一 : 并行运算进入Tilera时代(上海泛腾电子)
并行运算进入Tilera时代
作者:徐鹤军 单位:上海泛腾电子有限公司
当多数计算机工程师还在为如何充分发挥当前多核CPU的实际运行效果而绞尽脑汁时,Tilera公司内含64颗物理计算核的众核CPU已经开始的商业应用。(www.61k.com)这是一款专门为了高性能并行运算而诞生的具有革命性技术革新的CPU,采用当今最先进的两维iMesh构架,完全摒弃了传统多核CPU总线互联的结构,完全解决了传统多核CPU并行运算时常有的效率瓶颈,也为今后集成更多物理内核做好的基础构架。
下图为TileraPro64 64核CPU的示意图:
单颗TileraPro64 CPU集成了64颗866Mhz的计算内核,4个DDR2内存控制器,计算内核与内存之间的数据读写从此顺畅无比。尤其还集成了2个万兆网络控制器,摒弃了传统构架中的PCI-E总线的数据传输瓶颈。从此对于网络数据包能够真正达到了万兆级的处理能力。
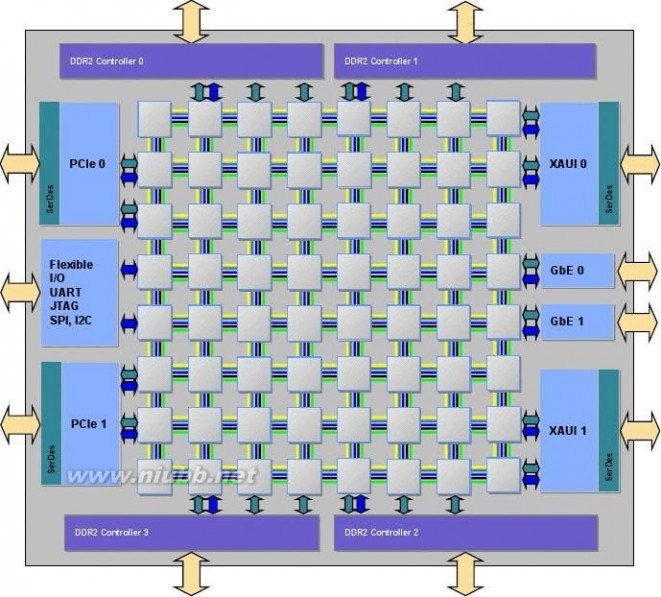
tilera 并行运算进入Tilera时代(上海泛腾电子)
每颗物理计算核都配有交换单元与多条总线连接,是内核之间的连接不再有瓶颈,数据交换更加通畅和实时。(www.61k.com]
下图为TileraPro64 单颗计算内核的结构示意图:

革命性的iMesh构架为Tilera 众核CPU高性能运算作好了技术基础,无怪乎Tilera众核CPU能比众多竞争者表现出更出色的性能。
下图为Tilera众核CPU与其他CPU的对比图标:

Compare Multi-core Processors
tilera 并行运算进入Tilera时代(上海泛腾电子)
多CPU的编程一直是困扰软件开发人员的技术瓶颈,当前的编程模式难以应对多CPU并行运算的效率,往往是随着的更多CPU加入运算队列,性能提升不明显甚至不升反降,多CPU反而成为累赘。(www.61k.com)
这时一门叫Erlang冷门编程语言开始引起大家的关注,20年前由Joe Armstrong 教授为爱立信通信公司的电话交换机系统开发的Erlang编程语言,以不同当前编程模式的设计模式,支持超大量级的并发线程。
Erlang社区的名人Ulf Wiger 采用Erlang语言在TileraPro64 众核CPU上实现了运算性能的线性提升,请看下图标:
国内
基于Tilera提供的良好软件开发环境,国内Erlang语言的先锋任职阿里巴巴淘宝网的余峰先生也在有上海泛腾电子科技有限公司提供的测试机上轻松实现了Erlang语言的编译和运行。下面是由余峰先生提供的编译过程:
# wget %%R13B04后otp_build变了好像有点问题,编译不过去。
# tar xzf otp_src_R13B03.tar.gz
# cd otp_src_R13B03
%%由于R13B03有个小小的bug会导致segment fault,我们需要对
tilera 并行运算进入Tilera时代(上海泛腾电子)
erl_misc_utils.c打个patch,以下是要打patch的地方:
# diff -Nau
otp_src_R13B04/erts/lib_src/common/erl_misc_utils.c{~,}
--- otp_src_R13B04/erts/lib_src/common/erl_misc_utils.c~
2009-11-20 14:32:23.000000000 +0100
+++ otp_src_R13B04/erts/lib_src/common/erl_misc_utils.c 2010-03-2915:53:28.000000000 +0200
@@ -373,8 +373,8 @@
return
0;
memcpy((void *)
topology,
(void *) cpuinfo-
>topology,
- cpuinfo->configured*sizeof(erts_cpu_topology_t));- return cpuinfo->configured;
+ cpuinfo->topology_size*sizeof(erts_cpu_topology_t));+ return cpuinfo->topology_size;
}
%%源码算是准备完毕了
%%开始编译前的环境准备
# export ERL_TOP=`pwd`
# eval `./otp_build env_cross $ERL_TOP/xcomp/erl-xcomp-
TileraMDE2.0-tilepro.conf`
# export TILERA_ROOT=/root/TileraMDE-2.1.2.112814/tilepro/ %%这个最好用2.x版本的
# export PATH=$TILERA_ROOT/bin:$PATH
# tile-monitor --pci -- uname -a %%验证板卡确实可用
Linux localhost 2.6.26.7-MDE-2.1.2.112814 #1 SMP Wed Sep 1 00:05:06 EDT 2010 tile GNU/Linux
