而平安的广告分析系统在与DMP客户分析对接时,可以识别这个客户)平安也可能拿到。拿到后,是打电话还是推网络广告,就取决于广告主了。
最后,题主的个人信息和浏览行为在多大的程度上会被广告主所利用和获取,取决于RTB广告系统中各参与方的“开放程度”,或者说是节操(中国互联网基本还处于裸奔的原始阶段,距离树叶遮体还有距离,远谈不上隐私保护),当然也包括广告主。
技术上,精准广告可以做到无限精准,虽然现在还有很多地方需要提高。但另一方面,像题主这种联系方式被“网络共享”的例子,再包括腾讯的朋友圈推荐,QQ群推荐之类的功能在用户隐私保护上是不是应该重新思考一下?
如果不想让广告主太“了解”我们,可以在浏览器上禁用所有cookie,但毕竟不太方便。而对于不想让360之类的客户端工具太“了解”我们,只能选择卸载。
易用性和隐私保护,某种程度上是一对矛盾,需要反复慎重权衡,当前国内互联网环境下,有些过了。
注:本人在技术解释上不够专业,仅就个人所知说个大概,不准确和不正确的地方请指正。
网友vczh对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
为什么只是稍微google了几次美帝藤校,隔天就有留学机构的咨询电话? - 网络安全
我觉得只要把这个答案里面的google换成baidu就可以获得真实的答案了。
网友匿名用户对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
好歹你是搜的车险,这哥们搜的是「早泄怎么办」。
这张图在微博最开始转得很火,但是貌似百度大大做了公关,全都删光了。
我转过来给大家看看吧。
 另外,我已经试过搜「早泄怎么办」这个关键词了,目前还没有声音甜美的小姐打电话过来。另外,我已经试过搜「早泄怎么办」这个关键词了,目前还没有声音甜美的小姐打电话过来。
另外,我已经试过搜「早泄怎么办」这个关键词了,目前还没有声音甜美的小姐打电话过来。另外,我已经试过搜「早泄怎么办」这个关键词了,目前还没有声音甜美的小姐打电话过来。
泪。
网友刘煜晨对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
没错,泄露你的隐私。
你的手机号码,属于线下数据。你在网上的搜索行为,浏览历史,属于线上数据。前者属于实名数据,后者属于匿名数据。通常来说,如果做互联网的精准营销,匿名数据是不能直接匹配实名数据做营销,线上匿名数据只能以群组划分的方式在线上进行精准投放,比如你的ip和cookie有保险相关数据,那么广告商将你划入某类精准用户组,给你推送保险相关广告 - 这是合乎隐私保护规范的,整个流程中不涉及实名数据。而题主的情况,线上的活动被监测,并且数据被匹配至线下实名信息,这是侵犯了您的隐私。
网友shady yu对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
前几天搜索一个程序员培训,然后就有各种企业号码加我聊天给我推荐培训课程。
网友atearsan对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
这种事情很无奈!
我想知道怎么避免?
ps,由于Google被墙,默认搜索引擎是bing。很少用百度,所以目前没发生这情况…
但是之前被朋友升级网盘绑定了手机号,觉得好坑!
顺便分享一个技巧,小网站注册账号,使用专门用来注册账号的邮箱,这样避免邮箱泄漏带来无尽的广告!
曾经csdn泄漏密码和邮箱让我从此再不使用csdn。fuck!
网友VV酱对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
解决这个问题很麻烦,我对这方面要求非常严格,所以从未被骚扰过。但是这个问题是由于网站之间串用历史记录导致的,普通用户不可能在[不损失方便]的情况下保护安全。
普通用户可以做的简单的办法:
1,使用Chrome浏览器,在设置里禁止“第三方Cookies”。这个操作可以在桌面版和手机版同样设置。对于外国网站,这一招基本有效,另外可以打开“请勿跟踪”项目。但对于国内网站用处不大,因为网站会从后台直接卖掉这些记录。
2,能在网页操作,就不要在App中搜索!建议使用苹果手机,苹果手机隐私保护要求很严。国产安卓系统本身就卖,没办法。不要安装百度搜索等App,因为App可以获得手机识别号(苹果手机不允许),所有记录以后直接关联识别Id,你换电话都跑不了。
3,定时删除所有浏览记录(并清除广告标识符,苹果),可以用日历提醒自己做这件事。
4,使用亲心小号等服务注册各类国产应用、国产服务,防止手机号泄露。
高级用户:
1,不在敏感系统(所有微软系统)中使用敏感信息,不使用管理员操作计算机。不安装国产软件(包括输入法),如必须使用,通过虚拟机。
2,浏览器缓存置入内存,每次从内存启动浏览器(RAMDISK-Cache) 断电后会消除全部记录。
3,专号专用,随机用户名/密码 确保账号间不产生可分析的关联 。手机号采用一次性注册码工具,一次性邮箱工具(mailinator一类)
4,管理登陆地点,不在本地使用某些服务时,使用VPN连回本地,防止服务器知道你的真实位置(3G的Ip是手机归属地,和你具体在哪没关系,但要禁用基站定位和GPS)
5,不随意混用设备,不在使用不明VPN时登陆账号……
PS.增加一点:
网络安全是个很深的问题,原则上说,比你高一级的网络对你就有绝对权限。这句话的意思是,你在你家的路由器上就可以模拟G/F/W,在你家的路由器上所能看到的东西和国家能看到的东西是一样的。
所以你在公司上知乎,原则上说公司是可以看到的,在公司里上网,你在百度里搜了什么,公司也能看到。
关于如何加密,混淆,安全上网,可以去“编程随想”的博客里学习(需科学上网)
网友蒙面大侠对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
看张截图: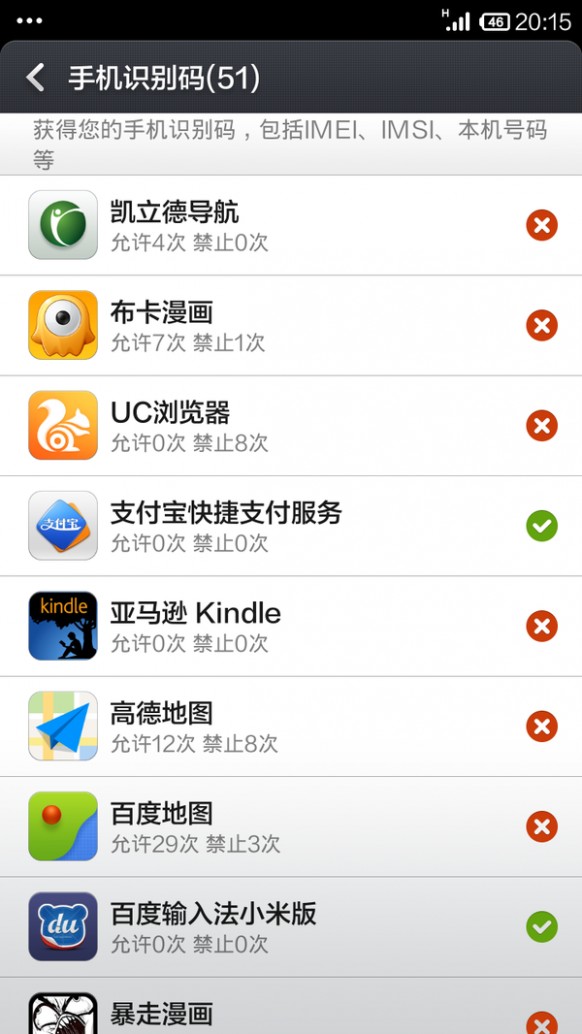
几乎所有程序都去要你的私人信息,包括网页也可以通过浏览器获得你的地理位置等信息,大多数人的隐私连白菜都不如
后来我索性不再纠结了,因为连有关部门的系统都在泄露个人隐私,完全不当回事
然后我也不再纠结一定要用iphone或者功能机,Android随便用,方便就行
补充:
没说明白,举个途径:你用过Baidu的app,那么Baidu就知道你的ip和手机甚至位置了,然后你用Baidu搜索关键字,通过你的ip,以及你手机上开着的百度后台服务(得到你当前ip),就可以大约找到相关的一些电话(包括你的),最后推送到营销公司,他们给你(以及其他一些人)打电话推销
网友匿名用户对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
匿了
前面回答的都不靠谱,你用上网搜索,然后你收到推销电话,百度怎么可能通过你上网来知道你的电话号码?这都可能,那随便一个站点,都能知道来访者的电话了?还有比这更泄漏隐私的么?goog?le的chrome至少不会这么坑爹,泄漏号码吧?
这中间必须有运营商参与,才可能做到,只有运营商,才能知道每个网络流量的访问,固话、宽带或者直接是手机浏览的,来自哪个电话。
百度并未跟哪个运营商达成这种合作(明面上,私下里我也不知道),体验很惊悚,估计运营商也没跟百度商量好。我也遇到过,搜索某种贵重的药材之后。
至于为什么是百度而不是其它网站,显然也是看上百度的用户搜索都代表了某种需求意愿,但百度没有自己的电商环(京东、淘宝等),正适合切入,这个跟360浏览器在百度搜索结果右边挂自己广告的行为,没啥两样
网友曾毅对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
我觉得答案很多,但都没有回答题主的问题。我就简单答复题主吧.
这个是什么?
根据题主描述,可以判断这个服务90%是百度基于账号体系下的广告营销服务。具体代号是什么不知道。
ps.不知道现在有没有划到百度BES(广告交易服务),因为这个东西侵犯隐私很明显。
为什么会产生?
产生这种一般需要精准的定位用户,题主已经声明他登录状态。你使用的任何百度service(尤其无线)提交的信息都会计入这个ID名下,估计在什么地方填手机号码,发过短信什么的,搜索过什么。所以可以精准定位到题主,具体使用过什么自己想了。
目前来说单纯的COOKIE根本无法精准定位用户的,就国内几家大的客户端厂商还有些能力。
如何防止?
只能告诉你防不胜防,看各厂商底线。百度如果售卖这个业务了,我觉得可以告他,现在都是遵守匿名采集,敏感信息不能透露给第三方。
附录:
百度隐私权保护声明:百度隐私权保护声明
网友蒙面大侠对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
百度尊重并保护所有使用百度用户的个人隐私权,您注册的用户名、电子邮件地址等个人资料,非经您亲自许可或根据相关法律、法规的强制性规定,百度不会主动地泄露给第三方。百度提醒您:您在使用搜索引擎时输入的关键字将不被认为是您的个人隐私资料。应该是你搜索百度的cookie被其他网站、软件利用了。至于怎么从cookie到平安业务员那里,就属于黑色产业链了。
网友wen wen对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
第三方追踪可以跨网站追踪你的历史行为。搜集你在多个网站的行为信息,浏览历史。国外对这方面的防御工作做了很多年,但是与广告商的利益冲突等问题,一直都没发展起来。目前,根本防御是不可能的。美国和欧盟都制定了相关的政策,不过其实也没啥用。你可以利用浏览器插件,比如donottrack,Ghostery ,利用黑名单进行防御的,实际上防御的数量也很有限。再就是,定期删除cookie和 flashcookie。都会起到一定效果。
第三方追踪其实分很多种类,我们常见的是广告类的,行为广告定制。还有分析类的,比如google analysis。还有社交网站类的,比如点赞,分享这些的。
真正的有效的防御,必须从政策上来解决,否则的话都白费。正在研究这方面的防御工作,希望会有好的结果。
再就是,当你用搜索引擎来进行搜索的时候,你的查询记录都会记在人家的服务器上,再通过cookie或者指纹识别技术,很容易知道你到底是谁,你所有的搜索记录,你在嵌入百度代码的网站上的浏览记录什么的。通过爬取网站分析,我发现百度,淘宝的第三方代码在中国网站的页面中存在很多。
网友蒙面大侠对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
请勿跟踪不是强制的,比如Google就不遵守,建议使用chrome插件ghostery,干掉一切跟踪器
google遵守了 他的广告业务怎么搞?
另外楼上的办法 很不错,但是我还是不相信百度
如果你搜索的时候禁用Cookie,并且不登陆百度账号(因为百度账号大都绑定有手机号)应该再也不会接到骚扰电话了吧!!
网友匿名用户对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
我知道一种软件叫增值宝,有幸亲眼目睹,首先你登QQ在电脑上访问该网页,网页后台和客服端显示你在某某页面停留多少秒,你的QQ号是多少。然后你用手机登录,网站后台和网站客服端显示你的手机号,哪个地方的和是移动还是联通啥,查看了什么项目网页,停顿多少秒
网友蒙面大侠对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
现在个人的信息根本就完全比猪肉还便宜
举个例子
我买了一套房 交了契税 结果装修的公司就开始各种电话轰炸 卖家具的 等等。
两种情况。1售楼部,我问了售楼部 售楼部的置业顾问发毒誓说不是自己
那么我可以怀疑房管局的人么?
网友王鹏飞对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
最常见的就是利用QQ快捷登录功能获取客户在线的QQ号,利用手机流量获取客户手机号码。
网友张亮-echo对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
如果是百度注册用户,并且自己资料里写了手机号,那么百度服务器可以得到搜索行为和手机号。
如果不登录直接用百度,百度服务器是获取不到手机号的,百度得到的包里都是ip化的信息。倒是运营商有数据,上网搜索url记录和手机号都有。
但是运营商不会把这些数据给外部合作伙伴。这种行为不管是百度还是运营商肯定侵犯隐私了。
网友howar对[百度泄露个人信息]从百度搜索关键词到相关公司打来推销电话,隐私信息是怎么被泄漏的?给出的答复:
哈哈哈,亲测果然是
三 : 基于本体的深度搜索系统关键词库的构造与研究
独创性声明
本人声明所呈交的学位论文是本人在导师指导下进行的研究工作及取得的研究成果。[www.61k.com]据我所知,除了文中特别加以标注和致谢的地方外,论文中不包含其他人已经发表或撰写过的研究成果,也不包含为获得或其他教育机构的学位或证书而使用过的材料。与我一同工作的同志对本研究所做的任何贡献均已在论文中作了明确的说明并表示谢意。
学位论文作者签名:秣签字日期:少77年6月弓日
学位论文版权使用授权书
本学位论文作者完全了解江西师范大学研究生院有关保留、使用学位论文的规定,有权保留并向国家有关部门或机构送交论文的复印件和磁盘,允许论文被查阅和借阅。本人授权江西师范大学研究生院可以将学位论文的全部或部分内容编入有关数据库进行检索,可以采用影印、缩印或扫描等复制手段保存、汇编学位论文。
(保密的学位论文在解密后适用本授权书)
学位论文作者签名:冲弟勒签名:诅冯签字日期:压11年l,月弓日签字日期:如,f年6月;日
关键词库 基于本体的深度搜索系统关键词库的构造与研究
]:
关键词库 基于本体的深度搜索系统关键词库的构造与研究
目录
摘要…….…...:..………...………...………………….………....….....………………………………IABSTRACT……………………………..…..….…………….………………………………………......III目录………………….
第1章绪论…….
1.1研究背景……………………………………………………………………..11.2选题的研究意义…………………………………………………………….11.3论文的主要内容和结构…………………………………………………….3第2章DEEPWEB数据搜索的相关研究综述……….
2.1DEEPWEB概述……………………………………………………………………………………62.2DEEPWEB数据搜索研究综述………………………………………………72.3本章小结……………………………………………………………………117第3章基于本体的深度搜索系统……………………………………………………………12
3.1本体概述……………………………………………………………………123.2基于本体的深度搜索系统描述……………………………………………143.3领域本体在深度搜索系统中的作用………………………………………163.4系统的基本思路……………………………………………………………183.5系统的主要框架……………………………………………………………183.6本章小结……………………………………………………………………20第4章本体的构建和基于本体的查询关键词库的研究……………………………。[www.61k.com]214.1本体构造的相关研究………………………………………………………214.1.1本体的描述语言………………………………………………………214.1.2本体的构建方法……………………………………………………….234.1.3本体的构建工具……………………………………………………….264.2本体的构造…………………………………………………………………274.2.1本体的需求分析………………………………………………………274.2.2领域知识的获取………………………………………………………284.2.3本体设计……………………………………………………………….294.2.4本体实现………………………………………………………………314.2.5本体维护………………………………………………………………354.3基于本体的关键词库研究…………………………………………………364.3.1基于本体的关键词库的构建…………………………………………374.3.2基于本体的关键词库中词的提取……………………………………424.3.3基于本体的关键词库的更新…………………………………………464.4本章小结……………………………………………………………………48V
关键词库 基于本体的深度搜索系统关键词库的构造与研究
第5章总结与展望.5.1
5.2………….….……………..…..49本文的研究工作总结与存在的问题………………………………………49进一步工作展望……………………………………………………………50参考文献….附录.
致谢.
