一 : 无监督学习特征--稀疏编码、深度学习、ICA部分代表文献-------之一
转载http://blog.csdn.net/zhoutongchi/article/details/8191991
学习映射函数及在行为识别/图像分类中应用的文献(模型与非模型之间存在关联,算法相互采用,没有明确的区分,含仿生学文献)
%研究重点放到ICA模型及深度学习兼顾稀疏编码
1)稀疏编码(稀疏编码、自动编码、递归编码):
[1] B. Olshausen andD. Field. Emergence of simple-cell receptive field properties bylearning a sparse code for natural images. Nature, 1996.
[2] H. Lee, A.Battle, R. Raina, and A. Y. Ng. Efficient sparse coding algorithms.In NIPS, 2007.
[3] B. A. Olshausen.Sparse coding of time-varying natural images. In ICA,2000.
[4] Dean, T.,Corrado, G., Washington, R.: Recursive sparse spatiotemporalcoding.In: Proc. IEEE Int. Workshop on Mult. Inf. Proc. and Retr.(2009).
[5] J. Yang, K. Yu,Y. Gong, and T. Huang. Linear spatial pyramid matching using sparsecoding for image
classification. InCVPR, 2009.
[6]S.Wang, L. Zhang, Y. Liang and Q. Pan.Semi-Coupled DictionaryLearning with Applications to Image Super-Resolution andPhoto-Sketch Image Synthesis. in CVPR 2012.
[7] Yan Zhu, XuZhao,Yun Fu,Yuncai Liu. Sparse Coding on Local Spatial-temporalVolumes for Human action Recognition.ACCV2010,Part II,LNCS6493.(上海交大,采用3DHOG特征描述,3DSift稀疏编码未注意)。
2)ICA(ISA)模型:
[1] A. Hyvarinen, J.Hurri, and P. Hoyer. Natural Image Statistics. Springer,2009.
[2]Alireza Fathi andGreg Mori. Action Recognition by Learning Mid-level MotionFeatures. IEEE,2008,978-1-4244-2243.
[3] A. Hyvarinen andP. Hoyer. Emergence of phase- and shift-invariant features bydecomposition of natural images into independent feature subspaces.Neu. Comp., 2000.
[4] A. Coates, H.Lee, and A. Y. Ng. An analysis of single-layer networks inunsupervised feature learning.
In AISTATS 14,2011.(该篇采用采用的特征,基于BOW方法不需要检测。形成BOW时采用图像块相似聚类,跟据离BOW距离将图像块特征非线性判决,之后将正副图像以一种稀疏形式表示)
[5] Q. V. Le, W. Zou,S. Y. Yeung, and A. Y. Ng. Learning hierarchical spatio-temporalfeatures for action
recognition withindependent subspace analysis. In CVPR, 2011.
[6] Q. V. Le, J.Ngiam, Z. Chen, D. Chia, P. W. Koh, and A. Y. Ng. Tiledconvolutional neural networks. In
NIPS,2010.
[7] M. S. Lewicki andT. J. Sejnowski. Learning overcomplete representations. NeuralComputation, 2000.
[8] L. Ma and L.Zhang. Overcomplete topographic independent component analysis.Elsevier, 2008.
[9] A. Krizhevsky.Learning multiple layers of features from tiny images. Technicalreport, U. Toronto, 2009.
%非分类识别文献,引入copula估计子空间,新特征组合
[10]Nicolas Brunel,Wojciech Pieczynski,Stephane Derrode.Copulas in vectorial hiddenmarkov chains for multicomponent imagessegmentation.ICASSP’05,Philadel(www.61k.com]phia,USA,March19-23,2005.(非识别分类文献,但是涉及到一种算法,对估计子空间很有用,可以引入ICA模型。)
[11] Xiaomei Qu.Feature Extraction by Combining Independent Subspaces Analysis andCopula Techniques. International Conference on system Science andEngineering,2012.
[12] Pietro Berkes,Frank Wood and Jonathan Pillow. Characterizing neural dependencieswith copula models. In NIPS, 2008.