%%开始交叉编译
# ./otp_build configure
# touch lib/crypto/SKIP && touch lib/ssl/SKIP && touch
lib/ssh/SKIP %%这几个模块用到了openssl, 编译不过去,忽略掉
# ./otp_build boot -a
# ./otp_build release -a /tmp/otp %%安装到/tmp/otp目录去
%%如果一切顺利,到这时候就编译完毕了。(www.61k.com)
%%我们开始收获成果。
tilera 并行运算进入Tilera时代(上海泛腾电子)
# cd /tmp/otp
# ./Install `pwd`
# tile-monitor --pci --here -- bin/erl %%没出错的话,就说明我们成功了。(www.61k.com]
%%当然我们可以把otp系统上载到板卡去,方便日后使用
# $TILERA_ROOT/bin/tile-monitor --pci --upload /tmp/otp /tmp/otp --quit %% 放在板卡的/tmp/otp目录下
%%我们还可以定义个命令别名,方便我们执行命令
# tile_erl="$TILERA_ROOT/bin/tile-monitor --pci --resume --tunnel 2023 23 --env HOME=/tmp --tiles - all ^0 - -- /tmp/otp/bin/erl"# $tile_erl +sct L10-18,1-9,19-55,57,58,61c1-55,57,58,61 +sbt db -noshell +S 58 -s init stop
好吧到此为止,我们在目标机器上/tmp/otp目录下有个完整的erlang系统。
我们开个console连接到板载的linux系统去:Object 1
[root@client otp_src_R13B03]# /root/TileraMDE-
2.1.2.112814/tilepro/bin/tile-console
tile-console: Assuming '--pci'.
Connecting to /dev/ttyS0, speed 115200
Escape character: Ctrl- (ASCII 28, FS):
enabled
Type the escape character followed by C to get back,
or followed by ? to see other options.
----------------------------------------------------
# uname -a
Linux localhost 2.6.26.7-MDE-2.1.2.112814 #1 SMP Wed Sep 1
00:05:06 EDT 2010 tile GNU/Linux
# cd /tmp/otp
%%我们跑个erlang程序<em>64核心并行</em>进行数学计算
%% 代码在这里下载 test=spectralnorm&lang=hipe&id=2
#cat > spectralnorm.erl
% The Computer Language Benchmarks Game
% % contributed by Fredrik Svahn
-module(spectralnorm).
-export([main/1]).
tilera 并行运算进入Tilera时代(上海泛腾电子)
-compile( [ inline, { inline_size, 1000 } ] ).
main([Arg]) ->
register(server,
self()),
N =
list_to_integer(Arg),
{U, V} = power_method(N, 10, erlang:make_tuple(N,
1), []),
io:format("~.9fn", [ eigen(N, U, V, 0,
0) ]),
erlang:halt(0
).
% eigenvalue of V
eigen(0, _, _, VBV, VV) when VV /= 0 -> math:sqrt(VBV / VV);
eigen(I, U, V, VBV, VV) when I /= 0 ->
VI = element(I,
V),
eigen(I-1, U, V, VBV + element(I, U)*VI, VV
+ VI*VI).
% 2I steps of the power method
power_method(_, 0, A, B) -> {A, B};
power_method(N, I, A, _B) ->
V = atav(N,
A),
U = atav(N,
V),
power_method(N, I-1, U,
V).