在读期间公开发表论文(著)及科研情况……...56
关键词库 基于本体的深度搜索系统关键词库的构造与研究
摘要
DeepWeb是指那些没有固定的超链接,不能被传统的搜索引擎检索到,而是由后台数据库根据用户的搜索请求动态生成的Web页面;与静态Web页面相比,DeepWeb中存储的信息具有较高的价值和权威性。[www.61k.com)随着Intemet的飞速发展,DeepW曲中的信息量也在快速地增长。因此,如何有效获取DeepW|eb中的信息资源是大家都在关注的话题,具有很现实的重要意义。
本文就如何有效获取DeepWeb中存储的数据信息,提出建立一个基于本体查询关键词库,以实现DeepWeb数据信息获取过程中查询表单的自动填充,解决DeepWeb信息搜索过程中存在的问题,如由于数据异构导致不能统一获取数据、通过手工获取数据成本高以及根据搜索结果建立的本地数据库不能及时更新等问题。目前电子商务的发展已经成为DeepWeb发展的主要驱动力量,本文以电子商务网站为例,重点介绍了如何构建合适的基于电子商务领域本体的查询关键词库,如何利用查询关键词库实现电子商务网站的信息集成,使本地数据库具有实时性、有效性和完整性。
本文的主要工作和创新点包括以下几点:
1、分析目前DeepWeb信息搜索技术,提出构建一个基于本体的查询关键词库以实现DeepW|eb数据集成。获取DeepW.eb数据是DeepWreb数据集成的首要工作,DeepWeb数据需要通过DeepWeb页面上的用户查询接口来获取,查询关键词库可以对用户查询接口自动提供查询关键词,实现DeepWeb数据获取过程的自动化。为了获取更全面更专业的数据,要求查询关键词库包含的关键词是有效而全面的。本体可以将某一领域内的所有概念通过语义关系联系起来,根据本体构建的关键词库就能够包含领域内所有的概念集合,提高DeepWeb信息搜索的查全率。
61阅读提醒您本文地址:
2、使用本体构造工具Prot696和本体描述语言OWL半自动地构建了电子商务领域本体。构建一个基于本体的查询关键词库,首先需要建立一个完整的、准确的本体。本文分析目前存在的几种本体构建方法的特点,将目标本体的构建分为本体需求分析、领域知识获取、本体设计、本体实现和维护五个阶段。根据电子商务网站中的数据特征,使用本体构造工具Prot696和本体描述语言OWL半自动化地构建了电子商务领域本体。
3、在UNIX系统环境下构建存储本体层次关系的树形目录文件,生成初始关键词库。本体的存储有文件存储和关系数据库存储两种方式。根据本体中概念的层次结构特点和UNIX系统对于文件系统操作的快捷性以及良好的可移植
关键词库 基于本体的深度搜索系统关键词库的构造与研究
性和安全性等特点,本文采用UNIX环境下的文件存储方式。[www.61k.com]将本体中的概念和概念之间的关系采取特定的映射方式映射到树形目录文件结构中,并通过编一~码生成树形目录文件结构中的文件夹和文件,形成查询关键词库。
4、对关键词库中所对应的UNIX属性文件目录进行遍历,使用一个特定文件保存关键词库中的所有查询关键词,通过读取特定文件中的内容来实现词的自动提取。为了给获取DeepWeb数据提供查询关键字,需要频繁的检索文件和访问文件,这样内外存之间的信息交换量太大会影响文件检索效率。针对这个问题,本文通过对库中所有目录文件进行遍历,建立一个特定文件,保存关键词库中的所有查询关键词。信息检索程序获取查询关键词时只需对这个特定文件进行访问,这样既提高了检索的效率又增加了关键词库的安全性。
5、通过本体学习,实现关键词库的更新。提交关键词查询DeepWeb中存储的数据后,得到包含DeepWeb数据的结果文档。根据本体和上下文知识对文档进行本体学习,经过词法分析、语义识别、本体查询、本体更新和词库更新五个阶段,实现关键词库的更新,并采用词库与文本同步更新的方法避免词库频繁更新而影响查询效率。
关键词:DeepWeb;深度搜索;本体;关键词库;电子商务II
关键词库 基于本体的深度搜索系统关键词库的构造与研究
Abstract
DeepWebhasnofixedhyperlinkandcannotberetrievedbytraditionalsearchengines,whichisdynamicallygeneratedbythebackgrounddatabaseinlinewithuser’Ssearch;ComparetotheSurfaceWeb,theinformationstoriedinDeepWebhasahighvalueandauthority.WiththerapiddevelopmentofInternetapplication,theamountofinformationinDeepWebisalsoinrapidgrowth.Therefore,howtoobtaintheinformationresourcefromtheDeepWebeffectivelyisnowahottopic,whichhasgreatpracticalsignificance.
ThispaperstudieshowtoobtainthedatainformationfromtheDeepWebeffectively.Akeywordlexiconbasedonontologyisproposedtorealizeautofillingthequeryformintheinformationacquisitionprocess,whichsolvestheproblemofDeepWebdatasearchsystems,suchascannotobtaindataunifyasthedatastructuralisomerism,highcostofmanuallyobtainingdataandthegainedlocaldatabasecannotbeupdatedintime.Thedevelopmentofe.commercehasbecometothemajordrivingforcetoDeepWebdevelopmentrightnow.Thispapertakese-commerceforexample;emphaticallyintroduceshowtobuildanappropriatekeywordslexicon,andhowtousethekeywordslexicontorealizeinformationintegrationfrome。[www.61k.com)commercesites,SOastoensurethedatabase’Sinstantaneity,validityandcompleteness.
Themainworkandinnovationareasfollows:
1.AnalysesthepassingtechnologyofDeepwebinformationsearches,andproposestoconstructaquerykeywordswarehousetorealizeDeepWebdataintegration.ObtainingDeepwebdataistheforemosttaskoftheDeepWebdataintegration,andtheDeepwebdataareachievedthroughthequeryinterfacesinDeepWebpages,andSOthequerykeywordswarehouseautomaticallyprovidingthequerykeywordstothequeryinterfaces,CanmaketheDeepWebdataacquisionprocessautumnally.Inordertoobtainmoreextensiveandspecializeddata,thekeywordswarehouseshouldcontaineffectiveandintegratedwords.AlmostalltheconceptsinacertaindomainCanbeconnectedthroughtheirsemanticrelationsinontology,thusthequerykeywordswarehouseestablishedonthebasisofontologyCancontainsalmostallthedomainconcepts,whichCanenhancetherateofDeepWebinformationsearch.
61阅读提醒您本文地址:
关键词库 基于本体的深度搜索系统关键词库的构造与研究
2.Semi?automaticallyestablishesontologyine-commercedomainusingontologyconstructtoolProtdgdandontologydescriptivelanguageOWL.Toconstructaquerykeywordswarehousebasedonontology,acompleteandaccurateontologyshouldbebuiltfirst.Thepaperanalysesseveralexistencemethodsoftheontologybuilding,dividestheprocessofthegoalontologyconstructionintofivestages,whicharedemandanalysis,domainknowledgeacquisition,ontologyimplementationandmaintenance.Inthelinewiththee—commercesites’datafeature,thepapersemi?automaticallyestablishesontologyine-commercedomainusingtheontologyconstructtoolProtdgdandtheontologydescriptivelanguageOWL.
3.StructuretreeformcataloguefilesinUNIXsystemenvironment,whichistheinitialkeywordswarehouse.Therearetwowaystostoretheontology,filestoreandusingrelationaldatabasetostore.Onthebasisoftheconcepts’hierarchystructuralfeaturesandtheconvenientoperationwiththefilesystem,niceportabilityandsecurityfeaturesofUNIXsystem,thepaperusesthefilestoreinUNIXsystemenvironment.Mappingtheconceptsandtherelationshipbetweenthemintothetreeformcataloguefiles,usingaspecificmappingpattern,andproducethequerykeywordswarehouseviacoding.
4.Traversethecataloguefilesinkeywordswarehouse,andbuildaparticularfilesavingallthequerykeywords,torealizeautomaticallywithdrawalthewords.InordertoprovidequerykeywordstotheDeepWebdataobtainingprocess,itshouldretrieveandaccessthefilesfrequently,thustoomuchinformationexchangecapacitybetweeninternalmemoryandexternalspeichermayinfluencethefilerecallprecision.Aimedatthisproblem,thepaperusesaparticularfiletotraverseallofthecataloguefilesinkeywordswarehouse,andsaveallthequerykeywordsinit.Whiletheinformationsearchprogramneedsquerywords,accessingtheparticularfileisallneeded,whichcanenhancetheretrievalefficiency,aswellasensurethesecurityofthekeywordswarehouse.
5.Learnontologyfromtheretrieveddocuments,andrealizeupdatingthekeywordswarehouse.Accordingtotheontologyandcontextknowledge,thekeywordswarehouseisupdatedthroughlexicalanalysis,semanticidentify,ontologyquery,ontologyupdateandlexiconupdatesuchfivesteps.Tosolvetheproblemofqueryefficiency’Simpactproducedbyfrequentlyupdate,awayofsynchronizationupdatebetweenthelexiconandtheparticularfileisadopted.
Keywords:DeepWeb;Deepsearch;Ontology;KeywordsWarehouse;E-commerceIV
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
第1章绪论
随着网络时代的发展,网络上的信息量越来越大,越来越多的人选择从网络上获取自己所需的信息。(www.61k.com)由于传统搜索引擎存在一定的技术缺陷,很多重要信息无法被传统搜索引擎检索到,导致用户花费很多时间却检索不到自己想要的信息。根据网络信息的分布位置,可以把网络分为静态网页和DeepWeb[纠。静态网页又称SurfaceWeb,其信息可以通过现在技术已经成熟的搜索引擎获得,如百度、Ooogle等。而DeepWeb中的信息则无法通过传统搜索引擎获得,之所以称为DeepWeb,就是因为其信息隐藏在网页搜索界面之后,需要通过专门的接口访问获得,相对于SurfaceWeb,DeepWeb中包含的信息往往更具有专业性和针对性114J,更符合用户的需求。根据BrightPlant统计,DeepW『eb的数据存储量是SurfaceWreb的五百多倍,总数超过五千多亿【lJ。如何从DeepWeb中精确地查询到所需信息是一个大家都在关注的话题,因此对DeepW.eb信息的检索已成为当前的研究热点。
61阅读提醒您本文地址:
1.1研究背景
根据目前对DeepWeb信息检索的研究,可以把DeepWeb信息检索模式分为两种,第一种是对DeepWeb数据源进行识别和分类,将用户填写的查询表单直接提交到DeepWeb站点服务器,访问DeepWeb数据库。第二种是先将DeepWeb数据集成到本地数据库,提供给用户统一的查询接口,通过访问本地数据库响应用户的查询12引。第一种查询模式的优点是实现简单、查询的准确度高,缺点是用户响应时间较长;第二种查询模式可以解决用户等待时间长的问题,但实现需要更多技术支持,包括数据提取和集成、模式匹配、数据管理等印J。数据的提取和集成是这类查询模式的重点工作,因此对这方面的研究比较多。但是诸多研究中对数据的获取都是通过手工方式模拟终端用户提交查询请求来获取的,这种方式费时费力,而且人工输入的不确定性也会影响搜索结果的准确性和完整性。据统计,95%的DeepWeb可以进行免费访问【441,即不需要进行网站的注册或付费就可以直接提交查询请求,获取有用信息,这使得DeepWeb数据获取的自动化成为可能。本文在这种背景下对DeepWeb信息的自动获取进行研究。1.2选题的研究意义
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
DeepW曲中的信息是以结构化数据方式存储于后台数据库中的,数据具有明显的领域专一性、层次性和结构性,基于这些特点,领域本体的概念被引入到DeepW曲信息获取中。(www.61k.com)本体Ontology原是哲学上的概念,意为现实世界中客观存在的一个系统的解释和说明,描述的是现实世界的客观本质【21。随着各门学科的发展,本体方法论已经延伸到各个领域,在计算机领域中也有着广泛的应用。在人工智能领域,领域本体被定义为客观世界里某个领域存在着的所有概念和概念间关系的集合【3】。它可以用一张无形的网把某一领域中所有的概念都包扩起来,并明确表示概念之间的各种关系。因此,本文利用领域本体层次概念明确的特点,提出建立一个基于本体的查询关键词库,该词库为DeepWeb数据的获取提供查询关键词,自动模拟用户手工输入的关键词,实现自动获取DeepWreb数据。
研究基于本体的深度搜索和查询关键词库,有以下几点意义:
1、缩短用户响应时间。在以往的对DeepWeb信息搜索的研究中,有的是对获取的网页结果进行过滤方面的研究【16】f17】,也有的是在提交表单之前对查询关键词进行语义扩充的【18】【19】,这些都是为了提高查询结果的准确率,但是很少考虑到用户的等待响应时间。而用户的等待响应时间长短是用户对搜索最基本的评价,是不可忽略的一个问题。本文提出的基于本体的深度搜索系统是在用户查询之前就做好了数据集成、分类和存储等方面的准备,在这个阶段所花费的时间不会影响或增加用户搜索的等待响应时间。此外本系统将获取的数据事先进行加工处理后存储在本地数据库中,用户查询时不直接访问DeepWeb站点服务器和后台数据库,不依赖DeepW|eb的页面深度,因此该系统还可以缩短用户响应时间。
2、解决由于DeepWeb数据异构导致用户不能统一搜索同一领域内不同DeepW曲站点数据的问题。网络中DeepWeb数据分布较广,但很稀疏,并且涉及到不同的领域,包括化学、生物、经济、计算机、电子商务等,同时还在迅速地发展【23】。DeepW|eb数据都存储在自己的W|eb数据库中,因此设计的数据结构和语义表述都不一样,由于这种不可避免的数据异构问题,用户不能对同一领域内不同DeepWeb站点中的数据进行统一搜索。例如用户要搜索一部诺基亚手机的当前市场最低价格,用户需要在淘宝网、京东购物商城、当当网等网站中各自查询一遍,然后通过判断才能知道所需信息。这样就存在两个问题,一是目前各种电子商务网站众多,用户可能只知道几个大型网站的网址,而不可能对所有此类电子商务网站进行一一查询。二是每个网站中的数据结构和网页组织结构都不一样,显示出来的结果也不同,用户还需要进行详细比对和人工判断,才能得到所需信息。这并且还是建立在用户清楚自己所需信息的基础上的,如果用户自己也不清楚需要什么样的信息,给出的查询要求很模糊2
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
的情况下,搜索效率将更低。[www.61k.com]本文通过建立一个基于本体的查询关键词库,实现数据的自动获取。根据本体的共享特性,可以实现DeepWeb中同一领域内概念的知识共享pJ,即本体可以给出同一领域内知识的共同理解。因此通过本文构建的关键词库进行数据抓取,可以抓取到不同DeepW曲中的数据。此外对获取的数据进行分类处理后通过统一的数据结构方式存储,可以很好的解决DeepWeb数据异构带来的问题。