[13] Y-Lan Boureau,Jean Ponce, Yann LeCun. A theoretical Analysis of Feature Poolingin Visual Recognition. In Proceedings of the 27’th InternationalConference on machine Learning, Haifa,Israel,2010.(介绍多样池及概念,可以形成稀疏表示及产生鲁棒性特征)
3)深度学习(与ICA、RBM关联性强,属于多层学习):
[1] Y. Bengio, P.Lamblin, D. Popovici, and H. Larochelle.Greedy layerwise trainingof deep networks. In NIPS, 2006.
[2] Alessio Plebe. Amodel of the response of visual area V2 to combinations oforientations. Network: Computation in Neural Systems, September2012; 23(3): 105–122.(涉及到模拟人类大脑皮层感知(v1、v2、v3、v4、v5),此类文献多,主要以猴子猫动物实验)
[3] G. Hinton, S.Osindero, and Y. Teh. A fast learning algorithms for deep beliefnets. Neu. Comp., 2006
[4] H. Lee, R.Grosse, R. Ranganath, and A. Ng. Convolutional deep belief networksfor scalable unsupervised learning of hierarchical representations.In ICML, 2009.
[5]Yann Lecun, KorayKavukcuoglu, and Clement Farabet. Convolutional Networks andApplications in Vision. In Proc. International Symposium onCircuits and Systems (ISCAS'10), 2010.
[6] Pierre Sermanet,Soumith Chintala and Yann LeCun. Convolutional Neural NetworksApplied to House Numbers Digit Classification. Computer Vision andPattern Recognition,2012.
[7] Quoc V. Le.Marc’Aurelio Ranzato. Rajat Monga. Matthieu Devin. Kai Chen. GregS. Corrado. JeffDean. Andrew Y.Ng. Building High-level Features Using Large Scale UnsupervisedLearning. the 29’th International Conference on Machine Learning,Edinburgh, Scotland, UK, 2012.
[8] A. Hyvarinen andP. Hoyer. Topographic independent component analysis as a model ofv1 organization and receptive fields. Neu. Comp., 2001
[9]Y. Bengio, P.Lamblin, D. Popovici, and H. Larochelle. Greedy layerwise trainingof deep networks. In
NIPS,2007.
[10] Q. V. Le, J.Ngiam, A. Coates, A. Lahiri, B. Prochnow, and A. Y. Ng. Onoptimization methods for deep learning. In ICML, 2011.
[11] H. Lee, C.Ekanadham, and A. Y. Ng. Sparse deep belief net model for visualarea V2. In NIPS, 2008.
[12] G. E. Hinton, S.Osindero, and Y. W. Teh. A fast learning algorithm for deep beliefnets. Neural Computation, 2006.
[13] Jarrett, K.,Kavukcuoglu, K., Ranzato, M., LeCun, Y.: What is the bestmultistage architecture for object recognition? In: ICCV. (2009)2146-2153.
[14] Lee, H.,Ekanadham, C., Ng., A.: Sparse deep belief net model for visualarea V2.In: NIPS. (2008) 873-880.
[15] Bo Chen .DeepLearning of Invariant Spatio-Temporal Feature fromVideo.[D].2010.
[16] Jiquan Ngiam,Zhenghao Chen, Pang Wei Koh,Andrew Y.Ng.Learning Deep EnergyModels.in Proceedings of the 28’th international Conference onMachine Learning,Bellevue,WA,USA,2011.
%以下(CRBM、SF)这些模型参考,不做重点研究,可借鉴算法。
4)CRBM(文献多,有博士论文):
[1] G. Hinton. Apractical guide to training restricted boltzmann machines.Technical report, U. of Toronto,
2010.
[2] G. Taylor, R.Fergus, Y. Lecun, and C. Bregler. Convolutional learning ofspatio-temporal features. In ECCV, 2010.
[3] Norouzi, M.,Ranjbar, M., Mori, G.: Stacks of convolutional restricted Boltzmannmachines for shift-invariant feature learning. In: CVPR.(2009).
[4] Memisevic, R.,Hinton, G.: Learning to represent spatial transformations withfactored higher-order Boltzmann machines. Neural Comput2010.