% return element i,j of infinite matrix A
a(II,JJ) -> 1/((II+JJ-2)*(II-1+JJ)/2+II).
% multiply vector v by matrix A
av(N, V) -> pmap(N, fun(Begin, End) -> av(N, Begin, End, V) end).
av(N, Begin, End, V) -> server ! { self(), [ avloop(N, I, V, 0.0) || I <- lists:seq(Begin, End) ]}.
avloop(0, _, _, X) -> X;
tilera 并行运算进入Tilera时代(上海泛腾电子)
avloop(J, I, V, X) -> avloop(J-1, I, V, X + a(I, J)*element(J, V) ).
% multiply vector v by matrix A transposed
atv(N, V) -> pmap(N, fun(Begin, End)-> atv(N, Begin, End, V) end).
atv(N, Begin, End, V) -> server ! { self(), [ atvloop(N, I, V, 0.0) || I <- lists:seq(Begin, End) ]}.
atvloop(0, _, _, X) -> X;
atvloop(J, I, V, X) -> atvloop(J-1, I, V, X + a(J, I)*element(J, V) ).
% multiply vector v by matrix A and then by matrix A transposedatav(N, V) -> atv(N, av(N, V)).
%Helper function for multicore
pmap(N, F) ->
Chunks = chunks(0,
erlang:system_info(logical_processors), N, []),
Pids = [spawn(fun()-> F(Begin, End) end) || {Begin, End} <- Chunks],
Res = [ receive {Pid, X} -> X end || Pid
<- Pids],
list_to_tuple(lists:flatten(R
es)).
chunks(I, P, N, A) when I == P-1 -> lists:reverse([{I*(N div P)+1, N} | A ]);
chunks(I, P, N, A) -> chunks(I+1, P, N, [{ I*(N div P)+1, (I+1)*(N div P)} | A ]).
CTRL+D
# bin/erlc spectralnorm.erl
# time bin/erl -noshell -run spectralnorm main 500 -s init stop
1.274224116
real 0m 16.90s
user 1m 16.07s
sys 0m 0.79s
# bin/erl +sct L10-18,1-9,19-55,57,58,61c1-55,57,58,61 +sbt db -noshell +S 58 -eval 'io:format("schedulers:
~p~n"[erlang:system_info(schedulers)])' -s init stop
schedulers: 58
tilera 并行运算进入Tilera时代(上海泛腾电子)
Bingo! 我们顺利的跑了数学计算,同时绑定调度器到CPU core上去了。(www.61k.com)接下来就可以按照平常那样进行Erlang并发编程了。
有关余峰先生的相关文章和资料请看 http://blog.yufeng.info.
作为国内唯一设计和量产Tilera众核高性能服务器的制造商:上海泛腾电子科技有限公司,已经为国内外众多大型网站和专业设备制造商提供高质量的Tilera众核服务器,也将与众多热衷于高性能运算应用,例如:网络包处理,视频编解码和云计算等技术人员一起推动众核服务器的广泛应用。
上海泛腾电子科技有限公司
电话:021-50270385
手机:15901848767
联系人:徐鹤军
二 : 并行运算进入Tilera时代(上海泛腾电子)
并行运算进入Tilera时代
作者:徐鹤军 单位:上海泛腾电子有限公司
当多数计算机工程师还在为如何充分发挥当前多核CPU的实际运行效果而绞尽脑汁时,Tilera公司内含64颗物理计算核的众核CPU已经开始的商业应用。这是一款专门为了高性能并行运算而诞生的具有革命性技术革新的CPU,采用当今最先进的两维iMesh构架,完全摒弃了传统多核CPU总线互联的结构,完全解决了传统多核CPU并行运算时常有的效率瓶颈,也为今后集成更多物理内核做好的基础构架。
下图为TileraPro64 64核CPU的示意图:
单颗TileraPro64 CPU集成了64颗866Mhz的计算内核,4个DDR2内存控制器,计算内核与内存之间的数据读写从此顺畅无比。尤其还集成了2个万兆网络控制器,摒弃了传统构架中的PCI-E总线的数据传输瓶颈。从此对于网络数据包能够真正达到了万兆级的处理能力。

每颗物理计算核都配有交换单元与多条总线连接,是内核之间的连接不再有瓶颈,数据交换更加通畅和实时。
下图为TileraPro64 单颗计算内核的结构示意图:

革命性的iMesh构架为Tilera 众核CPU高性能运算作好了技术基础,无怪乎Tilera众核CPU能比众多竞争者表现出更出色的性能。
下图为Tilera众核CPU与其他CPU的对比图标:

Compare Multi-core Processors
多CPU的编程一直是困扰软件开发人员的技术瓶颈,当前的编程模式难以应对多CPU并行运算的效率,往往是随着的更多CPU加入运算队列,性能提升不明显甚至不升反降,多CPU反而成为累赘。
这时一门叫Erlang冷门编程语言开始引起大家的关注,20年前由Joe Armstrong 教授为爱立信通信公司的电话交换机系统开发的Erlang编程语言,以不同当前编程模式的设计模式,支持超大量级的并发线程。
Erlang社区的名人Ulf Wiger 采用Erlang语言在TileraPro64 众核CPU上实现了运算性能的线性提升,请看下图标:
国内
基于Tilera提供的良好软件开发环境,国内Erlang语言的先锋任职阿里巴巴淘宝网的余峰先生也在有上海泛腾电子科技有限公司提供的测试机上轻松实现了Erlang语言的编译和运行。下面是由余峰先生提供的编译过程:
# wget %%R13B04后otp_build变了好像有点问题,编译不过去。
# tar xzf otp_src_R13B03.tar.gz
# cd otp_src_R13B03
%%由于R13B03有个小小的bug会导致segment fault,我们需要对
erl_misc_utils.c打个patch,以下是要打patch的地方:
# diff -Nau
otp_src_R13B04/erts/lib_src/common/erl_misc_utils.c{~,}
--- otp_src_R13B04/erts/lib_src/common/erl_misc_utils.c~
2009-11-20 14:32:23.000000000 +0100
+++ otp_src_R13B04/erts/lib_src/common/erl_misc_utils.c 2010-03-2915:53:28.000000000 +0200
@@ -373,8 +373,8 @@
return
0;
memcpy((void *)
topology,
(void *) cpuinfo-
>topology,
- cpuinfo->configured*sizeof(erts_cpu_topology_t));- return cpuinfo->configured;
+ cpuinfo->topology_size*sizeof(erts_cpu_topology_t));+ return cpuinfo->topology_size;
}
%%源码算是准备完毕了
%%开始编译前的环境准备
# export ERL_TOP=`pwd`
# eval `./otp_build env_cross $ERL_TOP/xcomp/erl-xcomp-
TileraMDE2.0-tilepro.conf`
# export TILERA_ROOT=/root/TileraMDE-2.1.2.112814/tilepro/ %%这个最好用2.x版本的
# export PATH=$TILERA_ROOT/bin:$PATH
# tile-monitor --pci -- uname -a %%验证板卡确实可用
Linux localhost 2.6.26.7-MDE-2.1.2.112814 #1 SMP Wed Sep 1 00:05:06 EDT 2010 tile GNU/Linux
%%开始交叉编译
# ./otp_build configure
# touch lib/crypto/SKIP && touch lib/ssl/SKIP && touch
lib/ssh/SKIP %%这几个模块用到了openssl, 编译不过去,忽略掉
# ./otp_build boot -a
# ./otp_build release -a /tmp/otp %%安装到/tmp/otp目录去
%%如果一切顺利,到这时候就编译完毕了。
%%我们开始收获成果。
# cd /tmp/otp
# ./Install `pwd`
# tile-monitor --pci --here -- bin/erl %%没出错的话,就说明我们成功了。
%%当然我们可以把otp系统上载到板卡去,方便日后使用
# $TILERA_ROOT/bin/tile-monitor --pci --upload /tmp/otp /tmp/otp --quit %% 放在板卡的/tmp/otp目录下
%%我们还可以定义个命令别名,方便我们执行命令
# tile_erl="$TILERA_ROOT/bin/tile-monitor --pci --resume --tunnel 2023 23 --env HOME=/tmp --tiles - all ^0 - -- /tmp/otp/bin/erl"# $tile_erl +sct L10-18,1-9,19-55,57,58,61c1-55,57,58,61 +sbt db -noshell +S 58 -s init stop
好吧到此为止,我们在目标机器上/tmp/otp目录下有个完整的erlang系统。
我们开个console连接到板载的linux系统去:Object 1
[root@client otp_src_R13B03]# /root/TileraMDE-
2.1.2.112814/tilepro/bin/tile-console
tile-console: Assuming '--pci'.
Connecting to /dev/ttyS0, speed 115200
Escape character: Ctrl- (ASCII 28, FS):
enabled
Type the escape character followed by C to get back,
or followed by ? to see other options.