3、实现数据自动获取。以往对DeepWeb数据集成的研究中,都需要手工输入查询关键词实现数据获取,这样做的代价和带来的问题是可想而知的。由于DeepWeb中绝大部分信息是可以公开访问的,本文使用建立的查询关键词库自动提供关键词,取代手工输入关键词方式,实现数据的自动获取。
1.3论文的主要内容和结构
本文在分析目前DeepWeb数据搜索研究现状的基础上,主要针对DeepWeb数据集成过程展开研究,构建一个基于本体的查询关键词库来实现数据的自动获取。研究如何有效构建本体以及如何利用查询关键词库实现数据的自动获取,致力于构建一个高查全率和高查准率的DeepWeb数据搜索系统模型。
本文首先介绍了基于本体的DeepWeb数据搜索系统模型,将系统模型分为DeepW曲数据自动获取、数据结果分析和DeepWreb用户搜索三个模块,提出建立一个基于本体的查询关键词库实现DeepWeb数据的自动获取,其模块组成如下图1—1所示。分析目前各种本体构建方法的特点,将领域本体构建过程分为本体需求分析、领域知识获取、本体设计、本体实现和维护五个阶段。以电子商务领域为例,使用本体构建工具Prot696和本体描述语言OWL半自动化构建了电子商务领域本体。通过特定的映射方式将本体中的概念和概念间的关系映射到树形目录文件中,然后在UNIX系统环境下编码生成树形目录文件中的文件夹和文件,建立初始的查询关键词库。对关键词库中的目录文件进行遍历,构造数据获取时需要键入的关键词。建立一个特定文件存储所有关键词,对文件内容进行简单读取,自动为数据获取提供查询关键词,实现自动获取DeepWeb数据。最后利用关键词查询得到的结果文本,使用本体的可扩充性和上下文语义关系,对基于查询关键词库进行更新;并采取词库与存储关键词的特定文件同步更新的方法,避免频繁更新词库导致影响查询效率。
61阅读提醒您本文地址:
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
图1.1系统模块组成图
本文共分为五章,各章节内容组织安排如下:
第一章:绪论。[www.61k.com)本章分析了论文的研究背景,介绍了DeepWeb的特点和检索DeepWeb数据的重要性,分析目前对DeepWreb数据搜索的研究现状,并根据DeepWeb数据搜索研究中存在的问题,提出了本文的主要研究内容,并对本文的组织结构进行了介绍。
第二章:DeepWreb数据搜索的相关研究综述。本章对DeepWreb数据搜索的相关研究进行了综述。首先简述了DeepWeb的定义,与SurfaceWeb的区别,
W曲的分类,对DeepWreb的特点进行了总结。然后介绍了DeepW|eb数据搜索工作流程,与传统搜索引擎进行对比,分析目前几种DeepWeb数据搜索模型,提出存在的问题和不足。
第三章:基于本体的深度搜索系统。本章提出了一种新的基于本体的深度搜索系统模型。首先介绍了本体的基本概念和特点,并分析了领域本体在本系统中的作用;其次根据目前DeepWreb数据搜索存在的问题,分析本系统需要解决的主要问题和本系统的主要特点;最后描述了系统设计的基本思路和主要框架。
第四章:本体的构建和基于本体的查询关键词库的研究。本章介绍了本体的构建过程和基于本体的查询关键词库的构造、应用和更新过程。首先分析了本体的几种描述语言、构建方法和构建工具的优缺点,将领域本体构建过程分为本体需求分析、领域知识获取、本体设计、本体实现和维护五个阶段。以电子商务领域为例,使用本体构建工具Prot696和本体描述语言OWL半自动化地构建了电子商务领域本体,并对每个步骤进行了详细描述;其次描述了查询关键词库的初始构造过程,选择在UNIX系统环境下,通过特定的映射方式将本体中的概念和概念问的关系映射到树形目录文件中,构建初始查询关键词库;4Deep
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
再次描述了如何利用一个特定文件存储词库中的关键词,实现自动获取DeepWeb数据;最后描述了如何利用查询得到的结果文本,使用本体的可扩充性以及上下文语义关系,经过词法分析、语义识别、本体查询、本体更新和词库更新五个步骤实现查询关键词库的更新,并设计了一种词库与存储关键词的特殊文件同步更新的方法,解决数据库频繁更新而导致影响查询效率的问题。(www.61k.com)
第五章:总结和展望。本章是对全文研究工作的总结以及对下一步工作的展望。
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
第2章DeepWeb数据搜索的相关研究综述
上一章介绍了论文的研究背景,分析了选题的研究意义,提出了本文的主要内容。(www.61k.com]本章将对DeepW曲数据搜索的相关研究进行综述,首先简要介绍DeepWeb的概念和相关知识,然后对DeepWeb数据搜索技术进行概述,并与传统搜索引擎进行对比,在分析目前几种DeepWeb数据搜索模型的工作流程和存在的不足之后,提出本文主要的研究方向。
2.1DeepWeb概述
文章【1】中提出,根据Web中所包含信息的深度,可以把Web分为SurfaceWeb和DeepWeb。SurfaceW曲是指信息存储在网络“表面"的网页,可以通过传统的搜索引擎查询获得。DeepWeb(深网)又称为HiddenWeb(隐网)或InvisibleW曲(不可见网),最初是由Dr.JillEllsworth于1994年提出的pJ。DeepWeb中的信息存储在后台数据库中,用户需要通过统一的接口提交查询才能访问数据库中的数据,由后台服务器将查询结果生成动态网页返回给用户,而这些动态网页就称为DeepWeb[14】,一般是临时由服务器动态生成的,所以并不存在固定的超链接,传统搜索引擎很难对其检索。DeepWeb的原义是指:“搜索引擎商家出于对信息保护或隐私安全等自身问题,不愿将某些网络内容公开供用户搜索,或是由于技术方面的原因,传统搜索引擎无法索引到的网络内容【l引。"后来一些学者又对DeepWeb给出了新的定义,ChristShermanp川、GaryPricep4J将其定义为:“可以通过互联网获取、但普通搜索引擎由于受技术限制而不能或不做索引的那些文本页面、文件或其他信息,这些信息通常是高质量、高权威的信息。"
DeepW曲一般包括以-FJL,中t18】【19】f23l:
1、要求注册、付费的网站。为了资源安全性等一些问题,一些网站规定用户访问数据资源之前必须通过用户名和密码注册登陆,有免费注册的也有需要付费的,但不论是否需要付费,传统爬虫技术都无法访问这类网站。
2、使用脚本语言编写的网站。这类网站可以被传统爬虫工具搜索到,但是其脚本语言不是HTML语言,通常无法被爬虫程序识别,加上一些垃圾脚本语言可能会使爬虫程序进入死循环,导致搜索无法进行。比如当网页的超链接地址中含有“?”字符时,恶意的“SPIDERTRAP"程序会使爬虫程序进入死循环。因此爬虫程序碰到此类网页时会主动放弃,以免搜索无法进行。
3、动态网站。这类网站是指只有在用户提交查询之后,服务器再根据用户
6~
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
的查询请求生成网页,其地址是动态的,网页在用户提交查询之前并不存在,即这类网页是依赖用户查询而存在的。[www.61k.com)
4、临时网站。又称为实时网站、流动网站。例如火车票余票查询、飞机航班查询、实时天气查询、股票信息等网站,这些网站内的数据只是临时性的,更新速度较快,一般的搜索引擎查询不到。
5、被本地网站管理员封锁的网站。指的是网站管理员通过一些特定命令或网络协议,比如添加口令保护或为网站添加禁止索引的标签等,使该网站不被网络爬虫工具爬到。
61阅读提醒您本文地址:
6、可搜索数据库。这类网站是指需要通过一定的网络接口访问网络数据库,由后台数据库根据搜索的结果生成动态页面。这类网站占DeepWeb的大多数,获取这类网站中的可用资源也是目前大多数学者研究的方向。很多地方所说的DeepW曲实际上是指这类网站,本文中的DeepWeb也是指这类网站,后面将不再重述。
随着搜索技术的发展,目前有些以前被定义成DeepW曲的网站已经可以被传统搜索引擎索引到,因此DeepWeb不是绝对的,而是相对的。
我们认为DeepWeb应具备以下特点:
l、DeepWeb没有固定的超链接指向页面,不能由传统搜索引擎获得。当数据库发生变化或用户输入的查询关键词不同时,生成的页面就会有所不同,具有动态性。“
2、DeepWeb中存储的信息具有高度的专一性和不公开性。
3、对DeepWreb数据库的访问必须通过查询接VI进行,因此DeepWeb上通常都包含查询接口,即供用户提交查询词的搜索框。
2.2DeepWreb数据搜索研究综述
针对SurfaceWeb上的信息进行检索的工具,如百度、Google等搜索引擎,采用的是一种全文搜索技术【5】。目前这种全文搜索技术技术已经发展得比较成熟,主要工作原理是利用爬虫程序爬行网页中的所有超链接。首先对网络中的每个页面进行关键字提取,再建立关键字与页面链接的索引,用户需要获取相关信息时,提交关键字给网络服务器,服务器对用户提供的关键字和页面中提取的关键字进行匹配,依据一定的相关度匹配原则,在索引中查询出结果网页的链接,最后以一定的顺序显示在结果页面中。一般称这类搜索引擎为传统搜索引擎【8】。传统搜索引擎的工作流程如下图2.1所示:
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
网页关键词’R弓I数据库
图2.1传统搜索引擎工作流程图
传统搜索引擎主要是对网站中各页面的超链接进行逐项爬虫来检索每个网深度搜索即对DeepWeb的信息搜索【4】1101,用户首先在DeepWeb中的搜索
查
数
图2.2深度搜索工作流程图
根据深度搜索中W曲数据库类型的不同,可以将DeepW曲信息检索模型
Web信息检索模型包括两种情况:一种情况是由数据
8页,因此,传统搜索引擎只能检索到网络中的静态网页,而对于那些没有固定超链接的页面,传统搜索引擎根本无法访问。(www.61k.com]框中输入想要查询的信息,提交查询后,这些查询关键字将形成查询表单;然后查询表单被提交给后台服务器;后台服务器接收到查询表单后,在数据库中对查询表单进行处理,查找匹配数据库,得到结果后生成动态网页返回给用户。最后用户在结果中查找符合自己要求的信息。其工作流程如下图2.2所示:分为两类。第一类Deep库所有者本身提供针对自身数据库的检索,例如淘宝网、当当网等,这类网站有自己的数据库,并提供针对用户的数据库访问接口。第二种情况是数据库所有者与搜索引擎之间建立合作关系,为搜索引擎提供后台数据库支持p4儿驯p川,如Yahoo!分类搜索,其与多家公司合作,能够检索到他们数据库中的数据资源。这类搜索方式虽然能够达到很高的准确度,但由于很多公司的数据库具有
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造.‘i研究
私密性和安全性等问题,使这种方法具有很大的依赖性和限制,针对这类信息检索模型进行技术研究的学者不多。[www.61k.com]
第二类DeepWeb信息检索模型是指开发者通过获取DeepWeb数据资源建立本体数据库,并不与Web数据源所有者直接联系,而是通过集成网络上公开的数据信息建立数据库【15】【27】【351。这种方法除了要搜索数据库中的内容外,还要利用一定的方法策略首先发现和识别DeepWeb,然后抓取DeepWeb中有用的数据信息,建立数据库。此类方法包含很强的技术性工作,引起了很多这方面学者的关注。本文研究的DeepWeb数据搜索也需要开发者自己建立数据库。
目前专门针对DeepWeb进行搜索的工具和网站有TheLibrarians’IntemetIndex(http://lii.ore,/)、CompletePlanet(http://aip.completeplanet.corn/)、About(http://www.about.corn/)、Educator’sReferenceDesk(http://www.eduref.org/)、LookSmart’sFindArticles(http://findarticles.com/)、IncyWincy
Spider(http://www.incywincy.com/)、GoogleScholar(http://scholar.google.com/)等。另外,Google(http://www.google.comO、Yahoo(http://yahoo.corn/)和Msn(http://www.msn.com)等也能对部分DeepW.eb进行检索。此外,现在国内还出现了一个专门针对找工作领域的DeepSearch网站。这些工具普遍具有很强的主题性,如航空领域、生物领域、化学领域、图书领域等。
目前对深度搜索技术的研究主要包括以下三种Deepw曲搜索引擎技术:简单的Deepw曲信息搜索引擎模型411451、基于接口集成技术的搜索引擎模型151149】和基于本体的搜索引擎模型【6】【31】【321。下面对这三类DeepW曲搜索引擎进行详细的介绍。
1.简单的DeepWreb信息搜索引擎模型【4J
简单的DeepWeb信息搜索引擎模型是在传统搜索引擎模型的基础上进行简单加工而形成的,其主要工作原理是在信息获取过程中增加一个子模块,将传统搜索引擎中针对静态网页的搜索改进成为针对动态网页的搜索,即DeepWeb搜索。这个子模块用来对获取的网页进行识别,并分类出DeepWeb站点或DeepWeb数据源,继而对DeepW曲资源进行信息获取。简单的DeepWeb信息搜索引擎模型的工程流程如下:首先采用爬虫技术从万维网中抓取网页,根据网页的超链接地址爬到所有网页;再通过一定的方法,比如分析SurfaceWeb与DeepWeb之间网页组织结构、超链接地址结构等方面的区别,将DeepWeb从获取的所有网页中区分出来,并对其数据进行采集;最后根据网页超链接地址的特征,如通常由同一Web数据库形成的对象网页的超链接地址的首部大体相同、结构类似等特征,对由同一数据库形成的其他DeepWeb进行抓取和数据集成。9
61阅读提醒您本文地址:
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
这类深度搜索技术主要是在传统的搜索引擎技术上加以改进,因此继承了很多传统搜索引擎中成熟的技术,但是由于其主要特点是通过判断出某单一DeepW|eb来发现同一数据源中其他的DeepWreb,其完全依赖于单一Deepw曲的判断,因此该技术存在一些问题:首先,某些Web数据库所有者只提供查询接口供用户访问,当用户没有提交查询时,网页并不存在,通过这种方式就无法发现和访问这类DeepWeb;再者,当发现到单一DeepWeb后,通过其超链接地址特征来获取其他同种数据源的DeepWeb,而一些网页的超链接地址并不具有很强的特征和规律性,加上很多地址还通过加密方式进行了加工和伪装,这样这种简单DeepW-eb信息搜索引擎也无法抓取这类网页。[www.61k.com]
2.基于接口集成的DeepWreb搜索引擎模型【13】
接口是指DeepW.eb网页中的搜索框,是Web数据库与用户之间建立联系的访问中介。用户通过在接口中输入查询关键字,然后由后台服务器从接口中获取用户输入的查询关键字形成查询表单,再将查询表单提交到数据库服务中心进行查询,最后服务器将查询结果以网页形式返回给用户。DeepWeb通常包含有一个或多个查询接口,因此可以通过判断网页中是否存在查询接口来判断网页是否属于DeepWeb。基于接口集成的DeepWeb搜索引擎的工作流程如下:首先通过一定的策略发现网络中的可搜索数据库,再通过查询接口的特征从网络中发现具有查询接口的DeepWreb,建立一个统一的集成的查询接El来接收用户提交的查询请求,将查询请求提交给数据库,再将各个数据库返回的结果进行整合、处理后以网页的形式返回给用户。
这类搜索引擎技术是通过查询接口来获取数据,间接访问Web数据库,相对于上一种方法其具有更高的准确率。但这种搜索模式需要实现可搜索数据库即数据源的发现和识别以及对接口的集成,实现起来比较困难,需要比较复杂的技术支持。目前对这类搜索模式的研究较多,由于本文不是针对这一模型进行的研究,就不在此进行详细描述。具体研究可以参考文献[10】【13】。
3.基于本体的DeepWeb搜索引擎模型
通常网络中可搜索数据库是面向某个领域或多个领域建立的,其数据信息具有很强的领域性,基于DeepWeb这一特点,一些学者提出了基于本体的DeepW.eb搜索引擎模型。这种技术主要是引入领域本体的概念,对DeepWeb搜索中的一些过程加以语义分析上的处理,使人机交互过程中达到相互理解,消除歧义,来提高DeepWeb搜索效率【6J。
基于本体的DeepWeb搜索引擎的模块组成图如图2.3所示。这种方法主要是针对用户输入的查询关键字通常具有语义不明或语义模糊、重复等特点,增lO
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
加了一个用户检索关键词扩展模块。[www.61k.com)其主要工作原理是通过领域本体概念对用户输入的查询关键词进行语义扩展,解决由于表达方式不一致而导致的数据丢失问题,以此提高搜索效率。
图2—3基于本体的DeepWeb搜索引擎模型框架
利用领域本体概念对DeepW|eb搜索引擎技术的改进还处于研究的初步阶段,目前很多对这方面的研究都只是对搜索过程中的某一模块进行改进,要实现整个搜索过程全面的改进还需要很大的工作量和技术支持。本文主要对这类搜索引擎模式进行研究,针对本体在数据获取模块方面进行研究和探讨,对现
’
在DeepWeb搜索引擎的发展起到一定的积极作用。
2.3本章小结
本章对DeepWeb数据搜索的相关研究进行了综述。首先介绍了DeepWreb的定义,与SurfaceWeb的区别,DeepWeb的分类,并对DeepWeb的特点进行了总结。然后介绍了DeepWeb数据搜索工作流程,并与传统搜索引擎进行对比,分析目前几种DeepWeb数据搜索模型,并提出存在的问题和不足。接下来一章将介绍本文提出的一种新的基于本体的深度搜索系统。
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
第3章基于本体的深度搜索系统
上一章综述了当前DeepWeb信息搜索的相关研究,总结了目前Deepw-eb数据搜索存在的用户响应时间长、手工实现数据获取代价大、建立的本地数据库更新不及时等问题,为解决这些问题,本文提出了一种新的基于本体的深度搜索模型研究提供了理论基础。(www.61k.com)本章将首先简要介绍本体的相关知识,分析领域本体在本文提出的搜索模型中的作用;提出一种新的基于本体的深度搜索系统模型,即在数据获取时使用基于本体的关键词库自动提供关键词,实现数据获取过程的自动化;再对本系统需要解决的主要问题和本系统的主要特点进行分析;最后描述系统设计的基本思路并将系统分为DeepWreb数据自动获取、结果分析和DeepW曲用户搜索三大模块,对每个模块进行简要说明,并着重介绍数据自动获取模块,为系统进一步细化提供指导方向。
3.1本体概述
随着计算机科学的不断延伸和发展,本体的概念和应用也从最初的哲学领域延伸到计算机信息科学领域,最近几年对本体的研究已经在人工智能领域展露头脚。人工智能领域内的很多复杂问题都可以通过本体论中的哲学思想来解答,因此人们越来越关注本体在计算机科学领域内的研究。本体在计算机科学领域内的发展与人工智能和信息技术的萌芽和发展密切相关。
本体这个术语最早产生于十七世纪,从希腊语的onto和logia派生而来,onto是指存在,logia是箴言录的意思,是一个哲学术语,属于哲学的一个分支
【36J【37】f391。从哲学上来讲,本体论是研究客观事物存在的本质,其真正内涵是对世界上任何领域内的真实存在作客观描述。本体论就是对以下这些问题进行回答‘20】【36】:对于某个领域,本质上有些什么样的对象、属性、过程和关系?什么是一项事物、一个人和一个组织?它们之间的相互依赖关系如何?