5)SlowFeature(慢特征学习分析(德国),代表文献)
这种新方法以邻帧图像为基础研究,是一种新思路。
[1] P. Berkes and L. Wiskott. Slow feature analysis yields arichrepertoire of complex cell properties. Journal of Vision,2005
二 : 机器码农:深度学习自动编程
作者简介:张俊林,中科院软件所博士,曾担任阿里巴巴、百度、新浪微博资深技术专家,目前是用友畅捷通工智能相关业务负责人,关注深度学习在自然语言处理方面的应用。
责编:何永灿,欢迎人工智能领域技术投稿、约稿、给文章纠错,请发送邮件至heyc@csdn.net
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2017年《程序员》
机器自动编程是人工智能一直以来期望攻克的重要应用领域,随着深度学习的逐步流行,最近在自动编程方向获得了广泛应用并取得了很大进展。深度学习如何指导机器自动编写出能正确执行的代码?本文对这方面的最新技术进展进行了介绍,将主流技术分为“黑盒派”和“代码生成派”两种派别,并分别介绍了对应代表系统:“神经程序解释器”及“层级生成式CNN模型”的工作机理。
随着深度学习技术的快速进展,人工智能时代的序幕已经揭起,目前深度学习在图像处理方面的能力已经接近人,甚至在某些方面已经超过人的识别能力,在语音识别、自然语言处理等人机交互方面也取得了很大的技术进步。在未来社会,各行各业的不同类型工种逐步由机器代替人作为一个社会发展趋势已经开始逐步显现,比如工业机器人目前已经开始在工厂大量使用,特斯拉也已经在在售汽车中启用自动驾驶功能,由人工智能部分代替了传统的驾驶员的作用。
目前看人工智能已经能够成功从事一些体力为主的工作岗位,那么程序员作为一个脑力密集型劳动岗位,是否会被机器取而代之?从技术和社会发展趋势来看,这个问题在很大程度上可能会是个肯定答案。那么机器码农如何理解需求?如何根据需求秒速写出代码?本文后续内容将介绍相关技术,尤其是深度学习相关的一些技术思路。
深度学习介入自动编码领域是最近两年的事情,目前深度学习系统自动编码能够解决的问题还比较简单,比如能做到自动根据训练数据写出冒泡排序等算法,根据例子学会十位数加减法以及字符串正则匹配规则等,所以短期内机器码农还没有替代人类程序员的可能。但也要看到随着深度学习在自动编码领域的深入应用,其技术发展速度是非常快的,极有可能在未来几年有突破性的技术进展。
归纳程序综合问题
如何让机器自动产生代码这个问题由来已久,是人工智能一直希望攻克的重大问题之一,传统上一般将这个问题称为“归纳程序综合”(Inductive Program Synthesis,简称IPS)问题。IPS问题的研究目标是:
给定一组<输入,输出>数据对,如何自动产生一段代码,这段代码能够正确地将这些给定的输入转换为给定的输出。
传统的研究方法里,建立能自动产生代码的IPS系统一般主要涉及两个过程:代码组合空间搜索以及代码排序。一般编程语言可以形成的程序语句是非常多样的,如果随机选择其中一些语句组合起来,就能够对输入数据完成某种转换的任务形成输出。但是这种合法代码组合出的空间非常大,在这么大的代码语句组合空间里,到底哪些语句组合起来能够将给定的那组<输入,输出>数据进行正确的转换呢?这就需要在巨大的代码组合空间中进行搜索,找到那些能够对给定数据都能进行转换的代码片段,这些代码片段就是机器自动产生的程序。很明显,这里的关键是设计高效的搜索算法。另外,在代码组合空间里搜索,有可能找到很多段程序,这些程序都能够将输入数据进行准确地转换,那么到底输出哪一段最合理呢?这就是代码排序要做的工作,就是给多段完成相同功能的代码进行排序,找出最好的那一段,比如一种简单直观的方式是输出代码长度最短的那段作为自动生成的代码。