----------------------------------------------------
# uname -a
Linux localhost 2.6.26.7-MDE-2.1.2.112814 #1 SMP Wed Sep 1
00:05:06 EDT 2010 tile GNU/Linux
# cd /tmp/otp
%%我们跑个erlang程序<em>64核心并行</em>进行数学计算
%% 代码在这里下载 test=spectralnorm&lang=hipe&id=2
#cat > spectralnorm.erl
% The Computer Language Benchmarks Game
% % contributed by Fredrik Svahn
-module(spectralnorm).
-export([main/1]).
-compile( [ inline, { inline_size, 1000 } ] ).
main([Arg]) ->
register(server,
self()),
N =
list_to_integer(Arg),
{U, V} = power_method(N, 10, erlang:make_tuple(N,
1), []),
io:format("~.9fn", [ eigen(N, U, V, 0,
0) ]),
erlang:halt(0
).
% eigenvalue of V
eigen(0, _, _, VBV, VV) when VV /= 0 -> math:sqrt(VBV / VV);
eigen(I, U, V, VBV, VV) when I /= 0 ->
VI = element(I,
V),
eigen(I-1, U, V, VBV + element(I, U)*VI, VV
+ VI*VI).
% 2I steps of the power method
power_method(_, 0, A, B) -> {A, B};
power_method(N, I, A, _B) ->
V = atav(N,
A),
U = atav(N,
V),
power_method(N, I-1, U,
V).
% return element i,j of infinite matrix A
a(II,JJ) -> 1/((II+JJ-2)*(II-1+JJ)/2+II).
% multiply vector v by matrix A
av(N, V) -> pmap(N, fun(Begin, End) -> av(N, Begin, End, V) end).
av(N, Begin, End, V) -> server ! { self(), [ avloop(N, I, V, 0.0) || I <- lists:seq(Begin, End) ]}.
avloop(0, _, _, X) -> X;
avloop(J, I, V, X) -> avloop(J-1, I, V, X + a(I, J)*element(J, V) ).
% multiply vector v by matrix A transposed
atv(N, V) -> pmap(N, fun(Begin, End)-> atv(N, Begin, End, V) end).
atv(N, Begin, End, V) -> server ! { self(), [ atvloop(N, I, V, 0.0) || I <- lists:seq(Begin, End) ]}.
atvloop(0, _, _, X) -> X;
atvloop(J, I, V, X) -> atvloop(J-1, I, V, X + a(J, I)*element(J, V) ).
% multiply vector v by matrix A and then by matrix A transposedatav(N, V) -> atv(N, av(N, V)).
%Helper function for multicore
pmap(N, F) ->
Chunks = chunks(0,
erlang:system_info(logical_processors), N, []),
Pids = [spawn(fun()-> F(Begin, End) end) || {Begin, End} <- Chunks],
Res = [ receive {Pid, X} -> X end || Pid
<- Pids],
list_to_tuple(lists:flatten(R
es)).
chunks(I, P, N, A) when I == P-1 -> lists:reverse([{I*(N div P)+1, N} | A ]);
chunks(I, P, N, A) -> chunks(I+1, P, N, [{ I*(N div P)+1, (I+1)*(N div P)} | A ]).
CTRL+D
# bin/erlc spectralnorm.erl
# time bin/erl -noshell -run spectralnorm main 500 -s init stop
1.274224116
real 0m 16.90s
user 1m 16.07s
sys 0m 0.79s
# bin/erl +sct L10-18,1-9,19-55,57,58,61c1-55,57,58,61 +sbt db -noshell +S 58 -eval 'io:format("schedulers:
~p~n"[erlang:system_info(schedulers)])' -s init stop
schedulers: 58
Bingo! 我们顺利的跑了数学计算,同时绑定调度器到CPU core上去了。接下来就可以按照平常那样进行Erlang并发编程了。
有关余峰先生的相关文章和资料请看 http://blog.yufeng.info.
作为国内唯一设计和量产Tilera众核高性能服务器的制造商:上海泛腾电子科技有限公司,已经为国内外众多大型网站和专业设备制造商提供高质量的Tilera众核服务器,也将与众多热衷于高性能运算应用,例如:网络包处理,视频编解码和云计算等技术人员一起推动众核服务器的广泛应用。
上海泛腾电子科技有限公司
电话:021-50270385
手机:15901848767
联系人:徐鹤军
本文标题:南通并入上海-并行运算进入Tilera时代(上海泛腾电子)61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1