61阅读提醒您本文地址:
不同的自然科学界学者对本体的理解和定义都有所区别。在哲学上,本体最初的定义是指:“客观存在的一个系统的解释或说明,其关心的是客观现实的抽象本质,关注的是客观世界的存在【4lJ。’’在计算机科学领域内,本体有了新的定义:主要关注客观世界存在的“逻辑”。
在人工智能领域中,最早对本体作出定义的是Neches[3J等人,他们提出:“本体给出了构成相关领域词汇的基本术语和关系,以及利用这些术语和关系构成的规定这些词汇外延规则的定义。"
Studer!…对本体作出的定义更能被外界所接受,他提出:“本体是对概念模12
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
型的明确的、形式化的以及可共享的规范说明。[www.61k.com)’’具体含义包括以下四点:
●概念模型:对客观世界中的概念进行抽象描述,建立模型。其内容与
实际环境独立存在;
●明确的:本体中概念和概念之间的约束都有明确的或显式的定义,即
其含义明确、无二义;
?形式化的:本体具有自己的本体描述语言,可以被计算机识别和读取;?共享的:本体中的知识是被大众所认可的,其反映的是相关领域内公
认的概念集,所针对的是团体而非个体。
对本体的定义最著名并被广泛引用的是由Gruber提出的:本体是概念模型的明确的规范说明。
以上仅仅是对本体进行文字描述上的定义,有很多学者对本体还给出了其形式化的定义,即描述本体的基本组成元素。不同的研究者根据自身所要解决问题的要求,给出了不同的形式化定义,有高君等人提出的二元组(领域和关系集合)、金芝等人提出的三元组(领域、状态和关系集合)、李曼等人提出的五元组、Myo-MyoNaing[13l等人提出的六元组、还有七元组和八元组表示方法。目前还没有一种权威的形式化定义表示,下面详细介绍Myo.MyoNaing等人提出的六元表示法。
由Myo.MyoNaing等人提出的一种六元表示法,定义本体主要包含六个元素{C,Ac,R,m,H,X),C表示概念集合,Ac表示概念的属性集合,R是概念之间的关系集合,Ar表示关系的属性集合,H表示概念之间的层次结构集合,X表示公理集合。
本体的目标是获取相关领域内的领域知识,对该领域知识提供共同理解,确定该领域内共同认可的词汇集,并从不同层次上给出这些术语和术语之间的相互关系的明确的、形式化定义113J。
定义本体时,主要需要定义以下几个部分:
●类:即领域概念,是对象的集合。’
?关系:即领域概念与概念之间的联系。
?函数:是一类特殊的关系。在一个关系F中有N个元素,其中的前
N?1个元素能够决定第N个元素,这种关系成为函数。
?公理:是指一种事实,若某一语句被定义成公理,则该语句就是永远
的真理,不可改变,作为一个永久的事实存在。举个例子,如果某学
生选修了政治和历史两门课,那么他是文科学生;如果选修了物理和
化学两门学科,那么他是理科学生。公理通常可以被用来进行知识的
逻辑推理。?实例:表示领域概念的特定元素,如小张是学生的实例,政治课是学
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
科的实例。(www.61k.com)
目前对于本体的分类标准还没有达成共识,较多的情况下,本体的种类有以下几种f39l:通用本体(CommonOntologies)、领域本体(DomainOntologies)、术语本体(TerminologyOntologies)、形式本体(FormalOntology)、混合本体(Mixedontology)、表现本体(Representationalontologies)、任务/方法本体(TaskandMethodOntologies)、局部本体(Regionalontology)。
通用本体:又称为常识性本体、顶级本体。是对世界的普遍认知,主要描述客观世界中最一般的标识和概念,比如时间、空间、状态和事件等,可以适用于很多领域。
领域本体:领域本体主要是针对特定的某一领域或一些领域,对领域知识的概念、类型、属性等内容和结构进行约束,在领域中形成共识,达到领域知识的共享。比如电力领域本体、化学领域本体、机械领域本体等。
术语本体:术语本体中的类不需要完全使用定义或公理进行详细说明。比如WordNet本体,其中只有部分类通过关系进行了详细描述。
形式本体:形式本体中的类使用一种逻辑语言或是可以自动转换成逻辑语言的机器可读的语言来表示。
混合本体:混合本体中有些子类是以公理和定义为特征,而有些子类是以原型为特征。
表现本体:表现本体提供代表性的实体。如Frame本体。
任务/方法本体:任务或方法本体是指针对某一特定任务或方法而进行的概念以及概念之间的关系描述,提供某一观点的推理。
3.2基于本体的深度搜索系统描述
随着人们对DeepW.eb数据重要性的理解,针对DeepWeb的搜索研究发展得越来越迅速。目前研究者普遍认为DeepWeb搜索主要包括DeepWeb站点识别、数据源选择、DeepWeb查询接口集成、查询结果提取、查询结果语义标注、W|eb数据库维护等过程。针对DeepWeb数据搜索是一个复杂的过程,目前对DeepW曲查询接口集成、查询结果提取和查询结果语义标注这几个过程已有比较多的研究,已经发展得比较成熟。但是针对数据获取过程的研究还处于初步阶段,本文提出了一种新的基于本体的深度搜索系统模型,该模型主要是对数据获取阶段进行改进,引入本体的概念,建立了查询关键词库,通过自动提取查询关键词库中的关键词,填充查询表单,实现数据的自动获取。
本系统需要解决的主要问题如下:
?如何建立合适的领域本体,将电子商务领域内的所有概念和概念间的关系在本体中详细描述,使建立的查询关键词库包含尽量全面的查询关键14
61阅读提醒您本文地址:
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
词。(www.61k.com)
?如何利用本体建立查询关键词库,为数据获取提供合理的查询关键词,保证数据获取的准确率和覆盖率。
?如何实现对关键词库中词的快速提取,做到既能减少内存消耗,又能加快提取速度。
●如何实现查询关键词库的实时更新。具体表现为怎么样从获取的结果文本中分析提取关键字,对本体库进行补充添加。这是一个不断更新的过程,因此系统还需保证提取的关键词是最近更新的。
基于本体的深度搜索系统主要是面向目前特别热门的电子商务领域,随着该领域的发展,各种电子商务网站相继出现,商品信息玲琅满目,选择在网上购物的用户在众多选择面前越来越头疼,例如网站的选择、店家的选择、商品的选择等都成为用户购物的难题。针对这些问题,本文提出了一种新的基于本体的深度搜索系统,在搜集DeepWreb数据时针对所有的电子商务网站进行搜集,提供给用户一个统一接口,这样就解决了用户不知选择哪个网站的难题,用户只需关心自己需要什么样的商品即可;根据用户的查询,系统提供给用户所有这些需求的详细信息的对比,将同类的商品全部展示给用户,包括其各自的属性,这样用户就可以轻松选择目标商品了,通过简单点击商品超链接,就可以进入目标商品原本的购买界面。
基于本体的深度搜索系统具有以下特点::特点一:考虑用户的等待响应时间,在用户提交查询之前做好准备工作。在以往的对DeepWeb信息搜索的研究中,有的是对获取的网页结果进行过滤,也有的是在提交表单之前对查询关键字进行启发式扩充,这些方法都是为了提高查询结果的准确率,但是却没有充分考虑用户的等待响应时间。而本系统是在用户查询之前就做好充分准备,因此在这个阶段所花费的时间对用户的等待响应时间没有影响,即前面所做的一系列的处理,分析等过程都不会增加用户等待响应时间。
特点二:缩短用户等待时间并提供结果的对比选择。本系统所采取的方案是在用户提交查询之前就已经获取了网站中的重要信息,并将其分类存入数据库,用户是直接从这个数据库中获取重要信息,相比由Web数据库所有者自身提供的搜索引擎,本系统既可以缩短用户响应时间,又可以搜集多个电子商务网站中的数据信息,供用户对比选择。
特点三:通过领域本体知识达到知识的统一理解和统一管理。本系统主要是对电子商务网站的信息搜索,因此,我们结合了领域本体论的研究方法,建立了各商品种类领域的本体,利用领域本体,构建了一个基于本体的查询关键词库,实现了查询过程中关键词的自动获取。根据建立的电子商务领域本体实
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
现了不同电子商务网站中商品名称和属性等信息的共享,如有些商品名称的表述不同,但却表示的是同种商品;属性的表述不同,但却表示的是同种属性,等这些以前都需要通过人工来分辨,而计算机是无法理解和识别的。(www.61k.com)在本系统中,我们可以通过领域本体知识达到知识的统一理解和统一管理。
特点四:自动获取DeepWeb数据。本系统构建了查询关键词库后,可以自动对DeepW曲数据进行自动获取。但是初始的查询关键词库是人工构建的,难免会出现遗漏的现象,加上网络的迅速发展,信息也在不断变化,因此本系统还包括对查询关键词库的更新操作,间接的对本地数据库进行不断的更新,使搜索结果更具有实时性和准确性。
3.3领域本体在深度搜索系统中的作用
本体作为一种中间语言,成为人机交互的桥梁,使领域知识达到统一的理解和共享。深度搜索系统与传统的搜索引擎的不同主要在于深度搜索是面向Web数据库的信息提取,而Web数据库中的数据一般都具有领域专一性的特点,因此本文提出在建立领域本体模型后,将数据库中的信息概念、属性等内容作为本体的数据源,通过本体来实现不同语言表达方式的同一理解。
DeepWreb信息搜索问题目前仍然存在准确率不高、遗漏重要信息等问题,出现这些问题的原因很大一部分在于人机交互时出现的理解误差问题,如用户输入的查询需求与数据库的表达方式不一样,用户与用户之间的查询需求表达方式也不同。要解决这些问题,很多研究者提出使用一种中间语言作为人机交互的桥梁,消除人机交互时对知识理解的一些误区。本体是对客观世界的统一表达,其主要特性就是能实现知识的共享,因此建立本体模型作为这个中间语言,能够实现人机交互的正确理解和认识,提高查询的准确率,减少信息的遗漏情况。
对DeepWreb中的数据获取是DeepWeb信息搜索的首要工作,在很多研究中都使用人工方式输入查询词语获取查询结果,这样做存在很多问题。由于每个人对知识的理解程度、认识方向和表达方式等的不同,即使是同样的查询需求,也会出现各种不同的查询关键词,这些查询关键词一般是同义词。又由于语言的灵活多变,输入的查询关键词可能会出现不同的理解,这种情况则是属于词语的多义性。词语的同义词和多义词通常会造成查询结果的不同,影响数据搜索结果的准确率和查全率,因此解决词语的同义多义等问题对于提高搜索的效率起着至关重要的作用。词语的同义、多义等情况都可以在本体中明确定义,本体将领域中的知识通过一张网全部联系起来,通过这张网模拟手工输入的查询关键词,既能使输入过程实现自动化,又能保证输入的关键词能包含所有概念的各种表达,解决结果的遗漏问题,从而提高查询的查全率和查准率。16
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
网络深度搜索根据搜索数据库的来源不同可以分为两类,一类是搜索系统本身直接提供Web数据库,这类搜索方式不存在很大的技术研究;另一类是数据库需要开发人员从Web中提取数据,分类后存储在数据库中供用户查询,因此这类深度搜索模式的首要工作就是要获取数据。(www.61k.com)数据的获取主要有以下几个步骤:
●识别DeepWeb站点:
61阅读提醒您本文地址:
●识别DeepWeb查询接,口;
?获取DeepWeb查询结果;
●从DeepWeb页面中提取有效数据;
●对数据进行分析;
●数据存储。
本文以电子商务网站为例,针对各电子商务网站中商品的搜索进行研究工作,对DeepWeb站点和DeepWeb查询接1:3的识别这两步可以忽略,因为电子商务网站如淘宝、当当、卓越、京东等这些网站就是DeepWeb站点,DeepWreb查询接口在首页和子页都存在,均不需要再进行识别。从DeepWeb页面中提取数据研究者众多,研究者们提出了很多有效的方式来提取,例如通过页面的视觉结构来获取,通过本体的映射等方式来获取。本文主要研究如何有效获取DeepW-eb查询结果,要获取DeepWreb查询结果首先要输入查询关键词,要想正确而全面的建立搜索数据库,必须提供全面有效的查询关键词,靠手工输入查询关键词费时费力,而且还不能保证不存在遗漏的状况,加上随着Web的发展,DeepWeb数据的信息量也在不断增加,靠人工提供查询关键词很明显是不实际的。因此本文提出了一种基于本体的查询关键词库的构建方法,利用本体的概念和特性,建立查询关键词库,实现关键词的自动提取。基于本体的查询关键词库在网络深度搜索系统中的作用如下:
1、本体中领域概念的层次关系可以很清楚的表达,概念与概念、概念与属性、属性与属性之间的关系也有明确的描述。通过本体建立的关键词库可以在最大程度上覆盖领域内所有的概念和属性特征,服务器自动提取查询关键词库中的查询关键词,将其提交到DeepWeb查询接口,得到的查询结果更加全面。通过本体建立的查询关键词库与手工提供查询关键词相比,具有以下优势:
?大大缩短了输入的时间,提高了查询效率;
●可以避免重复输入影响后期数据处理。
?可以减少关键词的遗漏现象,提高查询的查全率。
●在本体的构建过程中,由于本体概念集合的获取是从DeepWeb页面中获取的,因此词库中的查询关键词与DeepW曲数据库的表达方式一致,可以提高查询的查准率。
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕上学位论文
2、DeepWeb中的数据量与日俱增,每天都在发生变化,要保证获取的信息具有实时性,要求提供的查询关键词也具有实时性。[www.61k.com]由于构造的本体具有很好的可扩展性,因此将查询得到的结果文本再作为本体的数据源,对文本进行概念知识获取,利用文本中上下文语义关系获取概念的语义理解,另外通过对本体的概念和概念关系的编辑和添加,实现词库的更新,保证本地数据库的实时性。
3.4系统的基本思路
本文提出的DeepWeb搜索系统的基本思路如下:
●建立基于本体的查询关键词库。搜集DeepWreb中的查询关键词,根据领域本体建立查询关键词库,为数据获取过程自动提供关键词。?提取数据。利用前一阶段提供的查询表单对DeepW|eb进行数据提取,分析结果页面的数据,通过分类、去重等一系列处理后按照一定的格式存储于数据库中,形成DeepWeb搜索数据库。
●处理用户查询。对用户提供的查询进行语义处理,然后将查询表单提交给服务器,查询数据库中能够匹配的结果,并通过一定方式返回给用户。?更新查询关键词库。通过对查询得到的数据结果集进行分析,提取新的查询关键词,不断更新查询关键词库。
?更新数据库。调用更新的查询关键词库中的关键词进行新的数据的获取,更新数据库。
3.5系统的主要框架
根据系统的主要设计目标和特点,本节讨论了系统设计的主要框架,如下图3.1所示,系统主要划分为三大模块:DeepWeb数据自动获取模块、数据结果分析模块和DeepWeb用户搜索模块。18
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
图3—1基于本体的深度搜索系统的主要框架
DeepWeb数据自动获取模块是整个系统的首要工作模块。(www.61k.com]首先从万维网中分类出DeepWeb,提取DeepWeb的查询接口。建立初始的基于本体的查询关键词库,从关键词库中提取查询关键词,在DeepW|eb查询接Vl中自动提供查询请求,获取结果页面。对结果页面进行集成,存储于结果文档中,然后通过对结果文档中数据进行分析,提取领域本体概念,对领域本体进行扩充,更新查询关键词库。查询关键词库的构造与维护是一个循环的过程,其主要工作流程如下图3.2所示:
图3-2DeepWeb数据自动获取模块工作流程
结果分析模块是整个系统的重要工作模块,这个模块中主要工作是对获取的结果进行数据分析,主要包括对数据进行去重处理和分类处理。并将分类好的数据按照一定的规则存储于数据库中。这个过程中对数据分析的好坏直接关系到搜索效率,比如前期的数据获取过程为了达到提高相关数据的覆盖率,必19
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
定会存在重复的查询结果,如果不将这些重复的结果进行去重、冗余处理,将会影响系统搜索的时间,降低搜索效率。(www.61k.com)对查询结果的分析处理目前已经研究得比较成熟,本文将不着重描述,可参考文献118][35]。
DeepWeb用户搜索模块是整个系统的最终工作模块,DeepWeb搜索系统的设计就是为了实现用户对DeepW|eb的信息查询。系统为用户提供统一的用户查询接口,用户输入自己的查询需求,利用之前建立的基于本体的查询关键词库,对用户输入的查询请求进行语义加工和扩展处理,将其转化成结构化查询语句。最后提交到本地服务器,由本地服务器在数据库中查询得到结果返回给用户。由于数据库中存储的数据也是结构化的,因此将用户输入的查询请求转化成与数据库中存储的数据类型相同的结构化数据后,例如用户输入的查询词是“诺基亚老人手机’’,根据语义扩展将其转换成结构化查询语句“手机品牌=诺基亚手机定位=老人机”,可以使查询过程方便迅速,大大提高查询结果的准确度,降低用户查询等待时间。
61阅读提醒您本文地址:
3.6本章小结
本章首先介绍了本体的概念和特点,分析了领域本体在本系统中的作用;再根据目前DeepWeb数据搜索存在的问题,提出了一种新的基于本体的深度搜索系统模型,即在数据获取时使用基于本体的关键词库自动提供关键词,实现数据获取过程的自动化;然后分析了本系统需要解决的主要问题和本系统的主要特点;最后描述了系统设计的基本思路和主要框架。接下来一章将重点介绍系统中使用的电子商务领域本体的构建和基于本体的关键词库的研究。
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
-
’
第4章本体的构建和基于本体的查询关键词库的研究上一章主要描述了本文提出的一种新的基于本体的深度搜索系统模型,分析了领域本体在系统中的作用,并对系统模型的基本思路和主要框架进行了介绍,并着重描述了Deepw曲数据自动获取模块的工作流程,提出建立一个关键词库为数据获取过程自动提供查询关键词,实现自动获取DeepW|eb数据。[www.61k.com]本章将主要对系统中使用的电子商务领域本体和基于领域本体的查询关键词库的构造和运用进行详细描述。通过对目前构造本体需要使用的几种描述语言、构建方法和构建工具进行综合分析,将领域本体构建过程分为本体需求分析、领域知识获取、本体设计、本体实现和维护五个阶段。以电子商务领域为例,使用本体构建工具Prot696和本体描述语言OWL半自动化地构建了电子商务领域本体;其次分析UNIX系统与Window系统在文件操作方面的优势,选择在UNIX系统环境下,采取特定的映射方式将本体中的概念和概念间的关系映射到树形目录文件中,实现查询关键词库的初始构造,并通过一个特定文件存储词库中的关键词,对文件内容的简单读取实现词的自动提取;最后对结果集中的文本进行词法分析、语义识别、本体查询、本体更新和词库更新五个阶段,使用本体的可扩充性和上下文语义关系实现查询关键词库的更新,并采用一种词库与存储关键词的特殊文本同步更新的方法,解决词库不断更新过程导致频繁访问文件而引起的问题。
4.1本体构造的相关研究
4.1.1本体的描述语言
随着本体在人工智能领域中的发展,对本体的描述越来越重要,即对本体如何进行形式化表述,使其能被计算机识别和读取。描述本体的语言和环境主要有:KIF(KnowledgeInterchangeFormal)、Ontolingua、CycL、Loom、OKBC(openknowledgebaseconnectivity)、OCML(operationalconceptualmodelinglanguage)、FLogic(FrameLogic)等【25ID6】【501。随着本体在网络中的应用与发展,一些基于Web的本体描述语言也相继被提出,称为本体标记语言,主要有:SHOE、XOL、RDF、RDF.S、OIL、DAML、DAML+OIL、OWL等【33】【36】。表4.1是几种基于Web的本体描述语言的比较:2l
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
表4-1几种基于Web的本体描述语言比较【21
语言
特征语法正规语义
类的层、尖描述逻辑谓词逻辑类的相等属性相等实例相等
SHOE0眦.,CIOnL
XML
蛐FG)
XML
0ILDAML+OILBDF/XML
0WL
HTMZJXML
有支持否否
BIlF/XgL有
R1)r/xl忆有
有支持
无支持否否不支持不支持
有
支持
恧否
日
支持
意否
日
支持
疋
日
否/是
否支持支持不支持
否
支持支持支持支持支持
支持
支持
不支持
不支持
支持
支持支持支持
不支持
支持支持支持
不持
支持
不支持支持支持不支持有
本体分布定义本体扩展本体版本修订计算特性区分
不支持不支持
不支持
支持
不支持
支持
不支持
支持
有
无有无无
通过对各种本体描述语言特点的比较,本文选择OWL语言来描述和构建电子商务领域本体。(www.61k.com]OWL(Web
Ontology
Language)是由W3C推荐的语义
Web中标准的本体描述语言。下面对OWL语言进行简要介绍。
OWL可以显式的表达领域中概念的含义和概念之间的关系,因此OWL可以帮助应用程序处理文档信息的内容,而不仅仅关注信息的显示方式。OWL是在已形成统一标准的XML/RDF语言的基础上发展起来的,通过定义基于描述逻辑(DL)[46】的语义原语来描述和构建本体。OWL根据语言表示和推理能力可以分为三类子语言:OWLLite,OWLDL和OWL
Fullt261。
?OWLLite是表达能力最弱的子语言,仅提供概念的分层能力和比较单纯的属性约束功能。支持的基数约束值只能是零或一。
●OWLDL在保证可判定性和计算完整性的前提下,语言表达能力最
强。可判定性是指所有的计算能在有限时间内结束;计算完整性是指所有的结论都可以保证有计算结果。OWLDL包括OWL语言构造的所有部分,但其使用受到一定限制,比如规定一个类可以是许多类的子类,但不能是另一个类的实例。OWLDL还提供强大的逻辑推理功能。
?OWLFull在OWL
DL的基础上消除了对OWL语言构造部分的使用
限制。OWLFull中,所有个体的集合可以定义成一个类,一个单一的个体也可以定义成一个类。但是OWLFull不提供完整的推理机制,也不能保证其计算性能。
这三种子语言之间的关系表现为【26l:有效OWLLite是有效的OWLDL的充分必要条件;有效OWLDL是有效OWLFULL的充分必要条件;合法OWLLite是合法OWLDL的充分必要条件;合法OWLDL是合法OWLFULL的充分必要条件。
61阅读提醒您本文地址:
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
根据使用的不同需求和情况可以选择不同的子语言来描述和构造本体,OWLLite和OWLDL之间的选择主要考虑的是用户需要语言表达具有的约束能力的程度;OWLDL和OWLFull之间的选择主要考虑用户使用RDF元模型机制的程度(如是否需要定义类型的类型,或是否需要定义类型的属性)。[www.61k.com]目前OWLFULL还不能完全支持逻辑推理机制,而OWLDL不仅可以保证推理系统的计算完整性和可判定性,还具有最强的语义表达能力,因此本文在构建本体时选择OWLDL作为本体描述语言。