上面介绍的是传统IPS系统的设计思路,最近深度学习也开始被频繁应用到代码自动生成领域,后面内容主要介绍典型的相关技术思路。
机器如何使用深度学习学会自动编程
武侠世界分门别派是个常态,有少林、武当、峨眉、崆峒等派别之分,神经网络自动编程目前的主流技术路线也可以分为两派:“黑盒派”和“代码生成派”。尽管都采用了深度学习技术,但是两者在路线方向上有较大差异,也各有特点。下面我们分述两派的基本技术思路及其相应的代表系统。
黑盒派
“黑盒派”是神经网络编程的一类典型方法,所谓“黑盒”,是指编程系统并不显示地输出代码片段,而是从输入输出数据中学习转换规则,通过这些转换规则能够完成某项任务,正确地把输入转化为输出,所学习到的这些转换规则和输入输出数据中的规律则以神经网络参数的方式体现,所以并没有明确的代码或者规则输出,在人类眼中,只能看到能够完成指定任务的训练好的神经网络,至于它学到了什么规律并不清楚,这是为何称之为“黑盒”的原因。
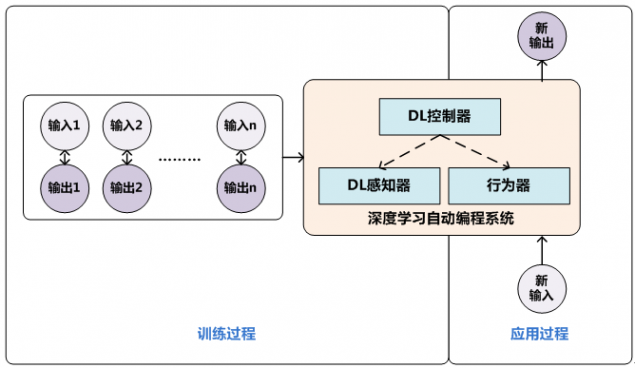
图1 “黑盒派”技术思路
图1展示了“黑盒派”神经网络编程器的基本运行思路,其主体部分包含三个关键部件:神经网络控制器、神经网络感知器以及行为器。神经网络感知器用来感知当前的输入数据并抽取输入数据的特征,神经网络控制器则根据输入数据的特征来判断当前应该对输入数据实施何种行为(比如对于数组排序来说可能是交换两个数值的SWAP(number1,number2)操作),属于决策机构,也是神经网络编程器中类似于人类大脑的关键构件,当确定了采取何种行为后,调用行为器来对输入数据进行实际操作,这样就将输入数据做了一步变换,形成中间数据,之后这个新形成的中间数据继续作为感知器的新输入,如此循环,就能够对原始输入数据不断变换,来完成比如数组排序等任务。在训练阶段,人类提供完成某项任务的一些输入及其对应的输出数据,并指定对应的行为序列,以此作为训练数据,训练神经网络编程器的学习目标是让深度学习系统模仿这种针对输入数据的行为过程,最终能够形成正确地输出数据。当训练完毕后,这些转换规则就被编码到神经网络的网络参数中,当实际应用时,提供一个新的输入,神经网络感知器对输入数据进行特征提取与表示,神经网络控制器决定采取何种操作,行为器对输入数据进行实际的变换行为,形成中间结果,如此反复,直到神经网络控制器决定终止操作,此时得到的结果就是程序对应的输出结果。
从上述过程中可知,“黑盒派”神经网络编程器并不产生具体的代码来完成编程任务,而是学习输入数据和输出数据之间的规律及其转换规则。从广义上来说,神经图灵机等网络模型虽然不是专门用于编程,而是用于更通用的任务过程中,但是其实也是符合这种“黑盒派”架构的基本思路。
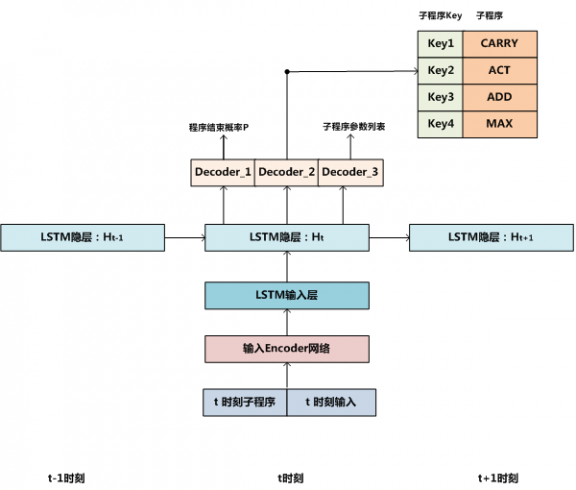
图2 神经程序解释器(NPI)运行机制
神经程序解释器(Neural Programmer Interpreters,简称NPI)是Google提交到ICLR 2016的会议论文中提出的神经网络编程模型,这篇论文因新颖的思路及创新应用获得了ICLR 2016最佳论文奖。神经程序解释器是一种典型的“黑盒派”方法。