4.1.2本体的构建方法
目前在人工智能领域内对本体的研究还处在初步阶段,对构建本体的方法还没有形成一套统一的标准【3J,一些专家已经开发出了各种不同的构建本体的方法,以下列举几个比较典型的领域本体构建方法。
l、IDEF系列
IDEFl4州(ICAMDEFinitionmethod)对结构化分析方法的改进,主要是采用图表和说明相结合的方式来获取本体中的领域概念【7】。IDEF3可以通过语义描述明确定义某个事件,并给出事件发生过程的流程图和状态转意图;IDEF5的图表方式直观易懂,但只能表达浅显的意思。相反,其语言表达方式较强,能够对图表中的隐含意义进行语义描述。因此将两种方式结合起来,互相补充,完成领域本体的语义表达。IDEF5提出构建本体的五个基本步骤如下【12】:
?组织和范围定义:确定构建本体的基本目标、本体使用的语境和表述观点,并为不同组员身份分配不同任务和角色。
?数据采集:通过各种方法获取领域知识。
●数据分析:分析数据,提取出概念、类、属性、关系等。
?建立初始本体:在上一步的基础上建立初始本体。
?本体的精炼和确定:对初始本体进行加工和完善,完成本体的构造。2、骨架法
骨架法(SkeletalMethodolgy)是由MikeUshold&MichealGnmingerl50】提出的,主要面向企业领域,包含某一系那个管商业或企业内部的术语。骨架法只为本体构建过程给出了一个指导方针,其主要分为以下几个步骤:
●确定构建本体的领域范围和开发目的;
?本体构建:本体构建分为本体获取、本体编码和本体集成三个步骤。本体获取是指对领域中的主要概念和概念间的关系进行获取,并对这些概念和关系进行明确定义。本体编码是指本体的形式化表达,确定本体的基本术语集,选择一中本体描述语言对本体进行编码。本体集成是指收集其他领域的相关概念和术语,然后扩充元本体。?本体评价:该方法没有提出本体的评价方法。
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
?本体文档化:建立文档,存储本体中对概念及关系的定义。[www.61k.com]
该方法还提出了本体构造过程的指导方针,包括一致性、明确性、可扩展性、最小编码偏差原则和最小本体承诺原则。
3、企业建模法
企业建模法是由MichaelGrainger&Mark.SFox[41]提出的,其目标是建立一套在商业和公共企业内部使用的本体,该方法的主要步骤如下:
●场景激发:为要建立的本体设置一个领域背景,确定构建本体的动机。?给出非形式化的提问:确定构建本体的需求,设定本体应该回答的所有问题,根据问题答案和领域背景的对应关系对本体进行评价,如本体是否需要扩展,是否能对提出的所有问题给出明确的答案等。
?术语规范化:从前面给的所有非形式化的提问中提取领域内的专业术语集,用本体描述语言对这些非形式化术语进行规范定义。
●给出形式化的能力提问:将非形式化的能力提问转换成形式化的能力提问,即用形式化语言描述问题。
?公理形式化:对本体中的公理进行形式化表达,包括领域术语的规范定义和约束条件。
●完成公理:定义完善形式化能力问题的解决方案。
4、METHONTOLOGY方法
METHONTOLOGY方法是由马德里大学MarianoFemandez&GOMEZ.PEREZt461等人提出的,使用领域是电子图书馆领域,主要目的是为了实现图书馆管理的人工智能化。该方法对SkeletalMethodology提出了一些修改方案,相比之下通用性更强。其基本流程如下:
●规格说明书编写:在本体构建初期首先编写一份非形式化的规格说明书,该说明书涵盖以下内容:本体的预期目的(包括本体的用途、使用领域和使用者等)、目标本体需要达到的形式化程度、本体的领域范围(要回答的问题集合和要描述的概念集合等)。
●领域知识获取:通过各种途径和方法获取领域知识,途径包括书籍资料、使用手册、领域专家以及其他领域本体。获取领域知识的方法有头脑风暴法、文本分析法(包括形式化和非形式化)、专家访谈法以及使用一些专门的工具。
?问题概念化:将上一步获取的领域知识解构为概念模型,生成规格说明书,并用书中的领域术语阐述问题。
?本体术语集成:集成其他领域本体中可以使用的概念术语集合。
?本体实现:本体实现也指本体编码。其实现依靠于一套完整的本体开发环境,包括词法句法分析器、解释器、编译器、浏览器、搜索器、评价24
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
器和自动维护工具。(www.61k.com]开发者可以自己选择本体编码语言。
?本体评价:本体评价是指在整个本体构造过程中,对每个阶段的成果、软件环境和技术文档进行技术性判断,从技术性和有效性两个方面对其进行判断。
◆本体文档化:在每个步骤完成时编写各自的文档。
5、循环获取法
循环获取法(CyclicAcquisitionProcess)是由AlexanderMaedche[241等人提出的一种环状结构本体获取法,其实现过程如下:
?选择数据源:选择已经存在的本体作为构建本体的数据源,如Cys、Dahlgren本体、WordNet、GermaNet、Tove等,选择元本体后,确定用于提取所需本体的概念的文本集合。
61阅读提醒您本文地址:
?概念获取:从文本集合中抽取领域本体的概念,并对这些概念进行归类。
?领域集成:从所有获取的概念中抽取与领域相关的概念,除去冗余和无关的领域术语,初步形成本体的概念体系结构。
●关系提取:确定概念与概念之间的关系,有些可以从元本体中继承,有些则需要利用学习方式从文本中提取。
?本体评价:建立初始本体后对其进行评价。然后重复整个过程进入下一轮循环。
6、结构化领域本体构造法
结构化领域本体构造方法【ll】的主要原则是强调文档在整个构造过程中的重要性,提出在每个阶段都编写规范文档,以便从文档中总结规律。其主要工作流程如下:
◆确定本体的领域和范围:了解目标本体的构建需求,明确目标本体的所属领域、使用范围、构建目的和最终使用用户,并编写详细的需求分析报告说明书,可以对后面的工作起到参考和导向作用。这个阶段需要开发者和领域专家共同完成。
?确定领域概念和概念之间的关系:首先通过各种途径获取领域知识,并对领域知识进行分析,确定领域中的概念,以及概念与概念之间的关系,用专门的术语准确的表达抽取的概念和概念之间的关系,形成目标本体的核心概念集。这个过程也需要开发人员和领域专家的配合才能很好的完成。
?本体实现:本体的实现即形式化编码,选择~种机器理解的语言进行编码。
?本体确认和评价:确定初始本体的建成,并对本体进行评价,评价内
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
容包括本体的完整性、明确性、一致性、可扩展性和兼容性。[www.61k.com]完整性是指本体是否包含了该领域的重要概念,概念及关系是否完整,概念的等级和层次是否多样化。清晰性是指本体中的概念术语和关系、属性的定义是否具有无二异性,是否准确清晰。一致性也可称严密性,即本体中概念之间的关系在逻辑上是否严密无漏洞,可以支持逻辑推理。可扩展性是指本体是否可以随时实施更新,概念的层次结构是否可以灵活扩展,语义是否可以再丰富和完善,最主要的是是否可以加入新的术语概念。兼容性是指本体能否和其他本体进行兼容,互操作。
●本体的维护:本体需要实时更新才能正确客观的反映现实世界,可以通过集成新的本体、添加新的概念术语和关系和通过知识学习等方式实现本体的更新和维护。
由于本体描述的领域不同,范围不同,具体工程不一,所以目前还没有一第一,本体构建首要工作是要确定本体的领域、范围、目的、用户等基本第二,本体的构建是一项大的工程,需要领域专家的配合,对于领域概念的获取和概念之间关系的定义只有领域专家才能完全认识和理解;
第三,本体实现的过程中需要选择一种适合自身的编程语言;
第四,本体的构建是一个重复的过程,需要不断的获取新的领域知识来填充本体的概念库。
结合上述各种本体构建方法的特点和目标本体的特点,将本体的构造分为4.1.3本体的构建工具
本体工具一般可以划分为:本体开发工具(Developmenttools)与本体映射工具(MappingTools)t31。本体开发工具就是文中所提的构建本体需要使用的工具,目前构建本体的工具有Protdgd一2000,OntoEdit,OilEd,WebODE,Omolingua等;本体映射工具是在本体具体的应用中使用的工具,主要有PROMPT,ONION,
本体开发工具根据所能支持的本体描述语言可以分为以下两类:
WebOnto和Ontolingua为一类,这两种本体开发工具都有特定的本体描述的。此外,这两种开发工具也支持多种基于趾的本体描述语言。
Protdgd系列、OntoEdit和WebODE等则归为另一类,这类本体开发工具在构建本体的过程中可以自己选择本体描述语言格式,如XML、RDFs、OWL等。开发与本体描述语言独立,可以自由导入导出不同语言的本体。本文使用的本个统一的本体构建方法,总结上述描述的几种本体构建方法的特点如下:情况,即需求分析要做好;本体的需求分析、领域知识的获取、本体设计、本体实现和维护五个阶段。OBSERVER,Chimaera,FCA.Merge,GLUE等。语言支持,WebOnto是基于OCML语言的,Ontolingua是基于Ontolingua语言
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
体构建工具是Protege3.1.1,该工具的主要特点是可以开放本体源码,为本体构建提供方便,对本体初学者也有很大的帮助。(www.61k.com]下面将对Prot696工具进行简要介绍。
Prot696工具是由美国斯坦福大学的StandfordMedicalInformatics开发的一个专门构建本体的开放性源码编辑器,已经发展成为一个系列,有Prot696.2000、Protege3、Protege4版本,均可以在官网免费下载。Prot696工具是用Java语言开发编写的,其用户界面操作简单方便,与普通Windows应用程序相当。本体的层次结构采用树形目录表示,一目了然,开发者可以很方便的添加、编辑或删除本体中定义的类、属性、关系和实例等。Prot696还为开发者提供整个本体的概念关系图,可以让开发者很直观的观察本体的构造,进而进行改进。此外Prot696具有很好的可扩展性,拥有完全开放的用户接口,可以提供大量的插件来完善本体的构建,能够支持几乎所有形式的本体描述语言,可以导入和导出各种语言的本体文档,另外还能支持不同语言之间的相互转换。
Prot696工具支持源代码开放,提供完全的API接口,软件更新快,还为初学者提供详细的帮助文档,集众多优点于一身,受到当前国内外本体研究者们的一致好评和亲睐。本文选用此工具来开发本体。
4.2本体的构造
构建的本体的直接目的是为查询关键词库的建立提供服务,在构建过程中要充分考虑领域类查询关键词的组成。本文以电子商务网站为例构造本体,主要根据商品的详细属性信息搜索这些电子商务网站内的商品,主要是要提供。查询关键词的数据来源即来自于这些商品的属性信息,但是电子商务中商品的种类繁多,达到成千上万,要全部把这些商品的各类信息用本体描述完全需要花费很多时间和精力。由于时间的限制,本文只针对数码领域内的笔记本电脑和手机两类商品进行本体构建。
61阅读提醒您本文地址:
本文结合了几种方法论的特点和目标本体的特点,将目标本体的构造过程分为本体的需求分析、领域知识的获取、本体类、对象、关系设计、本体实现和维护共五个阶段。下面分别对几个阶段的详细过程进行描述。
4.2.1本体的需求分析
本体的需求分析工作是本体构造的首要工作,其为本体的构建提供了依据,为本体的构建指明方向,因此不可忽视其重要性。本体的需求分析是指定义本体构造的目的、本体的应用范围、本体的最终使用用户、本体的描述语言和构建本体使用的工具等。要弄清本体构造的需求,可以通过回答以下问题来实现:问题一:构造本体的目的是什么?
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
答:本文中目标本体的构造主要是利用本体中概念之间语义联系为查询关键词库的建立提供依据,主要目的是为了提高深度搜索系统中数据库的覆盖率,实际目的是为了实现深度搜索系统查全率和查准率的提高。[www.61k.com)
问题二:目标本体的领域是什么?
答:目标本体的领域是数码商品中笔记本电脑和手机领域。
问题三:目标本体的使用用户是谁?
答:目标本体的使用用户是本体的维护者。
问题四:选择何种语言来描述本体?
答:本文选择OWL-基于Web的本体标准描述语言。
问题五:选择什么工具来构造本体?
答:本文使用Prot6963.1.1工具构造本体。
回答完上述问题后,编写本体需求分析文档,以便为本体的构造提供指导方向和进行本体后期的维护工作。
4.2.2领域知识的获取
领域知识是本体的基础和数据来源,领域知识的获取一定要全面、真实和有效。一般获取领域知识的来源有:领域专家、专业书籍、核心文献、网络和已经存在的本体等。本文构造的本体主要是针对电子商务网站的商品信息,网站中这些商品信息都可以免费获取,一些网站中的查询接口提供了既集中又全面的领域知识,直接从网站中获取领域知识既方便又可靠。本文选择了几个有代表性的电子商务领域的页面信息,如下图4.1所示,主要从这些页面中获取本体的领域知识。
淼IIdm,三。三雪二二■:,:薰1■忙■啪■舶
●口nlⅢ¨tllwineri,lq■
●a●I■■■啊^r越ri-Is-et-?H
■E‘蛐:■■t■■■耽’i,腿?,■’
““‘:淼~?~一…~…一14m-。.。盟一=’’■—■_z,■-—r—l,ft●_j■■哪II瑚1抛I舭斗争【f墨_‘I…‘{览"卫徽址删监旺面Ⅱ毕吧…l●*踟枷螂●●*’聃』=?辫誉谢}鬻器盛蹬躐矗AUG器ER(,-【●pp-)m革“_-●●-7.5111.110●堋一一t“***怒=:’”鼹i摇:蹦&塌嚣器叩“”。::竺^喇’计砷■:=::I柚t:。.~一一…t“4●州M—o■^●棚●●O‘h'’E’
■,埔l■一…叭'_-—-u____-o嚣翟,…‘二Z二岫_国-*^£t…,t?7●-f^,us)-_
?竹口t_压J-l__茸-?正-“盐竺竺!竺v:t■柏7目■■t●:::::●I■■"㈣H毫t:丰一■■■t■—■■^●●^穗,■t■■‘%.福寰HP】_?■●rt■●_1●瞳l—
±M11mill搠O●n■匿∞__
翱t■啊I≈r■嚏一1■t■nInmmr:■_一
}1■啊■一?r■哺㈣1一-Ⅱ
■r-‘--只—■■■u一Hm_o71工^●maim
aq■■I■●j,■£^t—一。l_●--∞I{■●e●■川mq●-_竹
口材I-一n■¨●_一臼■,哺●日掰啦∞rI■重‘‘—,
●■幸au●●-,,jmr●●●■_
_?Mj■R●●■●?m}■勺‘一o-_霸m?-_-口_洲
。●_
●_‘晓稿1-一t■■■●,聃一■■霸■E蛐-秘的■—■_
■■q●■”●■●,,,■啪■‘斜疆1-r舯
足‘婀船-o一妇,-
-I■■■?,{-q●●-n_-
■●■r■‘,辑…‘I岫。+j聃日一-●囊
■¨■。”疆吧啦一门■胡一n枷啊邪,一
n■吐I●
‘■●■■,’■‘■●,
■■肘-妒福,1‘●啊口nI‘●Hn峨≈靠●—t图4.I获取领域知识的网站
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
在这个阶段列出所有领域概念的清单,为本体类、对象和关系的设计做准备。[www.61k.com)
根据网络上这些信息资源可以获取的领域知识包括:笔记本电脑信息(包括颜色、上市时间、品牌、定位、价格、电池容量、电池寿命、内存容量、显存容量、epu型号、光驱类型、硬盘大小、重量、屏幕尺寸、型号等)、手机信息(包括手机功能、网络类型、外观、样式、颜色、屏幕像素、摄像头像素、操作系统、铃声类型、重量、价格、定位、品牌等)、笔记本的品牌(包括联想Lenovo、华硕Asus、惠普HP、戴尔、三星、苹果、索尼等)、手机品牌(包括诺基亚、三星、摩托罗拉、HTC、步步高、OPPO、金利等)。
4.2.3本体设计
本体设计是指定义本体的类、对象、属性和关系,是构建本体的核心环节。根据上一阶段得到的领域概念清单,从清单中分出哪些是类、哪些是属性、哪些是对象,然后确定这些类与类之间的关系、属性与属性之间的关系以及类与属性之间的关系。
本文中提取的类主要有:数码产品类、电脑类、笔记本类、手机类、内存、显存、CPU、显卡、硬盘。
本文中提取的属性主要有:颜色属性、品牌属性、价格、尺寸、重量、类型、容量、像素、大小、型号、上市时间、售后服务等。
属性值列举几个如下:
颜色属性值有白色、黑色、黄色、红色、绿色、蓝色、花色、透明、酒红色、军绿色、天蓝色、巧克力色、桔色、浅灰色、浅黄色、沈卡其布色、深灰色、深紫色、深蓝色、粉红色、紫罗兰色、紫色等。
品牌属性值有:ThinkPad、Apple/苹果、Lenovo/联想、AsuS/华硕、HP/惠普、Dell/戴尔、Acer/宏基、Samsung/--星、Sony/索尼、Toshiba/东芝、Hasee/神舟、Fujitsu/富士通、Gateway/捷威、MSI/微星、Founder/方正、Malata/万利达、BenQ/明基、GateWall/长城、清华同方、Nokia/诺基亚、……、SonyEricsson/索尼爱立信、Motorola/摩托罗拉、HTC、LG、K.Touch/天语、OPPOBBK/步步高、Sharp/夏普、Philips/飞利浦、Coolpad/酷派、Huawei/华为、Gionee/金立、ZTE/中兴Hisense/海信、UT、Starcom/UT斯达康、其它品牌等。
61阅读提醒您本文地址:
上市时间属性值有:2006年、2007年、2008年、2009年、2010年、2011年
售后服务属性有:全国联保、店铺三包、其它售后服务29
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
本体中对关系的表述主要有以下四类关系:
Part.of关系:整体与部分的关系。(www.61k.com)例如笔记本硬件包括CPU、内存、硬盘等,则“笔记本"与“CPU"是整体与部分的关系,“CPU”ispart-of“笔记本"。
Kind.of关系:父类与子类的关系,又称为抽象与具体的关系,在本体中kind.of关系非常重要,是实现关键词语义扩展的的重要依据。例如电脑与笔记本是父类与子类的关系,数码产品与电脑是父类与子类的关系。
Instance-of关系:概念与实例关系,即类与对象的关系。本文构建的本体主要是针对查询关键词构建的本体,没有涉及到具体的实例和对象,例如笔记本类中并不涉及某一台笔记本。
Attribute.of关系:属性关系,即一个概念是另一个概念的属性。本体中属性关系分为两种,类的属性和数据属性。类的属性和数据属性之间的区别是数据属性是数据与概念之间的关系,比如品牌属性是类的属性,价格属性是数据属性。“品牌’’isattribute.of“笔记本’’,“价格"isattribute.of“笔记本"。
本体中对定义的函数有:配置函数(内存容量,显存容量,显卡类型,硬盘大小,CPU,光驱类型,笔记本),表示内存容量、显存容量、显卡类型、硬盘大小、CPU、光驱是笔记本的配置。定义配置函数(CPU类型,CPU频率量级,电压,CPU),表示CPU类型、CPU频率量级、电压是CPU的配置。
功能函数(3G上网,蓝牙,摄像头像素,笔记本)表示3G上网、蓝牙、摄像头像素是笔记本的功能。功能函数(GPS导航,JA、,A扩展,MP3播放,Wifi,存储卡扩展,电视播放,多点触摸,蓝牙,摄像头,收音机,双卡双待,手写输入,在线炒股,手机)表示GPS导航、JA、,A扩展、MP3播放、Wifi、存储卡扩展、电视播放、多点触摸、蓝牙、摄像头、收音机、双卡双待、手写输入、在线炒股是手机的功能。
详细设计见附录。
部分领域类的层次结构图描述如下:30
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
。[www.61k.com];,-”,。d,
.,.?,’,
f,一,,,¥《.j‘_。I},毗,
图4.2部分领域类的层次结构图
图4.2为数码产品的大概框架结构,顶层为Thing,是所有类的父类,第二层是商品的分类,包括书籍资料、数码产品、生活用品等,其中属性是本层所有类的通用属性,这些类的属性可以被下层的类继承。第三层是数码产品的分类,分为电脑、手机、相机等,同样也包括数码产品的通用属性。下层主要对电脑中的笔记本电脑进行了属性、功能和配置的细化。确定好类的层次结构后就可以进行下一步本体的实现。
4.2.4本体实现
设计好本体的类、属性、实例和关系后,构建本体的准备工作就完成了,要让计算机理解本体的组成结构,即概念之间的关系,需要进行本体的实现。实现本体包括本体的构建和形式化编码。本文使用Prot696工具作为本体的构建工具,形式化编码语言使用OWL语言来描述本体。首先根据上-4,节中确定的类的层次结构,使用Prot696工具构造本体类,
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
图4.3中展示了本体部分类的基本层次构造。(www.61k.com)
Fofproject:●飞
Assen酣№憎rc网阍f司网隔
。owl:Thing
●书疆资料
●生活用品
'●数码产品
●}且机
t●电脑
t●笔记本电脑
●CPU
●显卡
●硬盘
■显存
●光驱
●主机
●显示器
●平板电脑
●手机
●家电
图4.3类的基本层次构造
构建了类的层次结构后,建立类的属性,类的属性包括对象属性ObjectProperty和数据属性DataProperty,其区别已经在前面叙述。图为本体中部分属性的构造。
ForProject:●
?p哪懒回谣’哥留冒7i
■型号。;
●外观
一类型
■吝里
●重里
一上市时间
一售后服务
一颜色
9啊品牌
瞳国内品牌
啊国外品牌
■价格
本体具有很好的层次性,父类的属性可以被子类所继承,子类也可以定义
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
自己的属性,例如手机是数码产品的子类,则手机可以继承数码产品的属性如上市时间、重量、品牌等,手机自己也可以定义自己的属性,如手机的外观。[www.61k.com)图4-4展示了手机的部分属性继承。
型两一
■
詈勰怒键筹嚣≯翥、≯
图4.5本体中属性的继承
本体的设计阶段中定义了函数,下图为配置函数的构造,描述为CPU、硬盘、显存和光驱都是笔记本的配置。
图4.6本体中函数的构造
构造了本体的类、属性、关系、函数后,接下来构造类的属性值,图为构造笔记本显卡类型,主要有独立显卡、继承显卡和双显卡三个属性值可选。
33
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
◆图4.7本体中属性值的构造
本体初步构建完成后可以查看其OWL代码,这是本体构建工具prot6醇的开放源代码的优势,部分代码如图4.8所示。[www.61k.com)
~
关键词库 基于本体的深度搜索系统关键词库的构造与研究
摹于本体的深度搜索系统关键词库的构造‘j研究
61阅读提醒您本文地址:
《?l蕾l馏‘io瞄声。[www.61k.com)I.O’?’