NPI的主体控制结构是递归LSTM(参考图2所示),这种递归LSTM结构可以体现程序与子程序之间的调用关系。至于什么是递归LSTM后文会有解释,我们先根据图2所示内容来说明NPI的运行过程。
在t时刻,LSTM的输入包括当前选中的子程序以及此时的输入数据,经过Encoder编码网络对这两个输入进行映射,形成t时刻LSTM输入层的内容。这个过程其实就对应图1中的神经网络感知器,用来对输入数据进行编码和特征提取,在NPI中,不同类型的任务可能对应不同的Encoder编码网络,因为不同任务的输入类型各不相同,比如有的是图片,有的是数组等,所以很难有公用的输入编码器能够统一处理,但是不同任务会共享LSTM层参数。
在对输入进行特征编码之后,t时刻的LSTM隐层单元对输入以及LSTM网络t-1时刻的隐层信息共同进行非线性变换,这是对历史信息和当前输入的特征融合;然后,通过三个解码器来产生t时刻的三种类型的输出:Decoder_1根据隐层编码信息产生一个概率值P,这代表了当前程序结束的可能性,当P高于阈值的时候,当前程序终止;Decoder_2输出子程序库中某个子程序的ID,这代表发生了<主程序,子程序>间的调用关系;Decoder_3输出新映射到的子程序所需的参数信息列表,Decoder_2和
Decoder_3一起可以触发被调用的子程序。可以看出,LSTM结构以及子程序库其实就是图1中所示的神经网络控制器,它决定了神经网络所需要做的各种决策。NPI没有明确的行为器,这些行为隐藏在被调用的子程序中,一般不同的子程序会定义针对输入数据的不同操作,调用子程序会触发子程序的操作来改变输入数据内容。
之所以说NPI是个递归LSTM结构,是因为当子程序被触发时,自身也形成了类似图2所示的LSTM结构,所以形成了递归LSTM的形态。当被调用的子程序中的某个时间步输出的程序终止概率P大于阈值时,会返回调用程序的LSTM结构中,继续下一个时间步的类似操作。
图3所示是NPI自动学习十进制加法的结构示意图,其输入是不断被子程序变换内容的数组矩阵,其控制结构其实就是图2所示内容,只是展示出了被调用子程序的LSTM结构,所以看上去比较复杂,但其运行逻辑就如上文内容所述。
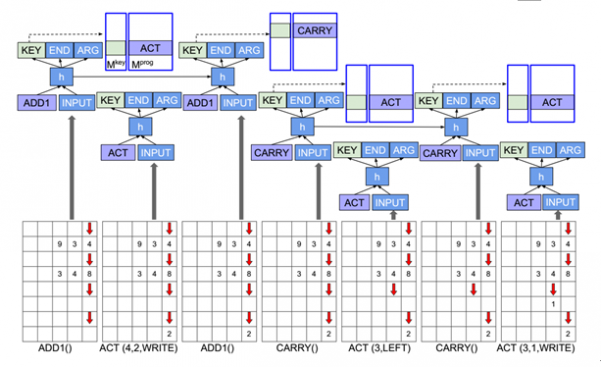
图3 NPI学习十进制加法
代码生成派
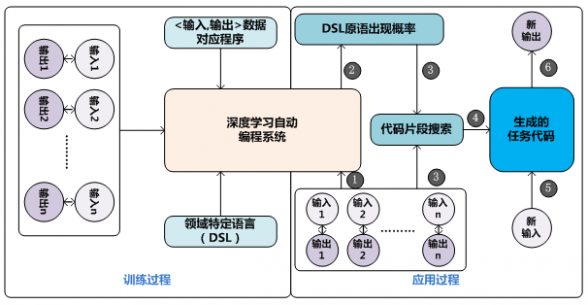
图4 代码生成派
“黑盒派”有个很容易被诟病的问题:对于开发人员来说,对神经网络到底从数据中学到了什么规律所知甚少,所以不利于分析系统存在的问题以及提出有针对性的改进方案。“代码生成派”在这一点上的思路和“黑盒派”有很大差异,更接近传统的解决“IPS问题”的思路,期望能够让机器码农像人类程序员一样把解决问题的过程形成代码片段。目前也有不少深度学习自动编码系统采用这一技术路线,尽管不同系统具体技术方案有较大差异,但其基本流程都是类似的,图4展示了从不同方案中抽象出的“代码生成派”神经网络自动编程的基本思路,分为模型训练阶段和模型应用阶段。
在模型训练阶段,需要使用不同种类编程任务的训练数据来训练深度学习自动编程模型,一般训练数据包括:
任务Taski的一系列输入输出数据:
{⟨Input1,Output1 ⟩,⟨Input2,Output2 ⟩……⟨Inputn,Outputn ⟩}