《rtf:船甲xzln=:r毫f:’h::≯://m.T3.or“l辨雪,0:,::-f士卜#珏tdl—1‘埔。I奎1n::册1=。h::p:.7.7百1隋.T3.::暑?’:00:j0:+龠i#’t正ln=:ZS宣:’ht:p://m.霄3.。!-.:/;001,船&sch黜‘a≯。t互1矗:::if==’h::口:/。,百-_冒.霄3.々?∥:0∞.-01,一。r立iI==hE置lI拳’
z正ln:=。h::p:/,/l"Jl"W.镛1一on:olori=:.=o曩,:h出cL:冒i#’
x=l:ba=e:‘h::p:,/冒,曙.o.1一on:ologie:.co=/:ht皿-.cy-l’>
≮册1:On=olo尊r芷:at钆::’’,,
<口Tl:cla==:蓝:ID=’末毫’>
《r己f=:=ttCia:;0f>
‘,ri!=:‘让C1a==of)<∞l:cl-s;r蛀:ID=。囊鳓4品’,’
</ofI:cla=:,
‘wi:Ci-==rdf:ID=’手机’>
tr立f::“tci-==锻r鲑:res雠fc芦’?蠹离产品’,>
</ofl:Clu=>
‘∞1:cla;;r赶:ID=’掩虮’>
‘,∞l:cla#s>..<r立f::=让cl-=:ofr鲑:reo口旺c芦+譬蠹荨;产品’,>
《nl:cla;sr赶:Z缸’置存’’
‘ri!=:;1:bClt==oj,
‘∞l:Cla;sr醛:ID=。萋逝毒tl蠛。,>‘/rib:=1【bCla=:Of>
‘,∞l:C15==,
<∞1:Cla:sr篮:ID=’殛盘’>
‘r立f;:=?LLbCl&::Of>
(口,l:cli;=:芷:ab倒:=’掌摹逻辜宅籍’,>
‘,ri如:=让Cl-=蝴f,
<,口-1:C1a:=>
《o冒1:Cl-==r畦f:ID=’C冗r’
<r蛙;::libClassOf)
‘/r立f=:=让ClusOf)《wl:clE;;:妊:暑b“t荨。#基i辞电jr,'
<Iofl:Cla=s)
《w1:口b拈=:h跆"t?蛀f:吐“.-’#晶嚣’)《ri虹:幻乩inr耋f:f=;佻rc乒’k:p://m.13.∞‘,∞∞,07,佣l摹k弘siti垤知。孵t,’,,r虻:re:以r:口’葶蠡暑声晶’,>
《r吐f::∞e
≮/Ⅱl:钝je=:Fr∞2r:7)
<owl:仇拈=:h∞er:7rdf:ID=。田内品壤’>
‘r立拓::让艮印e::了Ofrdf:re:饥rce:’摹品簿’,>
</wl:蚀je::ho”r:?,‘镰l:D虻::强=P:珊::了:矗f:I啦。型号。,’
《船l:Dt:配?pen卸ert,r旺:ID=’蛭皂’,>
<rdf.s:如mainr村:r量;弧rc筘’善手机’/}
‘靠1:D丑:at野eho脚7<r童f=::bzain>r茁:ID=。曩盈’,
(口t1:Cli=订
‘碍l:unionOf
《镛l:Clu:r宣f:Et以::。#三-,。r’,>r矗f:w;oI,搿。Colltcti锄’'
(owl:c15==rlf:a]y,u2=’警光疆’,>
‘/∞l:unior,0f>
(/o冒I:Cla==>
</r出k:i:Eain)
<rtf;:rur}>《∞l:h:妇L黔,
‘口-1:on.-o.。rtf:parseType=’Resource’><z.£f.:一firs:rif:妇:a:?础:’h:t,:,,俐.霄乱僻一2∞1,msch啦警;tri矗,>壤土昱毒</rd.。:firs:)
<r吐f:r=;:r虻:≯ar:e巧pe=’Resource’’
>襄畦最_;</r茁:jirs:><r篮:fir=:r虻:虹:tt了p筘’h.:,://霄-.诅茁暑,0∞l,趣Ls吐e啦赛;tri醒’‘r鲒::=#:rlf:舛r=er?≯筘’Ae删rce’)‘r立f:res:ri主:r!=饥了:F。h:-.p:/,御.-3.琵∥19∞,。:,:扣童}玎n:Ⅱ.n蜘il’,>‘rd三:fir:-.r茁:扭:丑ty强=’http://m.膏3.凹一2∞l俺虹s吐珏I摹£tri醒’>反置{{/r鲑:first>
<,ri!::en>
‘,rii:rest>
《,∞1:∞柏f>
<Io蕾I:D毗丑】沁lre,
图4.8本体实现代码
4.2.5本体维护
本体的维护是本体构造的一个重要环节,包括对初始本体的概念的补充和修改等维护工作,在本文构造的本体中主要体现为对领域内关键词的扩充和完善,以保证构建的本体的实时性和完善性。主要可以通过两种方法可以对本体进行更新和维护,一种是通过构造本体时使用的工具,在原始本体的基础上进行补充添加和编辑、删除操作,Protdgd工具对这些操作都能很好地支持。这种35
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
方法的特点是很直观,如果本体维护者使用的机器安装了Prot696工具,就可以很方便地开展维护工作。[www.61k.com]但由于这种维护方法是基于工具的,因此缺乏灵活性,如果服务器没有安装prot696工具,则通过这种方式的维护工作将无法展开。另一种维护方法是通过OWL代码来维护,该方法弥补了第一种方式的不灵活的特点。OWL文件不基于任何工具和背景就可以直接操作,因为其可以通过记事本编辑,方便又快捷。此外OWL代码层次结构清晰,代码简单易懂。这两种方法相互补充,可以很好的完成本体维护工作。
4.3基于本体的关键词库研究
将本文构建的本体应用到深度搜索系统中,需要对构建的本体进行一定方式的存储。本体的存储方式有两种:关系数据库存储和文件存储方式。
61阅读提醒您本文地址:
关系数据库存储方式是指将本体中的数据存储到关系数据库中,关系数据库主要有SQLServer、Oracle和MySQL等。关系数据库的数据存储格式是结构化的数据,通常表现为多个二元表的形式,但是本体的数据是三元的,要将三元数据映射N-元的表中,需要进行复杂的数据库设计,而且也不能准确无误的表现本体中的概念关系和层次结构。此外对关系数据库的操作还需要服务器安装数据库,并对数据库进行正确的配置之后才能进行。
利用文本方式存储相比关系数据库方式存储更具有方便灵活性,文件可以移植到任何环境下打开和操作,不需要进行额外的配置工作。利用文件夹和文件之间的嵌套可以很方便的表达出本体的概念关系,特别是层次结构。本文中构建本体的目的是为了实现深度搜索系统中关键词的自动提取和生成,数据的集成过程中需要不断的提取关键词,因此采用文本存储方式存在一个问题,即频繁的读取文件中的数据会导致占用太大内存,影响系统效率。
相比Windows系统,UNIX系统具有以下几点优势:
1、与Windows系统相比,UNIX系统在文本处理方面具有强大而完善的功能,特别是针对字符流的处理,如awk命令、sed命令、grep命令等。
2、UNIX系统提供良好的文件系统和文件规范。UNIX系统不支持文件类型,支持符号格式,对目录和文件名有明确的规范,而Windows系统使用的是
。
很早以前的文件名命名规则。
3、UNIX对文本操作支持日志管理,用户可以查看和处理文件操作日志。4、UNIX系统具有很好的稳定性和安全性。
本文在UNIX系统环境下编程实现本体文本方式的存储,生成查询关键词库。UNIX系统的多用户多任务、可移植性好和层次性文件系统等特点可以解决本体中类的层次结构的存储问题。
下面几节分别对关键词库的构建、应用和更新过程进行详细描述,并展示36
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
部分实现代码。[www.61k.com)
4.3.1基于本体的关键词库的构建
本体的数据包括类、属性、函数、属性值以及类与类之间的关系。使用文件存储时,将类名和函数名用文件夹存储,属性用文件存储,属性值存储在文件中,类与类之间的关系则用文件夹与文件夹、文件夹与文件之间的层次结构来表示。UNIX系统中的树型目录文件系统可以很好的描述本体中的概念和概念之间的上、下位关系和同位关系。本文采用特定的映射方式将本体中的概念和各种关系映射到树形目录文件中。
词库构建的过程中,初始词库的建立可以使用手工输入,方便快捷。初始词库建立完成后还需要后续不断的更新,这时则可以通过编程方式实现自动更新操作,如何获取更新的数据信息将在后面的小节中阐述,词库的建立采用基础语言C语言实现。
本体中几个主要概念的具体映射方式如下:
类(Class)的映射:本体中的类在目录文件中存储为目录,与此类有上下位关系的类,如父类与子类的关系(subClassOf),在父类的目录下建立子类目录;与此类有同位关系的类,如有两个类在本体中定义为相等类(equivalentClass),则将两个类的类名用空格连接,只建立一个目录;同一父类下的子类,则在与其相同的上层目录下重新建立新的目录。建立目录的主要功能代码如下:
intCreateDir(char}str){
char*currentdir;/.获取目录变量?/,
charfilename[LENGTH];产文件名称幸/
charDirStr[LENGTH];产目录名称幸/
DIR木dir;
structdirent毒ptr;
intre;
户初始化变量宰/
rc=O:
current_dir2NULL;
dir=NULL;
memset(filename,Ox00,sizeof(filename));
memset(DirStr,Ox00,sizeof(DirStr));
svTrim(str);37
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
户+获取当前目录+/
eurrent__dir=(char?)getcwd(current_dir,LENGTH);
严判断输入参数是否带”/”事/
if(str[O】一y)sprintf(filename,"%s%s”,current_dir,str);
elsesprintf(filename,"%s/%s”,currentdir,str);
svTrim(filename);
dir=opendir(current_dir);
while(NULL!=(ptr=readdir(dir))){
svTrim(ptr->d_name);
if(strcmp(ptr一>d_name,str)一0){
fprintf(stderr,”目录【%s】已存在Ⅵ”,ptr->d_name);
return20;
)
)
产关闭目录堆/
closedir(dir);
l*OlJ建所需目录宰/
sprintf(DirStr,"mkdir%s”,filename);
re=system(DirStr);
if(re)fprintf(stderr,"创建目录[%s】失败\Ia",filename);
returnO;
)
属性(Property)的映射:属性分为对象属性和数据属性。(www.61k.com]对象属性映射为(subPropertyOf)的关系,和类的上下位关系映射一样,在上层目录下建立子目录,数据属性映射为文件。属性与属性之间和类一样也存在子属性目录或子文件。属性中定义了TransitiveProperty(传递性)。传递性属性的映射方式为:将所有定义为传递性的属性也在本目录的下级目录下建立这些属性。比如价格属性、颜色属性定义为传递性,并且这两个属性是所有超类“Thing”的
61阅读提醒您本文地址:
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
属性,则在“Thing"目录下面的“数码产品"类,以及“数码产品"下的“笔记本"和“手机”类下都继承这两个属性。[www.61k.com)这两个属性又属于数据属性,则在数码产品目录下建立“价格"文件和“颜色”文件,并在“笔记本"目录和“手机”目录下也都建立“价格’’文件和“颜色"文件。建立文件的主要功能代码如下:
CreateFile(char幸str){
char*currentdir;产获取目录变量幸/
charfilename[LENGTH];产文件名称?/
charDirStr[LENGTH];严文件目录变量串/
FILE*fpr;产文件指针宰/
intrc;
严初始化变量幸/
re=0;
current—dir2NULL;
memset(filename,Ox00,sizeof(filename));
memset(DirStr,Ox00,sizeof(DirStr));
svTrim(str);
严木获取当前目录牛/
current_dir=(char牛)getcwd(current_dir,LENGTH);
/,笋lj断输入参数是否带”/”幸/
if(str[O】一’/’)sprintf(filename,"o/oSo/oS",current_dir,str);
elsesprinff(filename,"%s/%s”,current__dir,str);
产判断是否有后缀.txt*/
if【!strs似s仃,”.txt『’))strcat(filename,".txt”);
svTrim(filename);
if(access(filename,ROK)一O)
{
fprintf(stderr,"文件名【%s】已存在W',filename);
return10:39
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
/.创建文件名?/
fpr=fopen(filename,"w”);
if(fpr—NULL){
fprintf(stderr,"创建文件名【%s】失败kn",filename);
return20;
}
产关闭文件?/
fclose(fpO;
returnO;
)
函数集的映射:本体中定义了函数,函数的映射方式为:所有函数值建立在函数名的目录下。(www.61k.com)例如定义了“配置”函数(内存容量,显存容量,显卡类型,硬盘大小,CPU,光驱类型,笔记本),则在“笔记本"目录下建立“配置”目录,然后将“内存容量"文件、“显存容量"文件、“显卡类型"文件等建立在“配置"目录下。
属性值的映射:属性值映射为文件的内容,即在属性文件下添加属性值的内容。例如CPU类型包括有酷睿双核、赛扬双核、奔腾四核等。则在CPU类型文件中填入这些属性值。添加文件内容的主要功能代码如下:
imCrFilContent(char母strl.char宰str2){
char*currentdir;
char/.获取目录变量严文件名称宰/?/filename[LENGTH];
imrc:
FILE宰邱w,木邱r;
char产文件指针?/buffer[LENGTH];产字符串临时变量?/
/牛初始化变量枣/
rc=O;
current—dir=NULL;
memset(filename,Ox00,sizeof(filename));
memset(buffer,Ox00,sizeof(buffer));svTrim(strl);
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
svTrim(str2);
严宰获取当前目录宰/
current_dir=(char?)getcwd(currenLdir,LENGTH);产判断输入参数是否带M/’例如:/cheng.txtorcheng.txt+/if(strl[0】一少)spfintfffilename,"%s%s”,currentdir,strl);elsesprintf(filename,"%s/%s”,current_dir,strl);
严判断是否有后缀.tKt?/
if(!strstr(strl,”.txt”))strcat(filename,".txt”);
svTrim(filename);
if(!access(filename,R_OK)一0)
{
fprintf(stderr,"文件名【%s】不存在\11”,filename);
return10;
)
/宰打开文件引
fpw=fopen(filename,"a+”);
if(fpW—NULL){
fprintf(stderr,,I手丁开文件名[%s】失败\n",filename);return20;
)
/幸打开文件木/
fpr2fopen(filename,"r”);
if(fpr—NULL){
fprintf(stderr,"打开文件名【%s】失败u",filename);return30;
}
户判断添加的内容信息是否存在拳/
while(NULLf-fgets(buffer,sizeof(buffer),fpr)){41
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
svTrim(buffer);
if(strnemp(buffer,str2,strlen(buffer))一O){
61阅读提醒您本文地址:
fprintf(stderr,"添加的内容信息已存在瞰s】文件中\Il",filename);
return40;
)
产信息写入文件中?/
fprintf(fpw,”%sha",str2);
/宰关闭文件?/
felose(fpr);
fclose(fpw);
returnO:
4.3.2基于本体的关键词库中词的提取
建立查询关键词库的主要目的是为了实现深度搜索系统中查询关键词的自动提取。(www.61k.com]DeepWeb数据自动获取模块中,查询关键词库提供关键词给数据获取程序,实现自动提交查询请求。因此如何有效地自动提取词库中的数据,在本系统中起到很重要的作用,如下图4-9所示。
图4.9DeepWeb数据自动获取模块
~、
由于本文中建立的查询关键词库中的文件夹、文件以及文件内容都具有一定的含义,都是深度搜索系统中的关键词,因此词库中词的提取并不简单是文件内容的读取,还包括存储目录的提取,即文件夹名、文件名以及它们之间的
42
关键词库 基于本体的深度搜索系统关键词库的构造与研究
rr基于本体的深度搜索系统关键词库的构造与研究层次结构,这样才可以实现系统搜索时提供查询关键词。[www.61k.com)深度搜索系统中要完成数据的获取,需要不断的提供查询关键词,才能得
到尽量多的数据结果,以保证数据库的全面性。不断的访问文件夹和文件,对内存的消耗太大,因此本文建立一个特殊文件Temp.TXT来存储所有目录和文件内容,提取关键词只需要访问一个文件即可。其主要实现代码如下:
Staticvoidsearch—file(char?path,FILE幸fpw)
{
DIR奎directory;
structdirent幸direntry;严系统机构体目录木/
charbuffer[LENGTH];产字符串临时变量+/
charTempStr[LENGTH];严字符串临时变量掌/
charTempStrl[LENGTH],TempStr2[LENGTH];严字符串临时变量奎/
charTempStr3[LENGTH],TempStr4[LENGTH];严字符串临时变量?/
FILE*fpr;严文件指针幸/
/*opendir:系统函数,功能:打开目录掌/
if(NULL===(directory=opendir(path)))
{
fprintf(stderr,”%s”.path);
return;
,
/*readdir:系统函数,功能:读取目录幸/
while(direI崎readdir(directory))
{
/幸忽略UNIX系统隐藏的.和..目录
幸忽略可执行文件searchfile.
牛忽略源码demo_new.c,
宰忽略生成的文本文件Temp.TXT
奄|
if(!strcmp(direntry一>d__name,”.”)
lI!strcmp(direntry->d_name,"..")
fl!strcmp(direntry->d_name,"a.out”)
lI!strcmp(direntry一>d_name,"SearCh_file.C”)
l[!strcmp(direntry?>d.__llame,ItTemp.TXTIt))
{43
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕二E学位论文
,
}else{、’?
产判断路径中是否存在吵,没有则添加’/t分隔符幸/
if((strcmp(path,"/”))一O)
sprintf(buffer,”%s‰”,path,dir_entr)r->dname);
else
sprintf(buffer,”%s/%s”,path,dir_entry->d_name);
严判断是否为目录,是则递归继续循环奉/
if(isDir(buffer)){
search_file(buffer,fpw);
)
else
{
产此为非目录,则为文件
幸fopen系统函数,功能:打开文件,返回为空则打开文件错误
★|
fpr=fopen(buffer,”r”);
if(NULL—fpr){
/*fprintf:系统函数,stderr系统变量,把错误返回给界面?/
fprintf(stderr,”Openfile[%s】Eerr",buffer);
return;
)
/牛循环读取文件中内容+/
while(NULL!=fgets(TempStr,sizeof(TempStr),审r)){
/宰替换文件中l/t为¨分隔符奉/
strrep(buffer,”/”,””);
严特殊处理:删除文件名称后缀,删除每行前面无用字符宰/
if(strstr(buffer,".txt”)!=NULLIl
strstr(buffer,".doe”)!--NULL){
buffer[strlen(buffer)-4】=.\O’;
memcpy(buffer,buffer+3,strlen(buffer));
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
严文件中存在’/,需要换行宰/
if(strstr(TempStr,”/”)!却ⅢLL){
产初始化幸/
memset(TempStrl,0x00,sizeof(TempStrl));memset(TempStr2,0x00,sizeof(TempStr2));memset(TempStr3,0x00,sizeof(TempStr3));memset(TempStr4,0x00,sizeof(TempStr4));严分隔牛/
61阅读提醒您本文地址:
getdata(TempStr,1,TempStrl,’/.);getdata(TempStr,2,TempStr2,矿);getdata(TempStr,3,TempStr3,y);getdata(TempStr,4,TempStr4,y);严字符串保存到文件指针中书/
if(strlen(TempStrl)!=0)
fprintf(fpw,”%s=%s”.buffer,TempStrl);
if(strlen(TempStr2)!=0)
fprintf(fpw,”\11%s=%s”.buffer,TempStr2);
if(strlen(TempStr3)!=O)
fprintf(fpw,”ha%s=%s”.buffer,TempStr3);
if(strlen(TempStr4)!=0)
fprintf(fpw,”、11%s=%s”.buffer,TempStr4);
)else{
f#ntf(fpw,”%s2%s”.buffer,TempStr);)
}
/*fclose:系统函数,功能:关闭文件指针?/fclose(fpO;45
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
/*closedir:系统函数,功能:关闭目录宰/
closedir(directory);
)
词库中的每个文件中的每个词汇以及其所在目录就构成一条查询关键词,当检测到“/"存在时则说明此处出现同义词,为了减少数据的遗漏、提高数据库的覆盖率,本文在提取查询词时将出现的同义词另起一行,形成新的一条查询词。(www.61k.com)将所有文件夹和文件遍历后生成Temp.TXT文件,如图4.10所示。Temp.TXT文件中的内容可以为深度搜索系统中数据获取模块提供的查询关键词,因此对Temp.TXT文件中的内容一一读取就可以实现为数据获取过程自动提供关键词,操作过程简单方便,而且避免了重复访问词库造成的占用内存空间大和词库的安全隐患问题。
图4—10Temp文件内容
4.3.3基于本体的关键词库的更新
DeepW曲中的数据在不断更新,要保证查询结果的数据完整性,需要对查询关键词库进行不断更新,适应DeepW曲的发展。根据关键词库给出的关键词进行查询,获取查询结果,由结果分析模块对结果数据进行集成和分析,并将分析后的结果保存在文本中。再利用结果文本提取新的关键词,实现关键词库的自动更新。关键词库更新的过程在自动获取DeepWeb数据整个循环的过程中既是终点又是起点,如图4.1l所示。
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
图4-11DeepWeb数据自动获取模块
系统对结果数据进行结果集成后,生成一个数据集成文档,文档中去除了结果页面中与领域无关的内容,如广告、HTML标签、图片等。[www.61k.com]对这个数据集成文档进行关键词提取,然后通过本体中概念的语义关系和上下文知识表示,判断获取的新关键词的语义和在词库中的位置,实现对关键词库的更新操作。
对关键词库的更新过程主要包括:词法分析、语义识别、本体查询、本体更新和词库更新。
l、词法分析。对数据集成文档进行关键词提取,即将文本内容转换成词语。li
主要采用文本分词技术对文档的数据进行分词,主要使用FreelCTCLAS工具实现。FreelCTCLAS工具主要针对中文文本进行分词,该软件是完全免费的。.通过对数据结果进行集成和分析得到的文档中已经基本上对文本进行了词法分析,词语间已用冒号、空格和回车符隔开。
2、语义识别。根据上一步获得的词语,根据本体知识和上下文知识表示进行语义判断。
首先确定词语的大范围。由于获得的结果集是根据关键词库提供的关键词进行的搜索,因此通过某一条关键词查询的结果集,如关键词“手机老人机"搜索到的结果集中的词语语义一定是属于“手机’’的。可以通过这一点初步确定词语的大范围。
然后缩小词语的语义范围。观察结果集中的词语特点可以知道,词语之间有些用斜杠“/"隔开,有些利用标点符号冒号“:”隔开,有些利用回车符隔开。通过进一步分析可以知道,用斜杠“/”隔开的词语之间一般是同义词关系;用冒号“:”隔开的词语之间一般是属性关系,如“品牌:NoM#诺基亚’’;用回车符隔开的词语间一般表示下一条词语是另一条数据。根据这些特点,本文提出使用上下文知识来表示词语的特点。具体采用下面的表达式:47
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕上学位论文
W{D,LI,L2,R1,R2}其中W表示某个词语,D表示词语的数据类型,如String型、Data型等,L1和L2分别表示该词的左边第一个词和左边第二个词,Rl和R2表示该词右边第一个词和右边第二个词。(www.61k.com)其中L1、L2、Rl和R2中也包含斜杠“/"和冒号“:’’。比如对词语“Nokia”的表达为Nokia{String,“:",“品牌’,,“/",“诺基亚"}。
规定若L1=“:",则该词语是L2的属性值;
若RI=“:",则R2是该词语的属性值;
若L1-“/",则L2是该词语的同义词;
若RI=“/",则R2是该词语的同义词。
3、本体查询。在已经建立的本体库中查询每个词语,若本体中已存在这个词语,则继续查询下一个词语。当发现本体中没有该词语时,则根据上一步给定的表达式,查询其左右两边的词语。
4、本体更新。根据上一步对词语的左右两边词语的查询,和词语表达式的判断,更新本体。
5、词库更新。构建词库时本文定义了本体和词库的映射方式,同样通过这个映射方式对关键词库进行更新。本文从关键词库中自动提取关键词是利用一个特殊文件“Temp.TXT"来存储所有遍历到的关键词。当词库在不断更新时,如果每次都重新遍历一次词库,频繁的打开和读取文件,肯定会导致系统内存占用时间过长,甚至导致死机,影响其他程序的运行。因此本文采用词库和文件的同步更新来解决这一问题。即在数据更新到查询关键词库时,同时对包含库中所有查询关键词的特殊文件Temp.TxT进行同步更新,然后设置一个固定的时间如每隔一天,对本体库进行重新遍历,通过代码生成的方式重新生成Temp.TXT文件。这样既保证了数据的时效性、准确性,又可以避免数据更新后需要不断重新访问系统中的文件,减少更新次数,降低频繁生成Temp.TXT。
61阅读提醒您本文地址:
4.4本章小结
本章首先介绍了本体构造的相关知识,综合分析了目前本体构造使用的描述语言、构建方法和构建工具的特点,将领域本体的构建分为本体需求分析、领域知识获取、本体设计、本体实现和维护五个阶段。以电子商务领域为例,使用本体构建工具Prot696和本体描述语言OWL半自动化地构建了电子商务领域本体;然后描述了查询关键词库的设计和初始构造过程,并展示了部分主要功能代码实现;介绍如何利用特定文件存储词库中的所有关键词,实现自动获取DeepWeb数据;最后描述了如何利用查询得到的结果文本,使用本体的可扩充性和上下文语义关系,实现查询关键词库的更新;并采用一种词库与存储关键词的特殊文本同步更新的方法,解决频繁更新词库带来的问题。
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
第5章总结与展望
5.1本文的研究工作总结与存在的问题
随着网络的飞速发展,DeepWeb中的数据量也在急速增加,由于技术限制传统的搜索引擎无法检索到DeepW|eb中的内容,因此如何从大量的DeepWeb中搜索有效信息是目前该领域研究的热点。(www.61k.com)本文通过查阅国内外文献了解目前深度搜索的研究现状以及在深度搜索系统中引入本体概念的研究意义。本文将基于本体的深度搜索系统按功能划分为三个模块:Deepw曲数据自动获取模块、数据结果分析模块和DeepW曲用户搜索模块。通过建立一个基于本体的查询关键词库,自动为搜索过程提供关键词,实现DeepWeb信息获取过程自动化,解决DeepWeb信息搜索中由于数据异构而不能提供给用户统一查询功能、用户响应时间长、手工获取数据成本高以及得到的本地数据库不能及时更新等问题。以电子商务网站为例,本文重点介绍了如何构建一个合适的基于电子商务领域本体的查询关键词库,以及如何利用查询关键词库实现电子商务网站的信息获取,保证数据实时性、有效性和完整性。
本文的主要工作和创新点如下:
1、本文提出通过构建一个基于本体的查询关键词库实现DeepWeb数据集成。查询关键词库为DeepW.eb数据获取过程自动提供查询关键词,实现DeepWeb数据获取过程的自动化。本体可以通过一张语义关系网将领域内的所有概念和概念间的关系清楚地表达并联系起来,因此本文提出的基于本体的查询关键词库能够尽量包含领域内所有的概念集合。
2、根据电子商务网站中的数据特征,使用本体构造工具Prot696和本体描述语言OWL半自动化地构建了电子商务领域本体。本文分析目前存在的几种本体构建方法的特点,提出将目标本体的构建分为本体需求分析、领域知识获取、本体设计、本体实现和维护五个阶段。根据电子商务网站中的数据特征,使用本体构造工具Prot696和本体描述语言OWL半自动化地构建了电子商务领域本体。
3、将本体中的概念和概念之间的关系采取特定的映射方式映射到树形目录文件中,在UNIX系统环境下编码生成树形目录文件中的各层文件夹和文件,建立初始查询关键词库。根据本体中概念的层次结构特点和UNIX系统对于文件系统操作的便捷性以及良好的可移植性和安全性等特点,采用在UNIX环境下对构建的本体进行文件存储。
4、使用一个特定文件存储文件目录中所有内容,通过读取文件实现自动获49
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
取关键词。(www.61k.com]为了解决查询关键词库为DeepWeb数据获取提供查询关键词时频繁检索和访问文件带来的内存消耗过大的问题,系统对词库中所有文件夹和文件进行完全遍历,使用一个特殊文件存储所有遍历到的查询关键词。需要获取查询关键词时只需对这个特定文件进行访问和读取,这样既提高了检索的效率又增加了关键词库的安全性。
5、根据本体概念和上下文知识对查询得到的结果数据集进行本体学习,经过词法分析、语义识别、本体查询、本体更新和词库更新五个步骤实现查询关键词库的更新;并采用词库和特定文件同步更新的办法,避免频繁更新词库而影响查询效率。
虽然本文的研究工作已经告一段落,但目前本文的研究还存在一些问题,具体存在的问题总结如下:
l、本系统主要是针对电子商务领域内的深度搜索进行的研究,电子商务领域内的信息(主要是商品信息)的数量非常大,商品种类以及各自的属性等数据信息量也与日俱增。本文只是对其中数码商品类中的笔记本和手机两类商品进行了本体的构建和关键词库的建立,这只是领域内商品信息的很小一部分,要实现所有商品信息的知识获取并建立完整的本体和查询关键词库,完整实现电子商务领域内的信息深度搜索系统,还需要更多的时间、人力和物力。
2、随着网络信息量的增大,存储于关键词库中的词汇信息也逐渐增多。提取关键词库的查询词汇时本系统目前采取的是建立一个特定文件,对所有查询词汇进行遍历后存放在这个特定文件中,目前信息量较少的情况下可以方便快速的读取此文件中的查询关键词,但是随着词汇信息的增多,有可能超过一个文本文件的存储量,到时系统可能会对超出部分进行舍弃,这样就会导致查询词汇不能完全提取,影响获取的数据的信息覆盖率,并最终影响整个系统的效率,即用户查询的查全率,违背系统的初衷。
3、系统设计了根据建立的本体查询关键词库对用户的查询请求进行语义扩展,并转换成与本地数据库中的数据结构类似的查询语句,方便用户准确快速的查询。但由于时间和技术方面的限制,这一功能还没有实现。
4、目前国内外对本体构建的研究还没有很成熟的一套方法,特别是对于本体的评价、测试和维护方面,本文所构建的本体还需要领域专家的专业评价和更进一步的完善。
5.2进一步工作展望
针对目前本系统中存在的一些问题,总结出今后进一步工作的展望。具体工作如下:1、完善领域知识的获取,更新本体,逐步建立一个本领域内完整的本体知々
关键词库 基于本体的深度搜索系统关键词库的构造与研究
61阅读提醒您本文地址:
基于本体的深度搜索系统关键词库的构造与研究
识库。(www.61k.com]并对建立的查询关键词库进行实时更新,以保证获取的数据的覆盖率。
2、随着查询关键词库中查询词汇量的增大,~个特殊文件将不能完全存储所有查询词语,因此需要不只一个特殊文件来存储。而随着文件的增多,又会影响查询词汇提取的效率,进一步的工作将尝试生成多个特殊文件,以不同序号命名,并在文件读取时采取多线程读取方式来提高提取关键词的效率。
3、本系统没有充分利用本体的逻辑推理机制来实现对用户输入的查询关键词进行语义逻辑推理和扩展,这也是今后进一步的研究方向。
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
参考文献
【l】.BergmanMK.TheDeepWeb:Surfacinghiddenvalue.WhitePaperontheDeep
whitepaper.pdfWeb.2007.http://www.brightplanet.com/pdf/DeepWeb
【2】.邓志鸿,唐世渭,张铭等.本体论研究综述【J】.北京大学学报(自然科学版),2004,38(5):735
【3】.MikeUsehold,Micheal,Griinger.Ontologies:Principles,Method
EngineerandApplications[J].KnowledgeReview.2003,11(2):5?33
【4】.林超.面I句DeepWeb的对象检索关键技术研究【D】.江苏:苏州大学,2008.
【5】.藕军.DeepWeb搜索引擎的关键技术【D】.安徽:合肥工业大学,2007.
【6】.谭春亮.基于本体的DeepWeb语义搜索引擎【D】.广西:广西师范大学,2008.[7】.肖敏.领域本体的构建方法研究【J】.情报杂志.2006.(2):70一72.
【8】.杜剑峰,姜云飞.网络信息集成系统的研究[J】.计算机科学.2002,29(5):36-39.[9】.ChangK,ChenChuan,HeBin,LiChengkai,eta1.Structureddatabaseontheweb:ObservationsandImplications[J].SIGMODRecord,2004,33(3):61270.
hidden[10].SriramRaghavan,HeetorCareia—Molina.Crawlingthe
onweb[C].In:ProcoftheInternationalConference
2003.09.VaryLargeDataBases(VLDB),Rome,Italy,
【11】.PanagiotisGIpeirotis,LuisGravano,MehranSahami.Probe,Count,andClassify:CategorizingHidden
Bathara,Califomia,USA.2001WebDatabases.ACMSIGMODZ2001May2124,Santa
【121.JagodaWalny,Supervisor:Dr.Denilson
DeepBarbosa.SemaForm:SemanticWrapperGenerationforQuerying
ConferenceonWebDataSources.2009InternationalWebInformationSystemsandMining.
YY,Yu【131.HeH,MengWY,LuC,WuZH.Towardsdeeperunderstandingof
thesearchinterfacesofthedeepWeb.WorldWideWeb,2007,10(2):133—155.
14421148.【14】.黄晓冬.InvisibleWeb研究综述【J】.情报科学,2004,22(9):1
B,PATELM,ZHANGZ,eta1.AccessingtheDeepWeb:a
oftheACM,2007,50(5):942101.【151.HE
[16].survey[J】.Communications刘伟,孟小峰,孟卫一.DeepWeb数据集成问题研究,WAMDM2TR2200623[R].北京:中国人民大学,2006.
[17】.宋俊峰,张维明,肖卫东,等.基于本体的信息检索模型研究【J】.南京大学学报:自然科学版,2005,2(41):1892197.52
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
[18].GRAVANOL,LPEIROTISPG,SAHAMIM.QProber:asystemforautomaticclassificationofHiddenWebdatabases[J】.TransactionsonInformationSystems,2003,21(1):l-41.