任务Taski对应的代码片段:Programi
这组训练数据的含义是:对于要执行的任务Taski来说,当输入为Inputj的时候,经过任务的代码Programi对输入进行各种变换,形成对应的输出Outputj。训练数据中可以包含各种不同类型的任务及其对应的训练数据,这形成了总体的训练神经网络模型的训练数据集合。
目前常用的编程语言有很多,比如JAVA、C++、Python、PHP等,对于机器码农来说,也存在着:“PHP是不是最好的语言”这种问题,就是说需要作出应该用什么语言产生代码的决策。一般不同的深度学习自动编码系统都会参考“领域特定语言(Domain Specific Language)”自己定义一种编程语言,而不是直接采用人类程序员常用的某种编程语言,这是因为对于机器产生代码来说,目前常用的编程语言过于复杂,里面包含了循环、分支判断等复杂控制逻辑,而根据“领域特定语言”定义的语言一般都比较简单,不包含这些控制逻辑,只包含一些基本原语,比如数值加一、数值减一、移动指针位置、读取某存储器内数据、将数据写入存储器某位置等基本操作原语。所有代码片段(包括训练数据对应的程序以及将来要生成的代码)都采用自定义的领域特定语言,这样会大大简化机器码农的学习难度。
给定了各种任务的输入输出数据及其对应的代码片段,深度学习自动编程系统就可以开始使用SGD(随机梯度下降)算法来训练模型,一般神经网络的输入是某个任务对应的输入输出数据,而学习目标则是调整神经网络参数,使得其输出的代码片段和训练数据中对应的代码片段尽可能相同。通过这种方式可以训练获得自动编程模型。
在模型应用阶段,为了让机器码农能够针对新任务自动编写出解决任务的代码P(P能够正确地将给出的所有输入转换为对应正确输出),需要提供新任务的若干输入输出数据,这其实类似于日常程序员写代码的需求说明,只是以数据的方式体现的,否则不可能让机器漫无目的地去生成不知道在干么的代码,任务的输入输出数据其实是告知机器码农数据之间的映射规律。机器码农在获得新任务的输入输出数据后,根据训练阶段学习到的模型,可以预测出“领域特定语言”中的各种操作原语语句出现在代码片段P中的概率,可以认为出现概率较高的原语是代码片段P中应该包含的语句。这里需要注意的是:深度学习系统并不能准确地输出完整的代码片段,只能预测代码片段中DSL原语出现可能性。之后,可以采用某些搜索技术(比如线性动态编程或者宽度优先搜索等技术)在代码组合空间中寻找代码片段,这些代码片段能够准确地将给定的所有输入正确地转换为对应的输出。从这里可以看出,深度学习预测的结果起到的作用是形成代码组合空间搜索时的约束条件,能够大量减少搜索空间的大小,使得后续代码搜索过程极大地提速。
层级生成式CNN模型(Hierarchical Generative Convolutional Neural Networks,简称HGCNN模型)是Facebook最近提出的一种具备“代码生成派”典型特点的深度学习自动程序推导方法。其整体工作流程符合上述“代码生成派”运行过程,只是图4中的“深度学习自动编程系统”模块采用了具体的HGCNN模型而已。

图5 层级生成式CNN模型(HGCNN)
图5展示了HGCNN模型的神经网络结构。在模型应用阶段,对于需要编码的新任务,先提供若干满足任务处理逻辑的输入输出数据(HGCNN主要对数组进行各种类型的变换,比如图5中展示的例子是对数组进行排序)。对于每个输入输出数据,HGCNN使用四层采用全连接结构的DNN网络(图5中标为b的网络结构)来对其进行特征提取,每层网络包含512个隐层神经元。之后,将若干个输入输出数据的特征求均值作为输入输出数据的整体特征表示。可以看出,这个过程是对输入实例进行编码和特征提取的阶段。然后采用连续的CNN上采样(UpSampling)操作不断形成逐步扩大的二维结构矩阵,上采样是用来可视化展示CNN隐层所学到的特征所常用的技术,在这里采用上采样可以将输入输出数据中的特征规律以类似二维图形的方式展示;上采样形成的二维矩阵每次扩大一倍,直到形成最终的16*16大小的代码画布(Code Canvas),这个最终的代码画布代表了各种操作原语在最终代码中出现的可能性。代码画布的每一行代表一个操作原语语句,一个操作原语由某个操作符以及对应的两个参数构成(参考图5中的c部分)。GHCNN的“领域特定语言”定义的语言类似于汇编语言,图5中c子图展
示的是Load 1 2的操作命令,图6则列出了这个语言定义的操作原语。

图6 HGCNN的领域特定语言
在获得了最终程序中可能包含的原语语句概率信息后,HGCNN采用宽度优先搜索策略在代码组合空间中搜索满足输入输出实例约束条件的代码片段,以此来最终形成输出的程序代码,这样就完成了指定输入输出实例后自动产生代码的功能。
HGCNN有个特色是训练数据包括输入输出以及对应的代码完全自动生成得来,而不像很多其它系统需要提供现成的训练数据,从这点上说其运作机制有点类似于无监督学习。另外,从上述描述可以看出,本质上HGCNN是一种符合Encoder-Decoder(编码器-解码器)结构的具体模型,这里Encoder的编码对象是多个<输入,输出>数据,形成特征表示后采用Decoder来产生DSL原语语句,Decoder则是利用了上采样生成二维结构的方式生成DSL原语片段生成概率。
DeepCoder是另外一个采取“代码生成派”路线的深度学习自动编码系统,其主体思路和HGCNN类似,只不过使用的具体Encoder和Decoder不太相同,其整体运行流程也基本采用了图4所示的“代码生成派”典型流程。
问题与展望
利用机器自动根据任务实例学习编写代码是能够极大提高代码开发效率的人工智能应用领域,而深度学习技术广泛使用在这个领域也是最近两年刚出现的新趋势,尽管取得了非常快速的技术进展,但是这个研发领域仍然面临一系列需要解决的问题。
首先,深度学习自动编码研究仍然处于技术发展初期,目前也只能产生解决比较简单任务的代码,距离真正实用化的代码生成还有很大距离。其次,尽管提出了一些通用的解决方案,但是大部分技术的通用性仍然不够强。所谓通用性不强,是指当面临一类新的编程任务,需要重新训练神经网络参数,无法做到训练一次以后面对新场景时原先的神经网络能够反复适用,这对于技术的实用化应用是个很大的障碍。
再次,对于机器自动产生的代码,很难验证其逻辑的正确性。自动产生的程序虽然能够将训练实例中给定的输入正确转换为指定输出,但是毕竟这些例子很有限,对于更多的输入其输出是否正确这点很难验证。
虽然面临如上诸多困难,但是深度学习的蓬勃发展给很多应用领域都带来了根本性的性能提升,相信在未来几年内神经网络编码器领域会有大幅的技术进步,有可能在某些垂直领域产生真正实用化的机器码农。
【CSDN_AI】热衷分享 扫码关注获得更多业内领先案例

61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1