【19].RAGHAVANS,GARCIA2MOLINAH.CrawlingthehiddenWeb【C]PPATZENIP.ProceedingsofInternationalConfer.enceonVeryLargeDataBases.SanFrancisco:MorganKaufrnann.2001:1292138.
【201.HUPY,FANGW,CUIZ.OntologybasedDeepWebsynchronous-annotation[C]//YUF.ProceedingsofInternationalColloquiumonComputing,Communication,Control,andManagement.Washington:IEEEComputerSociety,2008,5852589.
61阅读提醒您本文地址:
【21].FernandezLopezMOverviewofMethodologiesForBuildingOntologies[C].ProceedingsoftheIJCAI’99WorkshoponOntologiesandProblem-SolvingMethodsStockholm,Sweden,Augusr2,1999.
【22].FHarmelen,JHendler,IHorrocks,eta1.OWLWebOntologyLanguageReferencelWorldWideWebConsortium.http://www.w3.org/tr/owl-ref,2004.02—10
【23].WorldWideWebConsortiumWebServicesActivity.http://www.w3.org/2002/WS,2004—04—29
【24].FBaader,DCalvanese,DMcGuinness,etallTheDescriptionLogicHandbook:Theory,ImplementationandApplications.Cambridge:CambridgeUniversityPress,2003
【25].DaveBeckett,BrianMcBridelRDF/XMLSyntaxSpecification(Revised).WorldWideWebConsortium.http://VCWVV.w3.oredtr/rdf2syntax29rammar/,2004—02一10
[26].DBrickley,RVGuhalRDFVocabularyDescriptionLanguage1.0:RDFSchema.WorldWideWebConsortium.http://WWW.w3.org/tr/rdf-schema/.2004.02—10
【27].JHeflin,JHendler.SearchingthewebwithSHOE.In:ArtificialIntelligenceforWebSearch.MenloPark,CA:AAAIPress,2000.35"--40
【28].LingYY,MengXF,LiuW.AnAttributesCorrelationBasedApproachforEstimatingSizeofWebDatabases【J】.JoumalofSoftware,2008,19(2):224-236.
【29].MouYJ,CaoJ,ZhangSS.ResearchonExtendedWebServiceQoSMode
【J】.JournalofComputerScience,2006,33(1):156.168.
【301.ChuangSL,ChangK,ZhaiCX.Context—AwareWrapping:SynchronizedDataExtraction[C].InProc.ofthe33rdinternationalconferenceonVerylarge53
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
databases(VLDB),ACM,2007,699—710
【311.MaedchA.OntologyLearningfortheSemanticWeb【J】.IEEEIntelligentSystems,2001,16(2):72—79.
【321.CalvaneseD,eta1.Aframeworkforontologyintegration[C].In:CruzI.,DeckerS.,EuzenatJ.,McGuinnessD.eds..TheEmergingSemanticWeb.SelectedPapersfromtheFirstSemanticWebWorkingSymposium,theNetherlands,IOSPress,2002,201-211.
【33].ZhangJ,PengZH,eta1.Si-SEEKER:Ontology-BasedSemantic
1SearchoverDatabases[C].KSEM2006,LN龇4092,2006,599—61
【34].NieZQ,WenJR,MaWY.Object-levelVerticalSearch[C].InCIDR2007,235-246.
【35].ZhaoPP,HuangL,FangW,CuiZM.OrganizingStructuredDeepWebby
NotesClusteringQueryInterfacesLinkGraphiC].Lecture
5139,2008,683—690.inArtificialIntelligence,Springer,ADMA2008,LNAI
[36].李善平,尹奇伟等.本体论研究综述【J】.计算机研究与发展,2004,41(7),P1041-1052.
【37].
[38].杜小勇,李曼等.本体学习研究综述【J】.软件学报,2006,17(9),P1837.1847.秦嘉伟.基于本体的信息检索方法研究[D].上海交通大、每’学,2007(1),11-12
[39].俞宜孟.本体论研究[J].上海人民出版社,1999(5),47
FangW,XianXF,ZhaoPP,CuiZM.ADynamicFuzzyDescriptionLogic【40].
【J】.WuhanUniversityJournalofNaturalSciences,Springer2008,13(4):417-420.
HS,MartinsJP.Amethodologyforontology
on【4l】.Pintointegration[C].InProceedingsoftheInternationalConferenceKnowledgeCapture,2001,131—138.
61阅读提醒您本文地址:
[42].GuhaR,McCoolR.TAP:ASemanticWebTest-bed[J].Journal
andofWebSemantics,2003,1(1):81?87.【43】.FininT,MayfieldJ.JoshiA.,eta1..InformationRetrieval
ontheSemanticWeb[C].Proceedings
2005,113—120.ofthe38thHawaiiInternationalConferenceSystemSciences,
[44].赵朋朋,高岭,崔志明.关于中国DeepWeb的规模、分布和结构[J].小型微型计算机系统,2007,28(10):1799-1802.
[45].胡东东,孟小峰.一种基于树结构的Web数据自动抽取方法[J].计算机研究与发展,2004,41(10):1607-1613.
【46].BaaderF,NuttW.HandbookofDescriptionLogic【M】.Thesecondchapter,Cambridge:CambridgeUniversityPress,2003.
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
【47].HanQ,LinZQ.DefaultReasoningwithInconsistentKnowledge[J】.Journalofsoftware,2004,15(7):1030-1041
【48].JiangYC,ShiZZ,TangY,WangJ.FuzzyDescriptionLogicforRepresentationoftheSemanticWeb【J】.Journalofsoftware,2007,18(6):1257.1269.
【49].AnYooJ,JamesG,eta1.AutomaticGenerationofOntologyfromtheDeepWeb[C].18thInternationalWorkshoponDatabaseandExpertSystemsApplications,IEEEComputerSociety,2007,470-474.
[50].JulianoPalmieriL,AltigranS.daS,PauloB.G,AlbertoH.F.Laender.AutomaticgenerationofagentsforcollectinghiddenWebpagesfordataextraction[C].Data&KnowledgeEngineering,2004,49:177-196.
【511.EhrigM,MaedcheA.Ontology-FocusedCrawlingofWebDocuments【J】.In:SAC2003,ACMUSA.2003,581.624.
[52].LiuVZ,RichardJC,eta1.Drop:AprobalilisticapproachforhiddenWebdatabaseselectionusingdynamicprobing[R].InProe.ICDE2004,2004.tip:i/tip.CS.ucla.edu/tech—report/2003一repots/030024.pdf.[53].Le-HV,ManfredHandKarlA.QoS.basedServiceSelectionandRankingwithTrustandReputationManagement[C].InternationalConferenceonCooperativeInformationSystems(CooplS),2005,285—294.55
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
附录
电子商务领域本体的详细设计,包括类、属性、属性值、关系、函数等的设计如下:
提取的类有:数码产品类、家电类、数码配件类、影音类、网络设备类、提取的属性有:颜色属性、品牌属性、价格、尺寸、重量、类型、容量、属性值包括:
颜色属性值有白色、黑色、黄色、红色、绿色、蓝色、花色、透明、酒红笔记本的品牌属性值有:ThinkPad、Apple、苹果、Lenovo、联想、Asus、手机的品牌属性值有:Nokia、诺基亚、Samsung、三星、SonyEricsson、导、Newsmy、纽曼、Alcatel、阿尔卡特、Haier、海尔、知己、Capitel、首信、莱达、Amoi、夏新、广信、琦基、AUX、奥克斯、高新奇、Hisense、海信、
笔记本定位:商务本、沉稳商务本、商务白领本、便携本、极致轻薄本、家庭影音本、女性机、时尚丽人本、学生本、全能学生本、游戏娱乐本、迷你本、入门机、日常办公本等。(www.61k.com)
上市时间属性值有:2006年、2007年、2008年、2009年、2010年、2011年办公设备类、电脑类、笔记本类、PC机类、手机类、内存、显存、CPU、显卡、硬盘、主机、显示器、电池等。像素、大小、型号、上市时间、售后服务、操作系统、铃声、屏幕、定位主频、外观样式、网络等。色、军绿色、天蓝色、巧克力色、桔色、浅灰色、浅黄色、沈卡其布色、深灰色、深紫色、深蓝色、粉红色、紫罗兰色、紫色等。华硕、HP、惠普、Dell、戴尔、Acer、宏基、Samsung、三星、Sony、索尼、Toshiba、东芝、Hasee、神舟、Fujitsu、富士通、Gateway、捷威、MSI、微星、Founder、方正、Malata、万利达、BenQ、明基、GateWaU、长城、清华同方、其他品牌等。索尼爱立信、Motorola、摩托罗拉、HTC、LG、Lenovo、联想、K—Touch、天语、OPPO、BBK、步步高、Sharp、夏普、Philips、飞利浦、Coolpad、酷派、Apple、苹果、Huawei、华为、Gionee、金立、ZTE、中兴、Changhong、长虹、Dopod、多普达、Konka、康佳、Daxian、大显、BlackBerry、黑莓、BIRD、波港利通、Hedy、七喜、OKWAP、英华OK、Skyworth、创维、亿通、金鹏、普UT、Starcom、UT斯达康、其它品牌等。
61阅读提醒您本文地址:
关键词库 基于本体的深度搜索系统关键词库的构造与研究
基于本体的深度搜索系统关键词库的构造与研究
售后服务属性值有:全国联保、店铺三包、其它售后服务
价格属性值有;1000元以下、1001.2000元、2001.3000元、3001.5000元、5001.7000元、7001.9000元、9001.12000元、12001元以上等。(www.61k.com)
笔记本的重量属性值:1公斤以下、1公斤、1.1.5公斤、1.5.2公斤、2.2.5公斤、2.5公斤以上
笔记本电池属性值:3芯锂电池、4芯锂电池、6芯锂电池、8芯锂电池、9芯锂电池、其它类型
笔记本尺寸属性值:9寸、10寸、11寸、12寸、13寸、14寸、15寸、16寸、17寸、其它尺寸
笔记本CPU类型:羿龙II三核、赛扬、Celeron、赛扬双核、酷睿双核、速龙双核、奔腾M、Dothan、速龙单核、奔腾双核、炫火双核、Atom、凌动、酷睿四核、酷睿2代、奔腾四核、速龙单核、奔腾双核、炫火双核、酷睿四核、其它CPU型号。
笔记本CPU频率量级:2.4GHz、2.2GHz、2.0GHz、2.3GHz、2.1GHz、1.8GHz、1.7GHz、1.6GHz、1.5GHz、1.4GHz、1.3GHz、1.2GHz、1.0GHz、2.13GHz、1.73GHz、1.66GHz、1.86GHz、1.83GHz、1.9GHz、2.8GHz、2.26GHz、2.66GHz、1.33GHz、2.53GHz等。
笔记本CPU电压:标准版电压、低电压版、LV、超低电压版、ULV。洲BO、其它光驱。笔记本光驱类型:无、DVD—ROM、COMBO、康宝、DVD刻录、蓝光机、
笔记本内存容量:512M、1G、2G、3G、4G。
笔记本显存容量:64M、128M、256M、512M、1G共享内存容量。
笔记本显卡类型:独立、集成、双显卡。
笔记本硬盘容量:120G、160G、250G、320G、500G、640G、64G固态硬盘、128G固态硬盘。
笔记本3G上网:移动3G上网、电信3G上网、预留3G模块端口、无。笔记本蓝牙:有、无。
笔记本摄像头像素:无、130万、260万、280万等。
手机操作系统:Android、iPhone、Windows、Mobile、Symbian、OMS、Linux、BlackBerry、黑莓、无操作系统。
手机铃声类型:普通、16和弦、24和弦、32和弦、40和弦、64和弦、72和弦、MP3铃声、立体声铃音、其它和弦。
手机屏幕像素:单色、256色、6万5千色、26万、1600万、其它。
手机定位:老人机、小孩机、商务机、女性机、智能机、音乐手机、照相导航、游戏、时尚。57
关键词库 基于本体的深度搜索系统关键词库的构造与研究
硕士学位论文
手机主频尺寸:2.5英寸、3.6英寸、3.7英寸、4.0英寸、4.3英寸、1.8英寸、1.9英寸、2.0英寸、2.1英寸、2.2英寸、2.4英寸、2.6英寸、2.8英寸、2.9英寸、3.0英寸、3.1英寸、3.2英寸、3.3英寸、3.5英寸、3.8英寸、其他尺寸。[www.61k.com]
手机外观样式:直板、滑盖、翻盖、旋转、超薄。
手机网络类型:GSM、双模、CDMA2000、CDMA、G3.移动、沃.联通、天翼.电信。
手机GPS导航:支持、不支持。
手机JAVA扩展:支持、不支持。
手机MP3播放:支持、不支持。
手机WIFI-支持、不支持。
手机存储卡:不支持存储卡、SD卡、内置存储、miniSD卡、TF、microSD卡、MMC卡microSD、microSDHC、M2卡、其它存储卡。
手机电视播放:支持、不支持。
手机多点触摸:支持、不支持。
手机蓝牙:支持、不支持。
手机摄像头:无、10万、30万、130万、200万、300万、320万、500万、800万、1210万、其它像素。
手机视频播放:支持、不支持。
手机收音机:支持、不支持。
手机手写输入:支持、不支持。
手机双卡双待:支持、不支持。
手机在线炒股:支持、不支持。
本体中对关系的表述主要有以下几种关系:
Part—of关系:CPU……笔记本,主机……PC机,显示器…一电脑,内存……电脑,显存……电脑,CPU……电脑,显卡…一电脑,硬盘一…电脑,电池一…电脑。
Kind.of关系:笔记本…一电脑,电脑……数码产品,PC机一…电脑,手机……数码产品,数码配件……数码产品,影音……数码产品,网络设备一…数码产品,办公设备一…数码产品。
Attribute.of关系:颜色……Thing,品牌……数码产品,价格…~Thing,尺寸……笔记本,尺寸……手机屏幕,重量~一数码产品,类型一一CPU,类型……光驱,类型……手机网络,类型……手机外观,类型一…手机铃声,类型……显卡,容量……内存,容量…~显存,容量~~硬盘,像素……屏幕,像素一…摄像头,型号……品牌,上市时间……数码产品,售后服务……数码产品,操作系统……手机,铃声……手机,屏幕…~手机,定位……笔记本,一、.≯、
关键词库 基于本体的深度搜索系统关键词库的构造与研究
拎基于本体的深度搜索系统关键词库的构造与研究定位一…手机,主频……CPU,外观样式……手机。[www.61k.com]Same.as关系:Apple…一苹果,Lenovo…一联想,Asus……华硕,HP一…惠普,Dell……戴尔,Acer-…一宏基,Samsung……三星,Sony-…~索尼,Toshiba-..--.--东芝,Hasee……神舟,Fujitsu~…富士通,Gateway……捷威,MSI……微星,Founder-…一方正,Malata-…一万利达,BenQ一~明基,GateWall……长城,商务机~沉稳商务……商务白领,便携~~极致轻薄,女性……时尚丽人,学生本…一全能学生本,赛扬……Celemn,奔腾M…~Dothan,Atom……凌动,低电压版…一LV,超低电压版一…ULV,COMBO…~康宝,BlackBerry…一黑莓,Nokia-….诺基亚,SonyEricsson-一一索尼爱立信,Motorola-…~摩托罗拉,Lenovo……联想,K.Touch-…~天语,OPPOBBK…一步步高,Sharp……夏普,Philips……飞利浦,Coolpad……酷派,Apple……苹果,Huawei-一.华为,Gionee……金立,ZTE…~中兴,Changhong……长虹,Dopod……多普达,Konka-…~康佳,Daxian……大显,BIRD……波导,Newsmy……纽曼,Alcatel……阿尔卡特,Haier-….海尔,Capitel一一首信,Hedy……七喜,OKWAP……英华OK,Skyworth-…一创维,Amoi……夏新,Hisense……海信,Starcom~一UT斯达康,TF……microSD卡,microSD……microSDHC,容量一一大小本体中定义的函数有:配置函数(内存容量,显存容量,显卡类型,硬盘大小,CPU,光驱类型,笔记本)。配置函数(CPU类型,CPU频率量级,电压,CPIJ)。功能函数(3G上网,蓝牙,摄像头像素,笔记本)。功能函数(GPS导航,JAVA扩展,MP3播放,Wifi,存储卡扩展,电视播放,多点触摸,蓝牙,摄像头,收音机,双卡双待,手写输入,在线炒股,手机)。59
61阅读提醒您本文地址:
关键词库 基于本体的深度搜索系统关键词库的构造与研究
灸.
关键词库 基于本体的深度搜索系统关键词库的构造与研究
r▲^,致谢
论文的撰写工作即将完成,在论文撰写的过程中,我的导师给予了我很大的支持和帮助。[www.61k.com]在此我要特别感谢我的导师,他在整个论文的开题、系统的设计和论文的审稿和定稿过程中都非常认真负责的进行监督和指导,花费了大量的心思和精力。在这段时间里老师不仅在学业上对我有很大的帮助,在生活上也给予了我很多关心和照顾。在他身上我除了学习到了专业知识和专业技能外,还学到了他严谨的工作作风、一丝不苟的科学态度和孜孜不倦的学习精神。三年的研究生时期转眼即逝,我的室友和同学们陪我走过了这短暂的三年,他们都是我人生中宝贵的财富。他们在学习上帮助我,在生活上关心我,为我营造了一个良好的学习氛围和生活环境,在此我也要特别感谢他们。感谢江西师大为我提供的美好的校园环境、优秀的师资团队和强大的图书馆资源;感谢软件学院为我提供的舒适的工作室环境和良好的设备和条件;感谢这三年来学院里各位老师对我的帮助和关心。
感谢我的家人和朋友对我的默默付出和关心,为我提供坚强的后盾。最后感谢各位老师的指导和批评。,令
关键词库 基于本体的深度搜索系统关键词库的构造与研究
≯、
关键词库 基于本体的深度搜索系统关键词库的构造与研究
在读期间公开发表论文(著)及科研情况
1.第一作者.nleDesignofDeepWrebSearchEngineBasedonDomainKnowledge[J].ICRS,2010:152—155.
2.第一作者.基于价值链的软件项目成本管理[J】.科协论坛,2010(9):126.127.3.第二作者.基于XML的Web数据挖掘模型设计与研究[J】.计算机与现代化,2010(9).
4?第二作者.基于知识树的文本自动分类方法探索【J】.电脑知识与技术,2010(5).61
关键词库 基于本体的深度搜索系统关键词库的构造与研究

关键词库 基于本体的深度搜索系统关键词库的构造与研究

基于本体的深度搜索系统关键词库的构造与研究作者:
学位授予单位:邓蓉江西师范大学
本文链接:http://d.wanfangdata.com.cn/Thesis_Y1944551.aspx
61阅读提醒您本文地址:
本文标题:百度关键词搜索-百度搜索异常 搜索任意关键词均现链家地产推广61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1